x264 lookahead阶段详解
x264 lookahead阶段详解
lookahead阶段,主要作用是决定输入帧的类型,计算MB-tree两大功能。
本章专门讨论帧类型决策,当一帧Frame被传入x264_encoder_encoode函数之后,Frame会被加入到h->lookahead->next当中,并且Frame的类型会被标记成AUTO类型,此时lookahead线程就会开始异步计算,最终输出一串BBBPBPP的帧序列。
细节如图所示:
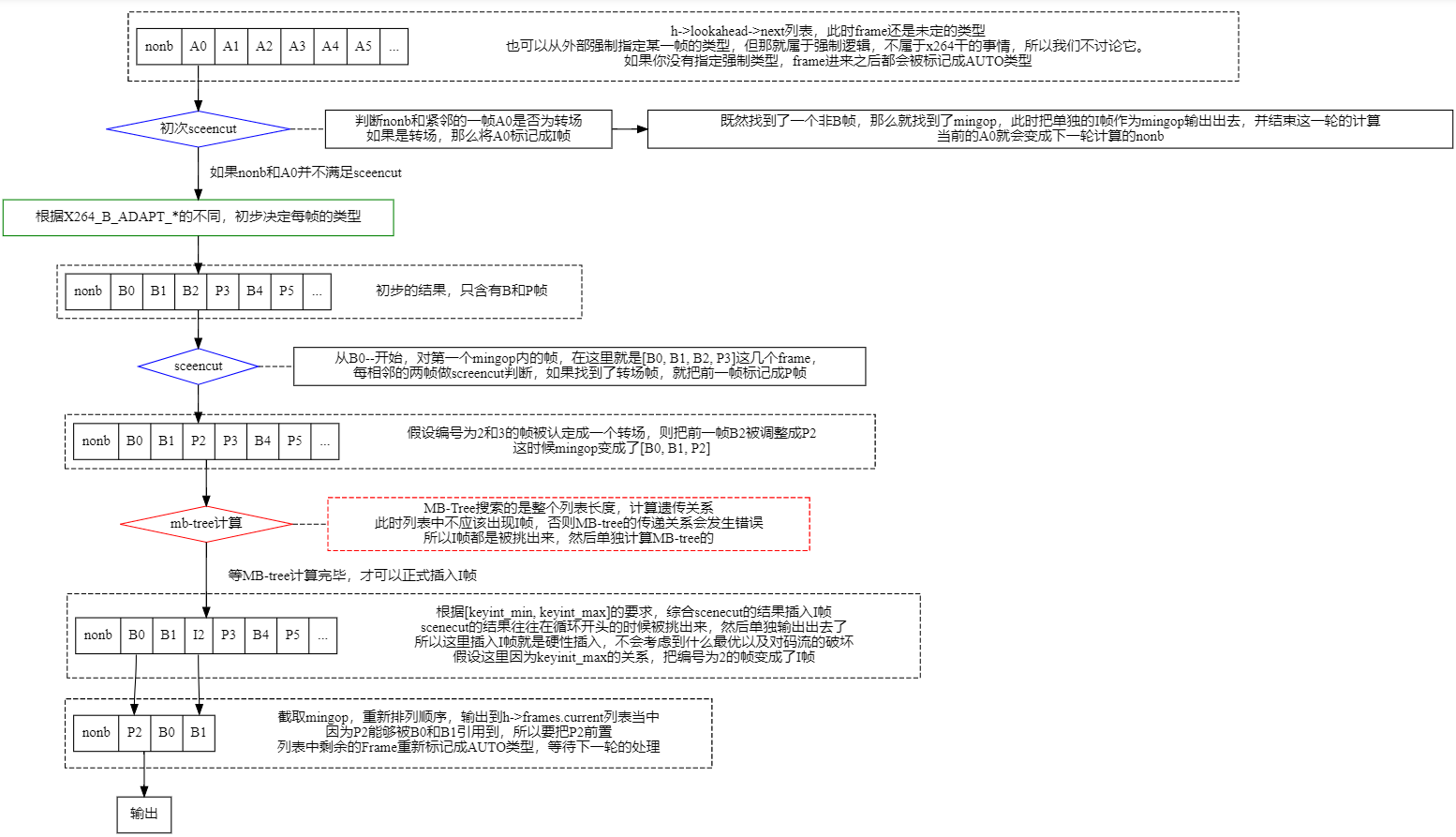
mingop: 虽然x264每次分析很长的一串Frame序列,但最后截取出来的一定是连续的B + 一个非B帧这样的mingop,若是序列的开头被标记为P帧或者I帧,那么就把P帧或者I帧当做一个独立的mingop输出出去。
在进一步细说之前,让我们先以设计者的角度,来品一品这张图的细节。
故事是这样的:
-
x264在正式编码(encoder)之前需要确定每一帧的类型,所以需要一个叫做lookahead类型的线程来帮忙计算。于是lookahead勤勤恳恳的算出来一串序列BBPPBBP,然后告诉x264这种序列的排布可以达到最小的码流效果。
-
然后x264苦着脸,说:“lookahead兄弟,我忘记告诉你,我身上有一道枷锁,必须每隔[keyint_min, keyint_max]的Frame数目就插入一个I帧, 你这串BBPPBBP虽好,但不符合要求,奈何……”
-
lookahead听完,当即彻夜未眠,之后请出scenecut来帮忙。scenecut在参考了[keyint_min, keyint_max]限制之后,弄出了一套方案,便是把BBPPBBP这串序列中最有可能是转场帧的Frame挑出来当做I帧,如此一来,既能满足需求,又可尽量减少码流的增加。
-
x264听完scenecut的方案,不由得大喜,但细细一思,又露出苦色:“家中有一个憨憨兄弟MB-tree,此人分析遗传信息(propagate)时只能接受B和P两种帧类型,若是胡乱插入I帧,MB-tree休矣。”
-
lookahead又献计:“如此好办也,将scenecut逻辑拆成两分,一份放在开头处挑选单独的I帧,此时I帧作为独立的mingop输出出去,不需担心MB-tree。而在后半段scenecut逻辑当中,若是发现转场帧,则仅仅将前一帧设置为P帧,将转场帧和前面的mingop强制断开,如此一来,即在不破坏MB-tree的前提下,实现了scenecut。”
