
玩一玩通义千问Qwen开源版,Win11 RTX3060本地安装记录!
大概在两天前,阿里做了一件大事儿。

就是开源了一个低配版的通义千问模型--通义千问-7B-Chat。
这应该是国内第一个大厂开源的大语言模型吧。
虽然是低配版,但是在各类测试里面都非常能打。
官方介绍:
Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。本仓库为Qwen-7B-Chat的仓库。
同时官方也给出了很多测试结果。
比如中文评测。
在C-Eval验证集上得分对比:
如果单看这个数据。说“吊打”同级别羊驼模型一点不夸张吧。比起热门的开源模型ChatGLM2也高出了不少。
除此之外还有:
英文测评(南玻王)
代码测评(南玻王)
数学测评(南玻王)
长序列测评(南玻王)
工具使用能力测评
全方位碾压同类70亿参数模型,在即将开源的、用于评估工具使用能力的自建评测基准上,居然K·O了GPT-4 哈哈。
我也不太懂,没研究过这个基准测试,反正就是看起来很厉害的样子。
不管怎么样,大厂开源的东西总不会太差。有可能真的是最好的小型中文大语言模型了。
阿里已经亮出态度了,接下来压力给到百度,讯飞,华为... 哈哈~~
既然阿里都开源了,那我们自然就笑纳了,接下就在本机跑一个试试。
下面是我在Win11 RTX3060 12G 上完整的安装记录。玩过的可以跳过,没玩过的可以当个参考。
我的安装思路完全来自官网指引:
