x264 psy_trellis详解
x264 psy_trellis详解
定义:基于心理视觉模型的量化方法
相关参数:
-
--psy-rd float:float : Strength of psychovisual optimization
#1: RD (requires subme>=6) -------------RDO相关的参数,与本文没有关系
#2: Trellis (requires trellis, experimental) ---------------psy_trellis的强度参数,值越大就代表越看重优化之后的bits大小,反之则更注重图像的质量(仍旧在实验阶段的模型)
-
-t, --trellis
Trellis RD quantization. - 0: disabled
- 1: enabled only on the final encode of a MB -------这里的意思是,只有在最后真正编码MB的时候,才使用trellis量化的策略
- 2: enabled on all mode decisions --------在前期评估的时候(运动搜索阶段),已经开始使用trellis量化来评估了,这种模式会增加计算量
psy_trellis到底在干什么?它真的是一种量化方法?还是一种算法?
严格来说,psy_trellis是一种算法,而不是一种量化矩阵,只是它的行为(或者说函数名字)伪装成了量化矩阵。在正常编码阶段,数据会经过DCT变换->quant量化->zigzag扫描->编码,这几个阶段。而psy_trellis干的事情,就是把quant量化之后的数据拿出来,然后对每一个系数coef进行评估,试图找出到底是coef-1好,还是原本的 coef更优秀,然后找出一串最优的编码。
所以经过psy_trellis量化的系数,它的解码过程和正常的解码一点区别也没有,因为psy_trellis并没有提供另一种更优秀的量化矩阵,所以也用不着特定的反量化矩阵了。它做的仅仅是评估一下“如果把系数coef减去1,会不会得到更优秀的结果”这件事。
至于为什么要这么做,或者说为什么coef-1会比原本的coef更优秀,究其原因还是因为quant量化带来的精度损失,再加上x264采用了严格的四舍五入的整数运算策略,这就导致有时候coef-1反而对图像更友好,而且还能减少编码之后的bits。
要实现这个功能,在CABAC和CAVLC下是不同的,具体的一个一个的来分析。
在CABAC中的具体实现
psy_trellis, 这里所谓的后缀_trellis,并没有特别的含义,只是代表是psy采用的算法是一种网格搜索算法。而网格搜索算法,秉承的原则就是:“基于局部最优,以达到全程最优”的策略。
再看CABAC的编码过程,它首先会编码zigzag扫描之后系数coef的mask(mask的每一位代表coef是否为0),然后再对每个系数coef采用zigzag扫描的倒序逐个编码,最后再编码当前系数coef的符号位。
而CABAC每编码一个coef,它的node_ctx状态就会发生迁移,故而就衍生出一个问题:psy_trellis在试探coef-1和coef的时候,并不能简单的比较两者哪一个更优,因为编码coef-1或者编码coef之后,CABAC的node_ctx状态并不一样,而这会对接下来需要编码的数据产生影响。简单来说,你编码了一个数据之后,就改变了CABAC的概率分布,然后在编码接下来参数的时候,进而影响了后续coef的大小。
这里采用的是,类似于人工智能中的路劲搜索算法,又称为trellis搜索。构建一个网格,对每一条编码路径的每一种可能都保留下来,并且综合评估最终的结果。
