图像拼接2 ORB特征提取
1. 绪言
发现有几个ORB特征提取算法讲的不错的博客,理论部分可参考的地址如下:
opencv 虽然已经封装了ORB特征提取,但是用的时候还是有优化的地方,在上篇文章中,用opencv的api提特征,会有很多的误匹配点,这些错误匹配点的置信度还很高,会给仿射变换矩阵计算带来较大的误差。所以我这里主要还是看下ORB_SLAM3中的orb特征提取算法,简单的测试了一下,发现该算法的准确性、耗时都比opencv中的实现好。
2. ORB 特征提取
本节主要是先介绍一下opencv与ORBSLAM3中ORB特征提取接口,并对比两者的效果与速度。
2.1 OpenCV ORB特征提取
特征类的对象指针创建接口函数
CV_WRAP static Ptr<ORB> create(int nfeatures=500, float scaleFactor=1.2f,
int nlevels=8, int edgeThreshold=31, int firstLevel=0,
int WTA_K=2, ORB::ScoreType scoreType=ORB::HARRIS_SCORE,
int patchSize=31, int fastThreshold=20);
- nfeatures, 提取的特征数量
- scaleFactor,尺度因子,后续划分多尺度检测特征时用到
- nlevel,图像金字塔层数
- edgeThreshold, 边缘不检测的像素个数阈值,根据后面的patchSize来定的,靠近边缘edgeThreshold以内的像素是不检测特征点的
- firstLevel, 指定第一层的索引值,这里默认为0
- WET_K, 用于产生BIREF描述子的 点对的个数,一般为2个,也可以设置为3个或4个,那么这时候描述子之间的距离计算就不能用汉明距离了,而是应该用一个变种。OpenCV中,如果设置WET_K = 2,则选用点对就只有2个点,匹配的时候距离参数选择NORM_HAMMING,如果WET_K设置为3或4,则BIREF描述子会选择3个或4个点,那么后面匹配的时候应该选择的距离参数为NORM_HAMMING2
- scoreType, 用于对特征点进行排序的算法,你可以选择HARRIS_SCORE,也可以选择FAST_SCORE,但是它也只是比前者快一点点而已
- patchSize, 用于计算BIREF描述子的特征点邻域大小
特征提取函数
// Compute the ORB_Impl features and descriptors on an image
void detectAndCompute( InputArray image, InputArray mask, std::vector<KeyPoint>& keypoints,
OutputArray descriptors, bool useProvidedKeypoints=false ) CV_OVERRIDE;
- image, 输入的检测图片
- mask,特征检测的区域mask
- keypoints, 关键点存储vector
- descriptors, 特征点描述子的输出向量(如果不需要输出,需要传cv::noArray())
- useProvidedKeypoints, 是否进行特征点检测。ture,则检测特征点;false,只计算图像特征描述
2.2 ORBSLAM3 orb特征提取
ORBExtractor构造函数
ORBextractor(int nfeatures, float scaleFactor, int nlevels,
int iniThFAST, int minThFAST);
- nfeatures, ORB特征点数量
- scaleFactor,相邻层的放大倍数
- nlevels,层数
- iniThFAST,提取FAST角点时初始阈值
- minThFAST,提取FAST角点时更小的阈值.设置两个阈值的原因是在FAST提取角点进行分块后有可能在某个块中在原始阈值情况下提取不到角点,使用更小的阈值进一步提取
特征提取
void operator()( cv::InputArray image, cv::InputArray mask,
std::vector<cv::KeyPoint>& keypoints,
cv::OutputArray descriptors);
重载()函数进行特征提取
- image, 输入灰度图像
- mask,特征检测的区域mask
- keypoints, 关键点存储vector
- descriptors, 特征点描述子的输出向量
2.3 两种实现效果对比
实现代码如下:
#include "ORBextractor.h"
#include "logging.hpp"
#include "opencv2/opencv.hpp"
int main()
{
std::string root_path = "data/img/";
std::string pic_pattern = "medium11.jpg";
std::string feature_type = "orb";
std::string img_names = root_path + pic_pattern;
