

UI自动化-元素定位方法
1、id定位: find_element_by_id()
从上面定位到的搜索框属性中,有个id="kw"的属性,我们可以通过这个id定位到这个搜索框
# 打开百度首页
# 启动浏览器 driver = webdriver.Chrome(executable_path=driverfile_path) # 打开百度首页 driver.get(r'https://www.baidu.com/')
# 通过id定位搜索框,并输入selenium
driver.find_element_by_id('kw').send_keys('selenium')
2、name定位: find_element_by_name()
从上面定位到的搜索框属性中,有个name="wd"的属性,我们可以通过这个name定位到这个搜索框
# 通过name定位搜索框,并输入selenium
driver.find_element_by_name('wd').send_keys('selenium')
3、class定位:find_element_by_class_name()
从上面定位到的搜索框属性中,有个class="s_ipt"的属性,我们可以通过这个class定位到这个搜索框
# 通过name定位搜索框,并输入selenium
driver.find_element_by_class_name('s_ipt').send_keys('selenium')
4、tag定位:find_element_by_tag_name()
如果懂HTML知识,我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等...。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行
# 通过tag定位搜索框,并输入selenium, 此处必报错
driver.find_element_by_tag_name('input').send_keys('selenium')
5、link定位:find_element_by_link_text()
此种方法是专门用来定位文本链接的,比如百度首页右上角有“新闻”,“hao123”,“地图”等链接
# 通过link定位"新闻"这个链接并点击
driver.find_element_by_link_text('新闻').click()
6、partial_link定位:find_element_by_partial_link_text()
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
我们用这种方法来定位百度首页的“新闻”超链接
# 通过partial_link定位"新闻"这个链接并点击
driver.find_element_by_partial_link_text('闻').click()
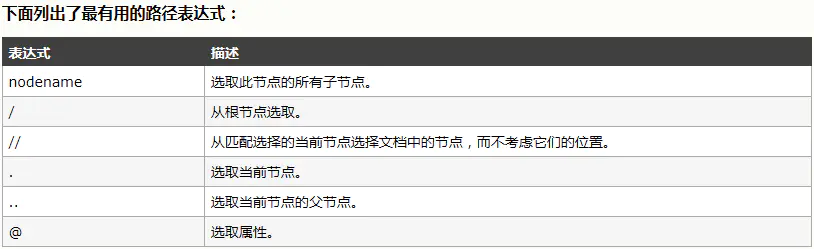
7、xpath定位:find_element_by_xpath()
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。

driver.find_element_by_xpath("//*[@id='kw']").send_keys('selenium')
//*input[@name="key"]
#元素定位-联合多个属性共同定位,逻辑表达式 -And查找
//*[@id="searchKey" and @name="key"]
#逻辑表达式 -Or查找
//book[@category=”web” or @cover=”paperback”]
#逻辑表达式 -非查找控件
//book[@category!=”web”]
#逻辑表达式 -Not查找
//year[not(.=2005)] 意思是:查找year内容不为2005的内容 注:“.”就等于text()
//book[not(@category=”children”)]
#元素定位-XPATH属性+标签+索引
//form/span[1]/inputsubstring(@class,3)='ipt']
模糊匹配
//form/span[1]/input[contains(@class,'ipt')]
//input[startwith]
精确匹配
//input[@value="查一下"]
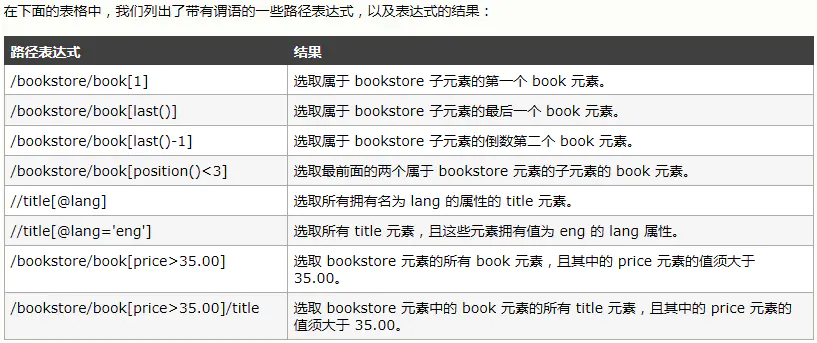
查找book对象
//book #所有的数
//book[1] #第一本书
//book[last()] 倒数第一本:
//表示从目录任意位置查找,/表示按照目录顺序查找
倒数第二本://book[last()-1]
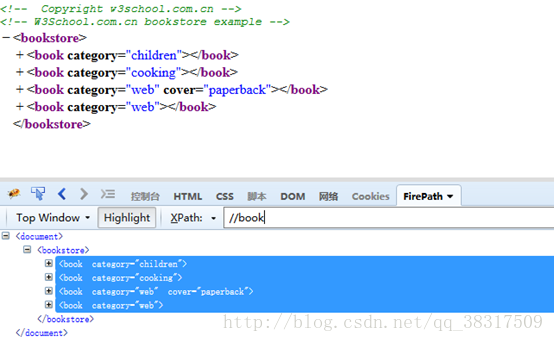
针对同一个元素下面多个相同的子标签和元素,如何定位多胞兄弟
//第一个元素 标签:first-chlid 如:a:first-chlid