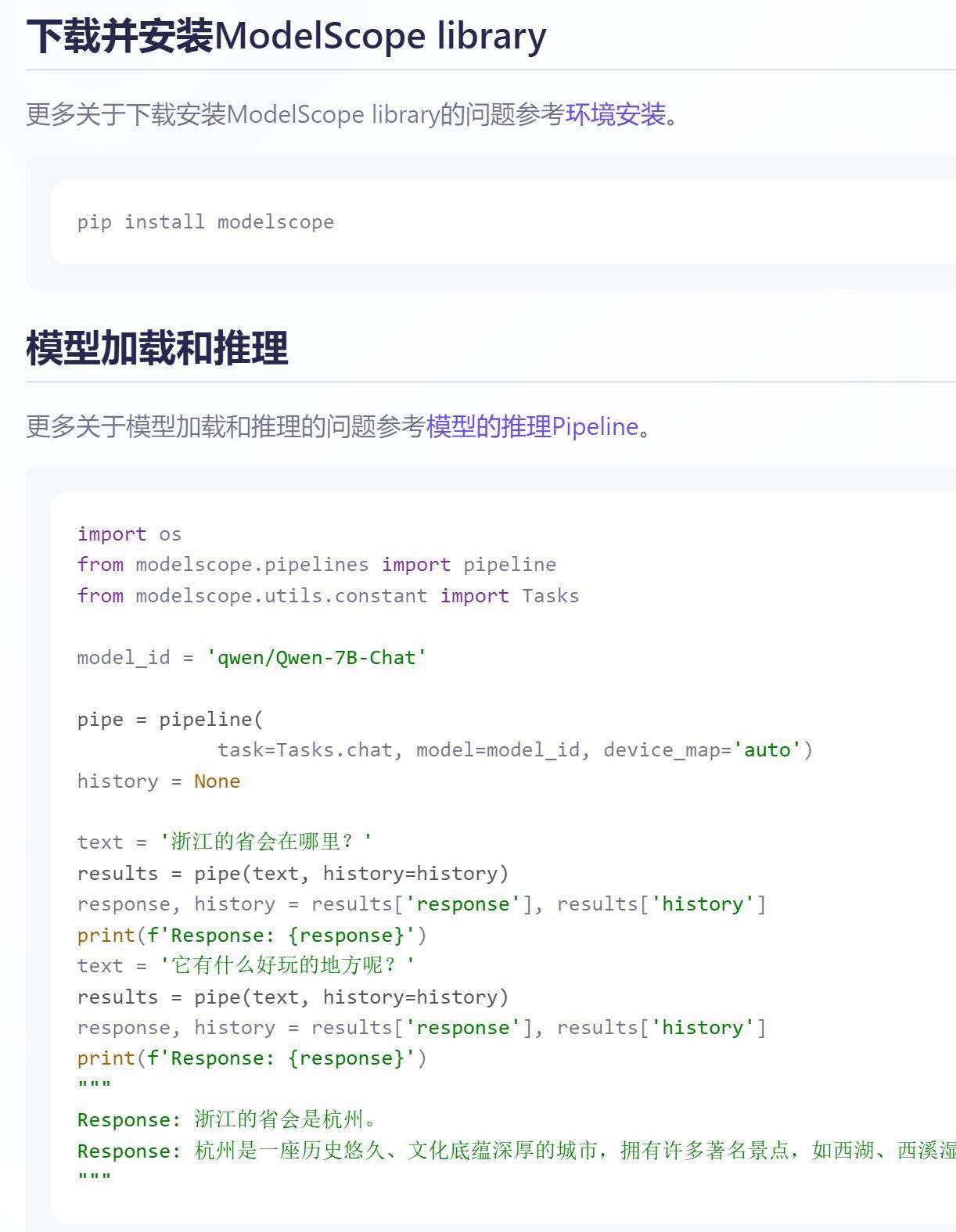
官方的安装指引看起来非常简单。只要安装一下modelscope这个包,然后运行一段Python代码就可以了。当然,这个世界上看起来简单的东西,做起来往往都不那么简单。一步一坑是常态,踩过了,就简单了。
常规流程
1.创建并激活虚拟环境。
我们还是用常用的MiniConda来创建一个虚拟的Python环境。
conda create -n models python=3.10.6
激活激活虚拟环境:
conda activate models
2. 安装modescope基础库
pip install modelscope
3. 编写Python代码
不需要自己编写啊,直接抄官方代码。
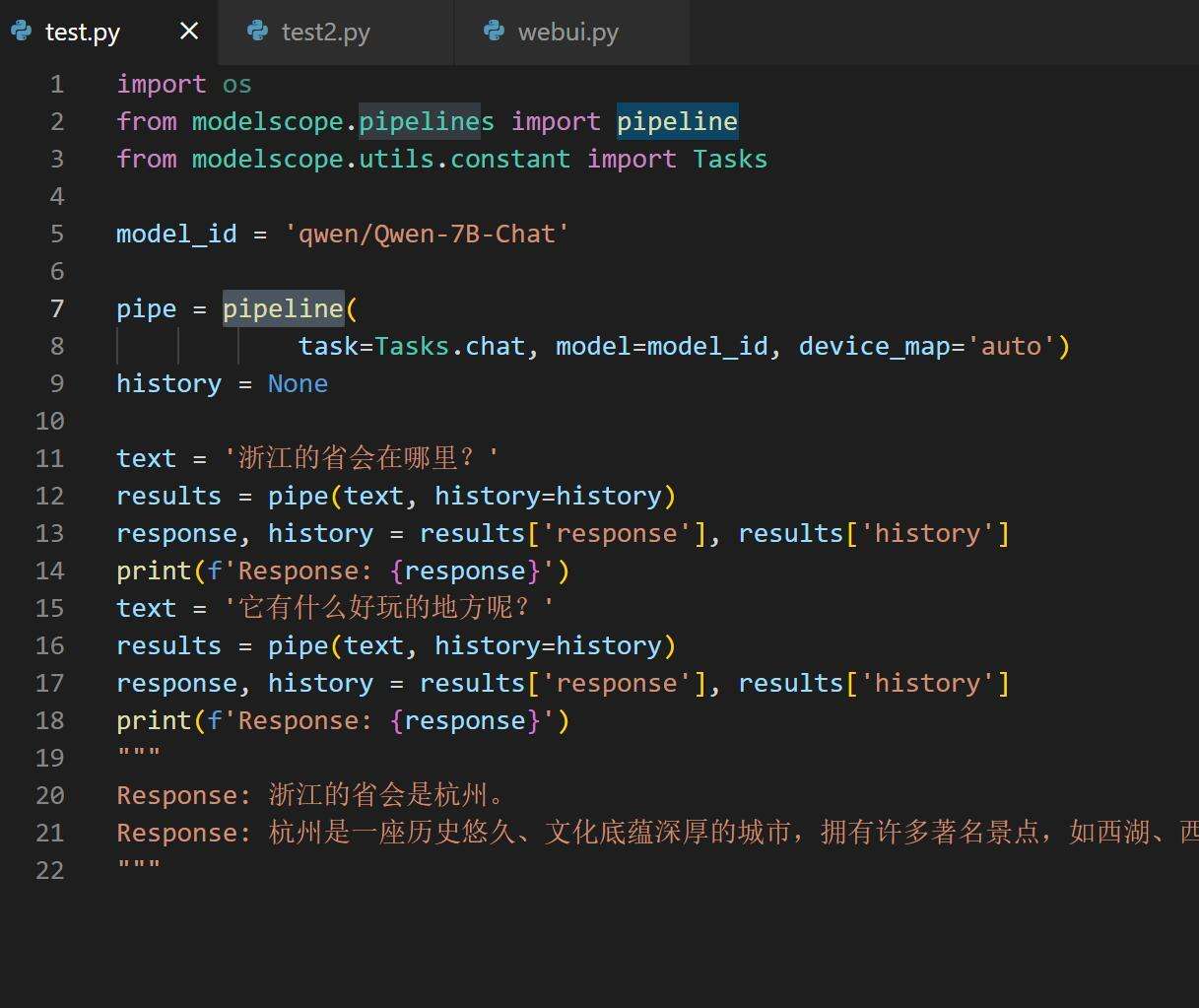
创建一个test.py文件,然后将代码粘贴到里面,Ctrl+S 保存代码。
4.运行代码
运行代码也非常简单。上面已经激活了虚拟环境。然后用cd命令,进入到代码所在目录。然后用Python运行就可以了。
E:cd E:\DEV\qwen python test.py
运行代码之后,会自动联网下载一个14G的模型文件。
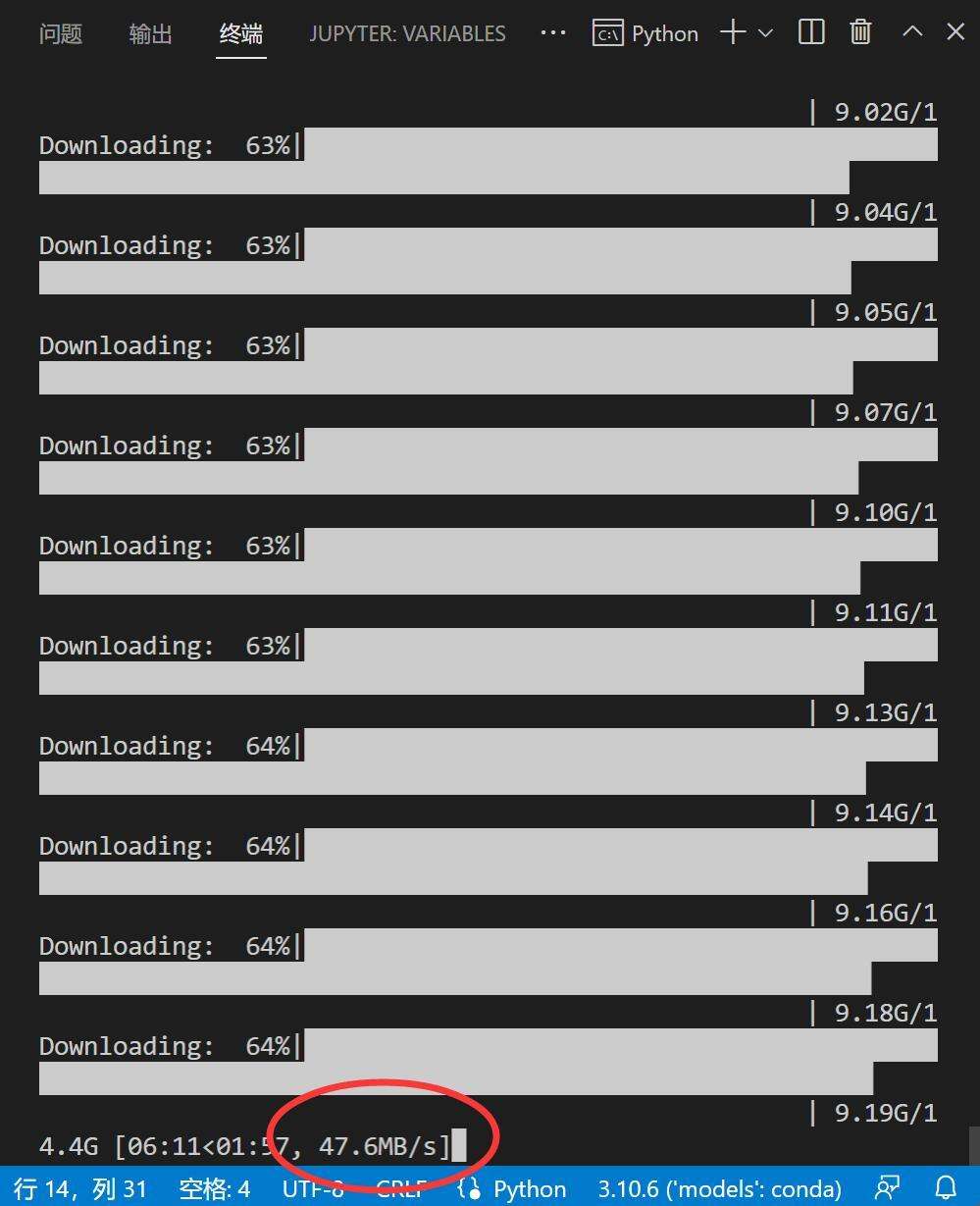
阿里毕竟是做服务器的,我又在杭州,这速度真的是真是相当给力。不用魔法,就能飞起,这是搞国外项目,永远享受不到的待遇啊。
