

java-容器 集合
源码分析:田小波个人技术网站:集合框架
http://www.tianxiaobo.com/categories/foundation-of-java/collection/
其他参考:https://github.com/Snailclimb/JavaGuide#%E5%AE%B9%E5%99%A8
https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%AE%B9%E5%99%A8.md#arraylist
https://blog.csdn.net/feiyanaffection/article/details/81394745
https://blog.csdn.net/zhangqunshuai/article/details/80660974
java容器/集合 主要分为Collection 和Map两类,Collection储存对象的集合,Map储存映射(键值对)的集合
Collection中又分List和Set,分别表示有序和无序集合,
①.有序无序指的是插入操作时,先插入的在前,后插入的在后即为有序,如Arraylist,按数组下标插入--有序,hashMap按hoshcode觉得插入位置--无序。
集合类接口,抽象类,具体类关系图:
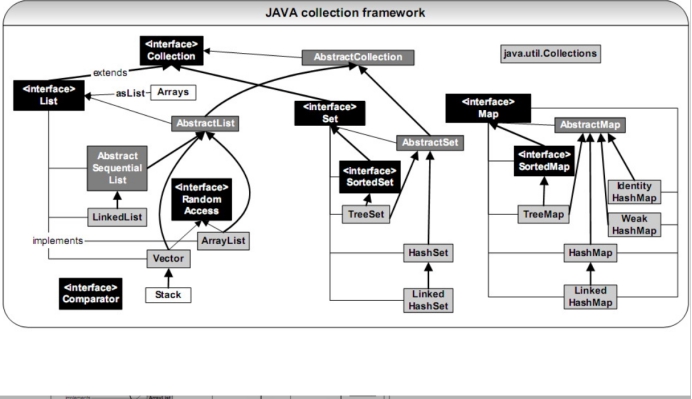
各抽象类中具体实现了各接口中的方法。
1,Collection接口中的List接口
1.1,ArrayList类:基于Object动态数组实现,支持随机随机访问。无同步,线程不安全
[1]动态数组-自动扩容机制:ArrayList调用非空构造方法时创建空数组;当添加第一个元素时,数组扩容为默认容量:10
每次扩容1.5倍左右,new=old+(old>>1) 整除--old奇数时省略小数
源码:


public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
[2],插入删除元素时,通过System.arraycopy(Object src, int srcPos,Object dest, int destPos,int length);实现移动数组。
与grow函数中Arrays.opyOf(T[] original, int newLength),实现数组长度改变不同。
源码:
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; }
②System.arraycopy与Arrays.opyOf的区别
1.2,Vector类:基于Object动态数组数组,支持随机随机访问。同步,线程安全
[1],动态数组-自动扩容机制:每次扩容时可以传入增量,即增加多少。若传值<=0,则默认增量为oldlength,即扩容两倍
源码:
public Vector(int initialCapacity, int capacityIncrement) { super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; this.capacityIncrement = capacityIncrement; } private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); }
[2],同步:通过synchronized实现线程安全。
1.3,LinkedList类:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不同步,线程不安全
③,AarryList与LinkedList的区别:
1,都是线程不安全。
2,ArrayList基于Object动态数组,LinkedList基于双向链表。
3,ArrayList插入删除元素受元素位置影响,数组需要移动元素,链表只需要遍历到位置。
4,数组支持高速随即访问。
5,占用空间:ArrayList尾部有预留空间,LinkedList每个元素都占更多的空间。
2,Map接口:
2.1,HashMap类:JDK1.8之后,基于数组+链表/红黑树,(哈希表+拉链法解决冲突+链表过长转为红黑树减小查询时间)。不同步,线程不安全。
源码分析:http://www.tianxiaobo.com/2018/01/18/HashMap-%E6%BA%90%E7%A0%81%E8%AF%A6%E7%BB%86%E5%88%86%E6%9E%90-JDK1-8/

[1],储存映射,key-value/键值对,键不可重复,可为null(仅一个),value可为null可重复。
[2],扩容机制:初始容量:16,负载因子:0.75f 每次扩容为原来两倍, newCap = oldCap << 1。
扩容源码,将原链表重新hashcode进新表,会生两个链表,一个还是原来的索引下标X,一个是X+oldlegth:
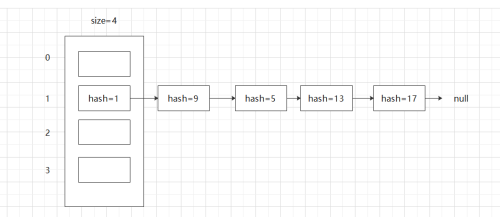
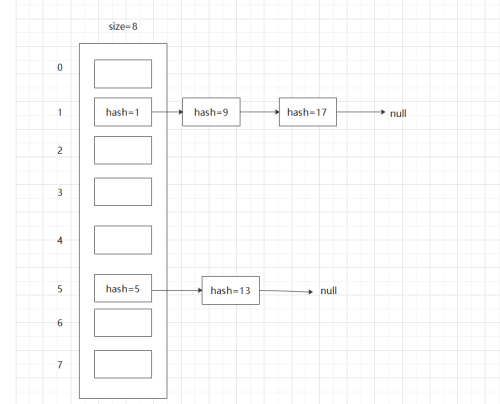
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
[3],链表树化(插入节点时),与树链表化(删除节点时):当链表长度>=8时,触发树化函数,①若数组长度<64则扩容,②否则将链表转为红黑树。
当树节点<=6时,将红黑树转为链表。
④JDK1.8中解决HashMap哈希冲突的方法:
1,(n-1)&hash;用hash值计算所在数组下标时,,用(n-1)&hash模拟hash%n; &运算比%求余运算效率高,(n-1)&hash=hash%n的前提
是n=2的幂次方;这是为什么hashMap长度为2的幂次方。
|- hashcode为Object类的方法,返回int整数值,32位 -|
2,hash=hash^(hash>>>16); 用了(n-1)&hash来求数组下标后,当数组长度较小时,n-1的高16位全是0,&上hash之后相当于hash的高16位(全0)
不起作用。大大增加了碰撞率,如果,hash^(hash>>>16) ^异或运算,hash>>>16之后高16位补充为0,与hash异或得到新hash,相当于新hash的高16位=原hash高16位
(1异或0=1,0异或0=0),而新hash的低16位为原hash高16位(hash>>>16之后高16位变低16位)于原hash低16位异或的结果,所以新hash值是高低16位共同作用的结果。
⑤hashMap长度为2的幂次方:
(n-1)&hash 1,(n-1)&hash=hash%n的前提是n=2的幂次方
2,用了这个公式,若n位奇数(奇数2进制最后一位为1,n-1最后一位为0,index=(n-1)&hash 最后一位为0),
数组下标的2进制最后一位为1的位置永远是空的,造成空间浪费。
2.2,LinkedHashMap类:继承自HashMap,上面HashMap有的属性和特性他都有,特有的地方就是再各节点间维护一条双向链表。
这篇画的更详细:https://www.imooc.com/article/22931
[1],上面HashMap有的属性和特性他都有,可以快速查找,同时又可以提供插入顺序遍历
[2],可以用于记录插入顺序,也可以用于记录LRU顺序,当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,
在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
记录插入顺序:

2.3,ConcurrentHashMap类:线程安全的HashMap,
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
2.4,TreeMap类:基于红黑树实现,适用于按自然顺序或自定义顺序遍历键(key)
TreeMap源码分析:http://www.tianxiaobo.com/2018/01/11/TreeMap%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
2.5,HashTabble类:遗留类,数组+链表实现,线程安全,
[1],扩容机制:初始容量为11,负载因子:0.75f, 扩容:2n+1;
int newCapacity = (oldCapacity << 1) + 1
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 public Hashtable() { this(11, 0.75f); } protected void rehash() { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; // overflow-conscious code int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) // Keep running with MAX_ARRAY_SIZE buckets return; newCapacity = MAX_ARRAY_SIZE; } Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++; threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
⑥HashMap 和HasnTabble:
1,HashMap线程不安全HasnTabble线程安全,所以HashMap效率高一点。
2,HashMap键可为null不可重复,value可为null可重复。HasnTabble,key-value不可重复。
3,初始容量与扩容机制不一样。HashMap:16 2n, HasnTabble: 11 2n+1。
4,底层数据结构:HashMap:数组+链表/红黑树, HasnTabble :数组+链表。
⑦ConcurrentHasnMap 和HashTabble:
1,数据结构不同,ConcurrentHasnMap 与HashMap一样:数组+链表/红黑树, HasnTabble :数组+链表。
2,实现线程安全的方式不一样:ConcurrentHasnMap java1.7:segment分段锁,java1.8:synchronized 和 CAS 来操作
HasnTabble :synchronized锁住整个结构,独占锁,写和读都是独占式访问,效率较低。
3,Collection接口中的Set接口:
之所以在Map接口后结束Set接口是因为Set接口下的类大部分是基于Map接口下的类实现的。
3.1,HashSet类:基于HashMap实现,底层用HashMap储存数据。只储存value。线程不安全,可以储存null,不可重复
⑧HashSet如何判断重复:
1,HashSet是基于HashMap实现的,看源码可以知道,他将value存在HashMap的Key上,而Value上所以元素同意存new Object(),不用。
HashSet如何判断重复即HashMap如何保持Key唯一,这在HashMap源码里添加函数里有提现。
2,用hashCode,和equals,(两个对象equals相等,hashCode肯定相等,反过来两个对象hashCode相等,equals不一定相等。)
1,底层是散列表,先根据hashCode计算出在数组中的index,所数组的index为空,则不重复。
2,若非空,则遍历该链表(或红黑树),该链表/红黑树上节点hashCode都相等(拉链法解决哈希碰撞),若不存在与待
插入节点equals的节点,则不重复,若存在则,重复。
⑨equals和==区别:
1,== : 它的作用是判断两个对象的地址是不是相等。即判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
2,equals() : 它的作用也是判断两个对象是否相等,它不能用于比较基本数据类型的变量。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类。
⑩equals和hashCode方法:
1,该两方法都是Object类里的通用方法,常用的还有toString,getClass,clone等。
2,hashCode方法返回一个int整数,
Object类中HashCode:由对象的地址得来。
String源码中的hashCode为:
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
是根据每一个字符计算得来,
HashMap中hashCode:
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
是根据,键和值的HashCode来决定,
3,当我们写一个类时,这个类的两个对象如果调用Object(根类)类中equals按储存位置来判断肯定是不相等的,而我们现在要重写equals函数
是的只要两个对象内容相等则equals相等。又因为两个对象equals相等,hashCode肯定相等,所以要重写hashCode函数,且判断equals相等的
属性参数都得用上。, 如String相等则每一个字符都得相等,HashMap对象相等则key-value相等。那么重新hashCode函数里就要由这些参数
共同确定hash值以确保---两个对象equals相等,hashCode肯定相等。 且要使hash值(散列码更加均匀,减少哈希碰撞)
3.2,LinkeedHashSet类:基于LinkedHashMap实现,维护双向链表。
3.3,TreeSet类:基于红黑树实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号