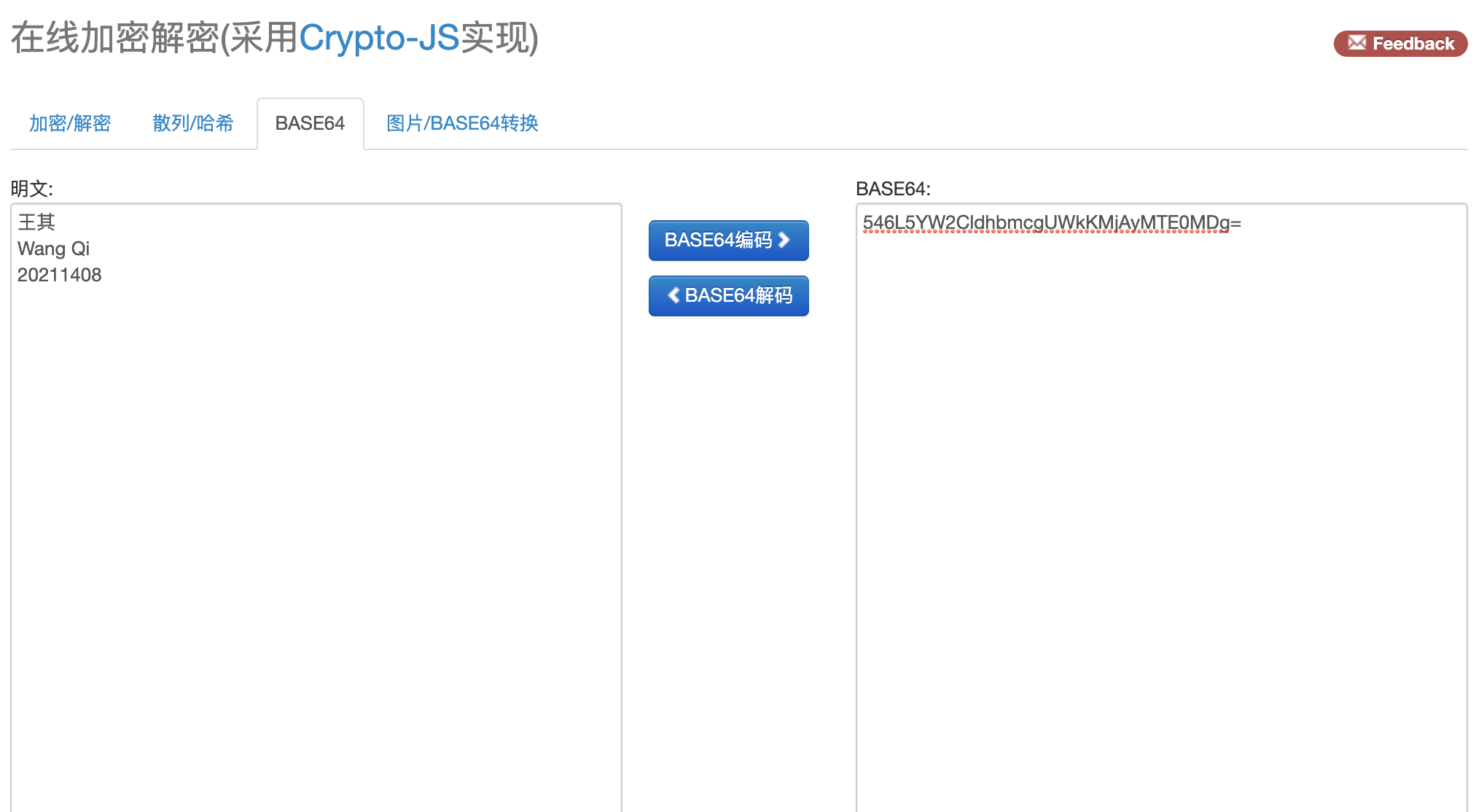
BASE64编码
BASE64编码
什么是BASE64编码,解决什么问题?