按正常的节奏来说,下载完大模型,然后运行代码。通义千问大模型就会乖乖的回答我预设的两个问题了。
但是...不可能这么顺利。
其实还有很多包还没装完,我就按我出错的顺序和解决方法,一个个来记录吧。
踩坑记录
1.缺少transformers包
提示信息如下:
ImportError:modelscope.pipelines.nlp.text_generation_pipeline requires the transformers library but it was not found in your environment. You can install it with pip:pip install transformers
解决方法很简答,运行提示中的命令即可:
pip install transformers
2. 缺少tiktoken包
提示信息如下:
modelscope.models.nlp.qwen.tokenization requires the tiktoken library but it was not found in your environment. You can install it with pip:
解决方法:
pip install tiktoken
3.缺少accelerate包
提示信息如下:
ImportError: QWenChatPipeline: QWenForTextGeneration: Using low_cpu_mem_usage=True or a device_map requires Accelerate: pip install accelerate
解决方法:
pip install accelerate
4.爆显存了OutOfMemory
终于所有包都装完了。
再次运行test.py
软件有条不紊的运行,好像有戏。可惜,最终还是卡在硬件配置上了。
见到了熟悉的OutOfMemory。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.16 GiB (GPU 0; 12.00 GiB total capacity; 9.99 GiB already allocated; 200.79 MiB free; 9.99 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
在大语言模型面前,12G显存,啥都不是。
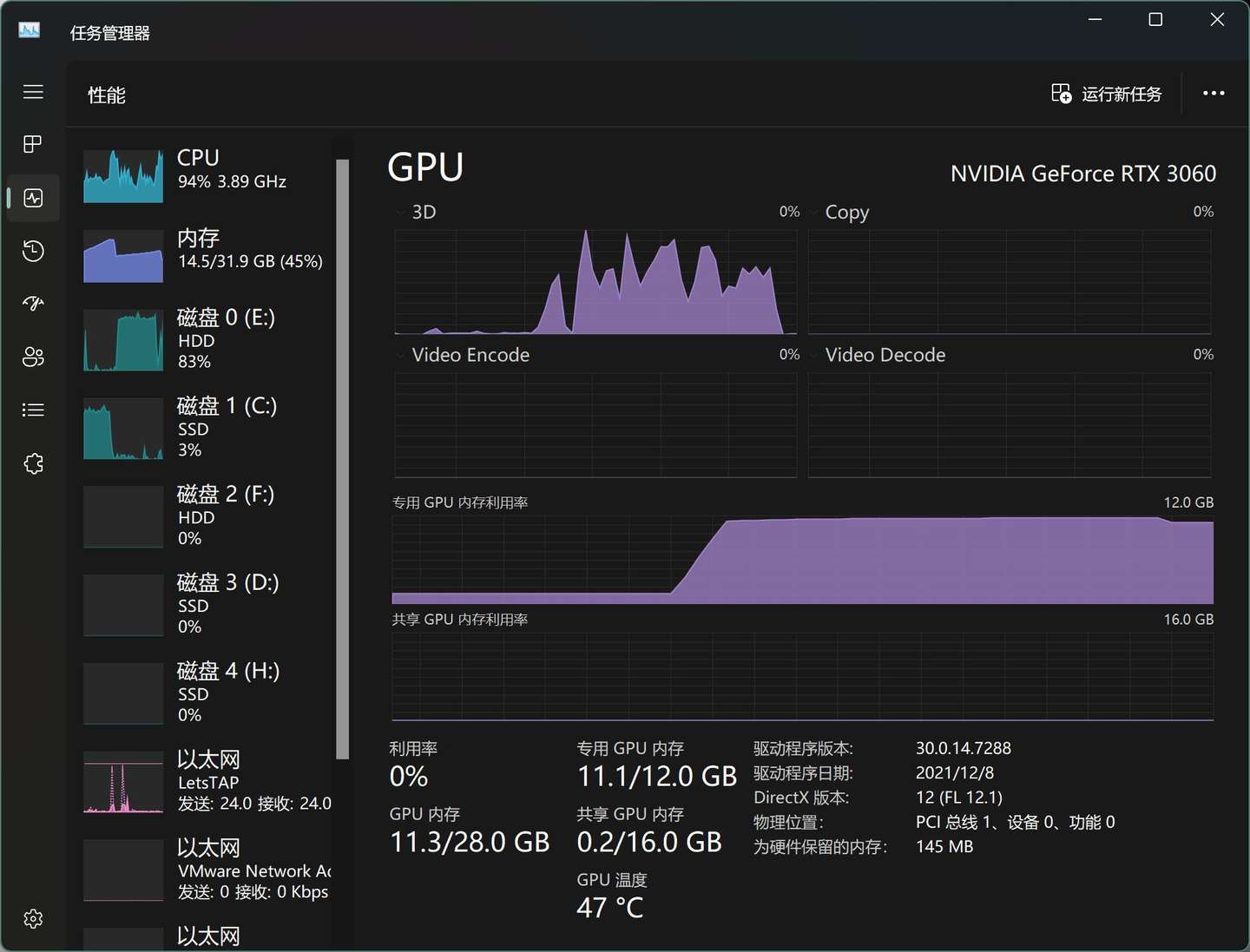
查了一下资料,BF16需要16.2G显存才可以运行...
遇到这种情况,没啥办法,只能用量化。官方也提供了4bit量化的代码,直接拷贝过来,搞了一个test2.py文件。
5. 运行4bit量化代码出错
错误提示如下:
importlib.metadata.PackageNotFoundError: No package metadata was found for bitsandbytes
大概就是量化的时候需要用到一个叫bitsandbytes的依赖包。
那就安装一下呗:
pip install bitsandbytes
安装非常简单快速,没有任何问题。
6. 量化包不支持Windows
安装完依赖之后运行test2.py 很快就收到了如下错误:
CUDA Setup failed despite GPU being available. Please run the following command to get more information:
这句话对于对于一个英语只过了4级的人有点难度啊。什么叫尽管有可用的GPU但是CUDA设置失败.... 你这句式是不是等价于,你有一个女朋友,但是不能用!
查了一下资料,bitsandbytes库目前仅支持Linux发行版,Windows目前不受支持。。。
还好上面的资料已经过时了,其实已经有大佬做了Windows版本。
7. Windows版量化包版本太低
为了解决上面一个的问题,找到了一个Windows版本的依赖包。
安装命令如下:
pip install git+https://github.com/Keith-Hon/bitsandbytes-windows.git
安装完成之后,本以为完事大吉了。
还是太年轻...
