Android轻量级数据SparseArray详解
SparseArray是Android中特有的数据结构,他的几个重要的特点;
- 以键值对形式进行存储,基于二分查找,因此查找的时间复杂度为0(LogN);
- .由于SparseArray中Key存储的是数组形式,因此可以直接以int作为Key。避免了HashMap的装箱拆箱操作,性能更高且int的存储开销远远小于Integer;
- 采用了延迟删除的机制(针对数组的删除扩容开销大的问题的优化, 具体稍后分析) ;
重要属性
public class SparseArray<E> implements Cloneable { private static final Object DELETED = new Object(); private boolean mGarbage = false; private int[] mKeys; private Object[] mValues; private int mSize;
- DELETED ,static final 的一个静态Object实例,当一个键值对被remove后,会在对应key的value下放置该对象,标记该元素已经被删除(延迟删除,等下具体介绍);
- mGarbage , 当值为true,标志数据结构中有元素被删除,可以触发gc对无效数据进行回收(真正删除);
- mKeys数组, 用于存放Key的数组,通过int[] 进行存储,与HashMap相比减少了装箱拆箱的操作,同时一个int只占4字节;一个重要特点,mKeys的元素是升序排列的,也是基于此,我们才能使用二分查找;
- mValues数组,用于存放与Key对应的Value,通过数组的position 进行映射;如果存放的是int型等,可以用SparseIntArray ,存放的Values也是int数组,性能更高;
- mSize,mSize的大小等于数组中mValues的值等于非DELETED的元素个数;
Remove方法(Delete)
public void delete(int key) { //查找对应key在数组中的下标,如果存在,返回下标,不存在,返回下标的取反; int i = ContainerHelpers.binarySearch(mKeys, mSize, key); //key存在于mKeys数组中,将元素删除,用DELETED替换原value,起标记作用; if (i >= 0) { if (mValues[i] != DELETED) { mValues[i] = DELETED; mGarbage = true; } } } /** * @hide * Removes the mapping from the specified key, if there was any, returning the old value. */ public E removeReturnOld(int key) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); if (i >= 0) { if (mValues[i] != DELETED) { final E old = (E) mValues[i]; mValues[i] = DELETED; mGarbage = true; return old; } } return null; } /** * Alias for {@link #delete(int)}. */ public void remove(int key) { delete(key); }
首先我们主要是通过ContainerHelpers.binarySearch来进行查找对应的key,返回的i就是对应数组的下标;下面我们去看看该方法的实现原理;
其实ContainerHelpers方法只有这一个方法(准确说还有一个,输入的第一个参数array的参数为long[],而不是int[])
主要做的就是二分查找,并返回下标。下面我们仔细分析其中的设计;请对着下述源码中的注释;
static int binarySearch(int[] array, int size, int value) { int lo = 0; int hi = size - 1; while(lo <= hi) { int mid = lo + hi >>> 1; int midVal = array[mid]; if (midVal < value) { lo = mid + 1; } else { if (midVal <= value) { return mid; } hi = mid - 1; } } return ~lo; }
这部分代码比较简单,重点就在于最后的return,可能往往二分查找没有找到都是返回-1。但是这里返回了~lo,取反导致下标小于0,用于判断没有找到;这个主要用在Put方法中,稍后再讲。我们现在只要知道,该方法是通过二分查找返回了当前key的对应于mKeys数组的下标,如果没有找到,就返回一个特殊的负数;
