
Linux内核内存管理:地址转换和MMU
地址转换和MMU
虚拟内存是一个概念,是给进程的一种错觉,因此它认为自己拥有巨大的、几乎无限的内存,有时甚至比系统实际拥有的内存还要多。每次访问内存位置时,由CPU将虚拟地址转换为物理地址。这种机制称为地址转换,由
内存管理单元(MMU)完成,是CPU的一部分。
MMU保护内存免受未经授权的访问。给定一个进程,需要访问的任何页面必须存在于进程VMAs中,因此必须存在于进程页表中(每个进程都有自己的页表)。
内存由固定大小的命名页(用于虚拟内存)和帧(用于物理内存)组织,在我们的示例中大小为4 KB。无论如何,您不需要猜测您为之编写驱动程序的系统的页面大小。它是通过内核中的PAGE_SIZE宏定义和访问的。因此,请记住,页面大小是由硬件(CPU)决定的。
考虑到一个4 KB的页面大小的系统,0到4095字节属于第0页,4096-8191字节属于第1页,以此类推。
引入页表的概念来管理页和框架之间的映射。页面分布在各个表上,这样每个PTE都对应于页面和框架之间的映射。然后给每个进程一组页表来描述它的整个内存空间。
为了遍历页面,每个页面都分配了一个索引(类似数组),称为页号。当谈到一个框架,它是PFN。这样,虚拟内存地址由两部分组成:页号和偏移量。偏移量表示地址的低12位有效位,而在8kb页面大小的系统中,低13位有效位表示地址:

操作系统或CPU如何知道哪个物理地址对应一个给定的虚拟地址?他们使用页表作为转换表,并且知道每个条目的索引是一个虚拟页码,值是PFN。要访问给定虚拟内存的物理内存,操作系统首先提取偏移量、虚拟页号,然后遍历进程的页表,以便匹配虚拟页号和物理页。
一旦匹配发生,就可以访问该页面帧中的数据:

偏移量用来指向帧中的正确位置。页表不仅包含物理页号和虚拟页号之间的映射,还包含访问控制信息(读写访问、特权等):

Virtual to physical address translation
用来表示偏移量的位数由内核宏PAGE_SHIFT定义。PAGE_SHIFT是左移一位以获得PAGE_SIZE值的位数。它也是右移将虚拟地址转换为页码和物理地址转换为PFN的位数。下面是这些宏的定义/include/asm-generic/page.h:
#define PAGE_SHIFT 12
#ifdef __ASSEMBLY__
#define PAGE_SIZE (1 << PAGE_SHIFT)
#else
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#endif
页表是部分解决方案。让我们看看这是为什么。大多数架构需要32位(4字节)来表示一个PTE,每个进程都有其私有的3gb用户空间地址,所以我们需要786432个条目来描述和覆盖一个进程地址空间。它表示每个进程花费了太多的物理内存,只是为了描述内存映射。事实上,一个进程通常使用它的虚拟地址空间的一小部分但分散的部分。为了解决这个问题,我们引入了关卡的概念。页表按级别(页级)分层。存储多级存储器所必需的空间。
为了解决这个问题,我们引入了分级的概念。页表按级别(页级)分层。存储多级页表所需的空间只取决于实际使用的虚拟地址空间,而不是与虚拟地址空间的最大大小成比例。这样,就不再表示未使用的内存,并且页表遍历时间也减少了。这样,第N层的每个表项都指向第N+1层的表项。第1级是较高的级别。
Linux使用一个四级分页模型:
- Page Global Directory (PGD):它是第一级(第一级)页表。在内核中,每个条目的类型都是pgd_t(通常是unsigned long),并指向表中的第二级条目。在内核中,tastk_struct结构表示一个进程的描述,该描述又有一个类型为mm_struct的成员(mm),它描述并表示进程的内存空间。在mm_struct中,有一个特定于处理器的字段pgd,它是一个指针,指向进程的level-1 (pgd)页表的第一个条目(条目0)。每个进程有且只有一个PGD,它可能包含多达1024个条目。
- Page Upper Directory (PUD):这只存在于使用四级表的体系结构上。它代表了间接的第二层。
- 页面中间目录(PMD):这是第三个间接级别,仅存在于使用四级表的体系结构上。
- 页表(PTE):树的叶子。它是一个pte_t数组,其中每个入口都指向物理页面。
并不是所有的级别都被使用。i.MX6的MMU只支持两层页表(PGD和PTE),这是几乎所有32位的情况。在这种情况下,PUD和PMD被简单地忽略。

