基于tesseract-OCR进行中文识别
1. 环境准备
1.1 下载
下载Tesseract-OCR安装包,地址为:
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w32-setup-v4.0.0-beta.1.20180608.exe
参考链接:https://github.com/tesseract-ocr/tesseract
1.2 安装
双击安装,语言库部分选择math,chinese simplified.

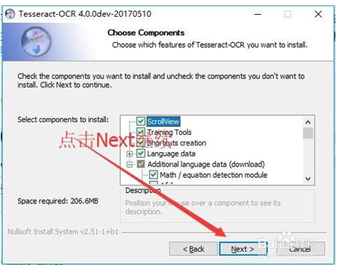
1.3 添加环境变量
将Tesseract-OCR安装目录加入环境变量,

变量名TESSDATA_PREFIX
变量值F:\Program Files (x86)\Tesseract-OCR\tessdata
1.4 测试
将以下图片保存为test.jpg,然后放在E盘根目录下

在cmd窗口中执行 tesseract test.jpg test.txt –l chi_sim+eng(chi_sim是中文识别包,equ是数学公式包,eng是英文包),即可将图片中的文字识别出来,识别结果如下:

1.5 语言库
语言库地址为:https://github.com/tesseract-ocr/tessdata
将所需要的语言库下载下来,放在F:\Program Files (x86)\Tesseract-OCR\tessdata目录下
1.6 编译生成定制的字库
采用jTessBoxEditor 生成自己的字库。
1.6.1 软件准备
首先需要安装java虚拟机10.0.2+jTessBoxEditor。
jTessBoxEditor下载地址:
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
这里我们下载jTessBoxEditorFX-2.0.1.zip版本,带FX的版本,才支持中文字符编辑。
1.6.2 字库制作
字库制作具体步骤:
1.环境变量设置
解压jTessBoxEditorFX-2.0.1.zip,发现有tesseract-ocr文件夹,里面有tesseract.exe软件。因此我们要将系统中之前安装的tesseract软件卸载,将环境变量定位到当前tesseract-ocr所在文件夹。
此外还需要添加环境变量:TESSDATA_PREFIX,变量值指向
..\jTessBoxEditorFX\tesseract-ocr\tessdata

2.图片准备
我们希望制作一个数字字库,能够识别以下字体的数字。

我们将上面图片中的每一行保存成一个小图片。然后打开然后用java虚拟机打开jTessBoxEditorFX.jar。
选择 Tools -> Merge TIFF,打开对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片,注意对话框中“文件类型”的选取:

