x264 P帧的处理
x264 P帧的处理
关于概念:所谓的P帧划分,仅仅是为了应对帧间引用关系,它并不是说P帧内的每一个MB都必须是P类型的,而是指MB只能够向前引用其他帧的数据,又或者,MB也可以是intra类型的。
基本过程:P帧的某一个MB ---> 运动预测 --> 以运动预测卫结果,得到残差数据 ---> 对残差数据编码
因为编码的是残差数据,故而数据量较小,可以得到更小的编码。
P帧的几种类型
-
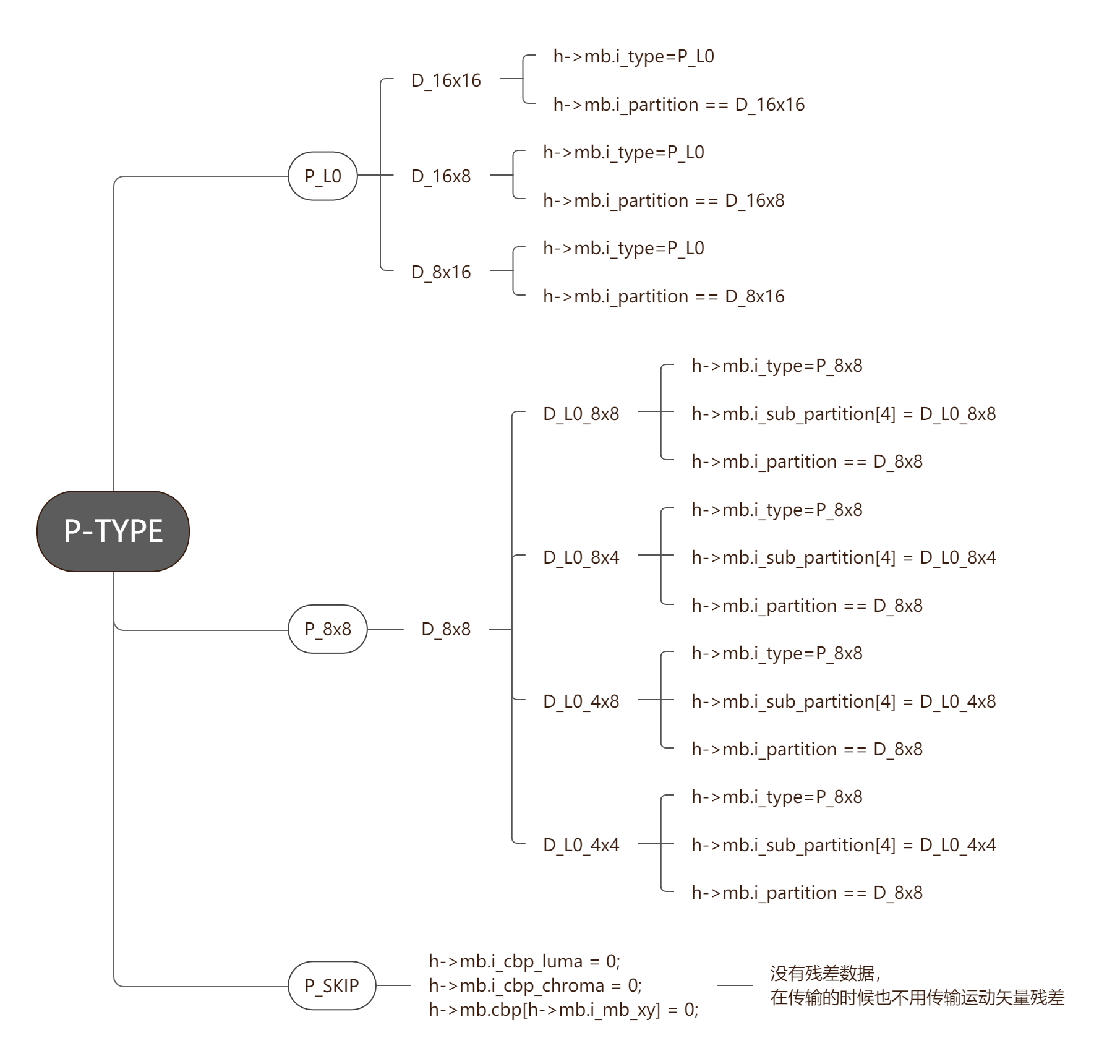
P_L0 : 当分割类型是16x16, 16x8, 8x16的时候,统一用P_L0来表示
-
P_8x8 : 当分割类型是8x8、或者更精细的划分的时候,用P_8x8来表示
-
P_SKIP : 当前的MB没有残差数据,也没有运动矢量残差MVD
