
java爬虫实例-jsoup爬取豆瓣电影
添加依赖
<!--jsoup-->
<dependency>
<groupId>net.databinder</groupId>
<artifactId>dispatch-jsoup_2.8.0</artifactId>
<version>0.8.10</version>
</dependency>
<!--fastJson用于解析json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
观察页面,发现是通过异步请求获取json,再加载到页面
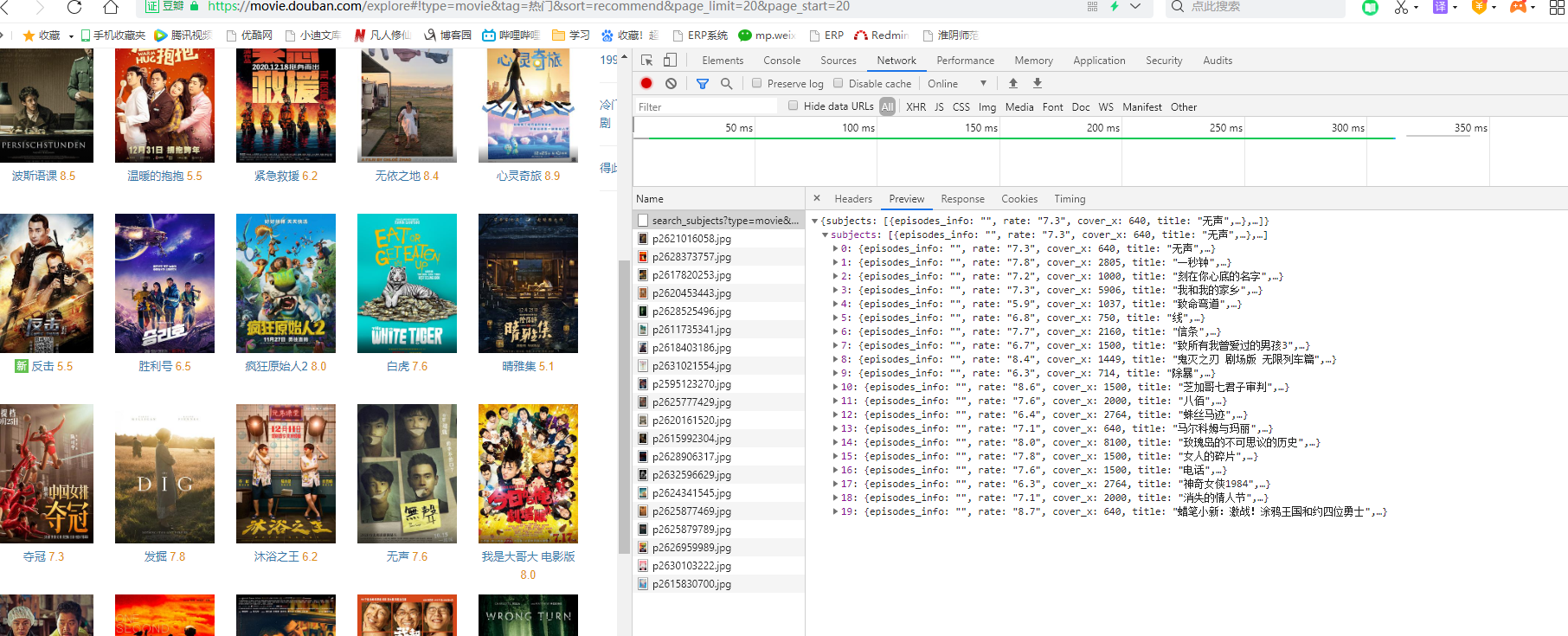
首先获取全部电影链接
class GetMovie {
//存放电影链接
public static List<String> movieList = new ArrayList<>();
@Test
void contextLoads() throws IOException, InterruptedException {
//先创建连接
String address = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=10000&page_start=0";
URL url = new URL(address);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.addRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36");
connection.setConnectTimeout(8000);
//设置从主机读取数据超时(单位:毫秒)
connection.setReadTimeout(8000);
//使用jsoup解析网页
Document parse = Jsoup.parse(connection.getInputStream(), "UTF-8", address);
//将json转成jsonObject
JSONObject jsonObject = JSONObject.parseObject(parse.body().text());
JSONArray subjects = jsonObject.getJSONArray("subjects");
for (int i = 0; i < subjects.size(); i++) {
//获取url
movieList.add(String.valueOf(subjects.getJSONObject(i).get("url")));
}
System.out.println(movieList.size());
get(movieList);
}
这样所有的电影url就全部获取到了,下面只需要将爬取每一个url中的信息
获取电影页面海报,主演,类型,评分等信息
public void get(List<String> movieList) throws IOException, InterruptedException {
List<Film> filmList = new ArrayList<>();
for (String url : movieList) {
URL request = new URL(url);
HttpURLConnection connection = (HttpURLConnection) request.openConnection();
connection.setRequestMethod("GET");
connection.addRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36");
connection.setConnectTimeout(8000);
//设置从主机读取数据超时(单位:毫秒)
connection.setReadTimeout(8000);
Document parse = Jsoup.parse(connection.getInputStream(), "UTF-8", url);
//获取名称
Elements span = parse.getElementsByTag("span");
String filmName = span.get(2).text();
//下载图片
Element mainpic = parse.getElementById("mainpic");
