
【python爬虫+情感分析】B站黑神话悟空热门弹幕情感分析及词云生成
黑神话悟空背景介绍
最近黑神话悟空这款游戏可谓红遍大江南北,不仅IGN给出了8分的高分,就连央视新闻都有报道。作为国内第一款单机大作:出圈的是游戏,输出的是中国文化,受到了广大游戏玩家的追捧和赞扬。
针对此热门事件,老王我用python爬虫和情感分析技术,针对B站的弹幕数据,分析了黑神话悟空这款热门游戏弹幕的舆论导向,并生成了词云图,下面我们来看一下,python代码是如何实现的。
B站弹幕接口分析
目标网址:https://www.bilibili.com/video/BV1AE4m1d7XT/
B站最新的弹幕接口采用的是 protobuf编码 的格式,我们来简单分析一下。
通过搜索黑神话悟空视频弹幕上的关键字,发现压根搜不到,那说明大概率是加了密或进行了特殊编码的文字。
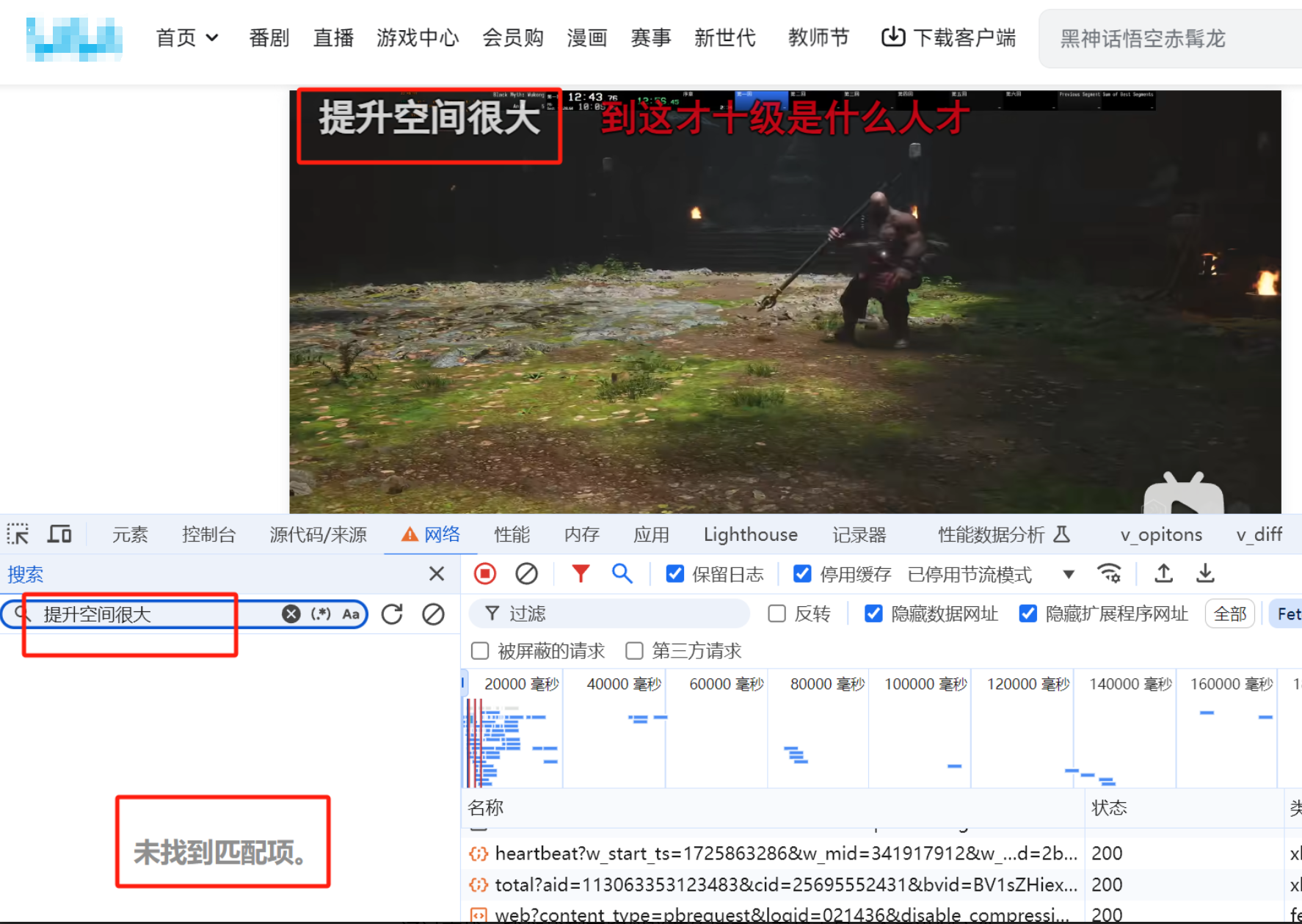
这也难不倒我们,就当多干点苦力活吧,一个一个的从接口里找一下吧!
