使用 Python 识别并提取图像中的文字
1. 介绍
介绍使用 python 进行图像的文字识别,将图像中的文字提取出来,可以帮助我们完成很多有趣的事情。
2. 必备工具
- tesseract-ocr
下载地址: https://github.com/UB-Mannheim/tesseract/wiki
tesseract-ocr 是一个开源的图片OCR识别库, 功能及其强大,支持多国语言。
更高级的用法,它还支持机器学习算法,通过训练的方式,使OCR识别更加智能化及准确。
- python 库
使用安装 pytesseract 和 pillow 库:
pip install pytesseract
pip install pillow
3. 开发使用
使用 python 配合 tesseract 识别文字中的图像可以非常简单,几行代码就可以搞定。
例如,识别下面这张图片:
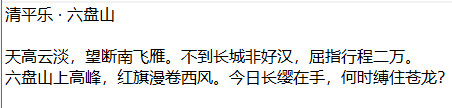
首先导入 pytesseract 和 pillow 库
import pytesseract
from PIL import Image
然后指定 tesseract 目录:
pytesseract.pytesseract.tesseract_cmd = 'f:/tessert/tesseract.exe'
然后使用 pillow 库加载图片:
img = Image.open('test.png')
最后使用 tesseract 识别图像的文字:
text = pytesseract.image_to_string(img, lang='chi_sim')
print(text)
最后的结果是:

可以看到,有偏差,但是基本上都识别出来了。
4. 总结
这里只是入门级的介绍,当然还有问题,比如彩色图像识别一般效果不好,对比度低的图像识别也不一定好,这就需要我们对图片进行处理后再来识别。比如提取灰度图片,锐化图片等操作,具体涉及到的是数字图像处理的领域了,这个后面有机会再讨论。
travel between codes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号