
CPython解释器支持的线程和进程
一、gevent :实现遇到IO操作就人为指定cpu切换的协程操作。
是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet,它是以C扩展块形式接入Python的轻量级协程。Greenlet全部运行在主程序操作系统进程的内部,但他们被协作式地调度。
g1=gevent.spawn(funcname,args)创建一个协程对象g1,
spawn括号内第一个参数是函数名,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的。
创建gevent。spawn()对象后,在该函数中出现IO阻塞,就会主动的切换cpu执行另外的操作,从而实现轻量级的协程,提高程序的性能。
import gevent
from gevent import monkey;monkey.patch_all()
#该步操作就是给gevent打一个补丁,以让gevent模块识别除了自己以外的IO操作,如time.sleep()等,建议以后只要使用到gevent就打下补丁
import time
def foo1():
print('foo1 run first')
gevent.sleep(2)
time.sleep(5) #如果不打补丁,gevent不能识别time.sleep(5)位IO操作,还是会顺序执行
print('foo1 run second')
def foo2():
print('foo2 run 1')
gevent.sleep(5)
time.sleep(4)
print('foo2 run 2')
g1=gevent.spawn(foo1)
g2=gevent.spawn(foo2) #使用gevent实现IO操作的协程,至少要指定两个函数,以实现遇到IO,切换到另一个函数,然后IO执行结束在切换回去。
gevent.joinall([g1,g2]) #同g1.join(),g2.goin() 必须有join操作,否则主程序运行结束,停止运行,不会有打印等操作
print('哈哈哈')
gevent应用模拟同步异步IO操作
#gevent模拟实现异步和同步的操作
from gevent import monkey;monkey.patch_all()
import gevent
import time
def work(id):
a='哈哈哈'
time.sleep(1)
print('work %s done' % id)
def synchronous():
for i in range(1,10):
work(i)
def asynchronous():
threads = [gevent.spawn(work,i) for i in range(1,10)]
gevent.joinall(threads)
start_time1=time.time()
synchronous()
stop_time=time.time()
print('同步耗费的时间%s' % (stop_time-start_time1))
#同步耗费的时间9.003515005111694顺序执行
start_time2=time.time()
asynchronous()
stop_time2=time.time()
print('异步耗费的时间%s' % (stop_time2-start_time2))
#异步耗费的时间1.0020573139190674 非顺序执行,哪个先执行完IO操作哪个先执行。
gevent模拟爬虫爬取网页操作
#模拟爬虫爬取网页的操作
from gevent import monkey;monkey.patch_all()
import gevent
import time
import requests
def get_page(url):
print('get %s' %url)
response=requests.get(url)
if response.status_code==200:
print('%d bytes recevied from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall(
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawh(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
)
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
#用gevent模拟socket服务端和客户端进行单线程通信
服务端
#通过gevent实现单线程下的socket并发
from gevent import monkey;monkey.patch_all()
import gevent
import socket
def connect(ip,port):
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
s.bind((ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
#gevent.joinall([gevent.spawn(work,conn,addr)])
#如果要实现多客户端的链接,就不能有上面的join,加上之后,一个客户端链接不结束,主进程永远不结束,就只能实现一个客户端的链接,不能实现多客户端的同时在线。
gevent.spawn(work,conn,addr)
def work(conn,addr):
try:
while True:
msg=conn.recv(1024)
if not msg:break
print('connect from %s,msg is :%s' %(addr,msg))
conn.send(msg.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
connect('127.0.0.1',8080)
单进程客户端
#通过gevent实现单线程下的socket并发
# import socket
#
# s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# s.connect(('127.0.0.1',8080))
# while True:
# msg=input('>>:').strip()
# if not msg:continue
# s.send(msg.encode('utf-8'))
# return_msg=s.recv(1024)
# print(return_msg)
多线程客户端
#多线程并发多个客户端
import socket
from threading import Thread
import threading
def client(ip,port):
c=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
c.connect((ip,port))
count =1
while True:
c.send(('%s say hello %d' % (threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(10):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()
二、协程
'''
协程:是单线程下的并发,又称微线程,Coroutine。协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。而不是那种依赖于操作系统控制切换的。
需要强调的是:
1、python的线程属于内核级别的,即由操作系统控制调度(如单线程一旦遇到I/O就被迫交出cpu执行权限,