通过查找,我们找到了疑似弹幕的接口,看起来是一个二进制文件。
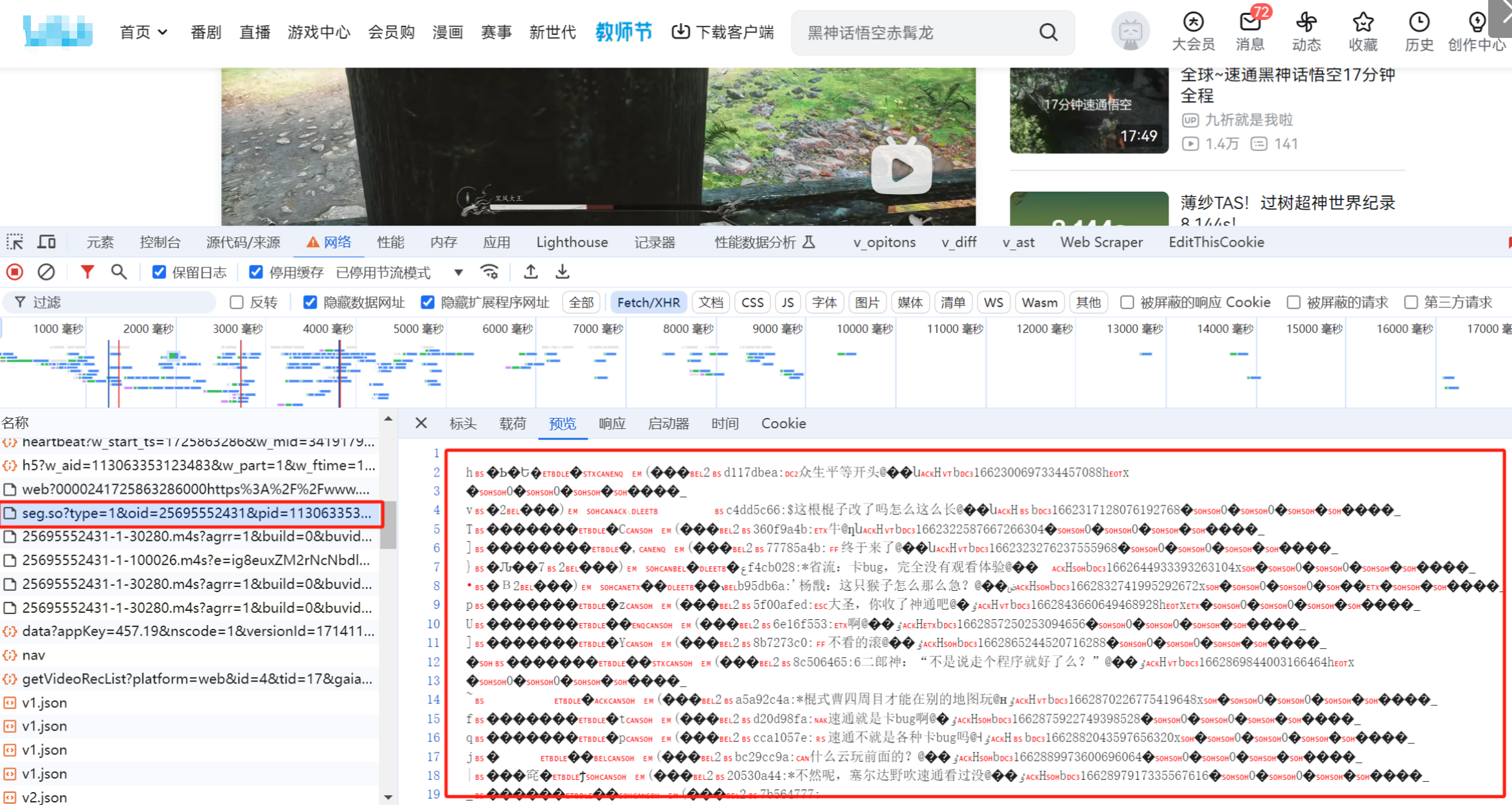
直接预览出现乱码,但是可以看见一部分的弹幕内容,已经可以确定这个就是弹幕文件了,但是有许多乱码在里面,不过仍可以查看部分弹幕内容。
老王这次不准备对protobuf编码的文字进行解码,而是告诉大家一个更简单的方法。
通过多方分析,发现B站的弹幕还有2个不加密的接口:
这两种返回的结果一致!但都不全,都是只有部分弹幕!但用来做此次分析足够了!
