Django学习之路03
django项目生命周期
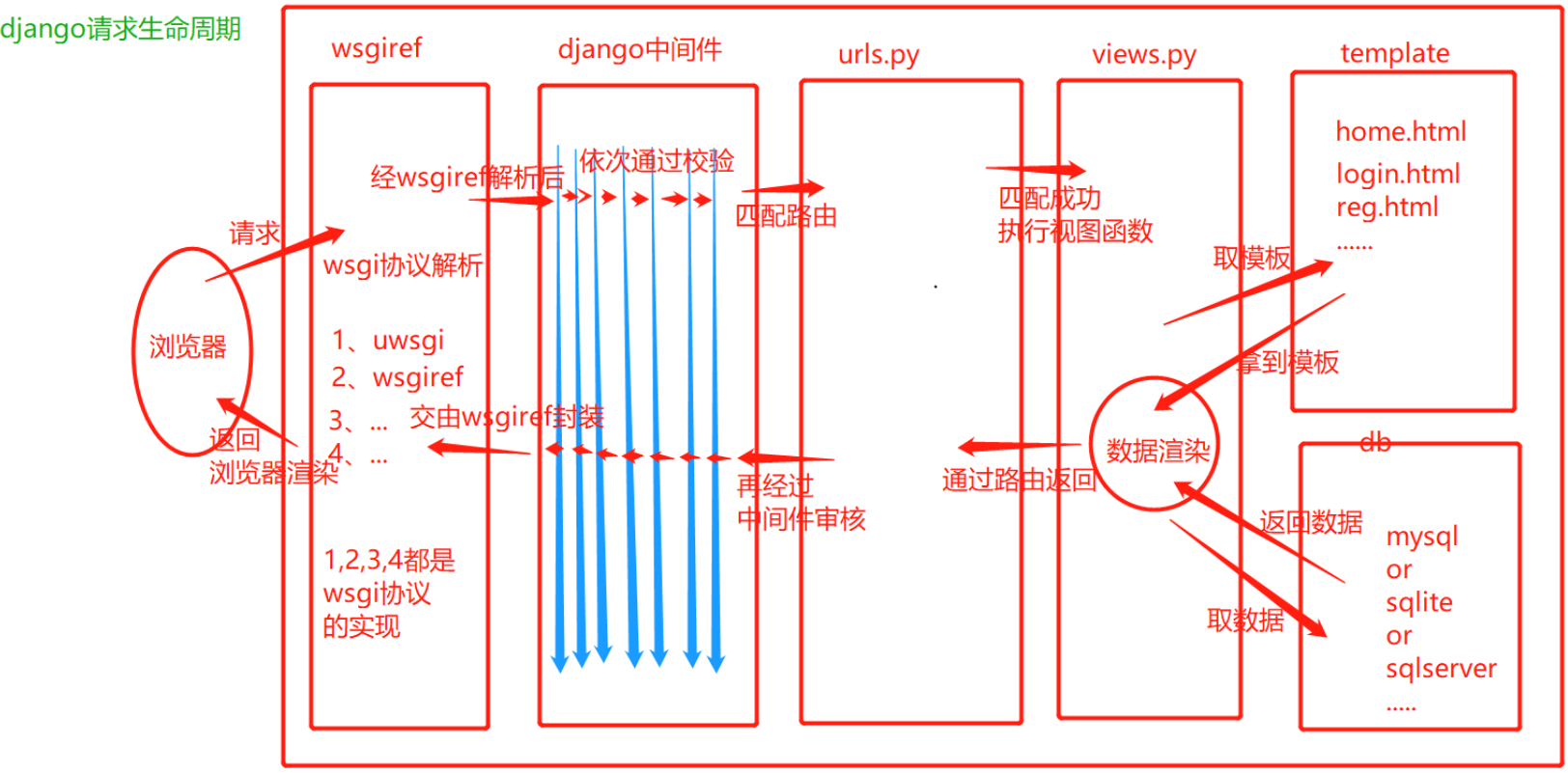
路由层
路由匹配
#urls中的urlpatterns #url()方法 urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^$',views.home), url(r'^test/$',views.test), url(r'^testadd/$',views.testadd), url(r'',views.error) ]
注意:第一个参数是正则表达式,匹配规则按照从上往下一次匹配,匹配到一个之后立即匹配,直接执行对应的视图函数
#网站首页路由 url(r'^$',views.home)
django在路由的匹配的时候 当你在浏览器中没有敲最后的斜杠,django会先拿着你没有敲斜杠的结果取匹配,如果都没有匹配上,会让浏览器在末尾加斜杠再发一次请求,再匹配一次 如果还匹配不上才会报错。
如果你想取消该机制 不想做二次匹配可以在settings配置文件中 指定
# 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项 APPEND_SLASH=True
补充:当所有路径都没匹配上时404
无名分组
url(r'^test/([0-9]{4})/', views.test) #路由匹配的时候 会将括号内正则表达式匹配到的内容 当做位置参数传递给视图函数 #例如test(request,2019)
有名分组
url(r'^test/(?P<year>\d+)/', views.test) #路由匹配的时候 会将括号内正则表达式匹配到的内容 当做关键字参数传递给视图函数 #例如test(request,year=2019)
无名和有名不能混合使用!!!
