
获取网页
前端打印
function preview(oper) { if (oper < 10) { bdhtml = window.document.body.innerHTML; //获取当前页的html代码 sprnstr = "<!--startprint" + oper + "-->"; //设置打印开始区域 eprnstr = "<!--endprint" + oper + "-->"; //设置打印结束区域 prnhtml = bdhtml.substring(bdhtml.indexOf(sprnstr) + 18); //从开始代码向后取html prnhtml = prnhtml.substring(0, prnhtml.indexOf(eprnstr)); //从结束代码向前取html window.document.body.innerHTML = prnhtml; window.print(); window.document.body.innerHTML = bdhtml; } else { window.print(); } }
.net后端
1.直接获取流:(适用于单个页面)
public static string GetRequestData(string url) { // 构建一个请求 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); // 请求的方式 request.Method = "GET"; // 请求的响应 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); // 响应的流 Stream responseStream = response.GetResponseStream(); // 字符编码 Encoding enc = Encoding.GetEncoding("utf-8"); // 读取流 StreamReader readResponseStream = new StreamReader(responseStream, enc); // 请求的结果 string result = readResponseStream.ReadToEnd(); // 关闭流,响应,释放资源 readResponseStream.Close(); response.Close(); return result; }
2.使用System.Net.WebClient下载web Page存到本地或者string中,适用于很多页面
using System; using System.Net; using System.Text; using System.Text.RegularExpressions; namespace HttpGet { class Class1 { [STAThread] static void Main(string[] args) { System.Net.WebClient client = new WebClient(); byte[] page = client.DownloadData("http://www.google.com"); string content = System.Text.Encoding.UTF8.GetString(page); string regex = "href=[\\\"\\\'](http:\\/\\/|\\.\\/|\\/)?\\w+(\\.\\w+)*(\\/\\w+(\\.\\w+)?)*(\\/|\\?\\w*=\\w*(&\\w*=\\w*)*)?[\\\"\\\']"; Regex re = new Regex(regex); MatchCollection matches = re.Matches(content); System.Collections.IEnumerator enu = matches.GetEnumerator(); while (enu.MoveNext() && enu.Current != null) { Match match = (Match)(enu.Current); Console.Write(match.Value + "\r\n"); } } } }
第三种使用Winista.Htmlparser.Net解析。
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using Winista.Text.HtmlParser; using Winista.Text.HtmlParser.Lex; using Winista.Text.HtmlParser.Util; using Winista.Text.HtmlParser.Tags; using Winista.Text.HtmlParser.Filters; namespace HTMLParser { public partial class Form1 : Form { public Form1() { InitializeComponent(); AddUrl(); } private void btnParser_Click(object sender, EventArgs e) { #region 获得网页的html try { txtHtmlWhole.Text = ""; string url = CBUrl.SelectedItem.ToString().Trim(); System.Net.WebClient aWebClient = new System.Net.WebClient(); aWebClient.Encoding = System.Text.Encoding.Default; string html = aWebClient.DownloadString(url); txtHtmlWhole.Text = html; } catch (Exception ex) { MessageBox.Show(ex.Message); } #endregion #region 分析网页html节点 Lexer lexer = new Lexer(this.txtHtmlWhole.Text); Parser parser = new Parser(lexer); NodeList htmlNodes = parser.Parse(null); this.treeView1.Nodes.Clear(); this.treeView1.Nodes.Add("root"); TreeNode treeRoot = this.treeView1.Nodes[0]; for (int i = 0; i < htmlNodes.Count; i++) { this.RecursionHtmlNode(treeRoot, htmlNodes[i], false); } #endregion } private void RecursionHtmlNode(TreeNode treeNode, INode htmlNode, bool siblingRequired) { if (htmlNode == null || treeNode == null) return; TreeNode current = treeNode; TreeNode content ; //current node if (htmlNode is ITag) { ITag tag = (htmlNode as ITag); if (!tag.IsEndTag()) { string nodeString = tag.TagName; if (tag.Attributes != null && tag.Attributes.Count > 0) { if (tag.Attributes["ID"] != null) { nodeString = nodeString + " { id=\"" + tag.Attributes["ID"].ToString() + "\" }"; } if (tag.Attributes["HREF"] != null) { nodeString = nodeString + " { href=\"" + tag.Attributes["HREF"].ToString() + "\" }"; } } current = new TreeNode(nodeString); treeNode.Nodes.Add(current); } } //获取节点间的内容 if (htmlNode.Children != null && htmlNode.Children.Count > 0) { this.RecursionHtmlNode(current, htmlNode.FirstChild, true); content = new TreeNode(htmlNode.FirstChild.GetText()); treeNode.Nodes.Add(content); } //the sibling nodes if (siblingRequired) { INode sibling = htmlNode.NextSibling; while (sibling != null) { this.RecursionHtmlNode(treeNode, sibling, false); sibling = sibling.NextSibling; } } } private void AddUrl() { CBUrl.Items.Add("http://www.hao123.com"); CBUrl.Items.Add("http://www.sina.com"); CBUrl.Items.Add("http://www.heuet.edu.cn"); } } }
效果: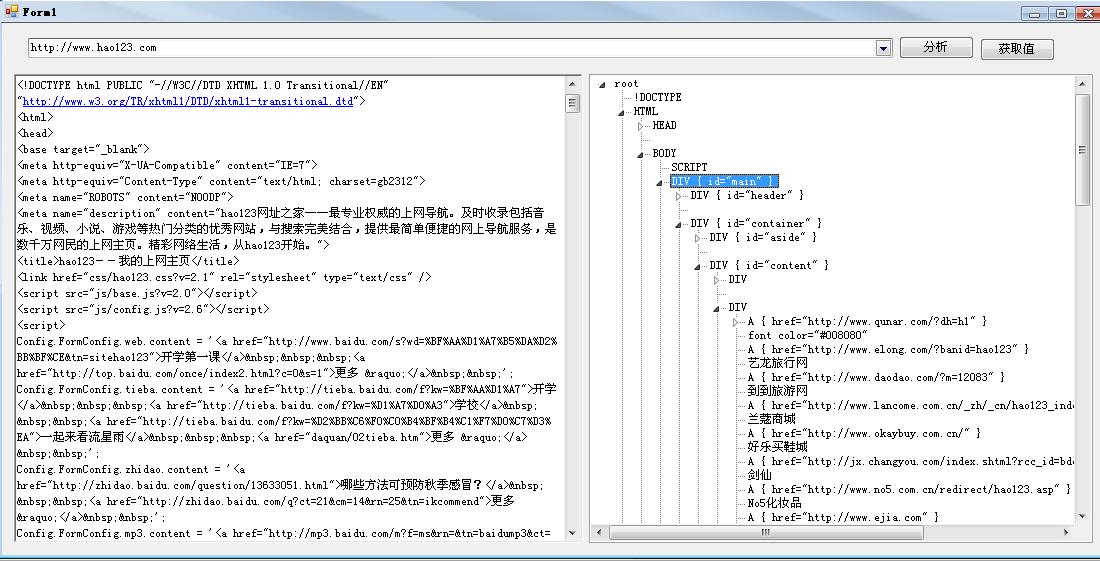


 浙公网安备 33010602011771号
浙公网安备 33010602011771号