以B站视频 https://www.bilibili.com/video/BV1AE4m1d7XT 为例,我们打开这个黑神话悟空的网站,通过 查看网页源代码 ,可以找到对应的cid=1656402207,我们直接按照上面的格式替换一下,得到了对应的弹幕接口的网址是:http://comment.bilibili.com/1656402207.xml
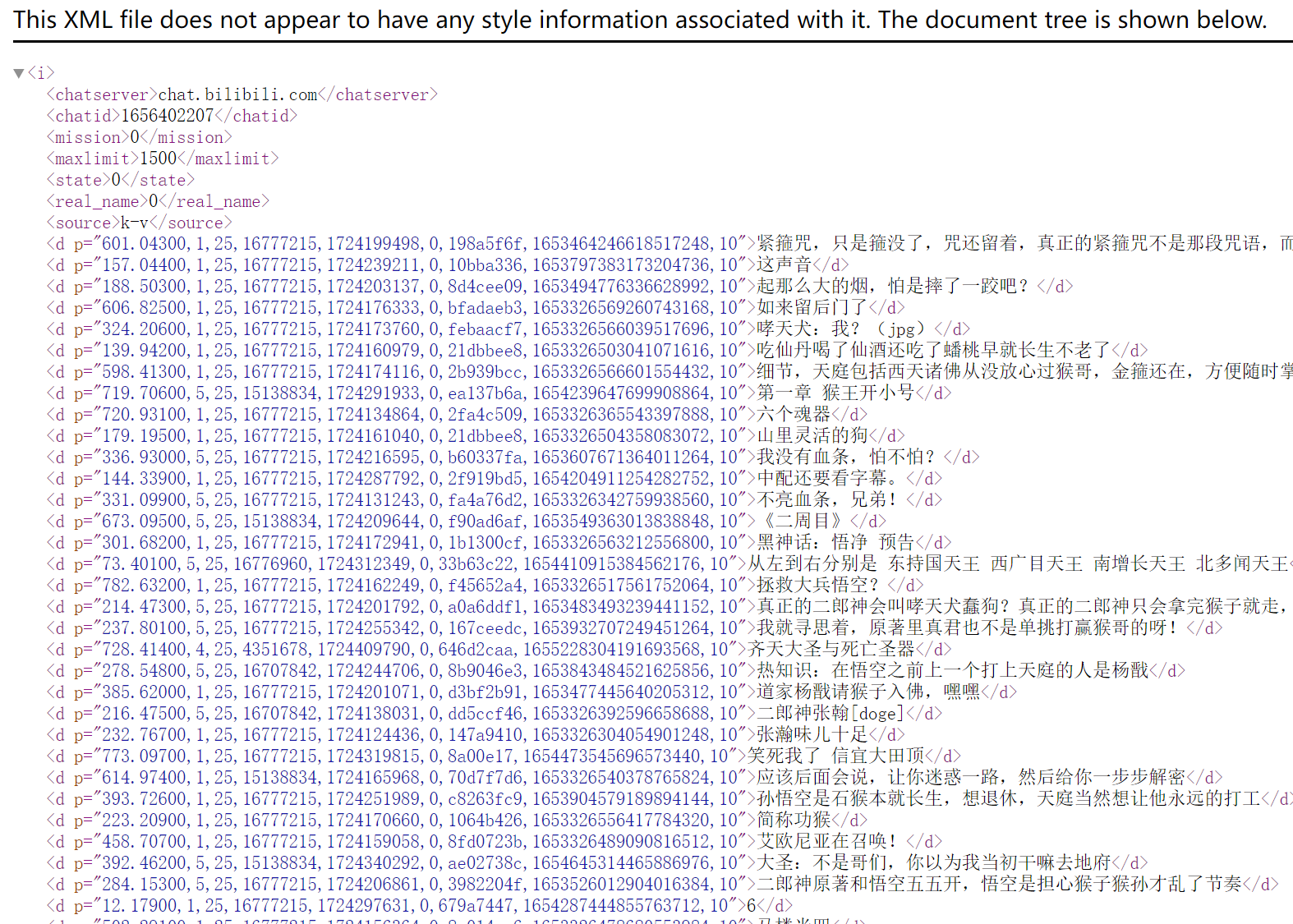
从上面可以发现,这不就是我们要的弹幕数据吗?而且都不用解密了,真爽!下面直接开始撸代码!
