
ES2018正则表达式更新
如果你是一个初学者,这篇文章可以拓展你对正则表达式用法的理解,不过建议你先阅读一些正则表达式入门文章,比如经典的《正则表达式30分钟入门教程》。如果你对正则表达式有一定的认识,那么这篇文章可以让你了解JavaScript中的新功能。
随着ES2018的更新,JavaScript正则表达式和其他基于PCRE的正则表达式引擎之间的差距越来越小。
ES2018有以下四个比较重要的更新:
- Lookbehinds
- 捕获分组命名
- 元字符.匹配换行符
- Unicode转义
Lookbehinds断言
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp
/(?<=a)b/ // 匹配字符串b,字符串b前面是字符串a,字符串a不包含在匹配结果内

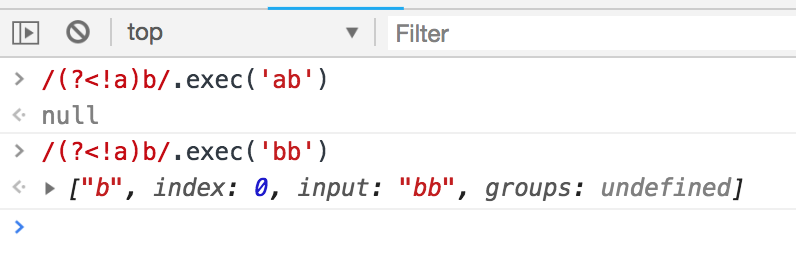
(?<!exp) 零宽度负回顾后发断言,断言此位置的前面不能匹配表达式exp
/(?<!a)b/ // 匹配字符串b,字符串b前面不是字符串a
你会发现在上面两个示例都没有捕获分组。如要需要捕获分组,可以在要捕获的表达式周围添加括号:
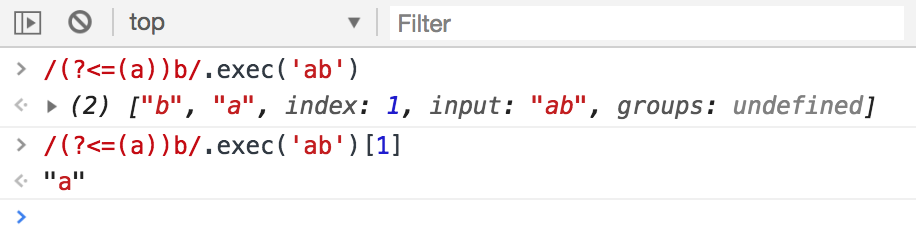
在此表达式中,生成的正则表达式匹配对象包含索引1下的捕获字符a。
groups属性仍是空的,这就是接下来要说的
捕获分组命名
/(?<name>content)/ // 语法:匹配content并捕获分组,分组命名为name
为了创建一个命名的捕获分组,我们所需要做的就是在括号开始后写一个问号,然后在左右尖括号之间写入捕获的分组名称。
示例:匹配出字符串“Price: $19.00”中的货币和价格并分别对分组命名
console.table( /^Price: (?<currency>\$)(?<numPrice>\d+\.\d+)$/ .exec('Price: $15.99') .groups )
货币分组名称:currency,价格分组名称numPrice

你仍然可以使用数字索引来引用捕获的分组,如果你访问groups属性,则可以读取自定义分组名称来获取对应的值
自动分组正则表达式反向引用语法:一个反斜杠加分组号,如\1,自定义分组反向引用语法则是:\k<groupName>,命名的捕获组使你的表达式更易于维护
const str = 'abc123'; str.replace(/([a-z]+)(\d+)/, '$2$1') // 123abc
const str = 'abc123'; str.replace(/(?<name1>[a-z]+)(?<name2>\d+)/, '$<name2>$<name1>') // 123abc
元字符.匹配换行符
这是一个非常简单的更新。正如您可能知道的那样,在JavaScript正则表达式以及许多PCRE正则表达式中,元字符.不匹配换行符\n
/./.test('\n')
// false
我们测试时可以看到返回false。
在ES2018中,我们可以添加一个s标志,以使点匹配换行符
/./s.test('\n')
// true
确切地说,还有其他行终止符,例如回车符\r,或行分隔符和段落分隔符,它们分别是U+2028和U+2029
Unicode转义
这是一个文档繁重的主题,因为文档本身详细介绍了此更新的每个细节。我将链接到文档作为参考。该文档详细介绍了如何将某些unicode字符组与某些表达式匹配,而不使用任何第三方库。
在本节中,我们将集中讨论此更新的一些实际用例,而不是对每个unicode组的详细描述。
我们从演示开始。假设你想匹配希腊字符。在我们决定不使用任何第三方库的情况下,我们在ES2018之前是如何做到的?
没错,我们不得不创建字符集。
/[θωερτψυιοπασδφγηςκλζχξωβνμάέήίϊΐόύϋΰώ]/u.test('λ')
// true
还要考虑大写
/[ΘΩΕΡΤΨΥΙΟΠΑΣΔΦΓΗςΚΛΖΧΞΩΒΝΜΆΈΉΊΪΐΌΎΫΰΏ]/u.test('Λ')
//true
在ES2018中,我们有一个更简单的符号:
/\p{Script=Greek}/u.test('π');
// true
\p{Script=Greek}只匹配希腊字符,这是一个很好的语义简写。希腊字符的数量有限,非常像英语。同时,如果没有Unicode转义,要匹配中文或日文,你必须在那里写一大堆符号。这个问题通过Unicode转义解决。
如果您需要克服JavaScript正则表达式的一些缺点,我仍然鼓励您使用xRegExp库。事实上,JavaScript正则表达式引擎并不会那么快取代xRegExp。与此同时,ES2018正则表达式引擎比之前变得更好,更易维护。