错误提示如下:
ValueError: 4 bit quantization requires bitsandbytes>=0.39.0 - please upgrade your bitsandbytes version
这个问题出在两个方面,一个是这个包好像只支持8bit量化,而我代码里有用的是4bit。另外一个问题就是错误日志中提到的版本太低。
没办法,又是一顿乱找,狂开N个网页。
最后最终找到了可以用的版本。
安装命令:
python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
终于安装成功0.41版本
8 缺少transformers_stream_generator包
习惯了,习惯了。上面的都搞完了,又出现缺包提示。
ImportError: This modeling file requires the following packages that were not found in your environment: transformers_stream_generator. Run `pip install transformers_stream_generator`
解决方法:
pip install transformers_stream_generator
9. Numpy不可用。
所有包装完之后,运行test2.py,眼看这要成功了,又跳出一个“Numpy is not available” 。
用pip list 查看了一下包列表,明明有这个包,怎么就不能用呢?
不管了,直接更新有一把看看。
把Numpy升级到最新版 :
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy --upgrade
安装过程出现红色提示:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
内心凉了一半。
提示里面说modelscope需要的是1.22, 但是我装了1.25.2... 最怕就是这种版本问题了...
我也不知道该怎么排查,想着就死马当活马医了。
最后...居然成功了,这是~~什么道理~~!
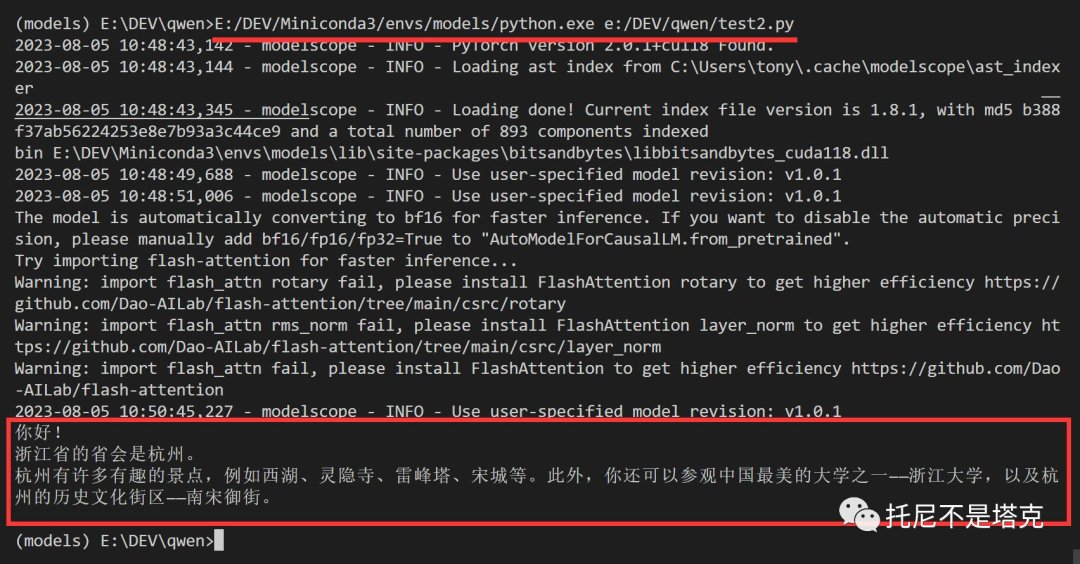
通过日志可以看到,AI已经做出了回答。答案也正确且通顺。幸福来的太突然...
到这里,我就成功的在我的Rtx3060 12G上面把“通义千问”给跑起来了。理论上所有的8G N卡也能跑起来!
成功后,心态就平稳很多了,半天功夫没白费,美滋滋。
趁热打铁,抽个几分钟来测试一下运行速度。
start:2023-08-05 11:06:54.399781;
加载模型用了好几分钟,回答问题大概只用了几秒钟。还不错啊,这速度基本能用了。
按上面的方式运行代码,AI只能回答预设的几个问题。这样搞起来就有点不爽,每次提问,还得改源代码,重新加载模型...
