
tensorflow:实战Google深度学习框架第三章
tensorflow的计算模型:计算图–tf.Graph
tensorflow的数据模型:张量–tf.Tensor
tensorflow的运行模型:会话–tf.Session
tensorflow可视化工具:TensorBoard
通过集合管理资源:tf.add_to_collection、tf.get_collection
Tensor主要三个属性:名字(name)、维度(shape)、类型(type)
#张量,可以简单的理解为多维数组
import tensorflow as tf
a = tf.constant([1.0,2.0],name='a')
b = tf.constant([3.0,4.0],name='b')
result = tf.add(a,b,name="add")
print(result)
输出:Tensor("add:0", shape=(2,), dtype=float32)
会话Session需要关闭才能释放资源,通过Python的上下文管理器 with ,可以自动释放资源
#创建会话,并通过上下文管理器来管理
with tf.Session() as sess:
sess.run(result)
#不需要Session.close()关闭会话
#上下文管理器退出,会话自动关闭
tensorflow设备:tf.device(‘/cpu:0’)、tf.device(‘/gpu:2’)
一、前向传播算法:
需要三个部分:神经网络的输入,神经网络的连接结构,每个神经元的参数
将前向传播算法使用矩阵乘法方式表示:
#将前向传播算法使用矩阵乘法方式表示: a = tf.matmul(x,w1)#x是输入,w1是第一层的参数 y = tf.matmul(a,w2)#a是第一层的输出。w2是第二层的神经元的参数
在tensorflow中变量(tf.Variable)的作用:保存和更新神经网络的参数,变量需要指定初始值:
1、使用随机数初始化
#定义2*3的矩阵变量 weights = tf.Variable(tf.random_normal([2,3], stddev=2))
其他随机数生成函数在表3-2
| 函数名称 | 随机数分布 | 主要参数 |
|---|---|---|
| tf.random_normal | 正太分布 | 平均值、标准差、取值类型 |
| tf.truncated_normal | 正太分布,如果随机出来的值偏离均值超过2个标准差,重新随机 | 平均值、标准差、取值类型 |
| tf.random_uniform | 平均分布 | 最小、最大取值、取值类型 |
| tf.random_gamma | Gamma分布 | 形状参数alpha、尺度参数beta、取值类型 |
2、使用常数初始化
import tensorflow as tf #定义长度3的矩阵变量 weights = tf.Variable(tf.zeros([3]))#初始值为0,长度为3的变量
| 函数名称 | 功能 | 样例 |
|---|---|---|
| tf.zeros | 产生全0数组 | tf.zeros([2,3],int32)–>[[0,0,0],[0,0,0]] |
| tf.ones | 产生全1数组 | tf.ones(2,3],int32)–>[[1,1,1],[1,1,1]] |
| tf.fill | 产生一个给定值的数组 | tf.fill([2,3],9)–>[[9,9,9],[9,9,9]] |
| tf.constant | 产生一个给定值常量 | tf.constant([1,2,3])–>[1,2,3] |
3、使用其他变量进行初始化
import tensorflow as tf w2 = tf.Variable(weights.initialized_value())#将w2初始化为与变量weights相同 w3 = tf.Variable(weights.initialized_value()*2)#将w2初始化为变量weights值的2倍
一个变量在使用前,必须先初始化
*(推荐)使用tf.initialize_all_variables()初始化所有变量
with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)
前向传播算法实现
import tensorflow as tf #声明w1和w2两个变量,使用seed参数设定随机种子,保证每次产生的随机数相同 w1 = tf.Variable(tf.random_normal([2,3], stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1], stddev=1,seed=1)) #暂时将输入定义为常量,x为1*2的矩阵 x = tf.constant([[0.7,0.9]]) #通过前向传播算法获得输出 a = tf.matmul(x,w1) y = tf.matmul(a,w2) with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)#初始化所有变量 print(sess.run(y))
所有的变量都被自动的加入tf.GraphKeys.VARIABLES,通过tf.all_variables()函数获取当前计算图的所有变量,
在神经网络中可以使用变量声明函数中的trainable参数区分需要优化的参数(神经网络参数或迭代轮数),如当trainable=True ,这个变量将加入集合tf.GraphKeys.TRAINABLE_VARIABLES中,可以使用tf.trainable_variables()函数得到所有可学习的变量
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.GraphKeys.VARIABLES | 所有变量 | 持久化TensorFlow模型 |