cv::Ptr<cv::FeatureDetector> finder;
if (feature_type == "orb") {
finder = cv::ORB::create();
} else if (feature_type == "sift") {
finder = cv::SIFT::create();
} else {
LOG(INFO) << "Unknown 2D features type: '" << feature_type << "'.\n";
LOG(INFO) << "use default ORB\n";
finder = cv::ORB::create();
}
//opencv orb检测函数
cv::Mat img = cv::imread(img_names);
if (img.empty()) {
LOG(INFO) << "failed to load image : " << img_names;
return -1;
}
std::vector<cv::detail::ImageFeatures> features(2);
NEW_TIME_VALUE
START_GETTIME
for (int i = 0; i < 10; i++) {
finder->detectAndCompute(img, cv::Mat(), features[0].keypoints,
features[0].descriptors, false);
}
END_GETTIME(10, "opencv extract orb , time cost ")
features[0].img_idx = 0;
std::vector<cv::Mat> feature_img(2);
cv::drawKeypoints(img, features[0].keypoints, feature_img[0]);
LOG(INFO) << "cv orb feature num: " << features[0].keypoints.size();
ORB_SLAM3::ORBextractor orb_extractor = ORB_SLAM3::ORBextractor(
500, 1.2, 8, 20, 10);
std::vector<int> vlapp{30};
cv::Mat gray_img;
cv::cvtColor(img, gray_img, cv::COLOR_BGR2GRAY);
START_GETTIME
for (int i = 0; i < 10; i++) {
orb_extractor(gray_img, cv::Mat(), features[1].keypoints,
features[1].descriptors, vlapp);
}
END_GETTIME(10, "slam extract orb , time cost ")
cv::drawKeypoints(img, features[1].keypoints, feature_img[1]);
LOG(INFO) << "slam orb feature num: " << features[1].keypoints.size();
cv::imshow("cv_orb", feature_img[0]);
cv::imshow("slam_orb", feature_img[1]);
cv::waitKey(0);
return 0;
}
-
特征提取耗时对比(时间只是做个参考,得看具体平台):
- opencv ORB 平均耗时:41.17ms
- ORBSLAM3 ORB 平均耗时:21.78ms
-
特征提取数量:
- opencv ORB 特征个数:500
- ORBSLAM3 ORB 特征个数:507
-
特征提取效果对比:

opencv orb 
slam orb
2.4 小结
从上面的结果可以看出,slam ORB特征提取速度更快,分布均匀。相对于opencv中的实现,ORBSLAM3中的orb特征提取更适合在嵌入式端使用。
3. ORB特征提取原理
第二节介绍了两种orb特征提取算法的使用,这部分将会对orb提取的原理做个介绍,对一些参数的设置将会有更加深入的理解。这部分内容主要来源:https://zhuanlan.zhihu.com/p/91479558
3.1 FAST
FAST核心思想:若某像素与其周围领域内足够多的像素点相差较大,则该像素可能是特征点。提取过程如下:
-
选择某个像素\(p\), 其像素值为\(I_p\)。以 \(p\) 为圆心,半径为3,确立一个圆,圆上有16个像素,分别为 \(p_{1}, p_{2}, \ldots, p_{16}\)

-
确定一个阈值:\(t\) (比如 \(I_p\) 的 20%)
-
让圆上的像素的像素值分别与 \(p\)的像素值做差,如果存在连续n个点满足 \(I_{x}-I_{p}>t\) 或 \(I_{x}-I_{p}<-t\)(其中 \(I_x\)代表此圆上16个像素中的一个点),那么就把该点作为一个候选点。根据经验,一般令n=12(n 通常取 12,即为 FAST-12。其它常用的 N 取值为 9 和 11, 他们分别被称为 FAST-9,FAST-11).
