

玩一玩“baichuan2”,很强的中文开源模型,2060s即可流畅运行!
OpenAI ChatGPT出来后,热闹了好一阵子!
先是一波大厂闭源PK。然后Meta不按套路出牌,直接放出来开源的Llama1-2
后来就百花齐放了。
但是外国的模型默认情况下中文支持都不好。
另外很多开源模型,最简单的对话都一塌糊涂。
今天来玩一个不错的中文开源模型。
先来简单看下本地运行的效果和速度。
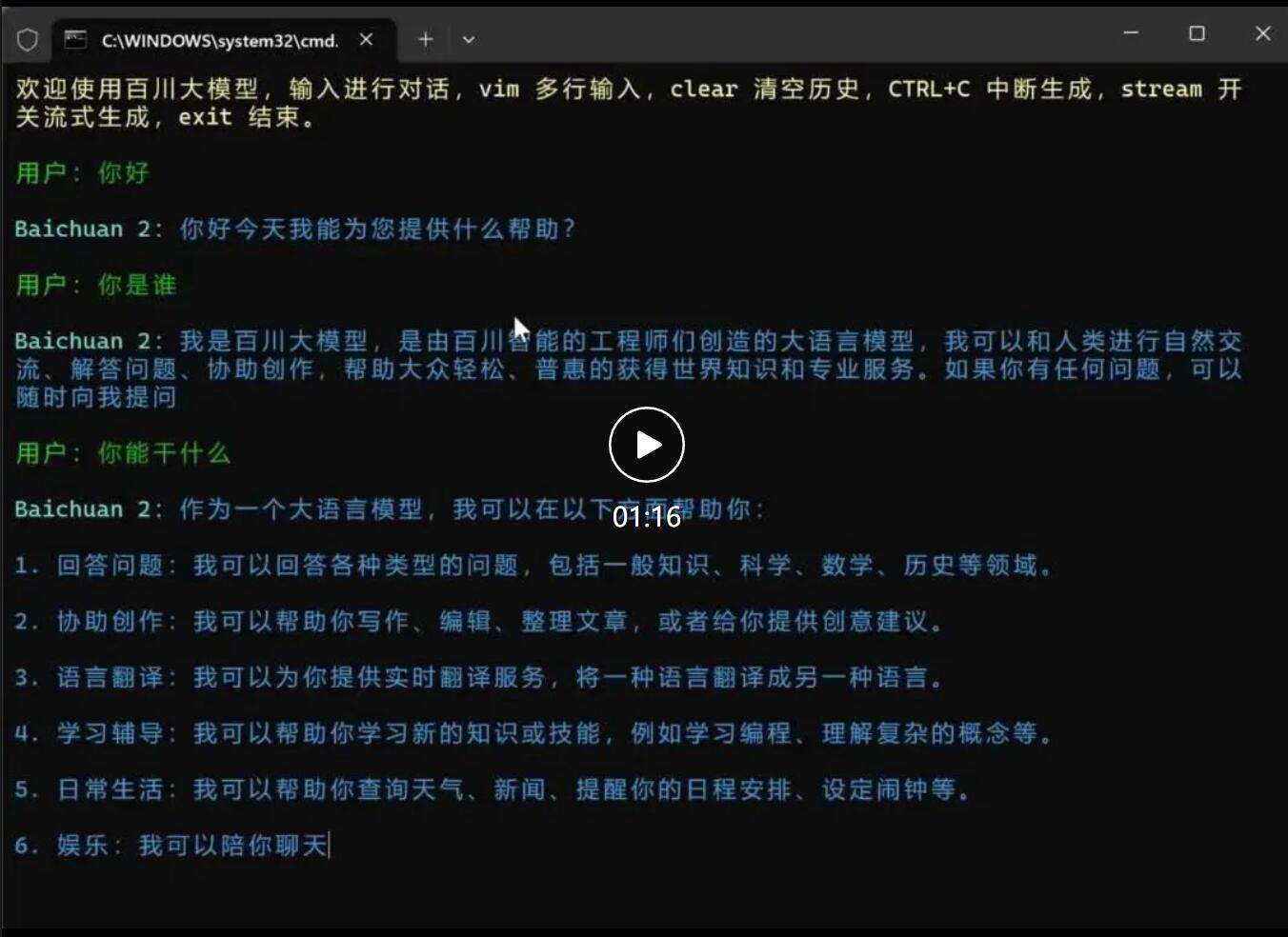
还不错吧。
我的感觉是,整体体验很不错!