好在CABAC的node_ctx状态转换并不复杂,只有8种状态,所以这个网格搜索算法的叶子节点顶多只有8个,只要针对每个coef依次遍历所有叶子节点,然后找出最优的编码方案即可。
cabac node_ctx状态转化数组:
static const uint8_t coeff_abs_level_transition[2][8] = {
/* 编码一个等于1的coef之后的跳转数组 */
{ 1, 2, 3, 3, 4, 5, 6, 7 },
/* 编码一个大于1的coef之后的跳转数组 */
{ 4, 4, 4, 4, 5, 6, 7, 7 }
};
简单的分析,就能看出node_ctx是一种只会增加的数值(初始状态node_ctx=0),它的跳转状态是一直递增的,永不可能往回退。(其实这和CABAC的设计策略有关系,因为一个node_ctx就代表一种概率,CABAC想要表达的是:每个系数的coef期望概率都不一样,因为是倒序编码,越往后coef的期望值就越大,CABAC则通过这种方式,以不同的编码概率来最优化每一个coef)
CABAC中的trellis搜索策略
既然知道了原理,再看x264中的具体实现。在x264中为了降低计算复杂度,把node_ctx细分成了两种状态,当cabac只编码了coef==1的情况,此时node_ctx只属于[0,1,2,3],称为ctx0,而如果cabac处理了coef>1的情况,node_ctxs取值范围是[1,2,3,4,5,6,7], 称为ctx1。
具体如下图:

在具体算法实现中,主要由两个叶子节点的数组构成nodes_prev[8]和nodes_cur[8],这两个数组都代表了cabac中的node_ctx,如果node_ctx符合 'i' --> 'j' 的转化状态且此时 'i' 作为起始状态是有效的,那么就尝试从‘i’状态编码当前的系数coef,并且将结果保存在 ‘j’ 状态中。(这个过程是严格符合CABAC编码的)
为了优化计算,减少搜索的叶子节点数目,x264提供了如下几个trellis_coef{m}_{n}的函数(其中m代表需要编码的系数coef,n代表上图提到的ctx{n}):
- trellis_coef0_0:

- trellis_coef1_0:

- trellis_coef0_1:

- trellis_coef1_1:
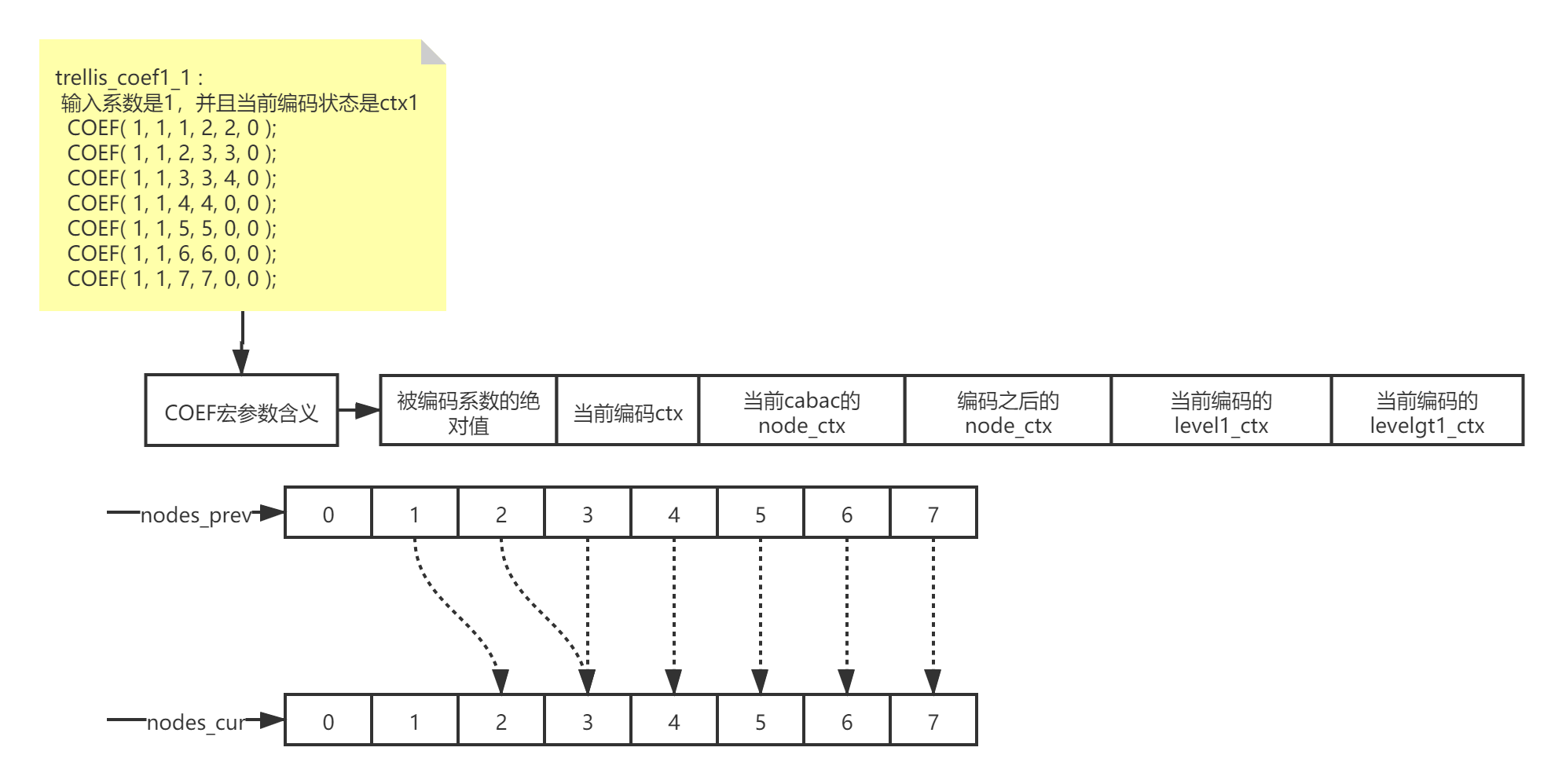
- trellis_coefn_0:

- trellis_coefn_1:

通过这几个trellis_coef*系列的函数,就能对每个输入的coef和coef-1进行试探,并构建出一个trellis树形结构。然后只要找出哪一个树形分支的score最低,就是最优的编码序列了。
算法中的数据结构详解:
树状结构Trellis基本类型
typedef struct
{
uint64_t score;//当前状态的score=编码之后的大小+图像损耗的评估,分值越大,结果越差
int level_idx; //指针,指向父亲节点所在的内存偏移位置
uint8_t cabac_state[4]; // 用来保存当前cabac state的数组,因为cabac编码的特殊性,只需要4大小的数组
} trellis_node_t;
//因为只关心搜索树的父亲节点位置和编码系数,所以这里的树状结构和trellis_node_t长得并不一样,也容易造成混淆,但这里才是构建trellis树的地方,类似于路径搜素算法,只是搜索的工作已经交给了trellis_node_t去维护,所以这里只需要记录最优的结果就行了