之后下一步,我们得到了下标i,如果非负数,我们则对其所对应的value进行替换成DELETED,用于标记该key已经被删除,同时,我们将garbage赋值true,代表数组中可能存在垃圾;
总结:remove方法主要做的就是这些,找到需要删除的key,并将对应的value用DELETED替换;但是key仍然存在于mKeys数组,因此删除是一个伪删除。这就是所谓的延迟删除机制;
接下来,我们就去put方法中切身体会一下延迟删除的作用和好处;
Put
public void put(int key, E value) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); //原来已经有key,可能是remove后,value存放着DELETED,也可能是存放旧值,那么就替换 if (i >= 0) { mValues[i] = value; } else { //没有找到,对i取反,得到i= lo(ContainerHelpers.binarySearch) i = ~i; //如果i小于数组长度,且mValues==DELETED(i对应的Key被延迟删除了) if (i < mSize && mValues[i] == DELETED) { //直接取代,实现真实删除原键值对 mKeys[i] = key; mValues[i] = value; return; } //数组中可能存在延迟删除元素且当前数组长度满,无法添加 if (mGarbage && mSize >= mKeys.length) { //真实删除,将所有延迟删除的元素从数组中清除; gc(); //清除后重新确定当前key在数组中的目标位置; // Search again because indices may have changed. i = ~ContainerHelpers.binarySearch(mKeys, mSize, key); } //不存在垃圾或者当前数组仍然可以继续添加元素,不需要扩容,则将i之后的元素全部后移,数组中仍然存在被DELETED的垃圾key; mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key); mValues = GrowingArrayUtils.insert(mValues, mSize, i, value); //新元素添加成功,潜在可用元素数量+1 mSize++; } }
可以看到,put方法也调用了ContainerHelpers.binarySearch方法先进行查找,查找到大于0,则在数组中找到了对应的key,此时,直接将value进行替换即可;
但是,如果没有找到,返回的是~lo,那么,将i赋值~~lo,即i=lo,,此时i就是我们需要插入的位置;这个可能对二分查找不熟悉的话难以理解,下面我们用个例子展示一下,如果我们查找Key=2;
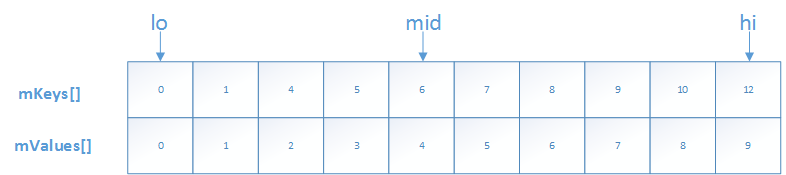

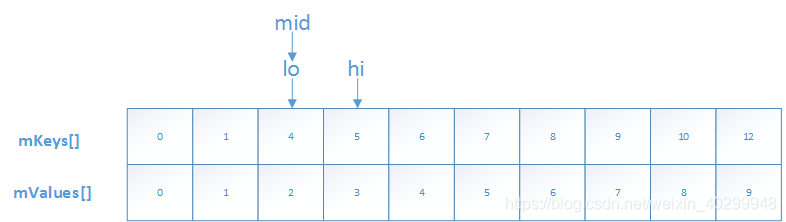
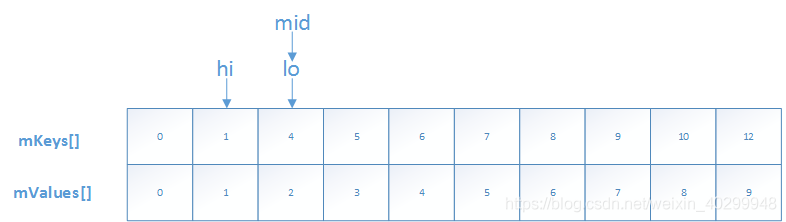
此时,lo大于hi,退出循环,lo对应的下标为2,且是插入Key=2的理想位置;因此,这个lo取反,有两个重要的作用:
- 代表没有找到对应的key
- 对返回值重新取反后,得到的就是lo,就是应该插入的元素。此时将key下标为lo及之后的元素后移,再将当前元素插入该位置。就完成了一次有序插入;
此刻,我们找到了i,就是目标位置,如果没有设置延迟删除(DELETED)。那么由于数组的特点,我们需要将i序号之后的数组后移,这样就会产生一个较大的性能损耗;但是如果我们设置了延迟删除且mValue[i]上当前的元素恰巧为DELETED,那么此时我们可以用当前的key替换原来mKeys的key,且用当前value替换DELETED;这样就成功避免了一次数组的迁移操作;
但是事情不可能永远凑巧,如果,i上的元素并非恰好被删除呢;
那么此时我们会判断mGarbage,如果为true那么我们执行一次gc,将无效数据移除,再进行一次二分查找,然后将i之后的数据全部后移,将当前key插入;
如果mGarbage为false,那么证明其中的数据全部存在,因此不需要gc,直接进行元素插入并将数组后移;
其中GrowingArrayUtils.insert主要做的就是调用System.arraycopy将数组后移,如果需要扩容则扩容;
数组后移