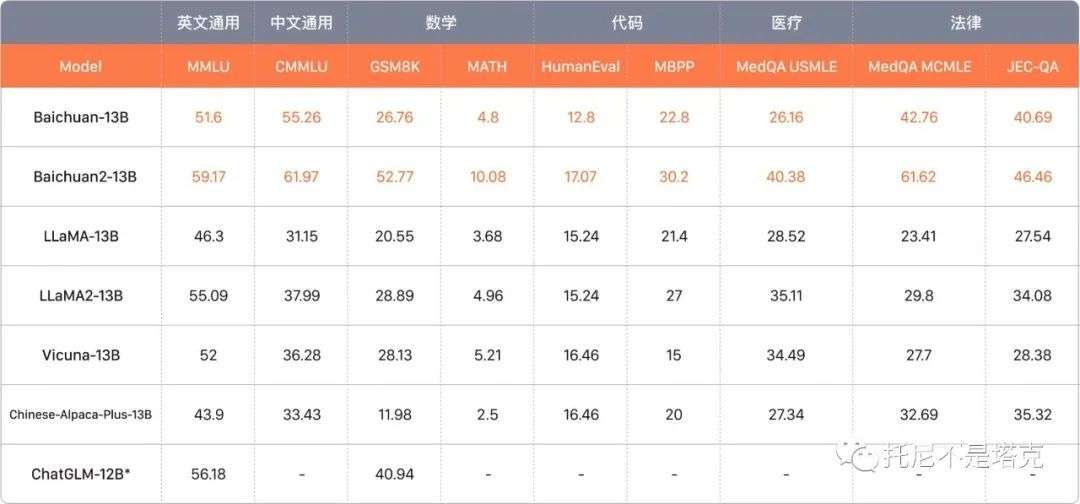
官方的测评数据来看也确实是有点强,另外这个项目文档完善,也比较容易上手。
官方的项目文档非常全面。

提供了简洁明了的模型介绍:
-
Baichuan 2 是百川智能推出的新一代开源大语言模型 2.6 万亿
-
Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳
-
本次发布包含有 7B13B Base Chat 4bits 量化