typedef struct
{
uint16_t next; //父亲节点位置,只要逆向搜索到trellis的起始节点,就能找出最优的cabac编码系数
uint16_t abs_level; //cabac编码系数coef的绝对值
} trellis_level_t;
宏SET_LEVEL所干的事情
#define SET_LEVEL(ndst, nsrc, l) {\
if( sizeof(trellis_level_t) == sizeof(uint32_t) )\
M32( &level_tree[levels_used] ) = pack16to32( nsrc.level_idx, l );\
else\
level_tree[levels_used] = (trellis_level_t){ nsrc.level_idx, l };\
ndst.level_idx = levels_used;\
levels_used++;\
}
-
创建一个tree的节点level_tree[levels_used],用来保存nsrc这个node的数据。这里只关心nsrc的父亲指针(nsrc.level_idx)和nsrc所携带的编码系数(l)
-
将当前ndst的指针(ndst.level_idx)指向nsrc所在的tree的节点位置(就是nsrc所在tree的内存偏移levels_used)
这样就构建了一个树形结构。
需要详解的函数
这个函数容易让人头晕,它的内容并不是很复杂,但参数太多了,而且参数的命名也不是很直观,在这里把每一个参数的含义写清楚,方便记忆和查阅。
int trellis_coef( int j, //当前编码的cabac的node_ctx
int const_level, //用来判断当前编码系数coef是否大于1,以选择合适的cabac ctx
int abs_level, //实际的编码系数coef,但这里并不会真正的编码,仅仅作为SET_LEVEL的参数传递给trellis tree
int prefix, //在cabac编码中,如果coef<15,那么就连续往cabac里写入coef-1个1,而这里的prefix就是当前coef需要写入1的个数,通过prefix可以查询一个预先处理好的列表x264_cabac_size_unary得到这些‘1’的cabac编码之后的大小
int suffix_cost, //在cabac编码中,coef>15的部分会被转化成Golomb编码,然后bypass进cabac编码器,这部分编码大小就=golomb(coef-15)
int node_ctx, //编码系数coef之后,node_ctx变成的结果
int level1_ctx, //如果编码的coef==1,就用这个值作为cabac的ctx,此时写入一个0,如果coef>1,也需要用到这个ctx,此时写入一个1
int levelgt1_ctx, //编码coef>1所用的ctx,cabac需要在这个ctx里写入coef-1个数目的‘1’和coef>15的golomb编码,但在这个函数里并不会这么做,因为这里并不是编码的时候。这里只需要拿到编码之后的大小即可,所以提前算出了x264_cabac_size_unary数组,方便查询编码之后的大小
uint64_t ssd, //图像的损耗程度,最终的评分score=ssd+编码之后占用的字节数
