x264 帧内预测
x264 帧内预测
相关参数:
-m, --subme
- 0: fullpel only (not recommended) 运动搜索的时候,只在整数偏移的mv位置进行搜索
- 1: SAD mode decision, one qpel iteration 评估函数采用SAD(16x16MB的绝对值之和),且只进行一次半像素的运动预测的试探
- 2: SATD mode decision 评估函数采用SATD(一种类似于DCT变换的结果,更能反映编码之后的大小)
- 3-5: Progressively more qpel 随着参数增加,在运动搜索的时候试探的qpel(半像素的位置)也会更多
- 6: RD mode decision for I/P-frames 对I/P帧,先用SATD来评估,然后对每一种分割模型和pred-mode,用RD重新评估,RD=ssd + i_lambda2*bits
- 7: RD mode decision for all frames 对所有帧都:先用SATD评估,然后用RD重新找出最优的分割模型。(同上,不会进行pred mode的细致评估,只是对satd的优化)
- 8: RD refinement for I/P-frames 对I/P两类型帧使用RD模型来评估,找出最优的预测模型和分割模型
- 9: RD refinement for all frames 对所有类型帧使用RD模型来评估,找出最优的预测模型和分割模型
- 10: QP-RD - requires trellis=2, aq-mode>0 对当前的QP进行扰动试探,尝试用收敛迭代的方式,找出一个局部最优的QP,使得RD模型最优
- 11: Full RD: disable all early terminations 禁止所有的“提前终止”策略,使用RD模型的时候,会利用SATD来提前筛选掉一些不符合条件的mode,以减少RD的计算量。