-
所有版本对学术研究完全开放。同时,开发者通过邮件申请并获得官方商用许可后,即可免费商用
提供了详细的测试结果。
提供了推理和部署的方法。
提供了模型微调的方法。
提供了各类型模型。
从开源项目的完成度来说,已经非常高了。
各类测评数据也非常全面。
能给出各类专业测评数据的项目肯定是有自信的项目。下面来看一看baichuan2.0的测试数据。
通用领域:
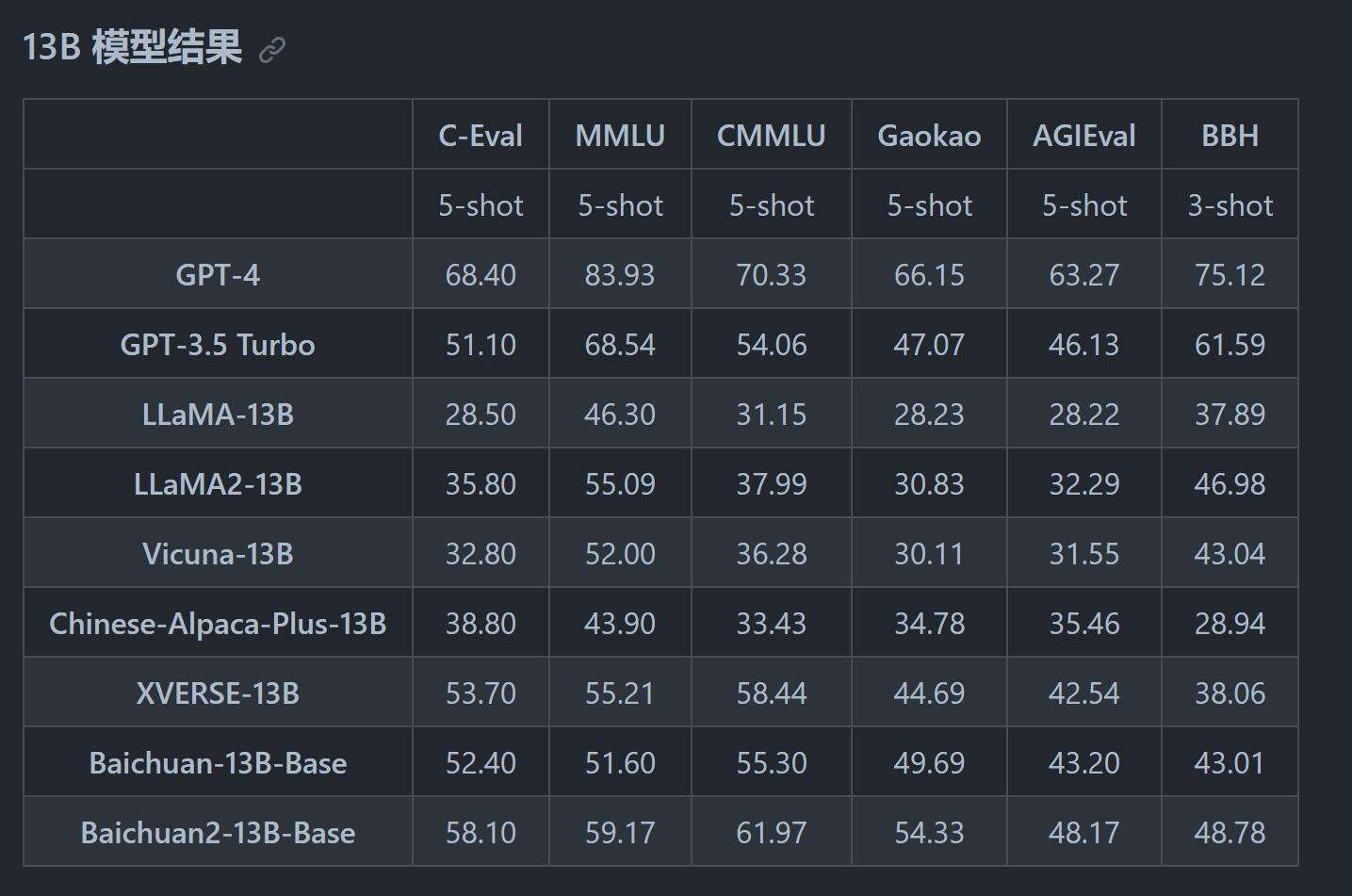