public static int[] insert(int[] array, int currentSize, int index, int element) { assert currentSize <= array.length; if (currentSize + 1 <= array.length) { System.arraycopy(array, index, array, index + 1, currentSize - index); array[index] = element; return array; } int[] newArray = ArrayUtils.newUnpaddedIntArray(growSize(currentSize)); System.arraycopy(array, 0, newArray, 0, index); newArray[index] = element; System.arraycopy(array, index, newArray, index + 1, array.length - index); return newArray; }
GC
private void gc() { // Log.e("SparseArray", "gc start with " + mSize); //n代表gc前数组的长度; int n = mSize; int o = 0; int[] keys = mKeys; Object[] values = mValues; for (int i = 0; i < n; i++) { Object val = values[i]; //遍历元素,如果value不为DELETED,则用前数据放在o上,o的序号表示当前的有效元素下标。 //每遇到一次DELETED,则i-o的大小+1; if (val != DELETED) { //之后遇到非DELETED数据,则将后续元素的key和value往前挪 if (i != o) { keys[o] = keys[i]; values[o] = val; values[i] = null; } o++; } } //此时无垃圾数据,o的序号表示mSize的大小 mGarbage = false; mSize = o; // Log.e("SparseArray", "gc end with " + mSize); }
这里要注意一个非常非常重要的点:
我们可以看到在循环遍历中,我们做的是将数组前移。因此会存在一个问题,即gc后有效数组长度为o,但是此时,keys.length可能会大于o,那么此时,最后的keys.length-o 个数组元素中仍然存在着key和value且不会消失;但是,由于mSize等于o,此时并不会访问到最后的多个废弃元素。只有在mSize数组范围内的DELETED数据才被称为延迟删除元素,mSize范围外的不会作为 被gc删除,只会被之后的put数组后移覆盖;
Get
public E get(int key) { return get(key, null); } /** * Gets the Object mapped from the specified key, or the specified Object * if no such mapping has been made. */ @SuppressWarnings("unchecked") public E get(int key, E valueIfKeyNotFound) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); if (i < 0 || mValues[i] == DELETED) { return valueIfKeyNotFound; } else { return (E) mValues[i]; } }
总结
- SparseArray采用了延迟删除的机制,通过将删除KEY的Value设置DELETED,方便之后对该下标的存储进行复用;
- 使用二分查找,时间复杂度为O(LogN),如果没有查找到,那么取反返回左边界,再取反后,左边界即为应该插入的数组下标;
- 如果无法直接插入,则根据mGarbage标识(是否有潜在延迟删除的无效数据),进行数据清除,再通过System.arraycopy进行数组后移,将目标元素插入二分查找左边界对应的下标;
- mSize 小于等于keys.length,小于的部分为空数据或者是gc后前移的数据的原数据(也是无效数据),因此二分查找的右边界以mSize为准;mSize包含了延迟删除后的元素个数;
- 如果遇到频繁删除,不会触发gc机制,导致mSize 远大于有效数组长度,造成性能损耗;
- 根据源码,可能触发gc操作的方法有(1、put;2、与index有关的所有操作,setValueAt()等;3、size()方法;)
- mGarbage为true不一定有无效元素,因为可能被删除的元素恰好被新添加的元素覆盖;
根据SparseArray的这些特点。我们能分析出其使用场景:
- key为整型;
- 不需要频繁的删除;
- 元素个数相对较少;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号