但是,同一分组下可以使用多个
# 无名分组支持多个 url(r'^test/(\d+)/(\d+)/', views.test), # 有名分组支持多个 url(r'^test/(?P<year>\d+)/(?P<xx>\d+)/', views.test),
反向解析
何为反向?
正常的请求流程是先走路由,在执行视图函数渲染模板,当我们在模板或者视图函数中需要获取路由信息时就称之为反向解析。
为什么要这样做呢?
目的是为了方便后续修改路由配置,反向解析可以获取请求路径信息,而避免直接写死路径带来的麻烦事。
本质:其实就是给你返回一个能够返回对应url的地址
如何反向解析?
首先要给url和视图函数对应关系起别名
url(r'^index/$',views.index,name='kkk')
然后在前端和后端上分别进行反向解析
#后端反向解析 #后端可以在任意位置通过reverse反向解析出对应的url from django.shortcuts import render,HttpResponse,redirect,reverse #在三剑客后面再导入一个reverse模块 reverse('kkk') #前端反向解析 {% url 'kkk' %}
如果是进行了无名分组或者有名分组该怎么做?
#无名分组反向解析 url(r'^index/(\d+)/$',views.index,name='kkk') #无名分组后端反向解析 reverse('kkk',args=(1,)) # 后面的数字通常都是数据的id值 #无名分组前端反向解析 {% url 'kkk' 1%} # 后面的数字通常都是数据的id值 #有名分组反向解析(同无名分组用法) url(r'^index/(?P<year>\d+)/$',views.index,name='kkk') #后端方向解析 print(reverse('kkk',args=(1,))) #前端反向解析 <a href="{% url 'kkk' 1 %}">1</a> #有名分组反向解析的另一种方法 #后端 print(reverse('kkk',kwargs={'year':1})) #前端 <a href="{% url 'kkk' year=1 %}">1</a>
路由分发
当应用程序体积大 模块多时需要拆分多个不同APP,同时urls也不能全都写在主路由配置中,我们可以让每一个应用都可以有自己的urls.py,static文件夹,templates文件夹,这就需要在主路由配置文件中引入其他app中的路由配置信息。
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^app01/',include('app01.urls')), url(r'^app02/',include('app02.urls')), ] #总路由中,一级路由的后面千万不加$符号
# 在应用(如app01)下新建urls.py文件,在该文件内写路由与视图函数的对应关系即可 from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^index/',views.index) ]
基于上述条件 可以实现多人分组开发 等多人开发完成之后 我们只需要创建一个空的django项目
然后将多人开发的app全部注册进来 在总路由实现一个路由分发 而不再做路由匹配(来了之后 我只给你分发到对应的app中)
补充:当你的应用下的视图函数特别特别多的时候 你可以建一个views文件夹 里面根据功能的细分再建不同的py文件。
名称空间
多个app起了相同的别名 这个时候用反向解析 并不会自动识别应用前缀,如果想避免这种问题的发生。
方法一:
#总路由 url(r'^app01/',include('app01.urls',namespace='app01')) url(r'^app02/',include('app02.urls',namespace='app02')) #后端解析的时候 reverse('app01:index') reverse('app02:index') #前端解析的时候 {% url 'app01:index' %} {% url 'app02:index' %}
方法二:
#起别名的时候不要冲突即可 一般情况下在起别名的时候通常建议以应用名作为前缀 name = 'app01_index' name = 'app02_index'
关于伪静态
静态网页:数据是写死的 万年不变
伪静态网页的设计是为了增加百度等搜索引擎seo查询力度
所有的搜索引擎其实都是一个巨大的爬虫程序
网站优化相关 通过伪静态确实可以提高你的网站被查询出来的概率
但是再怎么优化也抵不过RMB玩家(比如说advertisement)
关于虚拟环境
一般情况下,我们会给每一个项目 配备该项目所需要的模块,不需要的一概不装
虚拟环境:就类似于为每个项目量身定做的解释器环境,每创建一个虚拟环境 就类似于你又下载了一个全新的python解释器
django版本的区别
django1.X跟django2.X版本区别
django2.0里面的path第一个参数不支持正则,你写什么就匹配,100%精准匹配
django2.0里面的re_path对应着django1.0里面的url
虽然django2.0里面的path不支持正则表达式,但是它提供五个默认的转换器
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
#例如 path('index/<int:id>/',index) # 会将id匹配到的内容自动转换成整型
自定义转换器
# 自定义转换器 class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value # 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, 'yyyy') PS:路由匹配到的数据默认都是字符串形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号