
LeetCode——5.Longest Palindromic Substring
一.题目链接:https://leetcode.com/problems/longest-palindromic-substring/
二.题目大意:
给定一个字符串,找出它最长的回文子串。例如,字符串“caabb”,它的最长回文子串为“aabb”。
三.题解:
找最长回文子串应该说是比较经典的题目,这个题目我目前有三种思路:
方法1:暴力解决,找出所有的子串,并判断子串是不是回文,然后记录最长的回文子串。代码如下:
class Solution {
public:
string longestPalindrome(string s) {
int len = s.size();
string rs;//用于保存最长的回文子串
int max_len = 0;
for(int i = 0;i < len;i++)
for(int j = i + 1;j <= len;j++)
{
string temp = s.substr(i,j - i);
if(isPalin(temp) == true)
{
if(max_len < temp.size())
{
max_len = temp.size();
rs = temp;
}
}
}
return rs;
}
bool isPalin(string s)
{
int len = s.length();
int flag = 1;
for(int i = 0;i < len;i++)
{
if(s[i] != s[len - 1 - i])
flag = 0;
}
if(flag)
return true;
return false;
}
};
其中遍历所有的子串需要的时间复杂度为O(n2),判断子串是不是回文串的时间复杂度为O(n),所以总的时间复杂度为O(n3)。
提交结果:Time Limit Exceeded(超时).
方法2:
以字符串中的每个字符为中心向两边扩展,从而找到最长的回文子串。其中回文子串存在两种情况:(1)形如"aabaa"这种中间只有一个字符的回文子串。(2)形如"aabbaa"这种中间有两个或多个字符的回文子串。所以在处理的时候,先优考虑第二种情况,可以吧第二中情况中的中间重复字符看成一个字符,然后剩下的部分同第一种情况就可以进行相同的处理了。代码如下:
class Solution {
public:
string longestPalindrome(string s) {
int len = s.size();
int max_len = 0;
string rs = "";
for(int i = 0;i < len;i++)
{
int f = i,b = i;
int df = 0;
int oddf = 0;
while(s[b] == s[i])//中间字符存在重复的情况
{
b++;
oddf = 1;
}
if(oddf == 1)
b--;
while(f >= 0 && b < len && s[f] == s[b])//中间字符的左右两边字符相等,两边都增长
{
f--;
b++;
df = 1;
}
if(df == 1)
{
f++;
b--;
}
string temp = s.substr(f,b-f+1);
if(max_len < temp.size())
{
max_len = temp.size();
rs = temp;
}
}
return rs;
}
};
这个程序中的我设置了两个哨兵,用来判断是否发生了以下情况:
(1)中间字符连续几个都相同或重复,此时下标b增加。
(2)中间字符的左右两边字符相等,所以两边都增长,此时b增加,f减小。
由于每次增长后,下标f(或b)都会再次-1(+1),相当于多减少(增加)了一次,所以需要增加(减少)一次,来恢复成为正常的下标。
这种方法的时间复杂度为O(n2),空间复杂度为O(n)。
提交结果:Accepted(16ms).
方法3:
利用动态规划的思想,将父问题拆分为若干个子问题,用dp[i][j]来表示字符串下标为[i,j]的子串是否为回文串,那么有以下的分析:
(1)如果i == j表示子串是一个字符,那么此时必然是一个回文串。
(2)如果相邻的字符相等(这种情况实质就是方法2中的中间字符重复的情况),j == i+1,此时要判断s[i]与s[j]是否相等,如果相等,那么该子串也是回文串,
(3)判断剩下的情况,如果(s[i],s[i+1],.....,s[j])为回文串的话,那么(s[i+1],s[i+2],.....s[j-1])必然也是一个回文串,且s[i] == s[j]。
所以,初始状态为:
dp[i][i] =1。
整个状态方程为:
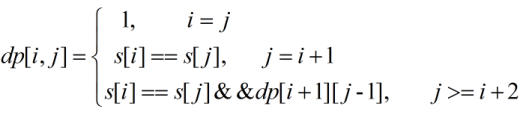
代码如下:
class Solution
{
public:
string longestPalindrome(string s)
{
int len = s.size();
string rs = "1";
int start = 0;
int max_len = 1;//此处的初始值为1,默认为dp[i][i]
int dp[1000][1000]= {0};
for(int i = 0; i < len; i++)
{
dp[i][i] = 1;//初始状态,在求解前必须初始化
for(int j = 0; j < i; j++)
{
if(i == j+1)
{
if(s[i] == s[j])
dp[j][i] = 1;
}
else
{
if(s[i] == s[j])
{
dp[j][i] = dp[j+1][i -1];
}
}
if(dp[j][i] && max_len < (i - j +1))
{
max_len = (i - j +1);
start = j;
}
}
}
rs = s.substr(start,max_len);
return rs;
}
};
这种方法有需要注意的几点:
(1)最大长度的初始值为1,而不是0,默认为dp[i][i]这种形式。
(2)由于求解父问题实质,是将父问题分解成为若干个子问题,所以子问题必须被解决,才能求解父问题。所以,一定要利用初始状态对dp进行初始化,即dp[i][i]=1。(动态规划类问题都要初始化初始状态)
(3)在这个程序中,利用dp[j][i]来代替理论上的dp[i][j],这是因为第一层for循环还没取到所有值的时候,第二层for循环已经取了所有可能的值了,这就可能导致子问题还没解决,就去求解父问题了。例如:
求dp[0][4]时,需用到dp[1][3],如果用常规的for循环的话,i=1肯定比i=0出现的晚,导致父问题求解出错。(这可以看成动态规划类问题的常用的技巧)
提交结果:Accepted( 212 ms). 比方法2慢好多...
========================================经查知,还有一种更优的算法============================================================================================================================
方法4:
就是有名的Manacher算法了,感觉这个算法真的不容易想到,这个算法的时间复杂度直接达到了常数级别,即O(n)。理解一下这个算法,对思维的锻炼还是挺不错的。Manacher算法的大致思路如下:
1.预处理:
(1)对于一个输入的字符串s,把字符串中的任意两个字符之间插入一个"#"(也可以是其他字符),第一个字符之前和最后一个字符之后也要插入。这样就生成了一个新字符串,例如:对于字符串aabbcc,经过处理后,就变成了#a#a#b#b#c#c#。这么做的好处就是不用考虑字符串的奇偶性了,所有的字符串的长度都变成了奇数。
(2)对于经过第一步处理后的字符串,在该字符串的首位各添加一个字符,但首尾字符一定不能是相同的。(如果是相同的话,在判断最后一个#时,会把这两个字符也考虑进去)。例如:对于#a#a#b#b#c#c#,首位字符分别添加为"%"和"$",则最终经过预处理后的字符串就变成了%#a#a#b#b#c#c#$。这么做的好处是为了防止判断字符串时发生越界。
2.构造一个数组P,其中P[i]表示的是以字符s1[i]为中心最长的回文串向左/向右扩展的长度(包括s[i],可以理解成其"半径"),P数组有一个性质:P[i] - 1是是该回文子串在原字符串中的长度(即在s中的长度)。为什么呢?以下是证明:
原字符串是s经过预处理后,变成了长度为奇数的字符串s1,已知P[i],则以s1[i]为中心的最长回文串的长度为2*p[i] -1(回文子串的长度必然为奇数),其中一定有p[i]个分隔符"#"(观察可知),所以该回文子串在原字符串s中的长度为p[i] - 1。所以求出数组P这个问题基本就解决了。
3.如何求解数组P呢?这里需要引入两个变量,id和mx,其中id表示某个回文串的中心,并且该回文串满足这样一个性质:它右边界是目前所有回文串中最大的。而mx表示的就是这个回文串的右边界的下标。对于数组p,我们可以通过mx和id以及之前已经求出的p[i]的值来求解,具体如下:
先从左至右依次计算P[i],但计算P[i]时,P[j](j<i)已经计算完毕。此时分为两种情况:
(1)i < mx.
1、 当i < mx 时,如下图。此时可以得出一个非常神奇的结论p[i] >= min(p[2*id - i], mx - i),下面我们来解释这个结论

