




实际上,代价函数(cost function)和损失函数(loss function 亦称为 error function)是同义的。它们都是事先定义一个假设函数(hypothesis),通过训练集由算法找出一个最优拟合,即通过使的cost function值最小(如通过梯度下降),从而估计出假设函数的未知变量。
例如: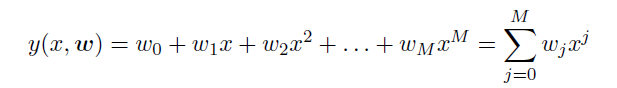
可以看做一个假设函数,而与之对应的loss function如下:
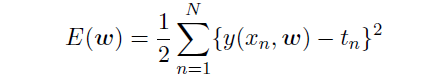
通过使E(w)值最小,来估计出相应的w值,从而确定出假设函数(目标函数),实现最优拟合。
硬要说区别的话,loss function用在参数估计上比较多;而cost function则用在优化理论上比较多(貌似这样....)