注:由于在检测特征点时是需要对图像中所有的像素点进行检测,然而图像中的绝大多数点都不是特征点,如果对每个像素点都进行上述的检测过程,那显然会浪费许多时间,因此FAST采用了一种进行非特征点判别的方法。如上图中,对于每个点都检测第1、5、9、13号(即上下左右)像素点,如果这4个点中至少有3个满足都比 \(I_{p}+t\) 大或者都比 \(I_{p}-t\) 小,则继续对该点进行16个邻域像素点都检测的方法,否则则判定该点是非特征点(也不可能是角点,如果是一个角点,那么上述四个像素点中至少有3个应该和点相同),直接剔除即可。
- 非极大值抑制.上面的步骤很可能大部分检测出来的点彼此之间相邻,我们要去除一部分这样的点。为了解决这一问题,可以采用非最大值抑制的算法:
- 假设P,Q两个点相邻,分别计算两个点与其周围的16个像素点之间的差分和为V
- 去除V值较小的点,即把非最大的角点抑制掉
3.2 Oriented FAST
原始FAST没有旋转不变性以及尺度不变性,优化后的FAST称为 Oriented FAST。
尺度不变性:
- 对图像做不同尺度的高斯模糊
- 对图像做降采样(隔点采样)
- 对每层金字塔做FAST特征点检测
- n幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点
旋转不变性:
- 在一个小的图像块 B中,定义图像块的矩。
- 通过矩可以找到图像块的质心
- 连接图像块的几何中心 \(O\) 与质心\(C\) ,得到一个方向向量\(\overrightarrow{O C}\) ,这就是特征点的方向
3.3 BRIEF
FAST 只是找到了特征点位置,但特征点一般还要用来做匹配,如何描述这个特征点更多的信息以便判断特征点是否相同就是特征描述子的作用。
BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度直方图描述特征点的传统方法,采用二级制、位异或运算,大大的加快了特征描述符建立的速度,同时也极大的降低了特征匹配的时间。建立特征点描述子流程:
- 为减少噪声干扰,先对图像进行高斯滤波(方差为2,高斯窗口为9x9)
- 以特征点为中心,取SxS的邻域窗口。在窗口内随机选取一对(两个)点,比较二者像素的大小,进行如下二进制赋值。\[\tau(\mathbf{p} ; \mathbf{x}, \mathbf{y}):= \begin{cases}1 & : \mathbf{p}(\mathbf{x})<\mathbf{p}(\mathbf{y}) \\ 0 & : \mathbf{p}(\mathbf{x}) \geq \mathbf{p}(\mathbf{y})\end{cases} \]其中,\(p(x)\),\(p(y)\)分别是随机点\(x=(u1,v1),y=(u2,v2)\)的像素值。
- 在窗口中随机选取N对随机点,重复步骤2的二进制赋值,形成一个二进制编码,这个编码就是对特征点的描述,即特征描述子。(一般N=256)这个特征可以由n位二进制测试向量表示,BRIEF描述子:\[f_{n}(\mathbf{p}):=\sum_{1 \leq i \leq n} 2^{i-1} \tau\left(\mathbf{p} ; \mathbf{x}_{i}, \mathbf{y}_{i}\right) \]
- 随机点对的选取。在ORB-SLAM中,取了128对点,位置如下:
第一对点的相对位置是\((8, -2), (9, 5)\),若当前关键点位置是\((x, y)\),现在确定找\((x+8, y-2), (x+9, y+5)\)这两个像素点,然后比较大小,若前者大,则BRIEF得到的二进制位是1,否则为0。依次最后可得到一个128位的二进制串。注意后文与此处取的值不同,为256.static int bit_pattern_31_[256*4] = { 8,-3, 9,5/*mean (0), correlation (0)*/, 4,2, 7,-12/*mean (1.12461e-05), correlation (0.0437584)*/, -11,9, -8,2/*mean (3.37382e-05), correlation (0.0617409)*/, 7,-12, 12,-13/*mean (5.62303e-05), correlation (0.0636977)*/, 2,-13, 2,12/*mean (0.000134953), correlation (0.085099)*/, 1,-7, 1,6/*mean (0.000528565), correlation (0.0857175)*/, ...... }
3.4 Steered BRIEF
为BRIEF增加鲁棒性,执行如下优化:
- ORB算法进一步增强描述子的抗噪能力,采用 9×9 的高斯卷积核进行滤波降噪,可以在一定程度上缓解噪声敏感问题;
- 在特征点的31x31邻域内,产生随机点对,并以随机点为中心,取5x5的子窗口。
- 比较两个随机点的子窗口内25个像素的大小计算灰度平均值(灰度和),比较随机点对的邻域灰度均值,进行二进制编码(而不仅仅是两个随机点了)
为BRIEF增加旋转不变性:
至于旋转不变性问题,可利用 FAST 特征点检测时求取的主方向,旋转特征点邻域,这种方法称为「Steer BREIF (sBRIEF) 」。但旋转整个 Patch 再提取 BRIEF 特征描述子的计算代价较大,因此,ORB 采用了一种更高效的方式,在每个特征点邻域 Patch 内,先选取 n 对随机点,将其进行旋转,然后做判决编码为二进制串。
- n 个点对构成矩阵 S:\[S=\left[\begin{array}{llll} x_{1} & x_{2} & \ldots & x_{n} \\ y_{1} & y_{2} & \ldots & y_{n} \end{array}\right] \]
- 旋转矩阵 \(R_{\theta}\) 为:\[R_{\theta}=\left[\begin{array}{cc} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{array}\right] \]
- 旋转后的坐标矩阵为:\[S_{\theta}=R_{\theta}S \]
使用steeredBRIEF方法得到的特征描述子具有旋转不变性,但是却在另外一个性质上不如原始的BRIEF算法。是什么性质呢,是描述符的可区分性,或者说是相关性。这个性质对特征匹配的好坏影响非常大。描述子是特征点性质的描述。描述子表达了特征点不同于其他特征点的区别。我们计算的描述子要尽量的表达特征点的独特性。如果不同特征点的描述子的可区分性比较差,匹配时不容易找到对应的匹配点,引起误匹配。ORB论文中,作者用不同的方法对100k个特征点计算二进制描述符,对这些描述符进行统计,如下表所示:
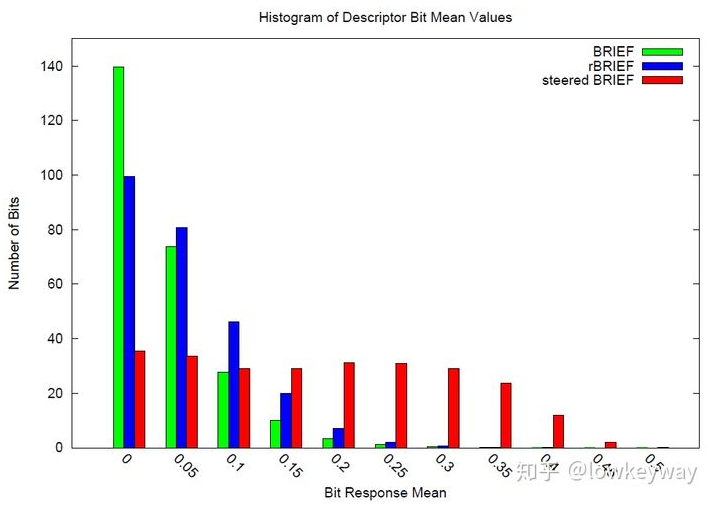
对BRIEF和steeredBRIEF两种算法的比较可知,BRIEF算法落在0上的特征点数较多,因此BRIEF算法计算的描述符的均值在0.5左右,每个描述符的方差较大,可区分性较强。而steeredBRIEF失去了这个特性。
至于为什么均值在0.5左右,方差较大,可区分性较强的原因,这里大概分析一下。这里的描述子是二进制串,里面的数值不是0就是1,如果二进制串的均值在0.5左右的话,那么这个串有大约相同数目的0和1,那么方差就较大了。用统计的观点来分析二进制串的区分性,如果两个二进制串的均值都比0.5大很多,那么说明这两个二进制串中都有较多的1时,在这两个串的相同位置同时出现1的概率就会很高。那么这两个特征点的描述子就有很大的相似性。这就增大了描述符之间的相关性,减小之案件的可区分性。
3.5 rBRIEF
为了解决描述子的可区分性和相关性的问题,而是使用统计学习的方法来重新选择点对集合。
- 建立300k个特征点测试集
对于测试集中的每个点,预处理参考第一个步骤。考虑其31x31邻域。这里不同于原始BRIEF算法的地方是,这里在对图像进行高斯平滑之后,使用邻域中的某个点的5x5邻域灰度平均值来代替某个点对的值,进而比较点对的大小。这样特征值更加具备抗噪性。另外可以使用积分图像加快求取5x5邻域灰度平均值的速度。
- 特征点选取,考虑其 31×31 的邻域 Patch选择 5×5 的子窗口的灰度均值代替单个像素的灰度,这样每个 Patch 内就有 \(N=(31−5+1)×(31−5+1)=27×27=729\) 个子窗口,从中随机选取 2 个非重复的子窗口,一共有 \(M=C^2_N\) 种方法,这样,每个特征点便可提取出一个长度为 M 的二进制串,所有特征点可构成一个 \(300k×M\) 的二进制矩阵 Q :\[Q=\left[\begin{array}{cccc} p_{1,1} & p_{1,2} & \cdots & p_{1, M} \\ p_{2,1} & p_{2,2} & \cdots & p_{2, M} \\ \vdots & \vdots & \ddots & \vdots \\ p_{300 k, 1} & p_{300 k, 2} & \cdots & p_{300 k, M} \end{array}\right] \quad p_{i, j} \in\{0,1\} \]
- 现在需要从 M 个点对中选取 256 个相关性最小、可区分性最大的点对,作为最终的二进制编码。筛选方法如下:
- 对矩阵 Q 的每一列求取均值,并根据均值与 0.5 之间的距离从小到大的顺序,依次对所有列向量进行重新排序,得到矩阵 T
- 将 T 中的第一列向量放到结果矩阵 R 中
- 取出 T 中的下一列向量,计算其与矩阵 R 中所有列向量的相关性(皮尔逊积矩相关系数?),如果相关系数小于给定阈值,则将 T 中的该列向量移至矩阵 R 中,否则丢弃
- 循环执行上一步,直到 R 中有 256 个列向量;如果遍历 T 中所有列, R 中向量列数还不满 256,则增大阈值,重复以上步骤
3.6 小结
本节主要是介绍了 ORB特征 提取算法,对于opencv中的阈值设置scaleFactor与nlevels是用于构建高斯金字塔用的,注意两者要考虑到输入图片的大小,opencv有做过处理不会有异常,但是orb-slam不匹配的话,会报错。edgeThreshold与patchSize的含义也清楚了,都是用于代替单个像素点而选择patch像素均值,这个大小一般默认为31。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号