从上面可以看到,Baichuan2 13B在各项指标都超过了LLaMa12 ,而且是大幅度地提升。
相比GPT3.5各有胜负。毕竟这只是一个13B的模型,能达到这种程度,已经很厉害了。
除了通用领域之外,项目主页很多分类的测评。
法律医疗
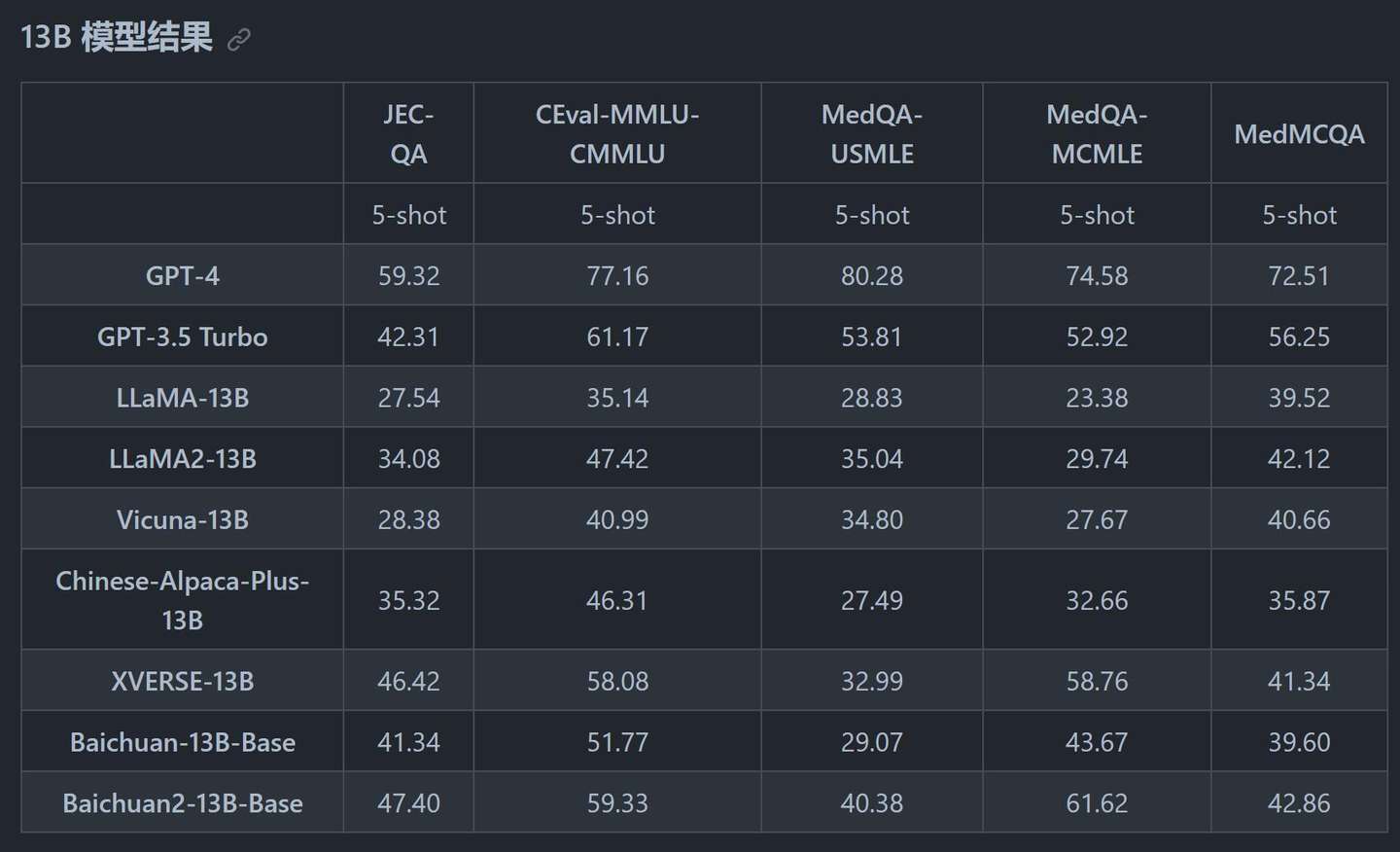
数学代码
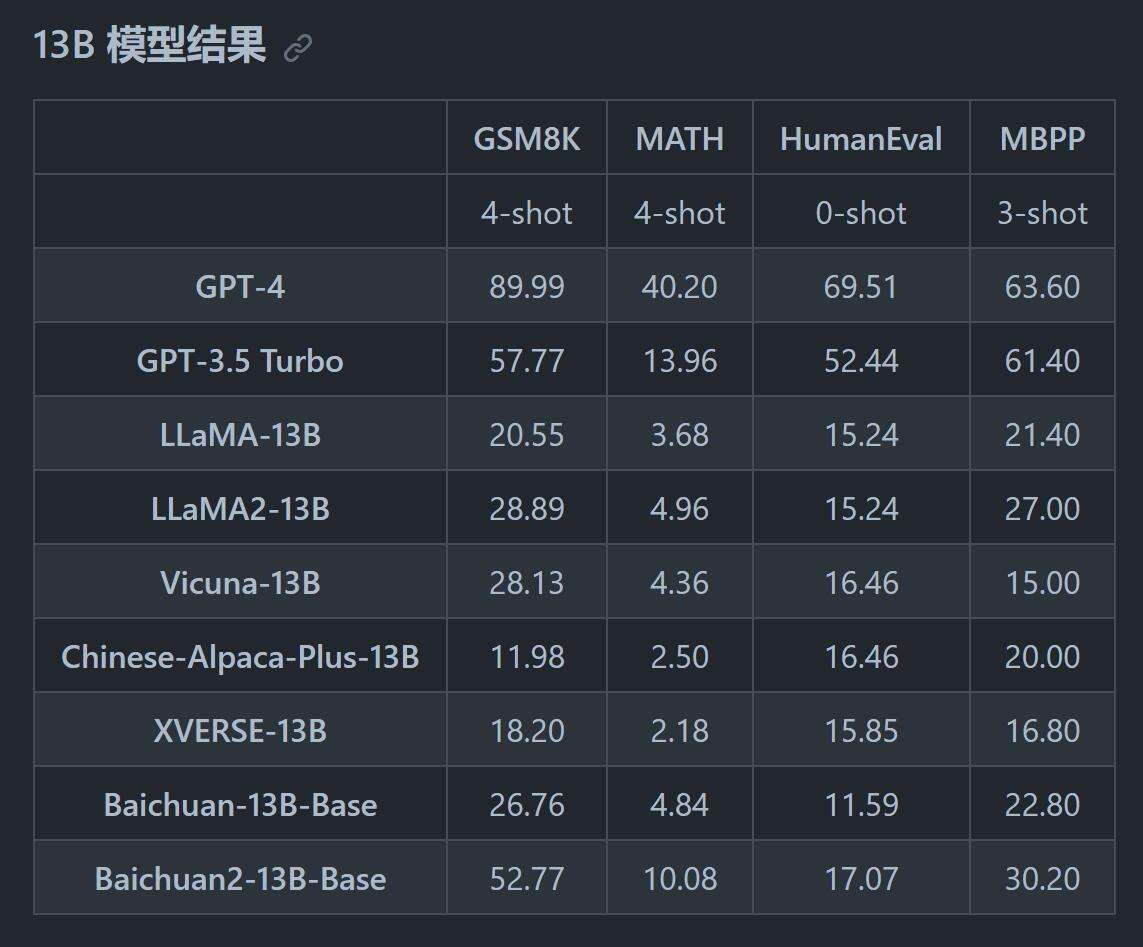
多语言翻译
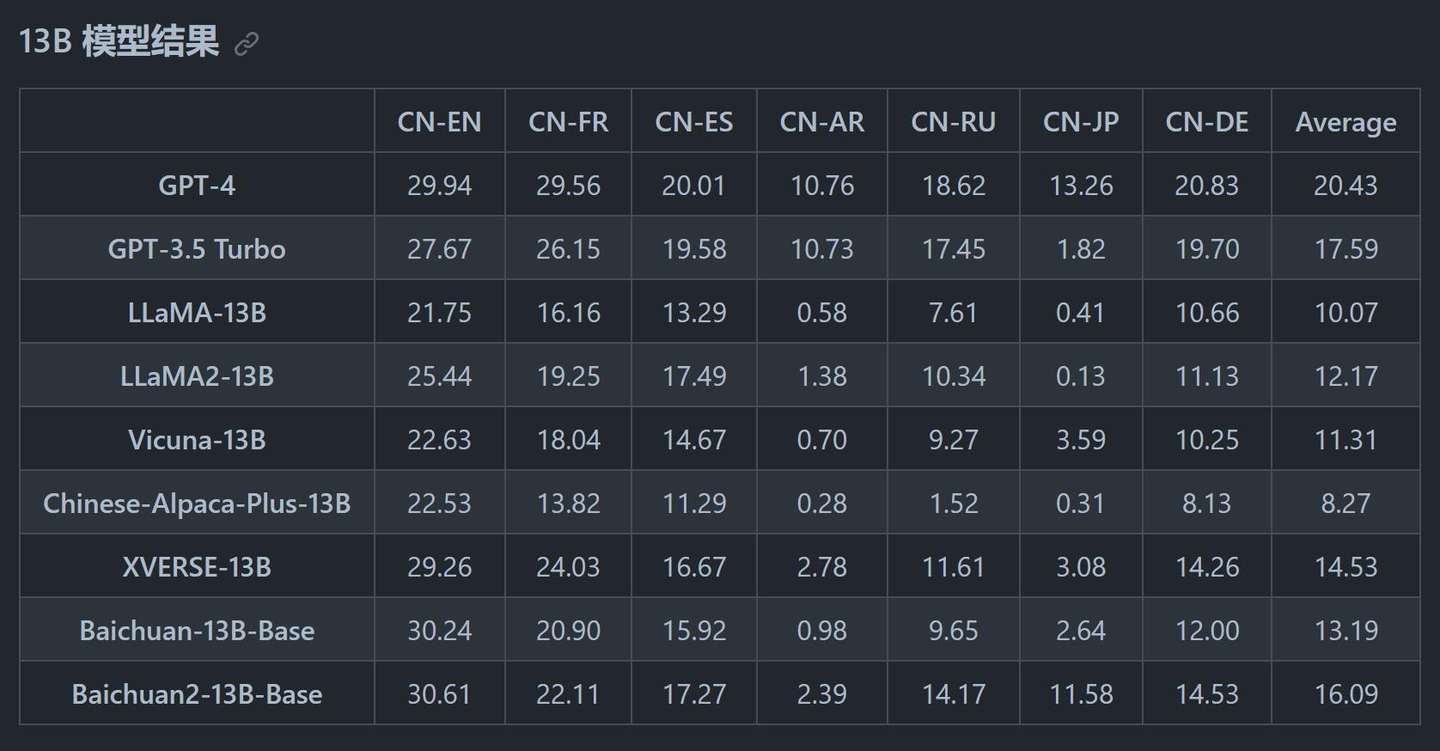