- 定义:是一种编码方式,Base64编码是从二进制到字符的过程,8Bit字节代码的编码方式之一;
- 特点:采用Base64编码具有不可读性,需要解码后才能阅读;
- 应用:可用于在HTTP环境下传递较长的标识信息;经常用作一个简单的
加密(编码不是加密!!!)来保护某些数据。
注:编码和加密的区别在于编码是通常希望别人解码的。而加密是不希望的。编码更多的是为了转换格式,加密是为了安全。解码,是编码的逆过程。解密,是加密的逆过程。
原理
- 转换表(摘自百度百科):
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
- 例子(摘自百度百科):
转换前 10101101,10111010,01110110
转换后 00101011, 00011011 ,00101001 ,00110110
十进制 43 27 41 54
对应码表中的值 r b p 2
所以上面的24位编码,编码后的Base64值为 rbp2
解码同理,把 rbq2 的二进制位连接上再重组得到三个8位值,得出原码。
(解码只是编码的逆过程,有关MIME的RFC还有很多,如果需要详细情况请自行查找。)
第一个字节,根据源字节的第一个字节处理。
规则:源第一字节右移两位,去掉低2位,高2位补零。
既:00 + 高6位
第二个字节,根据源字节的第一个字节和第二个字节联合处理。
规则如下,第一个字节高6位去掉然后左移四位,第二个字节右移四位
即:源第一字节低2位 + 源第2字节高4位
第三个字节,根据源字节的第二个字节和第三个字节联合处理,
规则第二个字节去掉高4位并左移两位(得高6位),第三个字节右移6位并去掉高6位(得低2位),相加即可
第四个字节,规则,源第三字节去掉高2位即可 - 原理(摘自百度百科):
转码过程例子:
3 * 8 = 4 * 6
内存1个字节占8位
转前: s 1 3
先转成ascii:对应 115 49 51
2进制: 01110011 00110001 00110011
6个一组(4组) 011100110011000100110011
然后才有后面的 011100 110011 000100 110011
然后计算机一个字节占8位,不够就自动补两个高位0了
所以有了高位补0
科学计算器输入 00011100 00110011 00000100 00110011
得到 28 51 4 51
查下对照表 c z E z
运行环境
- python
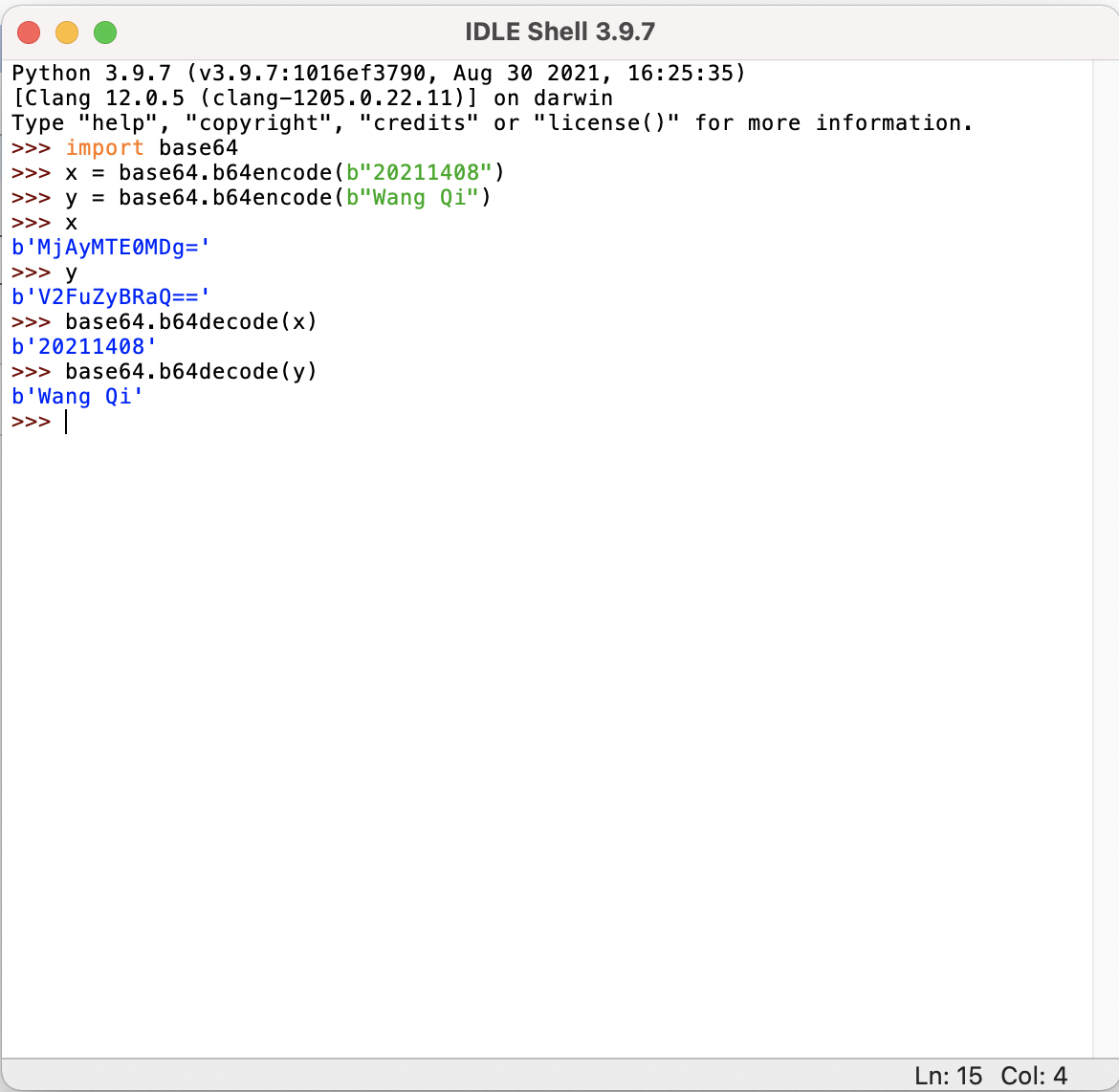
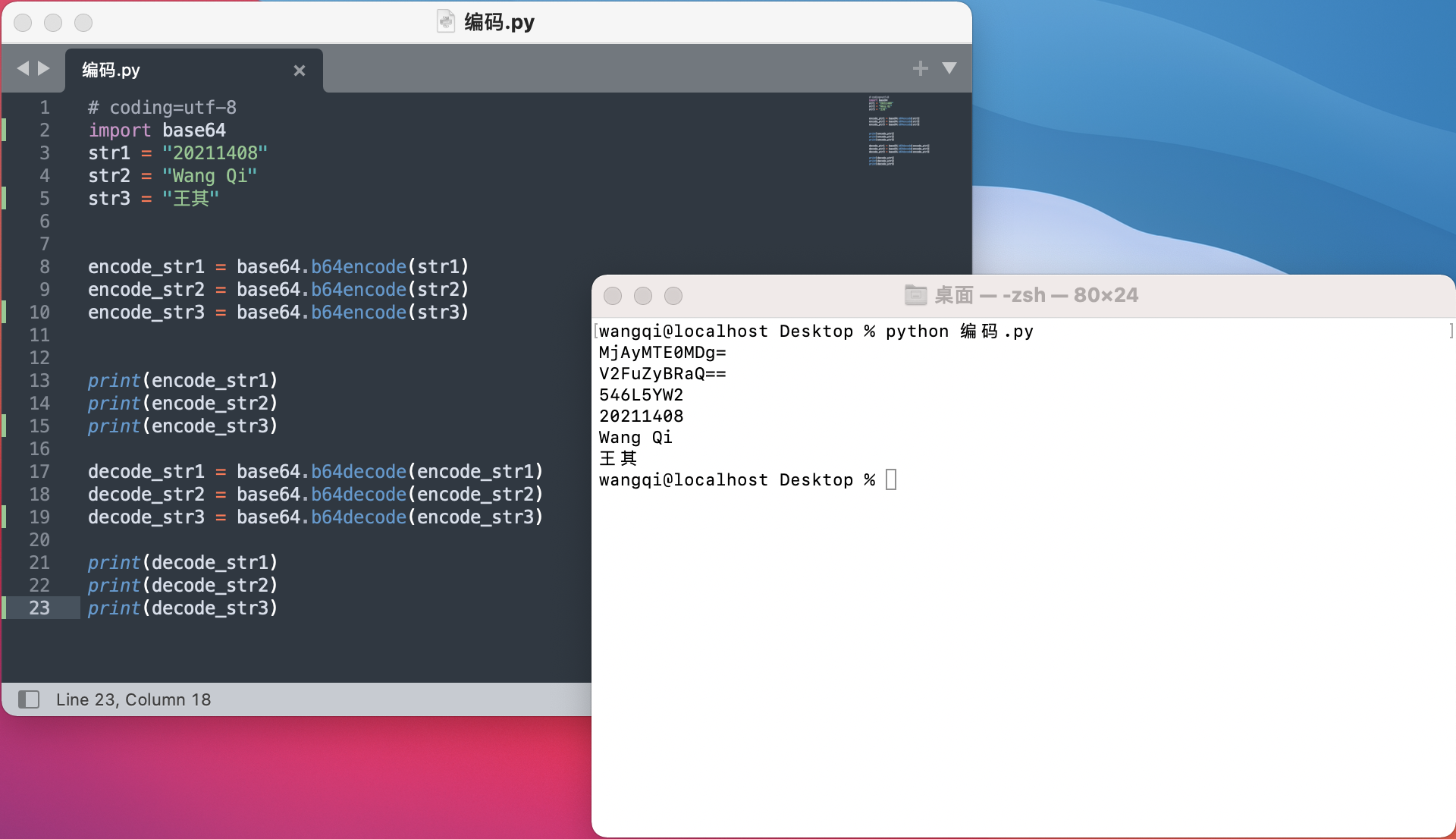
- 在线加密解密