弹幕爬取代码详解
首先,导入需要用到的python库
import requests
import re # 正则表达式
import json # json转换
from lxml import etree # xml解析
import pandas as pd # 存取csv
import os
import datetime
然后,我们请求一下视频地址,并拿到视频信息
resp = session.get(url)
# 解析页面数据
html_content = resp.text
obj_str = re.search('window.__INITIAL_STATE__=(.*?);', html_content).group(1)
obj = json.loads(obj_str) # 解析出来的视频信息(转换为json格式)
有很多信息我们是用不到的,这里我们只提取我们需要的数据
# 获得所需的视频信息
video_data = obj["videoData"]
stat = video_data["stat"]
return {
"aid": video_data["aid"], # aid,pid
"cid": video_data["cid"], # cid,oid
"bvid": video_data["bvid"], # url链接上的视频id
"title": video_data["title"], # 标题
"desc": video_data["desc"], # 描述
"pubdate": video_data["pubdate"], # 发布日期 时间戳
"view": stat["view"], # 观看数
"danmaku": stat["danmaku"], # 弹幕数
"reply": stat["reply"], # 回复数
"favorite": stat["favorite"], # 收藏数
"coin": stat["coin"], # 投币数
"share": stat["share"], # 分享数
"like": stat["like"], # 点赞数
}
然后就是用上面我们拿到的cid,去请求那个xml接口地址
url = f'https://comment.bilibili.com/{cid}.xml'
# 发送请求
response = session.get(url)
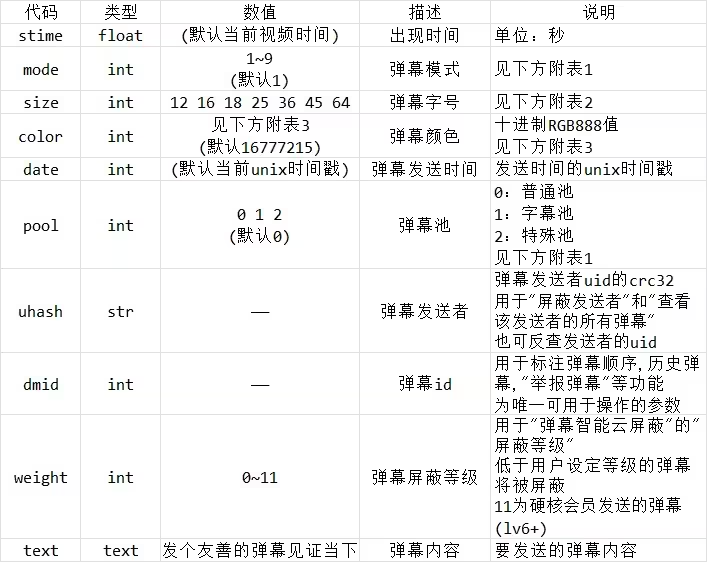
在这里附上一张B站的xml弹幕内容详解的图,方便大家查阅:
拿到xml的内容后,对xml文件进行解析
stimes = [] # 弹幕出现时间(单位:秒)
dates = [] # 弹幕发送时间
uhashs = [] # 弹幕发送者uid的crc32