如何根据p[j]来求p[i]呢,又要分成两种情况
(1.1)当mx – i > p[j], 这时候以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以 此时P[i]一定是等于p[j]的。如下图
注:这里p[i]一定等于p[j],后面不用再匹配了。因为如果p[i]后面还可以继续匹配,根据对称性,p[j]也可以继续扩展了。

(1.2)当mx – i <= p[j], 以S[j]为中心的回文子串不完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] 至少等于 mx - i,至于mx之后的部分是否对称,就只能老老实实去匹配了。
注:如果mx – i < p[j] ,这时p[i]一定等于mx - i, 因为如果p[i]在mx之后还可以继续匹配,根据对称性,mx之后匹配的点(包括mx)一定会出现在my的前面,这说明p[id]也可以继续扩展了

所以,最后p[i]去最小值(之后的值要去匹配),即p[i] = min(p[2*id - i], mx - i).
(2)i >= mx.
此时并不能利用已知的信息来求解P[i],此时默认P[i]=1,剩下的部分通过匹配来求解P[i]。
该方法的代码如下:
class Solution {
public:
string longestPalindrome(string s) {
int len = s.size();
if(len <= 1)return s;
//对s进行预处理
string temp_str = "#";
for(int i = 0; i < len; i++)
{
temp_str += s[i];
temp_str += "#";
}
temp_str += "^";
string st_str = "";
st_str += "%";
st_str += temp_str;
return Manacher(st_str,s);
}
//马拉车算法,时间复杂度为O(n)
string Manacher(string s1,string s2)
{
int p[3000] = {0};
int id = 0, mx = 0;
int len = s1.size();
int max_len = 0;
int flag = 0;
for(int i = 1; i < len - 1; i++)
{
if(i < mx)
{
if(p[2 * id - i] < (mx - i))
p[i] = p[2 * id - i];
else//即p[2*id-i] >= (mx -i)
p[i] = mx - i;
}
else
{
p[i] = 1;
}
//通过匹配计算p[i]
while(s1[i + p[i]] == s1[i - p[i]])
p[i]++;
//更新mx和id的值
if(p[i] + i > mx)
{
mx = p[i] + i - 1;
id = i;
}
if(p[i] > max_len)
{
max_len = p[i];
flag = i - p[i];
}
}
return s2.substr(flag/2, max_len - 1);
}
};
这段代码中有几个需要注意的地方:
1.P[i]的计算过程可以不通过分情况考虑,直接用P[i] = min(p[2*id-i],mx-i)来求解,我写成这样是为了更直观的去理解。
2.实际上通过匹配计算P[i],都是mx - i<= p[2*id-i]的情况,只有超过mx的地方才通过匹配计算p[i],所以它的时间是严格的线性的。
3.mx = p[i] +i -1,因为p[i]实际上也把s[i]也考虑进去了,所以此处还要减去1。
4.在最后计算最长回文子串在原字符串中的部分时,起始点为i-p[i]/2,(这也是通过观察的得知的),这一点需要注意。
提交结果:Accepted( 6ms).确实很快...
参考:
http://blog.csdn.net/suool/article/details/38383045

 浙公网安备 33010602011771号
浙公网安备 33010602011771号