如果subme设置成11,那么这些“提前终止”的策略将全部禁用,对每一种mode都强制计算RD
什么是帧内预测?
即:利用帧间的MB相关性,用已经编码的MB的边缘数据,来预测相邻MB。
帧内预测的函数调用
如下图所示:

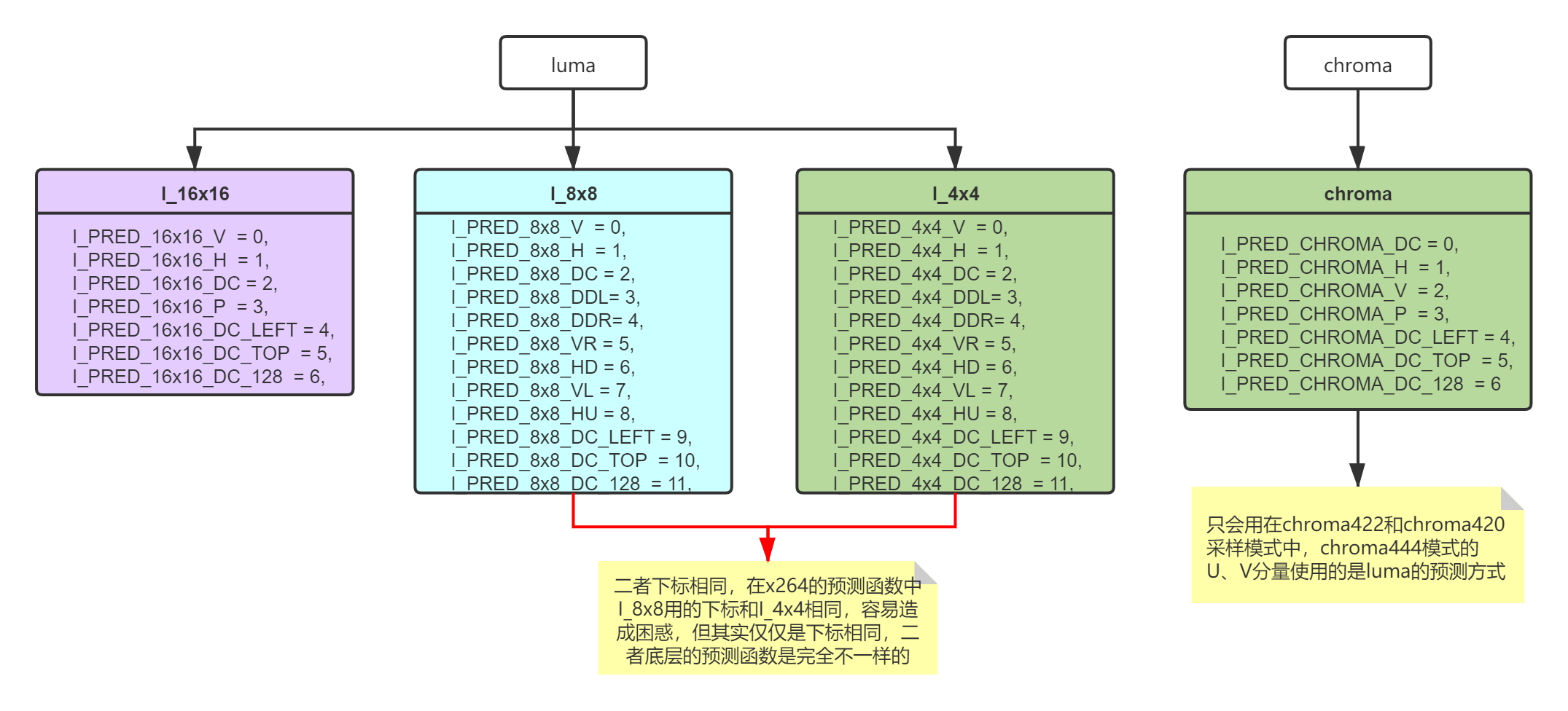
几种帧内预测mode
I帧的分割类型:
-
I_4x4 = 0
-
I_8x8 = 1
-
I_16x16 = 2
-
I_PCM = 3
其中的I_PCM,编码器会直接传输原本的图像数据,不经过残差、变换和压缩,也不会经过CABAC/CAVLC的编码,在这种模式下,占据的bits=256 * 8(即每个像素8bits,一共16 * 16 = 256个像素)。
I帧的预测模型pred mode
pred mode具体实现:
这里只列出了I_4x4的实现,关于I_8x8和I_16x16其实是一样的逻辑,只是I_8x8和I_16x16的数据量更大而已,同样的,chroma类型也是一样的。
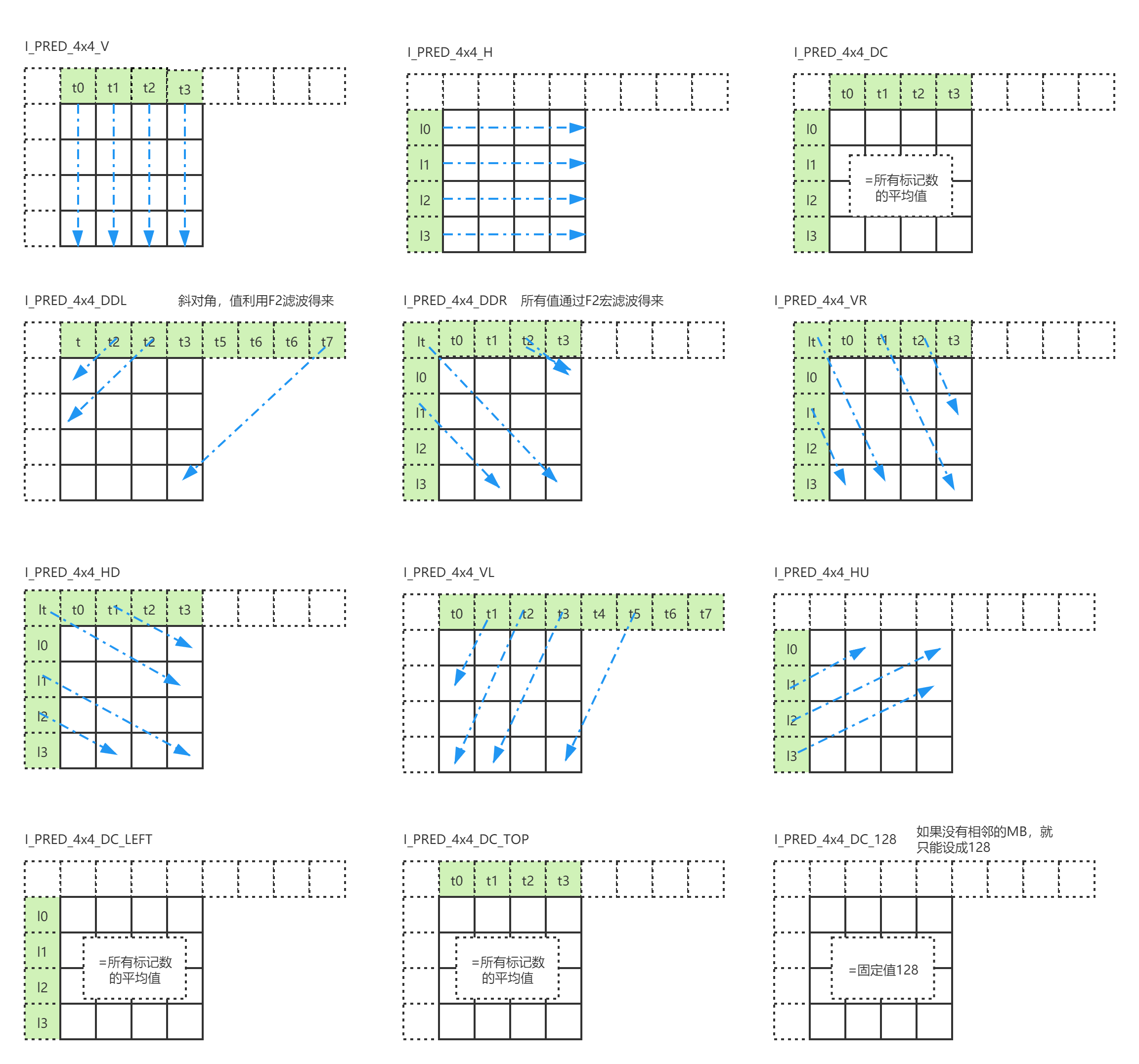
这里面没有 * _P 类型,即Plane预测,意思是利用边缘数据,按照平面方程来进行差值运算。Plane预测的计算量会比其他预测类型高很多。
预测过程
-
采用上面提到的分割类型(I_16x16, I_8x8, I_4x4)和预测模型pred mode来对每一个MB进行试探,搜索并找出最优的分割类型和预测模型pred mode
-
编码:预测数据---> 原始数据fenc减去预测数据,得到残差数据-->DCT变换--quant量化--zigzag扫描 ---> CAVLC/CABAC编码
帧内预测的逻辑并不复杂,只是试探一遍所有的pred mode和分割类型,然后找出最优的结果,在这里就没有什么多余的赘述。
但对于代码的细致内容:
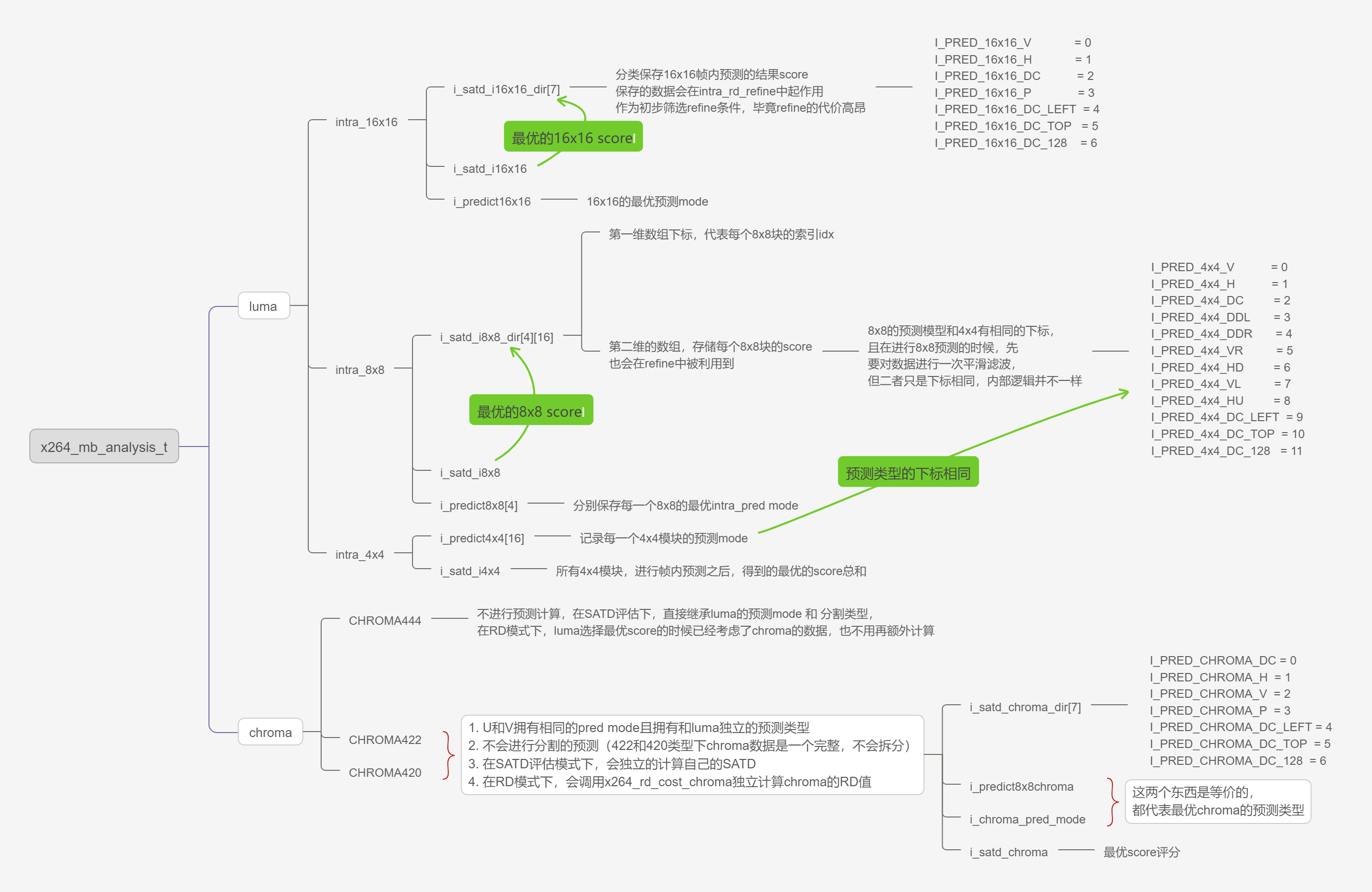
- 关于x264_mb_analysis_t这个数据结构,其实不用去细致理解里面的变量,因为没意义。这个数据结构干得事情,就是充当了一个“临时变量”。它负责记录每一种预测结果,以方便后面要用到这些结果的时候能方便拿到。(因为你总不想弄一堆全局变量来记录那些中间结果吧?那样太乱了,而且在预测计算的时候需要记录的太多了)。它所记录的数据,大部分只是结果,不会对算法逻辑有什么影响。
- 关于编码数据的存放:在得到每一种分割类型和预测模型之后,后续的编码处理,涉及到的数据结构如下。(预测类型,DCT变换之后的数据都放在哪里……)
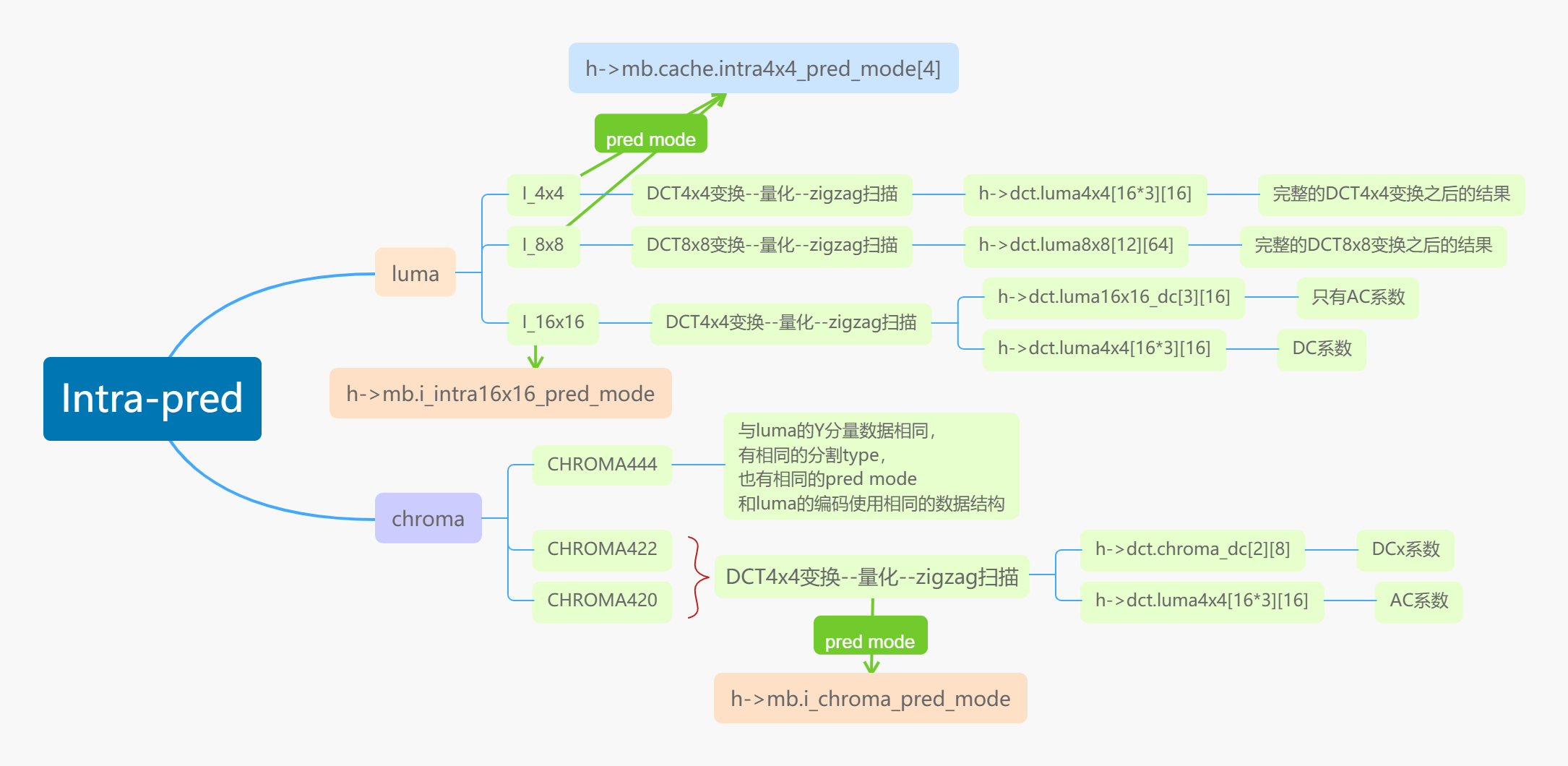
细心的人肯定发现了一些小问题:
-
为什么I_16x16在编码的时候,会单独把DC系数拎出来,放入luma16x16_dc,再对DC系数进行单独的编码?