int cost_siglast[3], //在cabac编码中,经过DCT->quant->zigzag_scan之后会得到一组数据,此时这组数据中有0,也有非0值,这就需要编码一个mask用来标记哪些数据是0和1。如果数据是0,那么在mask中用0表示,反之用1表示。这个cost_siglast就代表编码当前coef的mask大小,其三维数值分别代表{如果当前mask位是0的编码大小,当前mask位是1的大小,当前mask是1且是最后一个非0系数的编码大小}。在实现psy_trellis功能的时候,这里的编码顺序和cabac是反过来的,最后一个非0系数在一开始就编码了,所以当j==0的时候会使用cost_siglast[2],其他时候都使用cost_siglast[1]。使用这个函数不存在编码0的时候,所以cost_siglast[0]永远不会被用到。
trellis_node_t *nodes_cur,//当前编码的node,因为cabac编码的时候顶多有8种node_ctx,所以这里的数组长度是8
trellis_node_t *nodes_prev, //前一层编码的node,这里可以理解成一个trellis树状结构的叶子节点,通过这个叶子节点来搜索最优的编码路径
trellis_level_t *level_tree,//结果保存在这个tree里面,仅仅用来保存结果
int levels_used, //level_tree的memory分配索引
int lambda2, //编码之后的bits需要乘以这个系数,才能和ssd处在同一个“单位/量级”下进行加权
uint8_t *level_state //真正的CABAC state数组。通过这个数组可以查询到相应ctx的概率(也就是state),这里只是模拟计算编码之后的大小,所以不能修改这个数组,真正需要修改和保存的state会放在trellis_node_t::cabac_state[4]数据结构里面。
);
至此关于CABAC的psy_trellis实现方法就这多了,接下来看一看CAVLC的实现方式。
CAVLC中的实现方式
CAVLC编码的大致实现:先把[尾部abs_coef==1的系数个数 + nC + 总共的非0系数]打包起来,成为一个VAVLC的header进行统一编码,然后编码拖尾系数的符号位,之后编码所有非0系数,再之后编码系数的mask。
因为每一部分的编码都是息息相关的,改变任何一个系数coef都会引起整体产生较大的变化,故而导致它并不能使用trellis搜索算法,只能采用暴力搜索的方式来找到最优的编码序列。
CAVLC的实现代码就比较直白了,大致流程如下:
for coef in DCT:
quant = coef进行正常的量化操作,得到量化之后的值
deadzone = 也是coef的量化,但此时量化的偏移比例从正常的0.5变成了0.25,以图提前得到一个更合适的量化值
初始化数组:coefs= 所有coef的deadzone值
while True:
遍历搜索一次coefs,找出一个f,使得f采用coef-1(或者coef)之后,整体的score最小,然后就把当前的f作为一次遍历的最优结果,并且更新到coefs数组中。如果遍历一次列表之后没有找到更优的结果,则结束循环
CAVLC和CABAC想要达成的目的都是一致的:评估一下,到底是当前的系数coef更好,还是coef-1更优秀,只不过因为编码算法的不一样,在CABAC下能以更快速的trellis模型得到结果,而CAVLC只能采用这种蠢办法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号