

实验五:全连接神经网络手写数字识别实验
【实验目的】
理解神经网络原理,掌握神经网络前向推理和后向传播方法;
掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
1.使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
修改神经网络的学习率,观察对训练和检测效果的影响;
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
代码:
pip install torch

pip install torchvision
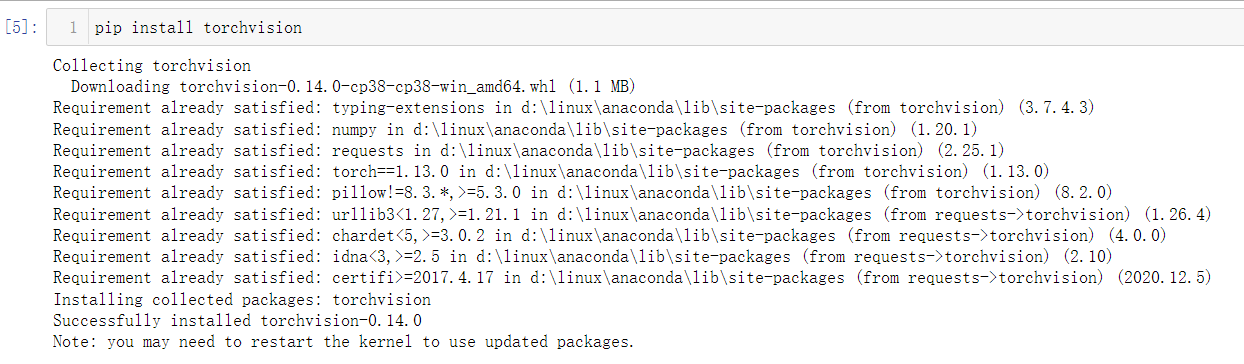
1 import torch 2 import numpy as np 3 from matplotlib import pyplot as plt 4 from torch.utils.data import DataLoader 5 from torchvision import transforms 6 from torchvision import datasets 7 import torch.nn.functional as F
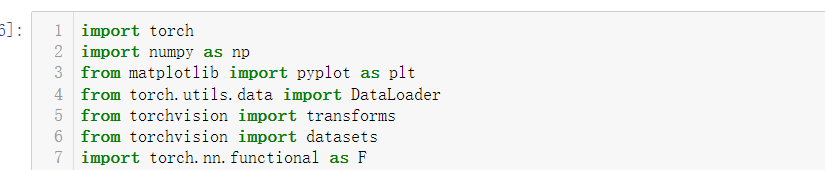
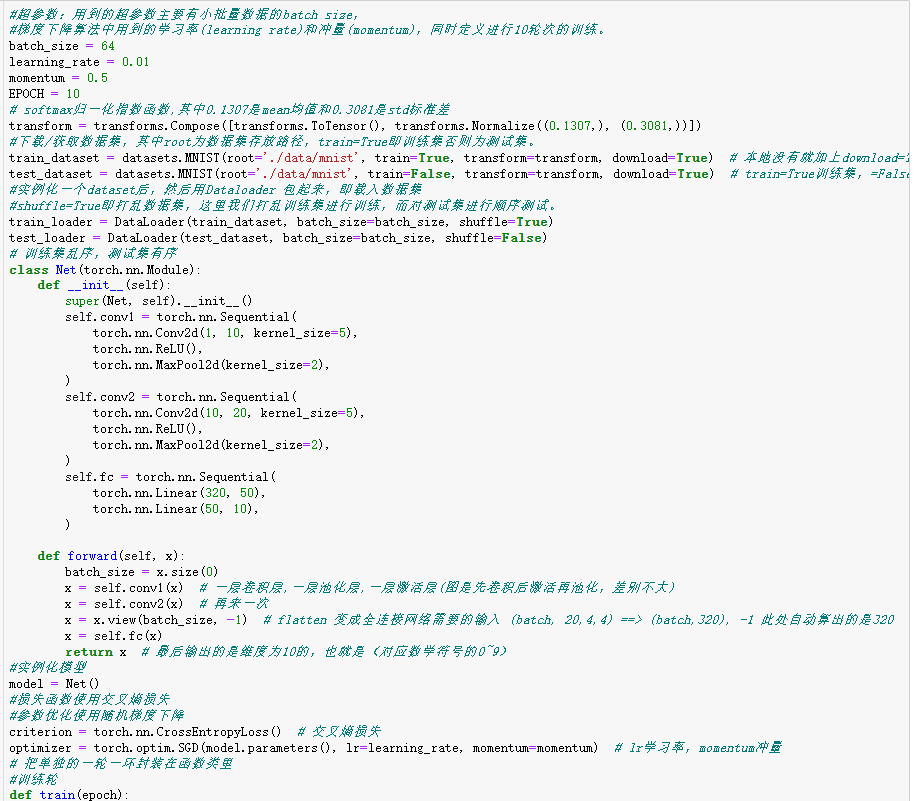
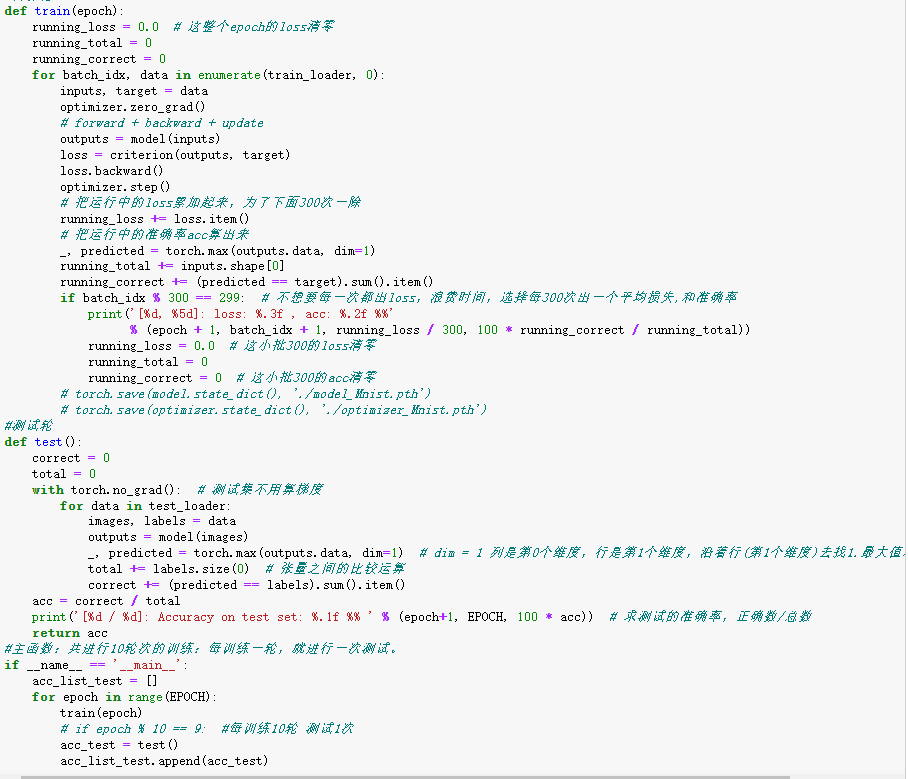
1 #超参数:用到的超参数主要有小批量数据的batch size, 2 #梯度下降算法中用到的学习率(learning rate)和冲量(momentum),同时定义进行10轮次的训练。 3 batch_size = 64 4 learning_rate = 0.01 5 momentum = 0.5 6 EPOCH = 10 7 # softmax归一化指数函数,其中0.1307是mean均值和0.3081是std标准差 8 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) 9 #下载/获取数据集,其中root为数据集存放路径,train=True即训练集否则为测试集。 10 train_dataset = datasets.MNIST(root='./data/mnist', train=True, transform=transform, download=True) # 本地没有就加上download=True 11 test_dataset = datasets.MNIST(root='./data/mnist', train=False, transform=transform, download=True) # train=True训练集,=False测试集 12 #实例化一个dataset后,然后用Dataloader 包起来,即载入数据集 13 #shuffle=True即打乱数据集,这里我们打乱训练集进行训练,而对测试集进行顺序测试。 14 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) 15 test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) 16 # 训练集乱序,测试集有序 17 class Net(torch.nn.Module): 18 def __init__(self): 19 super(Net, self).