类型分割关系:
分割类型一般记录在h->mb.i_partition当中,但如果MB细分的比8x8还小,则需要额外的数据结构h->mb.i_sub_partition[4]来分别记录每一个子块的细分模式。
具体实现逻辑如下(左边是逻辑,右边是函数调用):
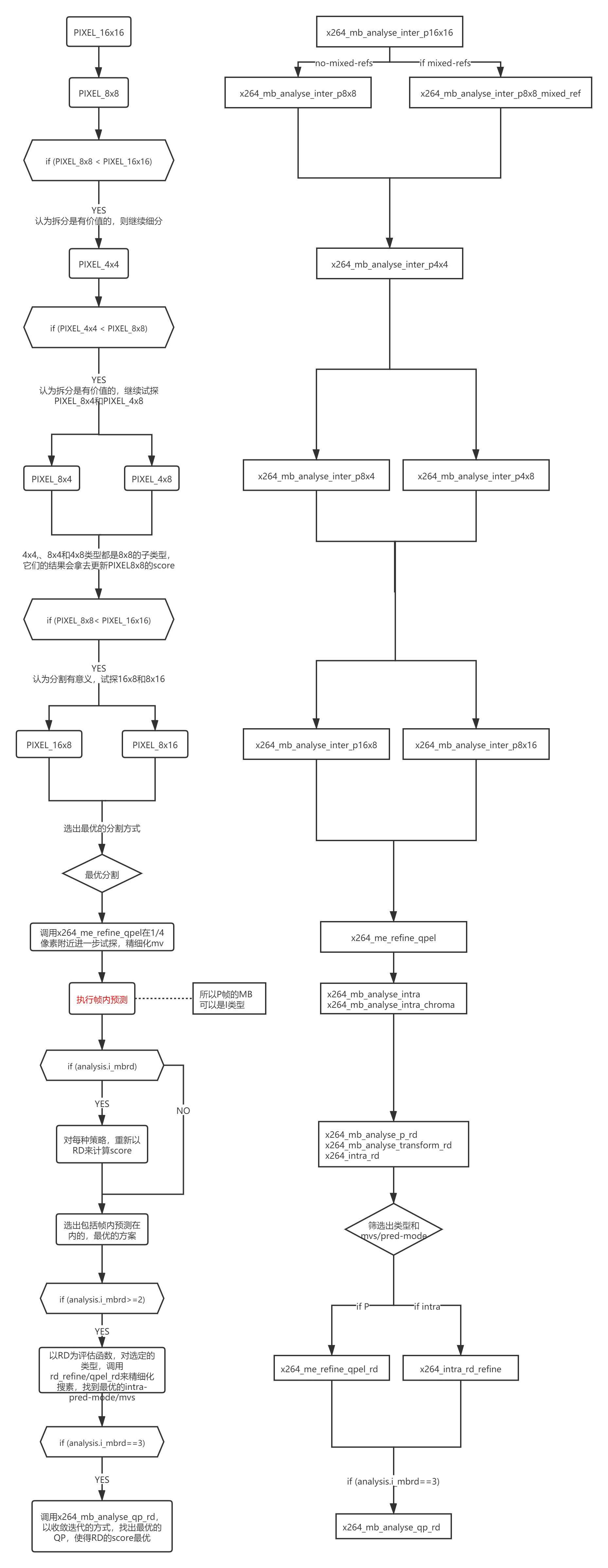
能够明显的看出来,P帧的MB可以是intra类型的。在执行完运动预测之后,如果发现当前的MB更适合当做一个intra类型,就会把当前的MB当做intra类型来编码。但即便所有的MB都是intra类型的,当前帧也还是P类型的,因为这里的P代表的是一种帧间关系,而不是代表MB的状态。(帧的设定是有责任的,并非仅仅指引用关系,I帧被赋予了降低扰动的责任,而P帧没有,虽然这里的P帧内部全是I类型的MB,但它还是一个P帧,它永远也不会抢I帧的责任。)