dmids = [] # 弹幕id(用于标注弹幕顺序,历史弹幕,举报大幕等功能)
dm_texts = [] # 弹幕文本
# 解析xml数据
xml = etree.fromstring(response.content)
dms = xml.xpath("/i/d")
for dm in dms:
dm_attr = "".join(dm.xpath("./@p")) # 弹幕属性
dm_text = "".join(dm.xpath("./text()")) # 弹幕文本
"""
弹幕格式:
<d p="{stime},{mode},{size},{color},{date},{pool},{uhash},{dmid},{weight}">
{text}
</d>
"""
dm_attrs = dm_attr.split(",")
stime = dm_attrs[0]
date = int(dm_attrs[4])
uhash = dm_attrs[6]
dmid = dm_attrs[7]
# 拼接
stimes.append(stime)
dt = datetime.datetime.fromtimestamp(date)
date = dt.strftime('%Y-%m-%d %H:%M:%S')
dates.append(date)
uhashs.append(uhash)
dmids.append(f"'{dmid}")
dm_texts.append(dm_text)
保存为excel文件时,这里有个点要强调一下,如果文件存在的话,是不需要写入表头的,否则会造成如下结果:
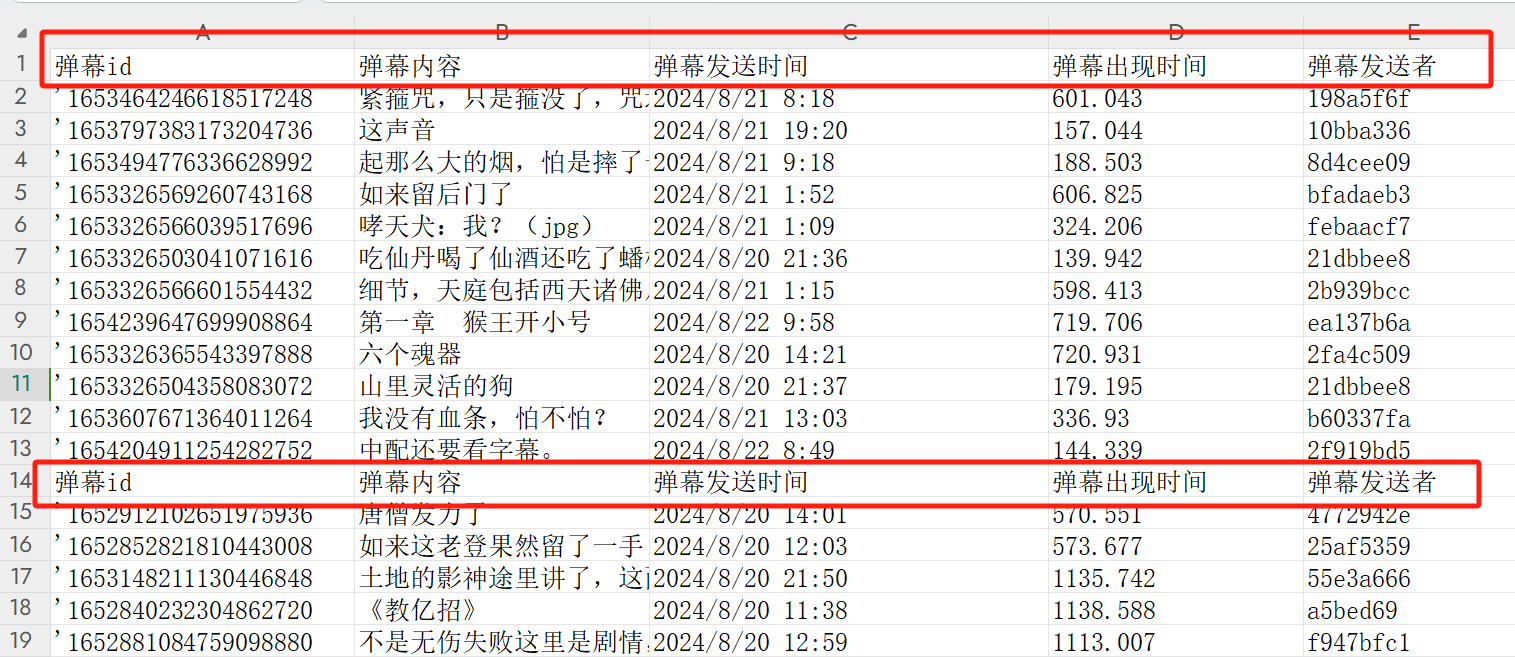
这里我写了一个方法,直接调用就可以将数据保存为csv文件了:
def save_to_csv(dms, csv_name):
"""
数据保存到csv
@param dms: 弹幕列表数据
@param csv_name: csv文件名字
@return:
"""
# 把列表转换成 dataframe
dm_df = pd.DataFrame(dms)
# 判断文件是否存在
if not os.path.exists(csv_name):
# 如果文件不存在,写入数据并包含表头 (如果乱码,可以尝试将编码设置成:utf_8_sig)
dm_df.to_csv(csv_name, mode='w', encoding='utf_8_sig', header=True, index=False)
else:
# 如果文件存在,追加数据并省略表头 (如果乱码,可以尝试将编码设置成:utf_8_sig)
dm_df.to_csv(csv_name, mode='a', encoding='utf_8_sig', header=False, index=False)