Two-level tables overview
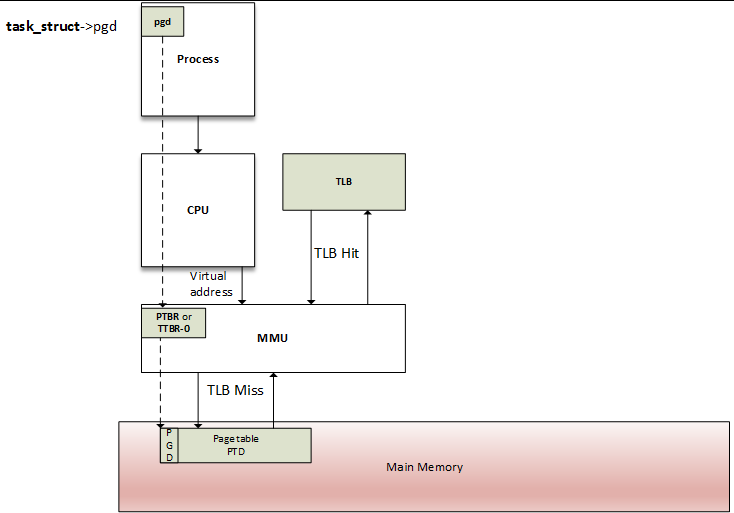
您可能会问MMU是如何知道进程页表的。它很简单,MMU不存储任何地址。相反,在CPU中有一个特殊的寄存器,称为页表基址寄存器(PTBR)或转换表基址寄存器0 (TTBR0),它指向进程的level-1(顶级)页表(PGD)的条目0。它正是mm_struct的pdg字段指向:current->mm.pgd = = TTBR0。
在上下文切换(当一个新的进程被调度并且给定了CPU)时,内核立即配置MMU并使用新进程的pgd更新PTBR。现在,当一个虚拟地址给MMU,它使用PTBR的内容来定位进程的第1级页表(PGD),然后它使用第1级索引,从虚拟地址的最有效位(MSBs)中提取,查找适当的表项,该表项包含指向适当的第2级页表基址的指针。然后,从该基地址开始,它使用level-2索引查找适当的条目,以此类推,直到它到达PTE。ARM架构(在我们的例子中是i.MX6)有一个两层的页表。在本例中,第2级条目是PTE,并指向物理页面(PFN)。这一步只找到物理页面。为了访问页面中确切的内存位置,MMU提取内存偏移量,也就是虚拟地址的一部分,并指向物理页面中相同的偏移量。
当一个进程需要读取或写入内存位置(当然,我们讨论的是虚拟内存)时,MMU将执行转换到该进程的页表中,以找到正确的条目(PTE)。虚拟页码是从虚拟地址中提取出来的,处理器将其用作进程页表的索引,以检索其页表条目。如果在该偏移量处有一个有效的页表条目,处理器将获取PFN从这个条目。如果没有,则意味着进程访问了其虚拟内存的未映射区域。然后引发一个页面错误,操作系统应该处理它。
在现实世界中,地址转换需要页表遍历,而且并不总是一次性操作。内存访问实例的数量至少与表级别相同。一个四级页表需要4次内存访问。换句话说,每个虚拟访问实例将导致5次物理内存访问。如果虚拟内存的访问比物理访问慢四倍,那么虚拟内存的概念就毫无用处了。
幸运的是,SoC制造商努力寻找一个聪明的技巧来解决这个性能问题: 现代cpu使用一个称为转义查找缓存(TLB)的小型且非常快的关联内存,来缓存最近访问的虚拟页面的pte。
页面查找和TLB
在MMU继续处理转换之前,还涉及到另一个步骤。正如有一个缓存用于最近访问的数据,也有一个缓存用于最近翻译的地址。由于数据缓存可以加快数据访问过程,TLB可以加快虚拟地址转换的速度。是的,地址转换是一项棘手的任务。它是内容寻址内存(CAM),其中键是虚拟地址,值是物理地址。换句话说,TLB是MMU的缓存。在每次内存访问时,MMU首先检查TLB中最近使用的页面,TLB包含一些当前分配给物理页面的虚拟地址范围。
TLB是如何工作的?
在虚拟内存访问中,CPU遍历TLB,试图找到正在被访问的页面的虚拟页号。这个步骤称为TLB查找。当找到一个TLB表项时(匹配发生),就说有一个TLB命中,CPU继续运行,并使用在TLB表项中找到的PFN来计算目标物理地址。TLB命中时不会出现页面错误。正如您所看到的,只要在TLB中可以找到一个转换,虚拟内存访问将和物理访问一样快。如果没有找到TLB表项(没有匹配),你说有一个TLB缺失。
在TLB miss事件中,有两种可能,这取决于处理器类型;TLB miss事件可以由软件来处理,也可以由硬件通过MMU来处理:
- 软件处理: CPU引起TLB miss中断,被操作系统捕获。然后,操作系统遍历进程的页表,找到正确的PTE,如果有匹配的有效的条目,CPU就会把新的翻译安装到TLB。否则,将执行页面错误处理程序。
- 硬件处理: 由CPU(实际上是MMU)在硬件中遍历进程的页表。如果有匹配且有效的条目,CPU会在TLB中添加新的翻译。否则,CPU将引发页面错误中断,由操作系统处理。
在这两种情况下,页面错误处理程序是相同的:执行do_page_fault()函数,这是依赖于体系结构的。对于ARM, do_page_fault在arch/arm/mm/fault.c中定义:
MMU and TLB walkthrough process
页表和页目录条目依赖于体系结构。表的结构是否与MMU识别的结构相对应,由操作系统决定。在ARM处理器上,在ARM处理器上,你必须在CP15(协处理器15)寄存器c2中写入转换表的位置,然后通过写入CP15的c1寄存器来启用缓存和MMU。从http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0056d/BABHJIBH.htm 和 http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0433c/CIHFDBEJ.html获取更详细的信息。
本文来自博客园,作者:闹闹爸爸,转载请注明原文链接:https://www.cnblogs.com/wanglouxiaozi/p/15031691.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)