点击 “打开” 之后弹出保存对话框,还是选择在当前路径下保存,文件命名为 “num_my.font.exp0.tif” ,格式只有一种 “TIFF” 可选:
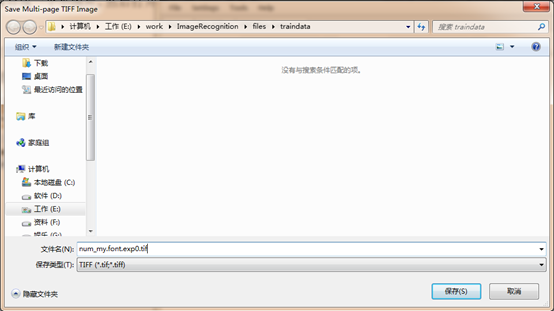
点击 “保存” 之后在指定路径下生成所有样本的 “合并” 图片 chi_my.font.exp0.tif。
3.使用tesseract生成.box文件
在上一步骤中生成的 “num_my.font.exp0.tif” 文件所在路径下打开命令行程序,执行以下命名:
tesseract num_my.font.exp0.tif num_my.font.exp0 –l eng batch.nochop makebox
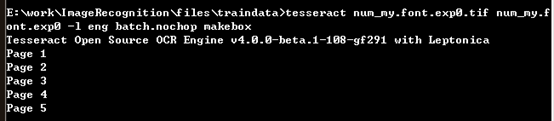
执行后,在当前路径下生成num_my.font.exp0.box文件。
使用jTessBoxEditor调整.box训练文件
“.box” 文件中记录了每个字符在图片上的位置以及识别出的内容,训练之前需要使用jTessBoxEditor调整字符的位置和内容。
打开 jTessBoxEditor ,点击 Box Editor -> Open ,打开步骤2中生成的 “num_my.font.exp0.tif” ,会自动关联到 “num_my.font.exp0.box” 文件:
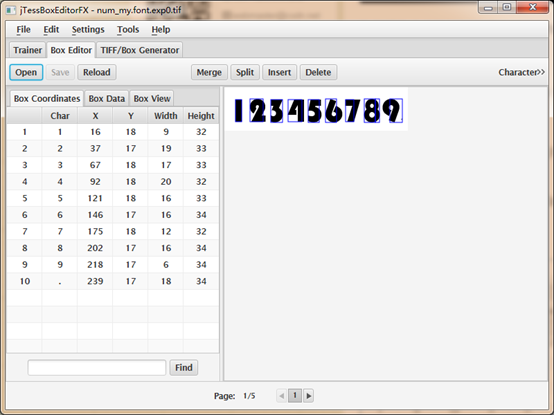
右上角红色方框内分别可以调整字符的内容、位置、宽高等,不带 “FX”版本的jTessBoxEditor还可以直接在方框内输入具体的数值,但不支持中文字符!…… 带 “FX” 版本的jTessBoxEditor支持中文字符,但是竟然不可以在方框内直接输入数值,需要一下一下点击方框右边的三角框!
接下来我们需要对识别不对的地方进行调整。
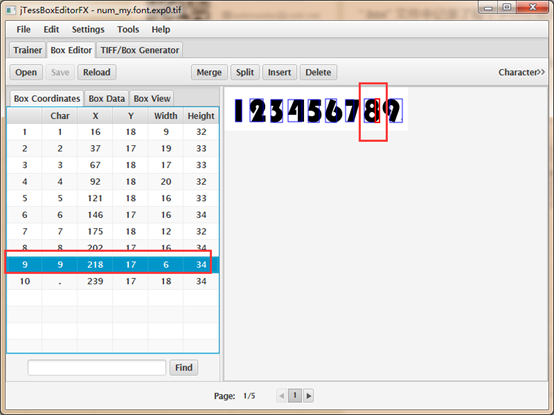
比如图片中还在数字”8”的位置,但它识别成“9”了,因此这里我们需要点击Merge进行处理。同理,有的地方需要点击spilit,insert进行处理。
上图调整之后如下:

依次将5张所需要训练的图片都进行适当的调整。
调整所有样本后点击 File -> Save as 另存为调整后的 “.box” 文件或Ctrl + S 原地保存。这里我们原地保存。
4.使用echo命令创建字体特征文件
在cmd窗口中执行echo num_my 0 0 0 0 0>font_properties

执行完成之后,在当前文件夹下生成font_properties文件
也可以手动在该文件夹下建立一个名为 “font_properties” 的文件,这个文件没有后缀名称,输入内容 “font 0 0 0 0 0” , 表示字体 font 的粗体、倾斜等共计5个属性全都设置为0
注意 : 这里输入的 “font” 名称必须与 “chi_my.font.exp0.box” 中两个点号之间的 “font” 名称保持一致。
在tesseract训练语言包的过程中,jTessBoxEditor的作用就是调整(位置和内容)tesseract生成的 “.box”文件,这个文件中列出了每个字符在图片上的位置以及内容。
5.使用tesseract生成num_my.font.exp0.tr训练文件
在终端上执行以下命令:
tesseract num_my.font.exp0.tif num_my.font.exp0 nobatch box.train
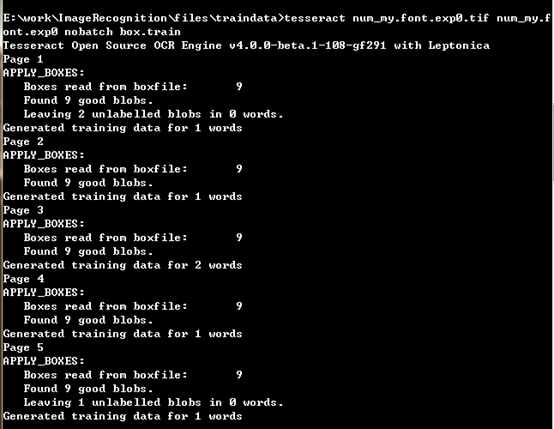
执行后在当前文件夹下生成 num_my.font.exp0.tr训练文件。
6.生成字符集文件
在终端上执行以下命令:

执行之后在当前文件夹下生成 “unicharset” 文件。
7.生成数据字典
在终端上依次执行以下两条命令:
mftraining -F font_properties -U unicharset -O num_my.unicharset num_my.font.exp0.tr
cntraining num_my.font.expo.tr
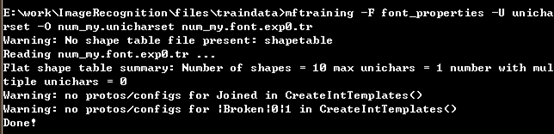

会在当前目录下生成 4 个文件(inttemp、pffmtable、normproto、shapetable),需要手动修改名称,这里我们修改成num_my.inttemp、num_my.pffmtable、num_my.normproto、num_my.shapetable。
8.合并数据文件
在cmd窗口中执行以下命令,生成num_my.traneddata语言包文件
combine_tessdata num_my.

将num_my.traneddata文件放到\jTessBoxEditorFX\tesseract-ocr\tessdata目录下。
9.验证训练生成的语言包
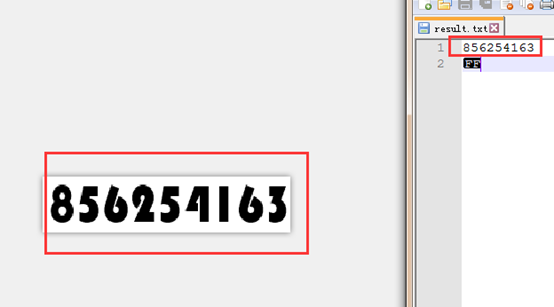
在cmd窗口中执行以下命令:
Tesseract test2.png result –l num_my –psm 7
然后打开result.txt.即可看到识别结果,下图左边是test2.png图片,又图是识别结果。
参考链接:
https://blog.csdn.net/dcrmg/article/details/78233459?locationNum=7&fps=1
1.7 Leptonica编译
下载leptonica源码:http://www.leptonica.com/source/leptonica-1.76.0.tar.gz
安装cmake,打开cmake-gui,按下图进行配置
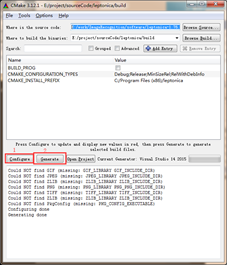
先点击configure,出现红色部分GIF,JPEG,TIFF,ZLIB都是leptonica所需要的图片识别库,这里我们不管他,再次点击Configure按钮进行编译就好了。
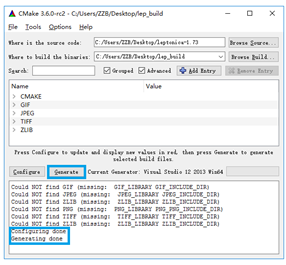
在generate生成的目录中,打开leptonica.sln
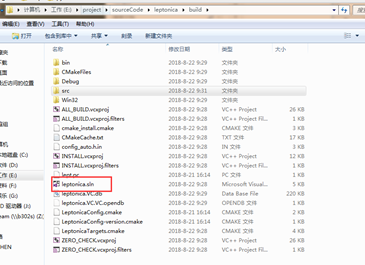
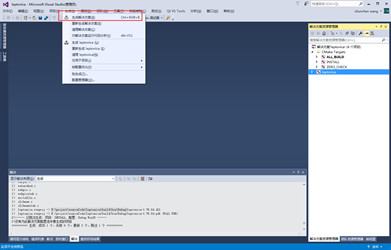
点击生成,默认生成的是dll文件,这里需要修改下,生成.lib文件