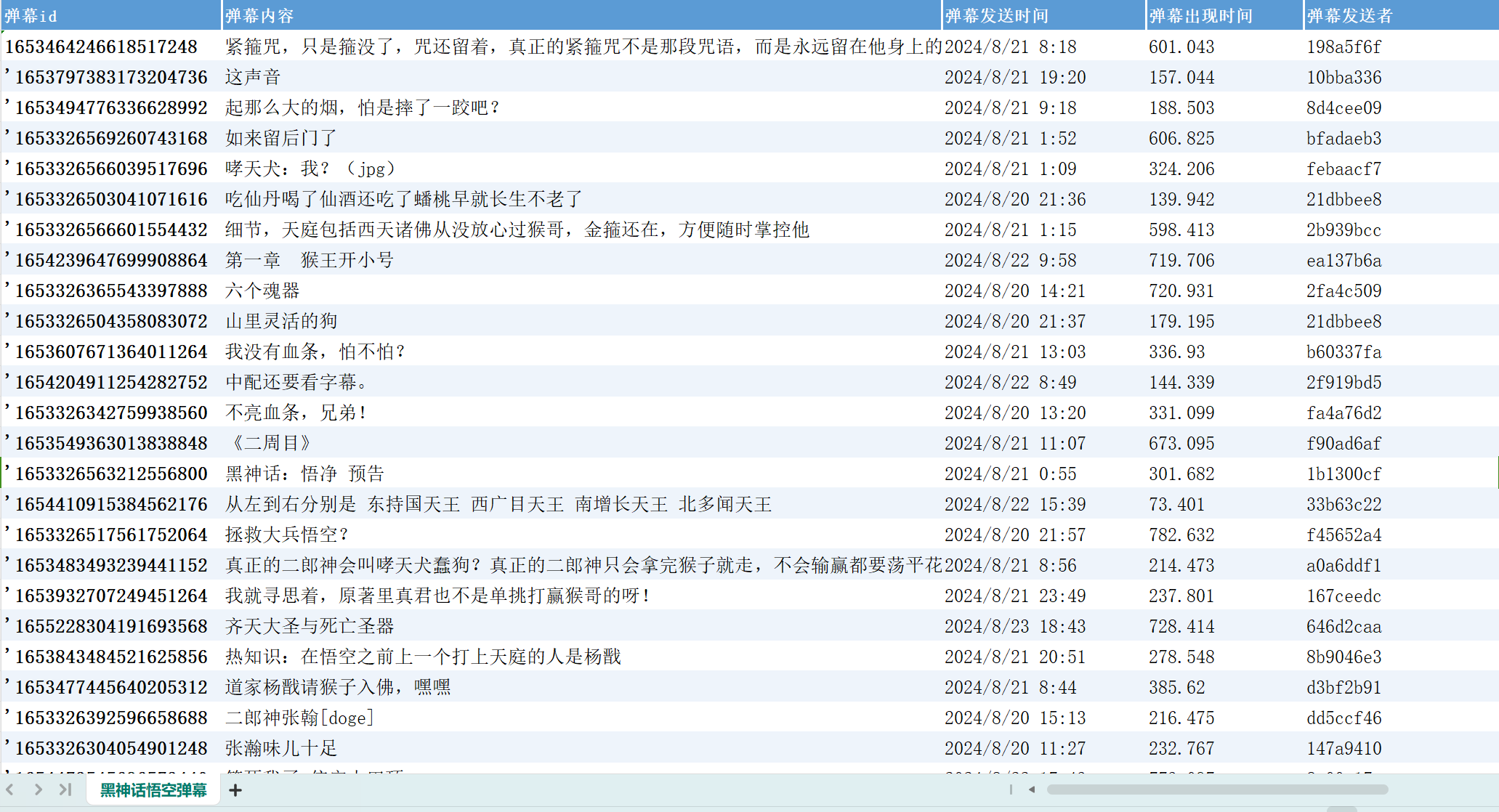
来看下爬虫程序运行后最终得到的excel文档数据:黑神话悟空弹幕.csv
黑神话弹幕情感分析
整体思路
1、使用jieba分词,统计TOP10高频词
2、使用SnowNLP给弹幕内容打标:积极、消极,并统计占比情况
3、使用wordcloud绘制黑神话悟空弹幕词云图
在编写爬虫代码之前,先导入我们必须用到的包
import jieba.analyse # 结巴分词
import jieba.posseg as pseg # 结巴分词
from wordcloud import WordCloud, random_color_func # 词云
import numpy as np
from PIL import Image # 图像处理
import pandas as pd # 存取csv
统计TOP10热门高频词
首先,我们需要读取刚刚我们获得的csv文件
# 读取csv文件
df = pd.read_csv("黑神话悟空弹幕.csv", encoding="utf8")
# 弹幕内容
danmu_texts = df["弹幕内容"].values.tolist()
dm_str = " ".join(danmu_texts)
print(f"总弹幕条数:{len(danmu_texts)}")
然后我们使用jieba分词,进行词性过滤,只保留名词(n)和形容词(a),避免介词等对我们的数据造成干扰
# jieba分词
words_list = pseg.cut(dm_str)
# 词性过滤:只保留名词(n)和形容词(a)
filtered_words = [word for word, flag in words_list if flag in ('n', 'a')]
words_str = ' '.join(filtered_words)
print(f"结巴分词结果:{words_str}")
最后,我们使用jieba.analyse.extract_tag这个方法统计一下黑神话悟空弹幕的TOP10高频词
# 统计TOP10高频词
top10_keywords = jieba.analyse.extract_tags(words_str, withWeight=True, topK=10)
print(f"TOP10高频关键词:{top10_keywords}")
看下输出结果:

情感分析打标
安装snownlp库
# SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的
pip install snownlp
然后我们来简单的看一下这个库是如何使用的:
from snownlp import SnowNLP
word = u'这个姑娘真漂亮!'