所以我又花了几分钟,写了一个WebUI。
界面如下:
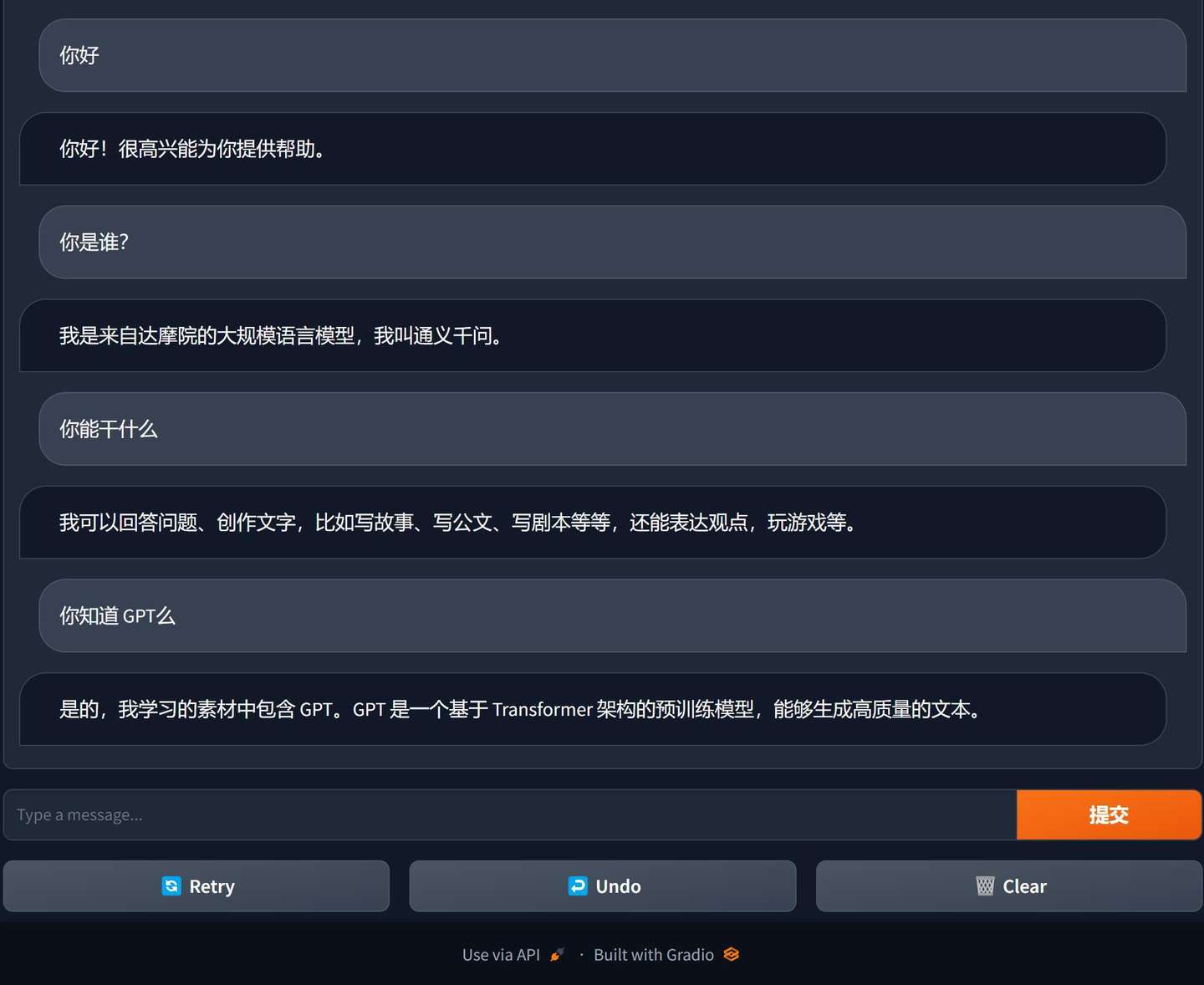
写这个界面和功能,大概只用了23行Python代码。Gradio这东西用起来确实爽,怪不得那么多开源项目都用这个来做界面。
心满意足了!!!
有没有看到这里,还是一头雾水的人?哈哈!
那么我就提供一个无需配置,无需登录,直接可以体验的网址把:
https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary
通义千问官方主页:
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
有兴趣的可以去玩一玩!
收工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号