-
x264终于喜笑颜开,遂采用此方案。
好了,听完这个小故事,想必大家都知道为什么lookahead的逻辑设计长这样了。其实它的设计思路很单一,只是为了戴上[keyint_min, keyint_max]这个枷锁的情况下,找出一串最优的帧序列。
先来弄清楚,最优帧序列是怎么选出来的
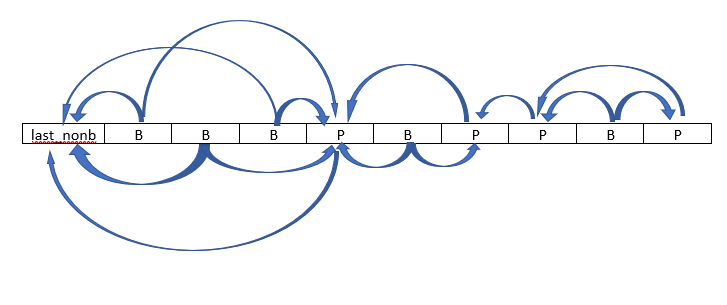
首先我们要明白一件事,lookahead阶段仅仅是一种预测手段,故而它不会和正式编码一样拥有复杂的引用关系,它的引用关系可以说简单到了极致:
-
B帧只会引用前后两个非B帧
-
P帧只会引用紧邻的前面一个P或者I帧
它的引用关系如下所示:
即便考虑到BREF帧,也是固定的(当h->param.i_bframe_pyramid>0的时候,会把连续的B帧中间挑一个当做BREF,BREF可以被别的B帧引用,这是一种优化手段):
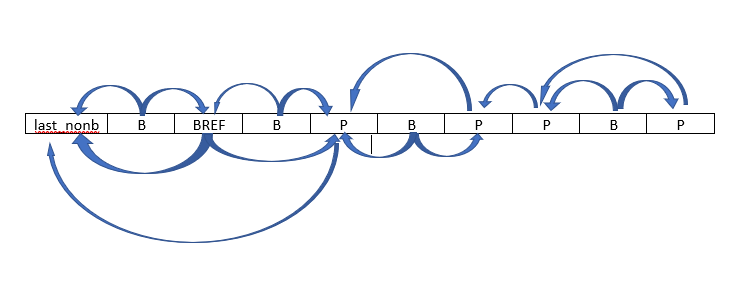
所以只要确定了基本的BBBPBBP序列,就可以得到这种固定的引用关系。lookahead只需要根据选定的帧序列计算出每一帧的码流大小,选择一个码流最小的帧序列即可。
所以这里没有什么花里花哨的动作,硬核搜索,每一个搜索到的序列都计算一遍,然后找出最优的。
当然在lookahead当中,使用的数据并非原始Frame的数据,而是经过向下采样的lowres数据,所以计算量要小很多。可即便如此,计算帧之前的引用cost的时候,也需要和正式编码一样进行运动预测,它的计算代价也不小,所以在这里x264设计了多线程计算模型。
硬核搜索,也是要讲策略的,x264中有三种策略:
X264_B_ADAPT_TRELLIS搜索策略:
假设已经找到的最优的3个Frame的序列BPP,此时又来了一个新的Frame,我们来看看它是怎么找出4个最优序列的:
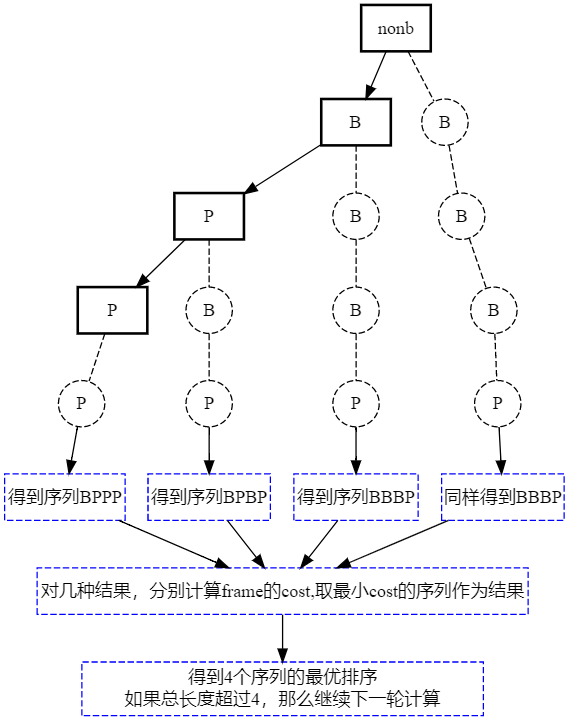
再看看X264_B_ADAPT_FAST策略:
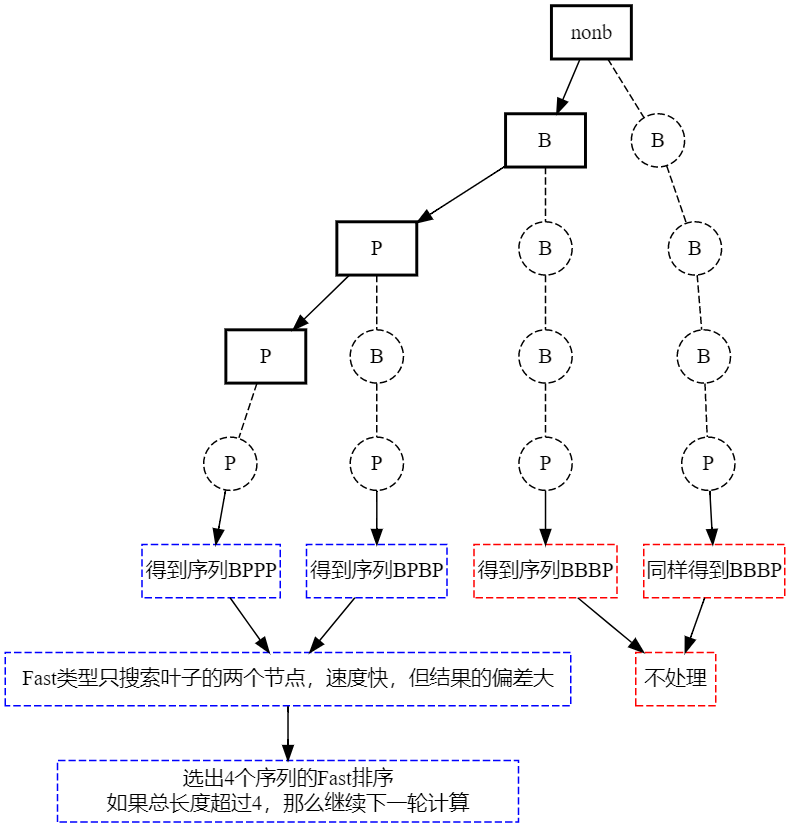
最后是X264_B_ADAPT_NONE:
