jdk源码hashMap的1.7与1.8的比较
1.8链表的定义基本上与1.7相同,但是类名改为Node,但是node实现了Map.Entry接口,实质是一样的
static class Node<K,V> implements Map.Entry<K,V> {
1.8的hash值的算法更加直观一点,就是key的hashcode与无符号右移16位的hashcode异或,然后返回。这是为了当length比较小的时候,也能保证考虑到高低Bit位都参与到Hash的计算中,同时不会有太大的开销。
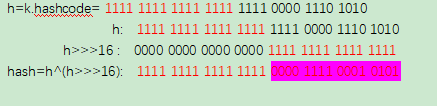
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
tableSizeFor主要功能是返回一个比给定整数大且最接近的2的幂次方整数,返回的是n+1,实例如下,右移一位,把最高位的1后面一位也变成了1,通过右移,把最高位后面全部置换成1,最后n+1,即为最接近传入数的2的幂次方整数


static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
hashmap1.8的数据结构如下,当链表的长度不小超过8的话就按链表存储,若是超过了8,那么通过treeifyBin 转化为红黑树

final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);//把每个及节点转化为TreeNode
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号