运动预测的结果,相关的数据结构:
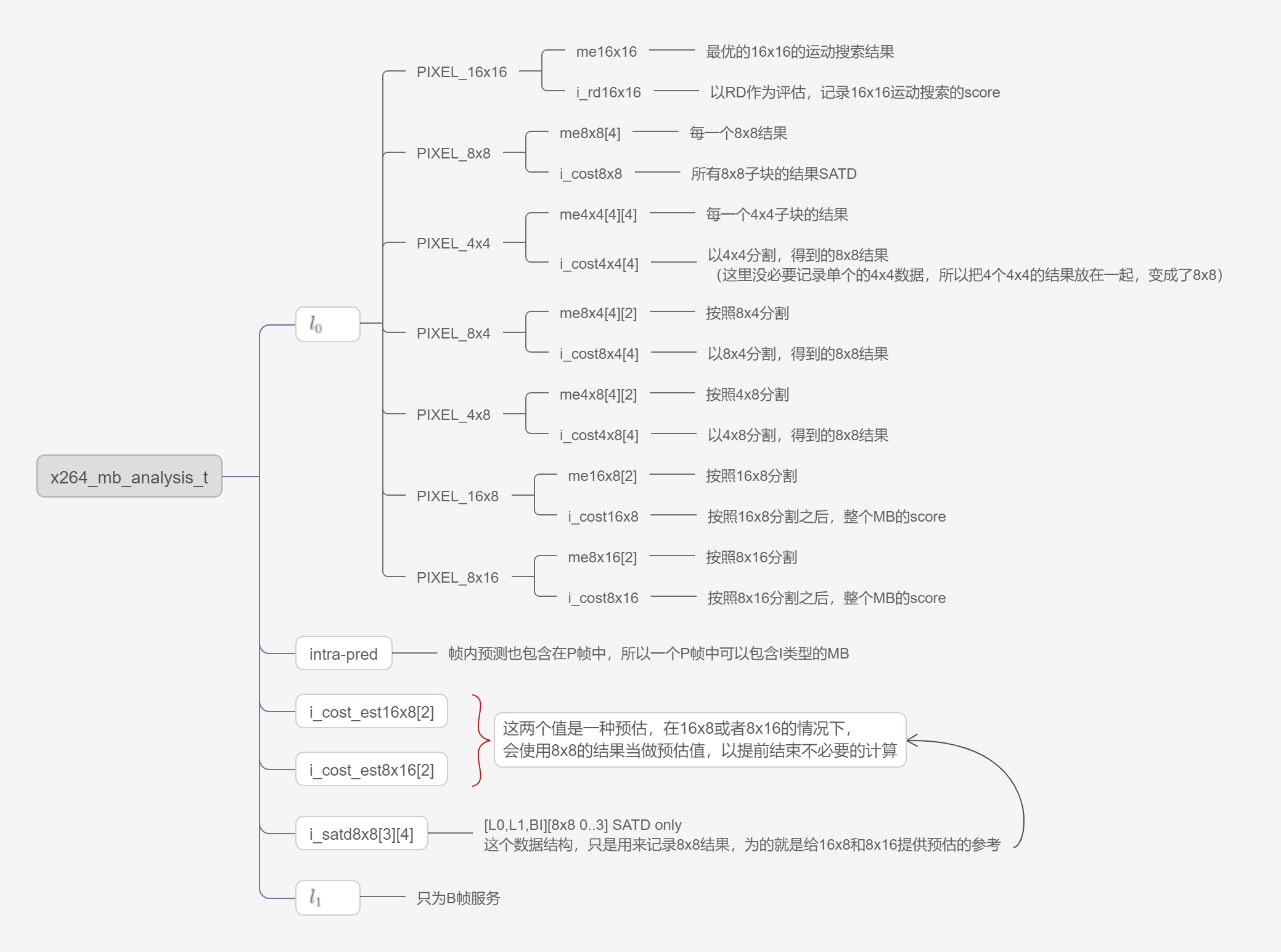
在选出最优的mv和分割类型D_*之后,就可以编码了。
编码相关的数据:
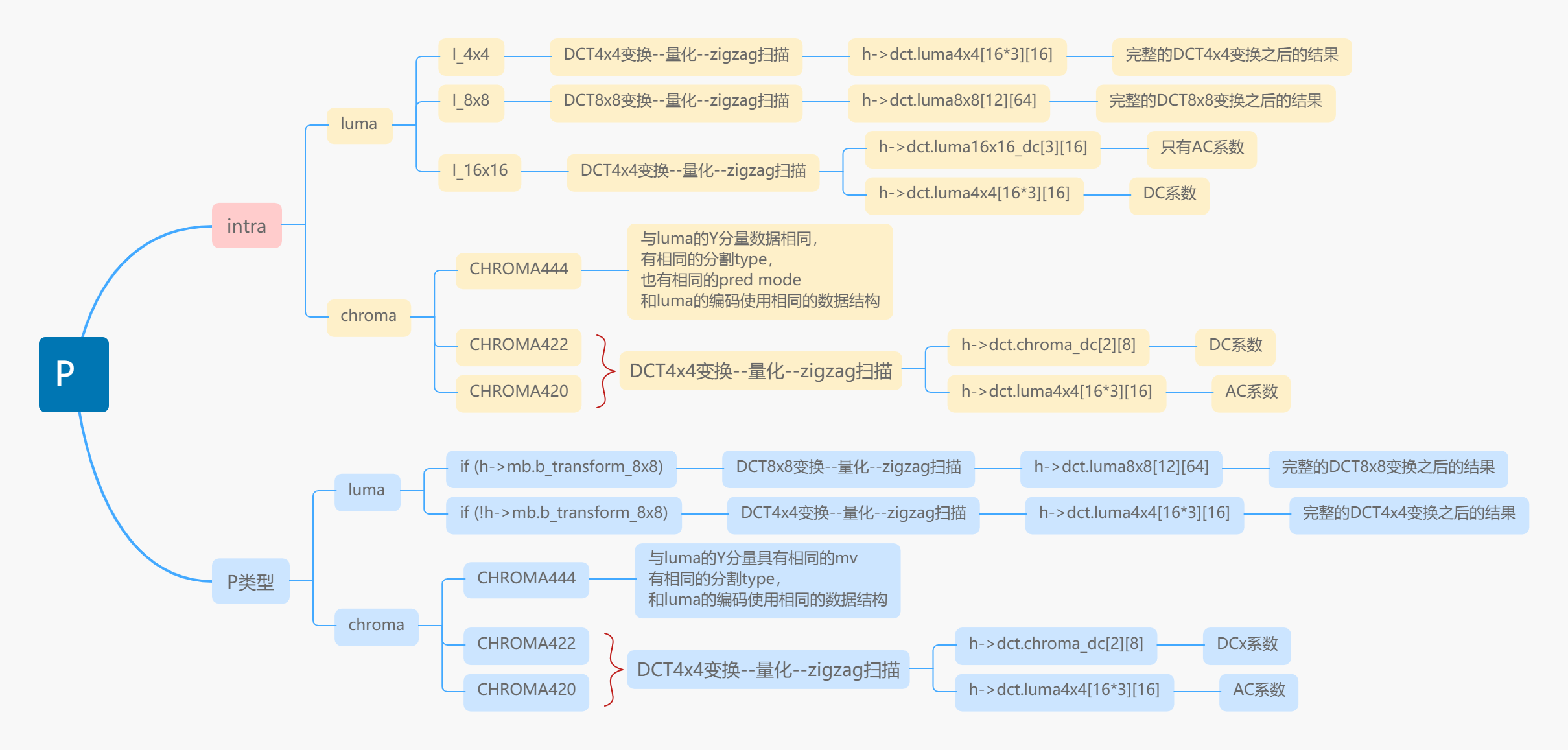
这里能够发现,对于P类型的MB,在编码阶段并不会把DC系数提取出来单独编码,为什么?
此前在另一篇关于帧内预测的解释中,已经说了,因为早期x264只有CAVLC编码,x264的很多优化策略都是围绕着CAVLC来进行的。而CAVLC要求编码系数满足由小到大,并且系数之间变化的较为均匀这个条件。因为DC系数往往和其他系数差距很大,故而x264才会把DC系数单独拎出来,组成一个新的DC矩阵,再进行DCT变换,然后才编码。
而这里,并不是x264不处理P类MB的DC系数,而是它已经用另一种方式处理了:
而在处理P类型MB的时候,已经调用了x264_mb_analyse_transform_rd/x264_mb_analyse_transform函数,试图找出用DCT8x8和DCT4x4哪一个更优。如果这里的DC系数导致了编码效率降低,那么会自动选择DCT8x8来做变换。
上图中的h->mb.b_transform_8x8变量,就是用来标记哪一种变换更能提升编码效率。这个变量在帧内预测的时候不会起作用,是专门处理P和B类型的。
同时也能发现,不管是P类型的MB、还是intra类型的MB,它们的chroma编码都把DC系数单独拎出来处理了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号