//第二个或者n个元素 标签:nth-chlid(n) 如:a:nth-child(n)
//最后元素 标签:last-of-type
8、CSS定位
被测试的html代码: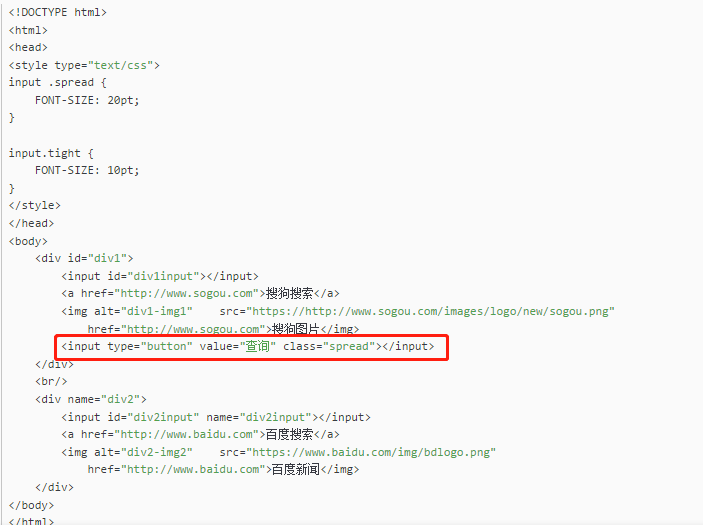
#使用绝对路径,根据层级定位,层级定位通过>或者空格隔开
CSS定位表达式:html>body>div>input[type='button']
webElement searchBox=driver.findElement(By.cssSelector("html>body>div>input[type='button']"))
#根据其他属性定位,则[属性值],如:
webElement searchBox=driver.findElement(By.cssSelector("input[type='button']"))
webElement searchBox=driver.findElement(By.cssSelector("input[value='查询']"))
根据id定位 使用#id属性值 如:"input#kw"
webElement searchBox=driver.findElement(By.cssSelector("input#div1input"))
定位获取多个元素:
elist=driver.find_element_by_css_selector("input#kw")
#根据class定位,使用.class属性值,如:"input.s_ipt"
webElement searchBox=driver.findElement(By.cssSelector("input.spread"))
使用页面其他属性值定位:
被测试网页中,查找div标签中第一张图片
CSS定位表达式:img[alt='div1-img1'][href='http://www.sogou.com']
定位语句:
webElement searchBox=driver.findElement(By.cssSelector("img[alt='div1-img1'][href='http://www.sogou.com']"))
使用页面元素属性值的一部分关键字定位
CSS定位表达式:a[href^='http://www.so'];表示匹配链接地址开头含有关键字的链接
a[href$='fou.com'];表示匹配链接地址结尾含有关键字的链接
a[href*='so'];表示匹配链接地址包含有关键字的链接
webElement searchBox=driver.findElement(By.cssSelector("a[href^='http://www.so']"))
webElement searchBox=driver.findElement(By.cssSelector("a[href$='fou.com']"))
webElement searchBox=driver.findElement(By.cssSelector("a[href*='so']"))
使用页面元素进行子页面元素的查询
CSS定位表达式:div#div1 > input#div1input
webElement searchBox=driver.findElement(By.cssSelector("div#div1 > input#div1input"))
使用伪类定位元素
被测试网页中,查找第一个div下的指定子页面元素
div#div1:first-child ;查找id为div1的div页面元素下第一个元素。
div#div1:nth-child(2) ;查找id为div1的div页面元素下的第二个元素。
div#div1:last-child ;查找id为div1的div页面元素下的最后一个元素。
webElement searchBox=driver.findElement(By.cssSelector("div#div1:first-child"))
webElement searchBox=driver.findElement(By.cssSelector("div#div1:nth-child(2)"))
webElement searchBox=driver.findElement(By.cssSelector("div#div1:last-child"))
查找同级兄弟页面元素
#表示ID属性值为div1的div页面元素下,查找input页面元素后面的同级链接元素
CSS定位表达式:div#div1 > input +a ;
#表示ID属性值为div1的div页面元素下,查找input页面元素和链接元素后面的同级图片元素
CSS定位表达式: div#div1 > input+a+img;
#表示ID属性值为div1的div页面元素下,查找input页面元素和某种类型页面元素后面的同级图片元素,*表示任意类型的页面元素。
CSS定位表达式:div#div1 > input + * +img ;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)