String img = mainpic.getElementsByTag("img").attr("src");
String[] split = url.split("/");
String uniqueId=split[4];
downloadImg(img, uniqueId);
Thread.sleep(3000);
//获取电影信息
Film film = new Film();
String info = parse.getElementById("info").text();
film.setFilmType(StringUtils.substring(info,StringUtils.indexOf(info,"类型") + 3, StringUtils.indexOf(info,"制片国家")));
film.setCountry(StringUtils.substring(info,StringUtils.indexOf(info,"制片国家") + 8, StringUtils.indexOf(info,"语言")));
film.setReleaseTime(StringUtils.substring(info,StringUtils.indexOf(info,"上映日期") + 6, StringUtils.indexOf(info,"片长")));
film.setFilmName(filmName);
film.setMainActor(StringUtils.substring(info,StringUtils.indexOf(info,"主演") + 3, StringUtils.indexOf(info,"类型")));
Elements strong = parse.getElementsByTag("strong");
film.setScore(strong.get(0).text());
Element intro = parse.getElementById("link-report");
film.setFilmIntro(intro.getElementsByTag("span").text());
film.setUniqueId(uniqueId);
filmList.add(film);
if(filmList.size()%50==0){
service.batchInsert(filmList);
filmList=new ArrayList<>();
}
}
}
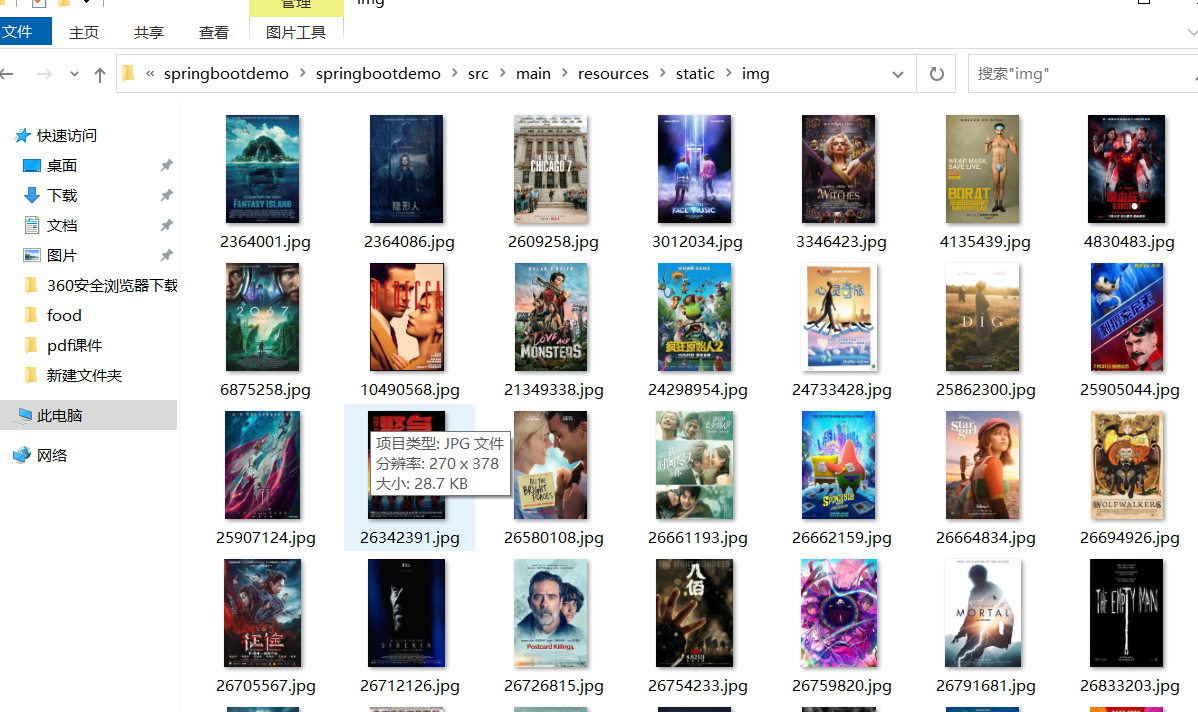
下载电影海报图片
/**
* 下载图片
*
* @param img
* @param filmName
* @throws IOException
* @throws InterruptedException
*/
public void downloadImg(String img, String filmName) throws IOException, InterruptedException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpget = new HttpGet(img);
CloseableHttpResponse response = null;
response = httpClient.execute(httpget);
InputStream contentStream = response.getEntity().getContent();
FileOutputStream out = new FileOutputStream("src\\main\\resources\\static\\img\\" + filmName + ".jpg");
System.out.println("下载" + filmName);
int temp;
while ((temp = contentStream.read()) != -1) {
out.write(temp);
}
out.close();
}
下载的图片
注意:
1 请求时记得加上
connection.addRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36");
模拟浏览器访问
2 间隔3秒
Thread.sleep(3000);
这样防止被服务器当做恶意请求拒绝访问