通过各项数据来看GPT-4依旧遥遥领先,但是Baichuan2和同级别开源模型来比,得分已经很不错了。
提供了4Bit量化模型只需要5.1GB显存。
模型好不好是一回事儿,能不能跑起来又是另外一回事儿。从运行的硬件要求上来说,百川还是比较友好。提供了4bit离线版模型,理论上一张6G显卡就能跑起来了,在咸鱼上500块就能搞定!实际上硬件要求比这个高一点点。
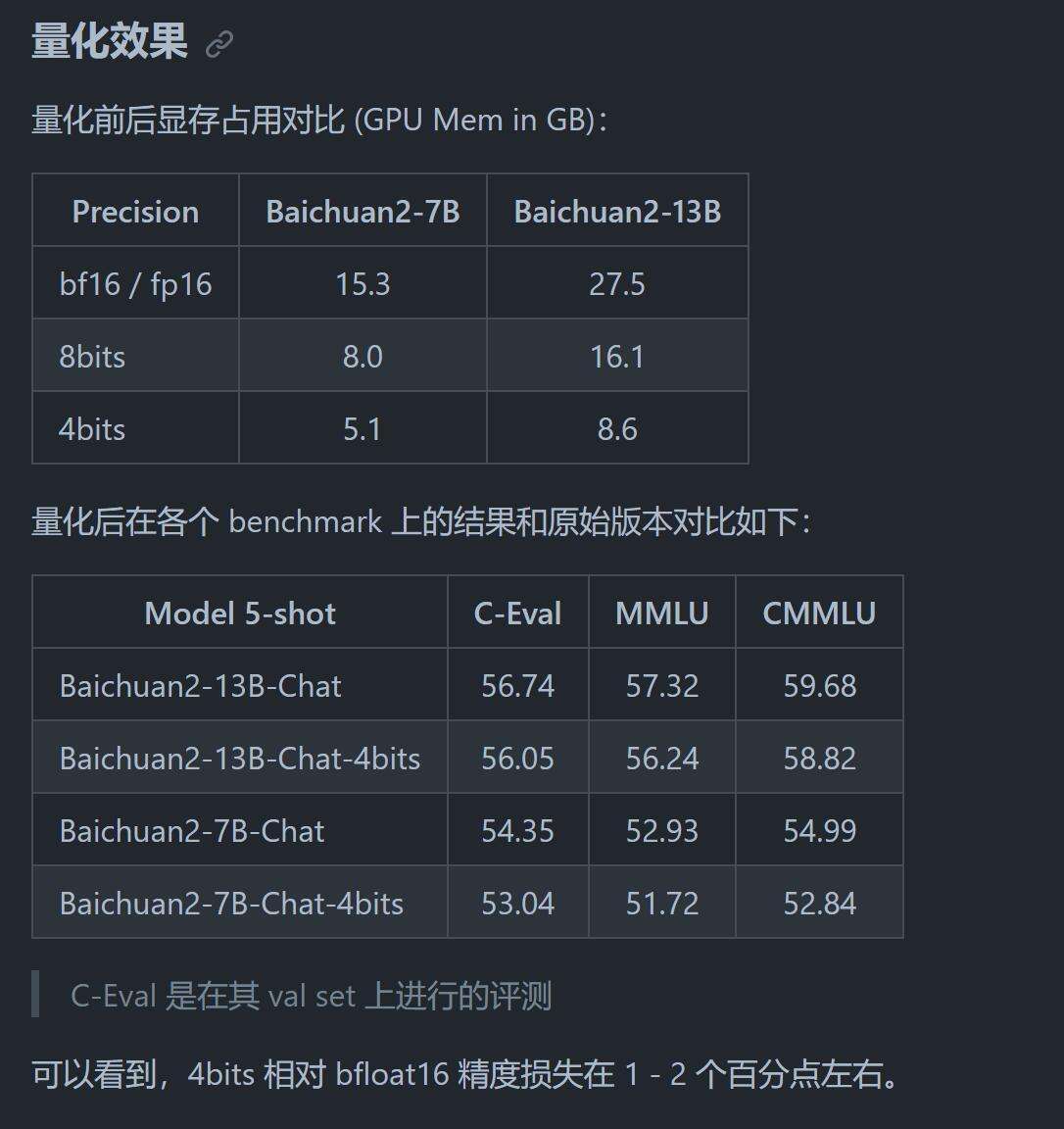
通过上面的图片可以看到,最低要求是5.1GB,13B的4bits量化也只要8.6G 这个配置不能说高了吧。
更重要的一点是,量化后,能力并没有减弱太多,大概下降1-2%的样子。
真的做到了,又让马儿跑,又少吃草。
基于以上因素,这完全是一个个人玩家也可以玩转的中文大语言模型。
介绍得差不多了,我们进入第二部分,本地安装。
先简单的说一下我本地环境:
操作系统 Win11
显卡 RTX3060 12G
基础软件 Conda,Git,魔法!