这种模式下,并不会搜素出最优的序列,lookahead只是机械式的输出一串B和P的序列。序列的规则是:连续i_bframes数目的B帧 + 一个P,然后又是连续_bframes数目的B帧 + 一个P,如此反复循环。
经过反复计算之后,便得到了一串最优编码的Frame序列
只有B和P当然不够,还需要scenecut来帮忙
因为每隔一定帧就插入I帧,scenecut就像是戴上了一个枷锁,它一边挑选I帧的时候,还必须满足挑出的I帧在[keyinit_min, keyint_max]的范围内。
scenecut定义:用来判断两帧是否属于转场。
实现细节:通过计算P0帧和P1帧的inter_cost和intra_cost来判断二者的相似度。
假设有相邻的两帧:P0, P1(P0在P1之前被播放出来)
先调用silicetype_frame_cost计算p1的intra_cost, 以及p1相对于p0的inter_cost,然后我们就得到了P1的两个参数:
scenecut的目的是为了找出一个合适的I帧,以符合“每隔一段时间插入I帧”的硬性需求。故而离上一次I帧(其实是last_keyframe)越远,那么scenecut就越急切的想找出一个合适的I帧,因为如果在一定期限内找不出合适的I帧,等达到了最大间隔h->param.i_keyint_max的时候,它就“违约”了,这时候它会不管P1合不合适作为I帧,都强制把P1设置成I帧。
当然,scenecut肯定不想“违约”,因为把不合适的P1设成I帧会浪费大量的码流。所以在最终的期限到来之前,scenecut会一点点的降低选择标准,争取在期限内找出合适的I帧。
scenecut的逻辑好比一个青年,他必须在30岁之前就找到新娘,否则30的时候,家族长辈会强制让他娶如花小姐。在20岁的时候,他的择偶标准是很高的,但随着年纪的增长 ,他在层层恐惧之下,择偶标准也会越来越低……
所以仅仅用inter_cost和intra_cost来判断scenecut是不够的,它还需要一个变量:
i_gop_size = frame->i_frame - h->lookahead->i_last_keyframe;
i_gop_size代表距离上一次关键帧的间隔。
这些参数都是x264自动计算的,还有一个外部可控参数:
f_thresh_max = h->param.i_scenecut_threshold / 100.0