__init__() 20 self.conv1 = torch.nn.Sequential( 21 torch.nn.Conv2d(1, 10, kernel_size=5), 22 torch.nn.ReLU(), 23 torch.nn.MaxPool2d(kernel_size=2), 24 ) 25 self.conv2 = torch.nn.Sequential( 26 torch.nn.Conv2d(10, 20, kernel_size=5), 27 torch.nn.ReLU(), 28 torch.nn.MaxPool2d(kernel_size=2), 29 ) 30 self.fc = torch.nn.Sequential( 31 torch.nn.Linear(320, 50), 32 torch.nn.Linear(50, 10), 33 ) 34 35 def forward(self, x): 36 batch_size = x.size(0) 37 x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大) 38 x = self.conv2(x) # 再来一次 39 x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320 40 x = self.fc(x) 41 return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9) 42 #实例化模型 43 model = Net() 44 #损失函数使用交叉熵损失 45 #参数优化使用随机梯度下降 46 criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失 47 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # lr学习率,momentum冲量 48 # 把单独的一轮一环封装在函数类里 49 #训练轮 50 def train(epoch): 51 running_loss = 0.0 # 这整个epoch的loss清零 52 running_total = 0 53 running_correct = 0 54 for batch_idx, data in enumerate(train_loader, 0): 55 inputs, target = data 56 optimizer.zero_grad() 57 # forward + backward + update 58 outputs = model(inputs) 59 loss = criterion(outputs, target) 60 loss.backward() 61 optimizer.step() 62 # 把运行中的loss累加起来,为了下面300次一除 63 running_loss += loss.item() 64 # 把运行中的准确率acc算出来 65 _, predicted = torch.max(outputs.data, dim=1) 66 running_total += inputs.shape[0] 67 running_correct += (predicted == target).sum().item() 68 if batch_idx % 300 == 299: # 不想要每一次都出loss,浪费时间,选择每300次出一个平均损失,和准确率 69 print('[%d, %5d]: loss: %.3f , acc: %.2f %%' 70 % (epoch + 1, batch_idx + 1, running_loss / 300, 100 * running_correct / running_total)) 71 running_loss = 0.0 # 这小批300的loss清零 72 running_total = 0 73 running_correct = 0 # 这小批300的acc清零 74 # torch.save(model.state_dict(), './model_Mnist.pth') 75 # torch.save(optimizer.state_dict(), './optimizer_Mnist.pth') 76 #测试轮 77 def test(): 78 correct = 0 79 total = 0 80 with torch.no_grad(): # 测试集不用算梯度 81 for data in test_loader: 82 images, labels = data 83 outputs = model(images) 84 _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,沿着行(第1个维度)去找1.最大值和2.最大值的下标 85 total += labels.size(0) # 张量之间的比较运算 86 correct += (predicted == labels).sum().item() 87 acc = correct / total 88 print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数 89 return acc 90 #主函数:共进行10轮次的训练:每训练一轮,就进行一次测试。 91 if __name__ == '__main__': 92 acc_list_test = [] 93 for epoch in range(EPOCH): 94 train(epoch) 95 # if epoch % 10 == 9: #每训练10轮 测试1次 96 acc_test = test() 97 acc_list_test.append(acc_test)

1 #举例展示部分图 2 import matplotlib.pyplot as plt; 3 fig = plt.figure() 4 for i in range(16): 5 plt.subplot(4, 4, i+1) 6 z=train_dataset.train_data[i] 7 m=train_dataset.train_labels[i] 8 plt.imshow(z, cmap='gray', interpolation='none') 9 plt.title("Labels: {}".format(m)) 10 plt.xticks([]) 11 plt.yticks([]) 12 plt.show()
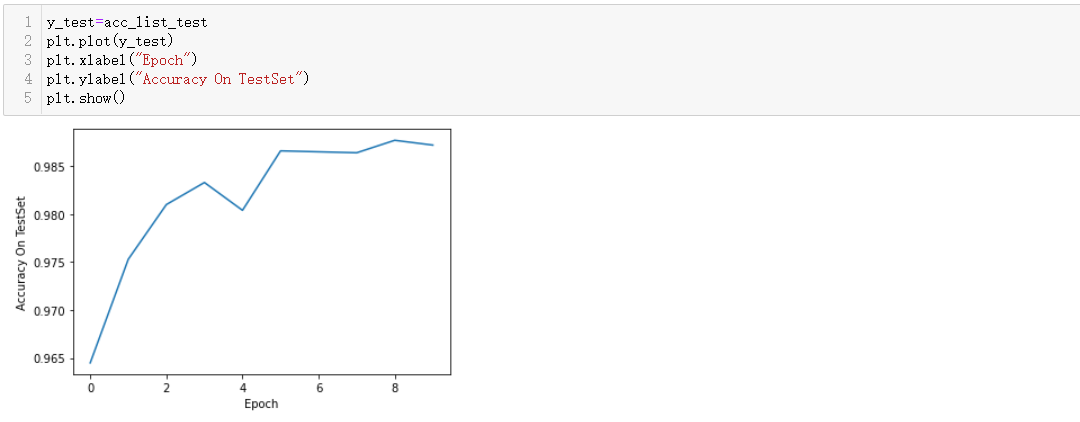
1 y_test=acc_list_test 2 plt.plot(y_test) 3 plt.xlabel("Epoch") 4 plt.ylabel("Accuracy On TestSet") 5 plt.show()
修改神经网络的学习率,观察对训练和检测效果的影响;
学习率设置太大会造成网络不能收敛,在最优值附近徘徊,也就是说直接跳过最低的地方跳到对称轴另一边,从而忽视了找到最优值的位置,学习率设置太小,网络收敛非常缓慢,会增大找到最优值的时间,也就是说从山坡上像蜗牛一样慢慢地爬下去。虽然设置非常小的学习率是可以到达,但是这很可能会进入局部极值点就收敛,没有真正找到的最优解。
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
一般条件下,在调参合理的情况下,层数和神经元数越多,正确率越高,但随之对应的是,容易出现过拟合