这个问题很有意思,因为这涉及到下层编码算法的结构。在CAVLC编码中有一个有趣的假设,即zigzag扫描的数据符合由大到小的排序。而CAVLC的优化策略,也都是基于这个假设来进行的。不仅如此,CAVLC在处理数据的时候,采用了一个变量i_suffix_length来进一步预测数据间的大小关系。即:i_suffix_length在数据满足“由大到小,且数据间的差值均匀分部”这个条件的时候,能达到最大的优化效果。
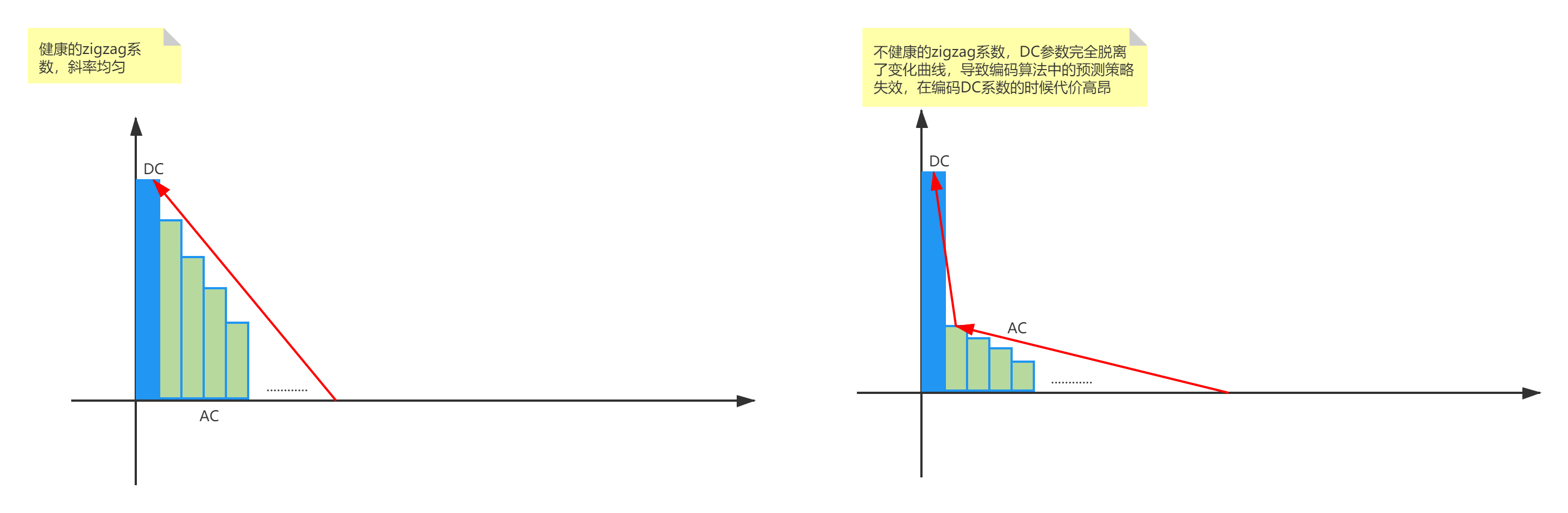
了解了CAVLC的优化策略,就很容易弄明白了:因为DC系数像是脱缰的野马一般不受控制,所以才把DC系数全都拿出来,单独放在一起,再经过一次DCT变换,然后编码。如此才能达到最佳的压缩效果。
-
既然把DC系数单独拿出来有这么多好处,为什么I_8x8和I_4x4不这么做?
-
让我们先回答I_4x4为什么不这么做:在I_4x4中,每个4x4的子块都有自己独立的pred mode,故而每个子块的DC系数之间差异很大!请回想一下,为什么我们要先进行DCT变换再编码?是因为在任何情况下DCT变换都能达到理想的效果?答案并不是这样,DCT变换能带来的压缩性能提升,也是有一个假设的:“图像是均匀变化的,不可以完全没有规律可言”。而I_4x4模式下,把各个模块之间的DC系数搞成了完全没有规律可言,就算你把DC系数全集中在一起,也没办法享受到DCT-->zigzag--->编码带来的压缩效率。
-
关于I_8x8,将子块的大小设定成8x8,每个8x8子块内部是高度关联的,那么为什么这里又不把子块间的DC系数提取出来?其实x264已经考虑了这件事了,但单独提取8x8子块的数据太繁,所以直接把DCT变换的规模从DCT4x4变成了DCT8x8,相当于把8x8这个子块看成一个整体,统一处理,也就没必要再单独处理DC系数了。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号