i_scenecut_threshold默认是40,所以f_thresh_max默认是40%
接下来就可以比较了,当满足以下条件的时候,就认为P0和P1之间是一个转场:
pcost >= (1.0 - f_bias) * icost
//pcost越大,就说明二者差距越大,就越可能是一个scenecut
//但f_bias似乎没提到? 别急f_bias是scenecut的“择偶”标准,它是一个不断变化的参数,f_bias越小代表“择偶”标准越严格。
看看f_bias是怎么计算的,我不想贴出来一大段代码,因为那样太乱了,让我们一点点的来看:
f_thresh_min = f_thresh_max * 0.25;
if( i_gop_size <= h->param.i_keyint_min / 4 || h->param.b_intra_refresh )
f_bias = f_thresh_min / 4;
i_gop_size很小,这时候的scenecut没有“满足成亲条件,仍旧是幼年阶段”,那么scenecut心里一点也不着急,它的择偶标准也高到离谱
else if( i_gop_size <= h->param.i_keyint_min )
f_bias = f_thresh_min * i_gop_size / h->param.i_keyint_min;
gop_size在一点点接近h->param.i_keyint_min(也就是scenecut的法定年纪),scenecut开始有一点着急了,降低了一点点标准。但它这时候还是很高傲,因为用的系数是f_thresh_min,f_bias仍旧很小。
最后:
else
{
f_bias = f_thresh_min
+ ( f_thresh_max - f_thresh_min )
* ( i_gop_size - h->param.i_keyint_min )
/ ( h->param.i_keyint_max - h->param.i_keyint_min );
}
scenecut彻底成年,它必须挑出合适的I帧,挑到之后立即拿去刷新key_frame;随着i_gop_size的增长,它也会一点点的降低标准。而它在最后的关头,也就是i_gop_size=h->param.i_keyint_max的时候,终于把标准降低到了f_bias=40%(这时候它喊着不能再降了,然后被强迫娶了如花小姐……)