然后来介绍一下我配置安装的完整步骤,大概用了1个小时,全部搞定。这其中大部分时间是花在了下载模型上面。话说回来4Bit是真香,模型小了好多好多好多。否则,动不动几十上百G,搞起来累得不行!
下面就按我探索的过程来讲一下步骤,安装前完整没有看任何教程,都是走一步,错一步,就改一步。
1.克隆源代码
常规操作
git clone https://github.com/baichuan-inc/Baichuan2.git
包代码拷贝到本地。
2.创建虚拟环境并激活
常规操作
conda create -n baichuan2 python=3.10
创建一个名为baichuan2的虚拟环境,Python版本为3.10 。创建成功后,激活这个虚拟环境。
3.安装依赖
进入项目目录,并安装依赖。
cd baichuan2
4.安装量化包
使用4bits的话,需要安装这个量化包,默认安装的包不行!
python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
5.安装加速包
pip install xformers
6.安装PyTorch 2.0.1
这个东西肯定肯定少不了。
torch==2.0.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
文件比较大,下载可能有困难,可以设置pip镜像加速。
7.修改代码,4bit量化!
改一下代码
def init_model(): model = AutoModelForCausalLM.from_pretrained("Baichuan2-7B-Chat-4bits", device_map="auto", trust_remote_code=True) model.generation_config = GenerationConfig.from_pretrained( "Baichuan2-7B-Chat-4bits" ) tokenizer = AutoTokenizer.from_pretrained( "Baichuan2-7B-Chat-4bits", use_fast=False, trust_remote_code=True ) return model, tokenizer
如果不改代码,我打打包票没有几张卡能跑得起来。所以,这里改代码完全是为了,降低设备要求。
8.下载模型和配置文件
下载最好分两步,一步下载所有小文件。
git lfs install set GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bits
然后打开网址,单独去下载模型文件。
使用git命令一次性下载模型,往往容易卡住,下载时间不可控。
9. 运行
全部准备好之后,就可以运行demo了。
python cli_demo.py
量化版因为模型比较小,启动挺快。启动后第一次对话会稍微慢一点,后面就好了。
运行效果如下:

在RTX3060 12G上启动后大概消耗7GB显存,对话过程中增加到9GB,然后一直到11.6GB。然后就不再变化了。可以流畅对话。
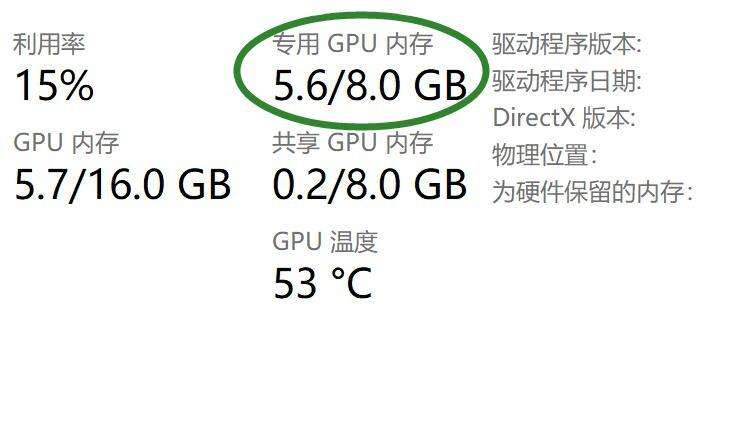
2060s 8G 上面也可以运行,启动后用了5.6G,减去默认消耗,和官方数据差不多。启动后,可以流畅对话!