| tf.GraphKeys.TRAINABLE_VARIABLES | 可学习的变量 | 模型训练、生成模型可视化内容 |
| tf.GraphKeys.SUMMARIES | 日志生成相关张量 | TensorFlow计算可视化 |
| tf.GraphKeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.GRaphKeys.MOVING_AVEGAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
二、反向传播算法
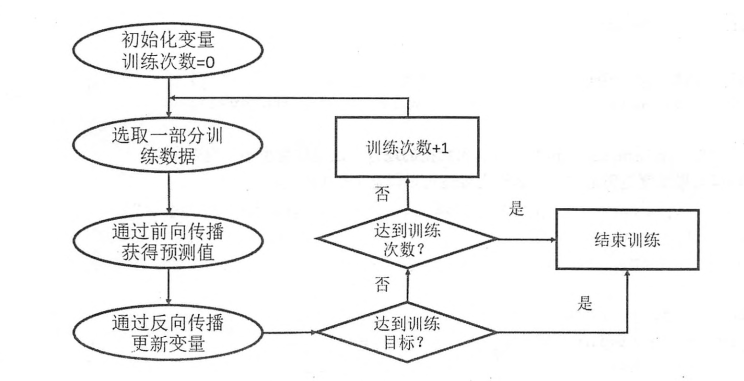
1、上面我们使用x = tf.contant([[0.7,0.9]])表达训练数据,若都使用常量,计算图将非常大(一个常量,计算图增加一个节点),利用率低,故tensorflow提供placeholder机制提供输入数据
placeholder机制:
定义一个位置,这个位置中的数据在程序运行时再指定
定义时,数据类型需要指定(指定后不可改变)
例如使用placeholder实现前向传播算法:
import tensorflow as tf w1 = tf.Variable(tf.random_normal([2,3], stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1], stddev=1,seed=1)) #定义placeholder存放输入数据,指定维度降低出错几率(可以不指定) x = tf.placeholder(tf.float32, shape=(1, 2), name="x") #通过前向传播算法获得输出 a = tf.matmul(x,w1) y = tf.matmul(a,w2) with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)#初始化所有变量 #feed_dict是一个字典,,在字典给出placeholder的取值 print(sess.run(y,feed_dict={x:[[0.7,0.9]]}))
2、得到前向传播的结果后,需要定义一个损失函数表示预测值与真实值的差距,然后通过反向传播算法缩小差距
#使用交叉熵损失函数表示预测值和真实值的差距 cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))) #定义学习率 learning_rate = 0.001 #定义反向传播算法优化神经网络的参数 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) with tf.Session() as sess: sess.run(train_step)#优化GraphKeys.TRAINABLE_VARIABLES集合中的变量
TensorFlow支持7种优化算法,常用的三种优化算法:tf.train.AdamOptimizer,tf.train.GradientDescentOptimizer,tf.train.MomentumOptimizer
完整的样例程序:
训练神经网络步骤:
1. 定义神经网络结构和前向传播输出结果
2. 定义损失函数及反向传播优化算法
3. 生成会话(tf.Session)并在训练数据上反复运行反向传播优化算法
import tensorflow as tf from numpy.random import RandomState # 定义神经网络的参数,输入和输出节点 batch_size = 8 w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input") y_= tf.placeholder(tf.float32, shape=(None, 1), name='y-input') #定义前向传播过程,损失函数及反向传播算法 a = tf.matmul(x, w1) y = tf.matmul(a, w2) cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))) train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) #生成模拟数据集 rdm = RandomState(1) X = rdm.rand(128,2) Y = [[int(x1+x2 < 1)] for (x1, x2) in X] #创建一个会话来运行TensorFlow程序 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) # 输出目前(未经训练)的参数取值。 print("w1:", sess.run(w1)) print("w2:", sess.run(w2)) print("\n") # 训练模型。 STEPS = 5000 for i in range(STEPS): start = (i*batch_size) % 128 end = (i*batch_size) % 128 + batch_size sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0: total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y}) print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy)) # 输出训练后的参数取值。 print("\n") print("w1:", sess.run(w1)) print("w2:", sess.run(w2))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号