除去上面的一套选择标准,scenecut还有重要的宏观策略:
在某些情况下,即便发现了一些合适的帧,scenecut也不能认定了对方,因为视频画面中除了转场,还有一种叫做“Flash”的东西。
Flash:突然闪出来的画面,它一闪即逝,虽然和别的帧格格不入,也完全符合scenecut的标准,但Flash出现的片段太短了,不值得将它认定成scenecut
这其中的重要原因是,scenecut每次挑出来的I帧,都应该能作为一个重要的引用帧,如果你跳出来的是Flash,那么只是平白的浪费了码流,因为Flash与后续帧的格格不入,后续的帧也没办法有效的引用它,这样可能会出现连续的I帧,显然这不是我们想看到的。
想要识别出Flash,先要把搜索范围延伸一下,对于P0和P1两个相邻的帧,首先要把搜索范围向后扩大成[p0, p0 + i_bframes + 1]:
可以认为搜索范围是一个mingop
-
识别AAAAAABBBAAAAAA类型的Flash,这种frame的序列,虽然中间出现了BBB三帧,但因为BBB之后又出现了A类型,而且A显然连续性更强一些,那么就认为B是一种Flash,不会把B升级成I帧。
-
识别AAAAABBCCDDEEFFFFFF,这里的A,B,C,D,E,F都各自不同,互相之间都满足scenecut的条件,但因为sceencut处理的是一个mingop的小区间,它不允许在小区间内出现这么多I帧,所以只把最后一个E当做scenecut。
第二种情况比较难理解,代码中采用策略是:拿区间内的每一帧和最后一个F帧比较,直到找到最后一个E,从这里开始,后续都是FFFFF的连续一样的帧了。所以就认定最后一个E为scenecut。
这样选出来的scenecut比较合理,因为至少保证了后续帧是“相似的”,可以减少后续帧的码流大小。
识别出scenecut帧之后,就要处理MB-tree了,不过MB-tree的篇幅有一点长,而且和帧的选择策略没有一丁点的关系,就留待其余章节再说。
在算完MB-tree之后,lookahead就正式完成了它的使命,输出了一串符合要求的帧序列给正式编码进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号