参考链接:https://blog.csdn.net/zzb4702/article/details/51760678
1.8 Tesseract 编译
1.8.1 下载&配置cppan
地址为:https://raw.githubusercontent.com/cppan/binaries/master/cppan-master-Windows-client.zip
解压该压缩包,将cppan所在目录添加到系统环境变量PATH
1.8.2 Tesseract源码下载
Tesseract源码地址为:https://github.com/tesseract-ocr/tesseract
1.8.3 Cmake下载
Cmake下载地址为:https://cmake.org/download/
1.8.4 Tesseract编译
打开cmd窗口,定位到tesseract目录,执行cppan命令,如下:
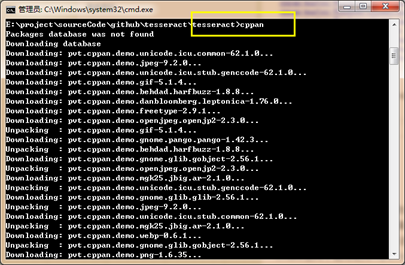
在tesseract目录下创建build目录,然后进入到build目录,执行cmake ..
如果出现如下错误
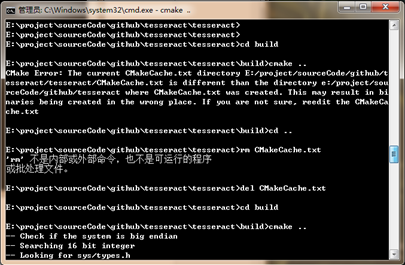
请将tesseract目录下的CMakeCache.txt删除,再重新cmake ..
该过程大概需要5分钟。
然后在build目录下生成vs2015的工程文件
打开tesseract.sln,然后点击生成,应该会报错
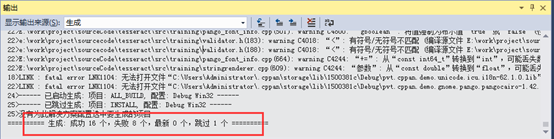
尽管有报错,但仍然会在tesseract\build\Debug目录下生成tesseract40d.lib库文件
参考链接:https://blog.csdn.net/naidoudou/article/details/70225849
如果需要生成x64的库文件,在tesseract的目录下,打开cmd窗口,执行以下命令(先要删除tesseract目录下的之前生成的CMakeList.txt缓存文件):
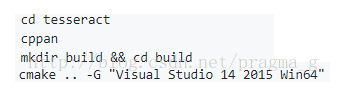
下图是正在编译时的界面
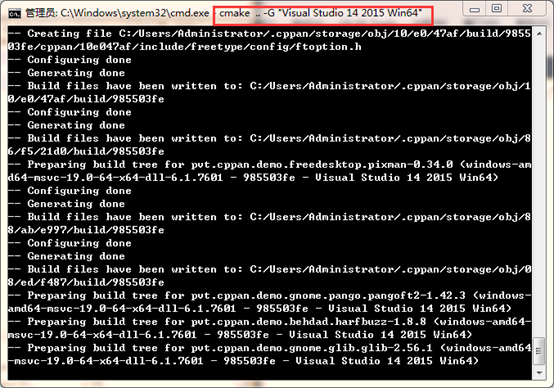
然后打开tesseract.sln,编译生成库文件
参考链接:https://blog.csdn.net/pragma_g/article/details/79272271
1.8.5 另一种方法编译tesseract
修改tesseract的CMakeList.txt文件
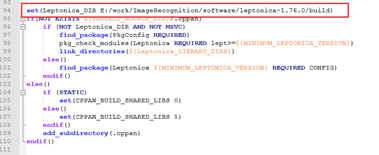
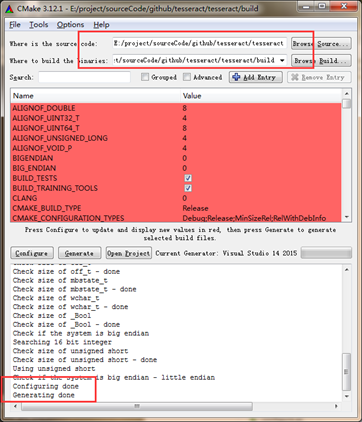
指定leptonica的目录为图中所在目录
然后然后打开cmake-gui,点击configure,再点击generate,生成vs2015的工程