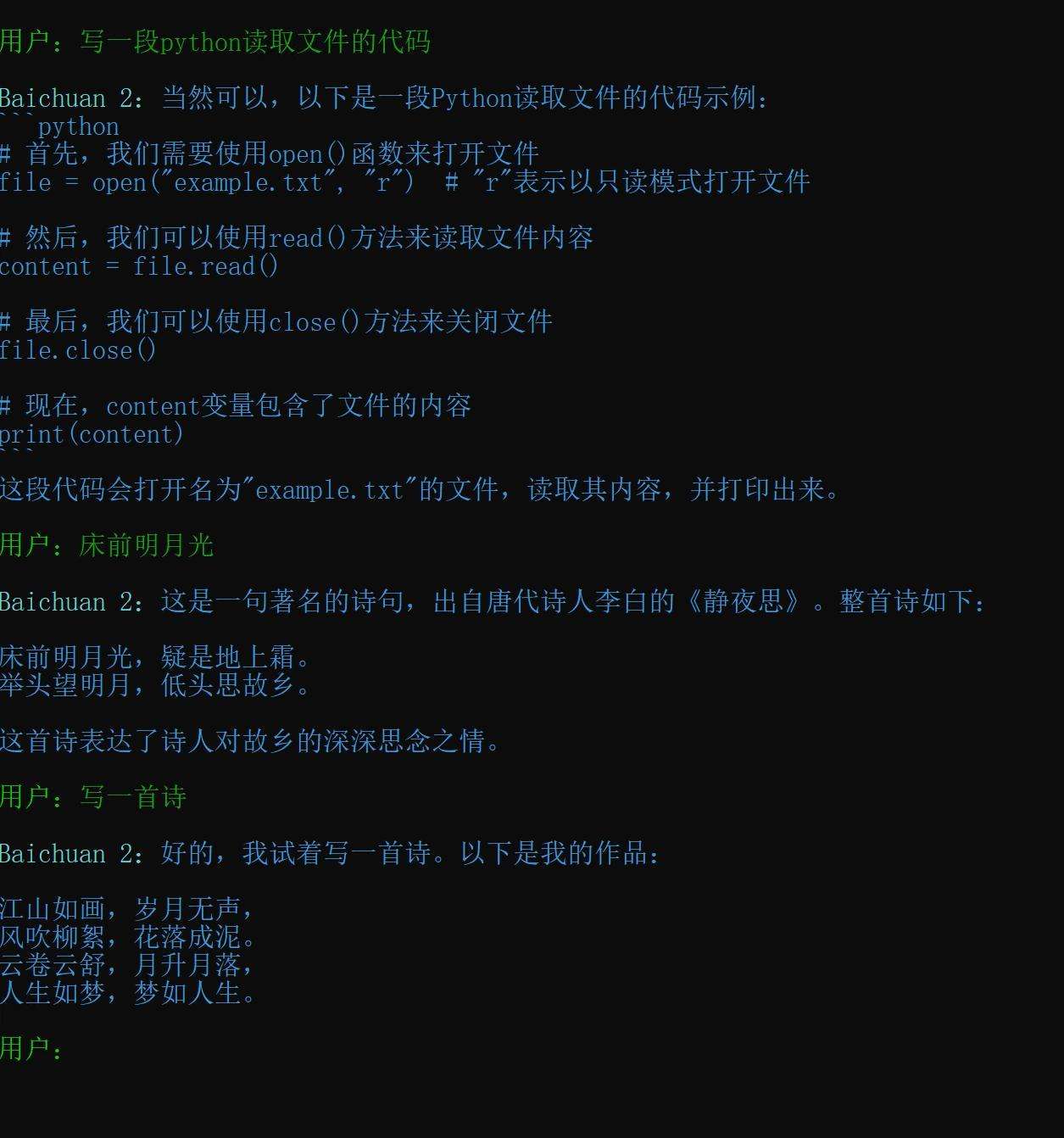
3090上跑了7B(70亿参数),7b-4bit量化,13B-4bits量化。都可以跑,但是不量化,聊天有点卡。量化后70亿和130亿都还快到飞起。
整个对话过程非常流畅,也没有明显的胡说八道,整体逻辑通顺。
一张图普普通的游戏卡就能把一个不错的LLM跑起来,并且流畅运行,这已经很不错了。
更加不错的是,这个可以免费商用哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号