s = SnowNLP(word)
print(s.words) # 分词
print(list(s.tags)) # 词性标注
print(s.sentiments) # 情感分数
print(s.pinyin) # 拼音
print(SnowNLP(u'蒹葭蒼蒼,白露為霜。所謂伊人,在水一方。').han) # 繁体字转简体
# 运行结果如下:
['这个', '姑娘', '真', '漂亮', '!']
[('这个', 'r'), ('姑娘', 'n'), ('真', 'd'), ('漂亮', 'a'), ('!', 'w')]
0.9704576746581126
['zhe', 'ge', 'gu', 'niang', 'zhen', 'piao', 'liang', '!']
蒹葭苍苍,白露为霜。所谓伊人,在水一方。
接着我们来为黑神话悟空的弹幕写一个情感分析的函数,方便直接调用。
def emotion_analyse(danmu_texts, out_file_path):
"""
情感分析打分
@param danmu_texts: 弹幕列表
@param out_file_path: 输出文件
@return:
"""
scores = [] # 情感评分值
tags = [] # 打标分类结果
pos_count = 0 # 计数器-积极
neg_count = 0 # 计数器-消极
for danmu_text in danmu_texts:
# 获得该条弹幕的情感分数
emotion_score = SnowNLP(danmu_text).sentiments
if emotion_score < 0.3:
tag = '消极' # 如果分数 < 0.3 我们认为他是消极的
neg_count += 1
else:
tag = '积极' # 如果分数 >= 0.3 我们认为他是积极的
pos_count += 1
scores.append(emotion_score) # 得分值
tags.append(tag) # 打标分类
print('积极评价占比:', round(pos_count / (pos_count + neg_count), 4))
print('消极评价占比:', round(neg_count / (pos_count + neg_count), 4))
# 放到表格里
df['情感得分'] = scores
df['分析结果'] = tags
# 把情感分析结果保存到新的excel文件
df.to_csv(out_file_path, index=False)
调用后,得到了如下情感分析的csv文件(最后两列,是情感得分和分析结果)
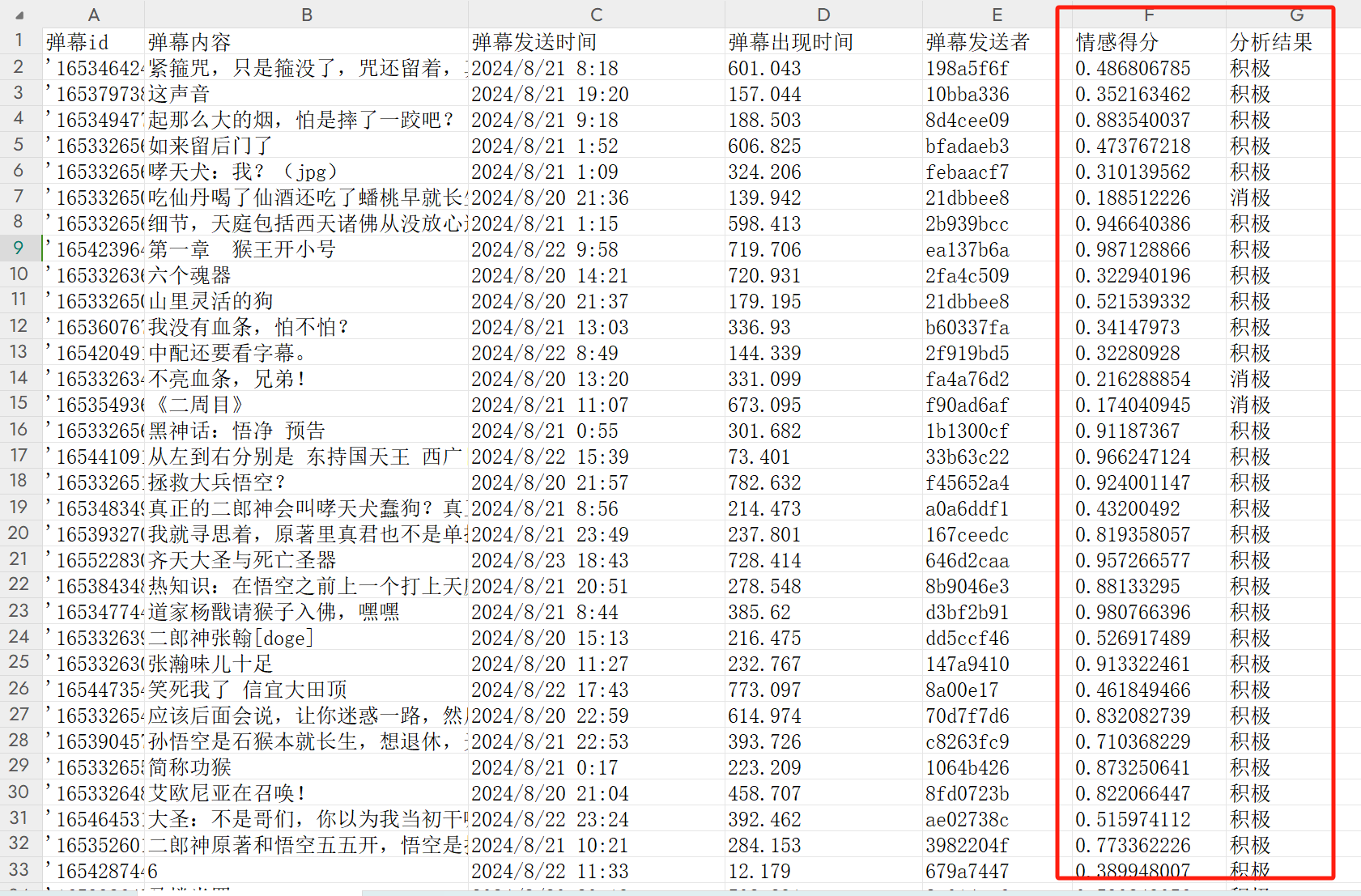
从下面的最终占比结果中可以看出:83%的弹幕都是积极向上的肯定评论,也说明了这款游戏确实得到了广泛的认可。
词云图生成
注意!注意!注意!