参考链接:https://blog.csdn.net/yazi1297/article/details/54706390
2. 项目开发
2.1 新建工程
打开Visual Studio2015,新建一个空项目,然后添加test.cpp文件,增加源代码如下:
#include <string>
#include <baseapi.h>
#include <publictypes.h>
#include "leptonica/allheaders.h"
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
string outText;
string imPath = "E://pictest//test.bmp";
// Create Tesseract object
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
/*
Initialize OCR engine to use English (eng) and The LSTM
OCR engine.
There are four OCR Engine Mode (oem) available
OEM_TESSERACT_ONLY Legacy engine only.
OEM_LSTM_ONLY Neural nets LSTM engine only.
OEM_TESSERACT_LSTM_COMBINED Legacy + LSTM engines.
OEM_DEFAULT Default, based on what is available.
*/
ocr->Init(NULL, "chi_sim+eng+equ", tesseract::OEM_DEFAULT);
// Set Page segmentation mode to PSM_AUTO (3)
// Other important psm modes will be discussed in a future post.
ocr->SetPageSegMode(tesseract::PSM_AUTO);
// Open input image using OpenCV
Mat im = cv::imread(imPath, IMREAD_COLOR);
// Set image data
ocr->SetImage(im.data, im.cols, im.rows, 3, im.step);
// Run Tesseract OCR on image
outText = string(ocr->GetUTF8Text());
// print recognized text
cout << outText << endl;
// Destroy used object and release memory
ocr->End();
return EXIT_SUCCESS;
}
2.2 工程配置
该工程选用的是OpenCV2.4,Tesseract4.0,Leptonica-1.76
因而增加对应的头文件目录和库文件目录如下
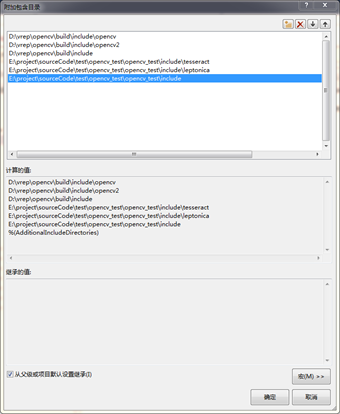

2.3 编译运行
test.bmp原图为:

编译运行结果如下:

可见中文完全乱码
2.4 中文乱码
针对中文乱码情况,网上提供解决方案,UTF--->Unicode--->Ansi
在test.cpp中增加如下两个函数:
//utf-8转unicode
wchar_t * CIDcardRecogizeDlg::Utf_8ToUnicode(char* szU8)
{
//UTF8 to Unicode
//由于中文直接复制过来会成乱码,编译器有时会报错,故采用16进制形式
//预转换,得到所需空间的大小
int wcsLen = ::MultiByteToWideChar(CP_UTF8, NULL, szU8, strlen(szU8), NULL, 0);
//分配空间要给'\0'留个空间,MultiByteToWideChar不会给'\0'空间
wchar_t* wszString = new wchar_t[wcsLen + 1];
//转换
::MultiByteToWideChar(CP_UTF8, NULL, szU8, strlen(szU8), wszString, wcsLen);
//最后加上'\0'
wszString[wcsLen] = '\0';
return wszString;
}
//将宽字节wchar_t*转化为单字节char*
char* CIDcardRecogizeDlg::UnicodeToAnsi( const wchar_t* szStr )
{
int nLen = WideCharToMultiByte( CP_ACP, 0, szStr, -1, NULL, 0, NULL, NULL );
if (nLen == 0)
{
return NULL;
}
char* pResult = new char[nLen];
WideCharToMultiByte( CP_ACP, 0, szStr, -1, pResult, nLen, NULL, NULL );
return pResult;
}
并修改main函数:
char* test1 = ocr->GetUTF8Text();
wchar_t* tempchar = Utf_8ToUnicode(test1);
char* resulttemp = UnicodeToAnsi(tempchar);
// outText = string(ocr->GetUTF8Text());
// print recognized text
cout << resulttemp << endl;
即可解决中文乱码问题,识别结果如下:
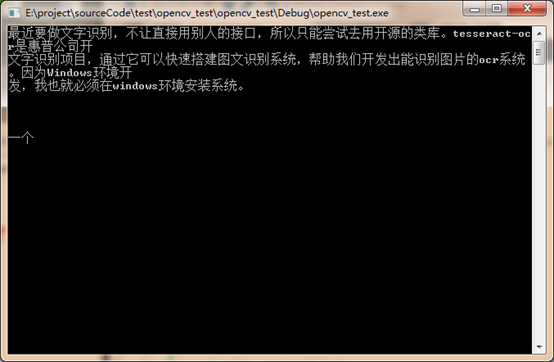
参考链接:https://blog.csdn.net/liulina603/article/details/45668307

 浙公网安备 33010602011771号
浙公网安备 33010602011771号