作为词云图的背景底图,下面的代码要求必须是白色背景或透明背景的(实在找不到的话,就只能用ps软件处理一下了),否则生成的词云图是满屏的!!
def generate_word_cloud(words_str, stop_words, background_image_path, out_file_path):
"""
生成词云
@param words_str: 文本内容
@param stop_words: 停用词
@param background_image_path: 背景图路径
@param out_file_path: 词云图输出文件路径
@return:
"""
# 读取背景底图
backgroud_image = np.array(Image.open(background_image_path))
# 创建词云
wc = WordCloud(
background_color='white', # 背景颜色
mask=backgroud_image, # 背景图
font_path='C:\Windows\Fonts\msyh.ttc', # 字体文件路径,根据实际情况(Windows)替换
max_words=2000, # 最多字数
color_func=random_color_func, # 随机文字颜色
stopwords=stop_words,
contour_width=1, # 添加1px的轮廓线
contour_color='steelblue', # 轮廓线的颜色
# width=1500, # 图宽
# height=1200, # 图高
# max_font_size=100, # 最大字体大小
# min_font_size=10, # 最小字体大小
# random_state=5, # 随机数种子(如果不指定,则生成的词云图布局具有随机性;如果指定,则每次生成的词云图布局都是确定的)
)
# 生成词云图
wc.generate(words_str)
# 保存图片文件
wc.to_file(out_file_path)
词云图绘制结果:因为我上面添加了1px的轮廓线,所以会有下面图上的人物边缘线

和原始图对比:

弹幕情感分析总结
- 打标结果:积极占比0.8322,消极占比0.1678,远远高于消极评论!
- top10热门高频词统计结果:"二郎神"、"猴子"、"猴哥"等是大家非常关注的对象!"卧槽"、"太帅"等情绪词也表明了对游戏的肯定!
- 词云图中:"好"、"太帅"等好评词也反映了观众的积极情绪!
综上所述,经分析"黑神话悟空"相关弹幕,可以得出结论:
众多网友对黑神话悟空的评价都很高,也很喜欢这款游戏大作,不仅游戏画质高,还能将中国传统文化传播到全世界!
致敬!
获取python完整源码
我是@王哪跑,持续分享python干货,各类副业技巧及软件!
附完整python源码及csv表格数据:B站黑神话悟空热门弹幕情感分析及词云生成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号