切换其它线程运行)
2、单线程内开启协程,一旦遇到I/O,从应用程序级别(而非操作系统)控制切换对比操作系统控制线程的
切换,用户在单线程内控制协程的切换,优点如下:
①协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级。
②单线程内就可以实现并发的效果,更大限度的利用cpu
要实现协程,关键在于用户程序自己控制切换,切换之前必须由用户程序自己保存协程上一次调用时的状态,
如此,每次重新调用时,能够以上次的位置继续执行
(详细的:协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其它地方,在切回
来的时候,恢复先前保存的寄存器上下文和栈)。
为此,我们之前已经学习过一种在单线程下可以保存程序运行状态的方法,即yield,
1、yield可以保存状态,yield的状态保存于操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级
2、send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换。
缺点:
协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程。
协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
协程的定义(满足1,2,3就可以称为协程)
1、必须在只有一个单线程里实现并发
2、修改共享数据不需加锁
3、用户程序里自己保存多个控制流的上下文栈
4、附加:一个协程遇到I/O操作自动切换到其它协程(如何实现检查I/O,yield、greenlet都无法实现,就用到类gevent模块(select机制)
yield切换在没有I/O的情况下或者没有重复开辟内存空间的操作,对效率没有什么提升,甚至更慢,为此,可以用
greenlet来为搭建演示这种切换。
'''
# import time
# def consumer(seq):
# a=333333
# b='dfdfdf'
# c='哈哈哈'
# d=998
#
# def producer(target,seq):
# for item in seq:
# consumer(item)
# start_time=time.time()
# producer(consumer,range(100000000))
# stop_time=time.time()
# print('run time is %s' %(stop_time-start_time))
#consumer中直接pass不做任何操作,耗时9.473541975021362秒
#consumer中定义多个变量后,耗时12.311704158782959秒,
import time
def consumer():
a=333333
b='dfdfdf'
c='哈哈哈'
d=998
while True:
item=yield
def producer(target,seq):
for item in seq:
target.send(item)
g=consumer()
next(g)
start_time=time.time()
producer(g,range(100000000))
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
#使用yield后耗时11.68366813659668秒
三、Python GIL(Global Interpreter Lock)
在CPython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
首先需要明确的是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以GIL并不是Python的特性,Python完全可以不依赖于GIL。
正因为有了GIL的存在,同一时刻同一进程中只能有一个线程被执行,不能利用cpu的多核优势。
结论:现在的计算机基本上都是多核,Python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
#计算密集型
from threading import Thread
from multiprocessing import Process
import random,time,os
# def work():
# res=0
# # start_time=time.time()
# for i in range(100000000):
# res+=i
# stop_time=time.time()
# print('run time is %s' % (stop_time-start_time))
#work() #单个执行是6.8723931312561035秒
# if __name__ == '__main__':
# p_l=[]
# start_time=time.time()
# for i in range(20):
# t=Thread(target=work) #131.88954377174377
# #t=Process(target=work) #69.68398571014404
# t.start()
# p_l.append(t)
# for p in p_l:
# p.join()
# stop_time=time.time()
# print('run time is %s ;' %(stop_time-start_time))
#I/O密集型应用,用time.sleep()模拟IO阻塞
def work():
time.sleep(3)
#print(os.getpid())
if __name__ == '__main__':
t_l=[]
start_time=time.time()
for i in range(20):
#t=Thread(target=work) #3.002171754837036
t=Process(target=work) #6.054346323013306
t_l.append(t)
t.start()
for i in t_l:
t.join()
stop_time=time.time()
print('run time is %s' % (stop_time-start_time))
四、Greenlet:
greenlet是一个用C实现的协程模块,相比于Python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
from greenlet import greenlet
#greenlet模块
def test1():
print('test1,first')
gr2.switch()
print('test1,second')
gr2.switch()
def test2():
print('test2,1')
gr1.switch()
print('test2,2')
gr1=greenlet(test1)
gr2=greenlet(test2)
gr1.switch()#遇到switch就自动切换
五、socketserver实现并发
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
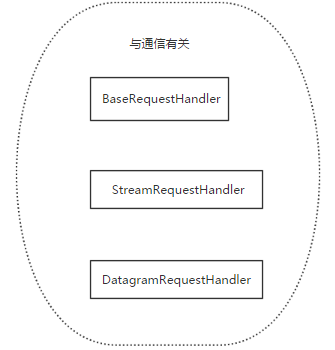
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
server类:
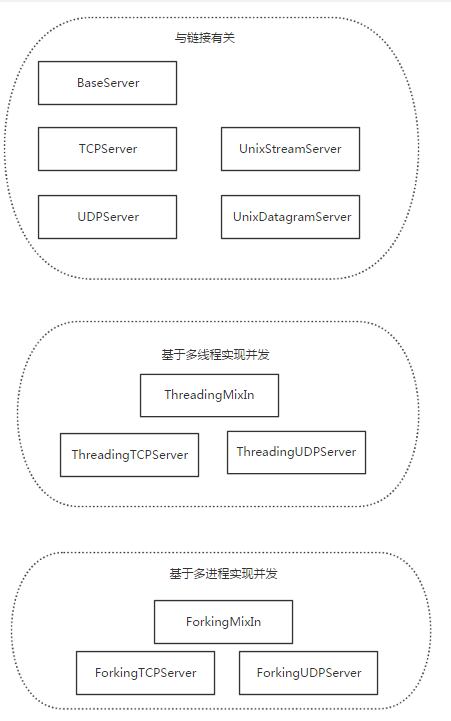
request类:
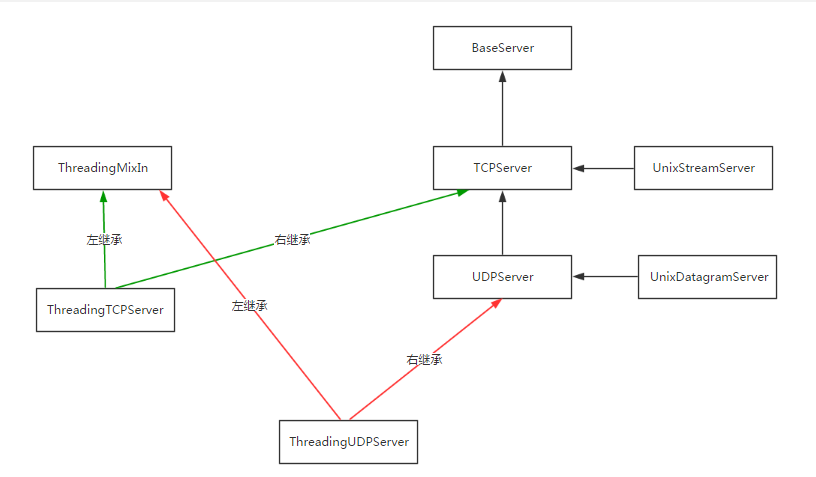
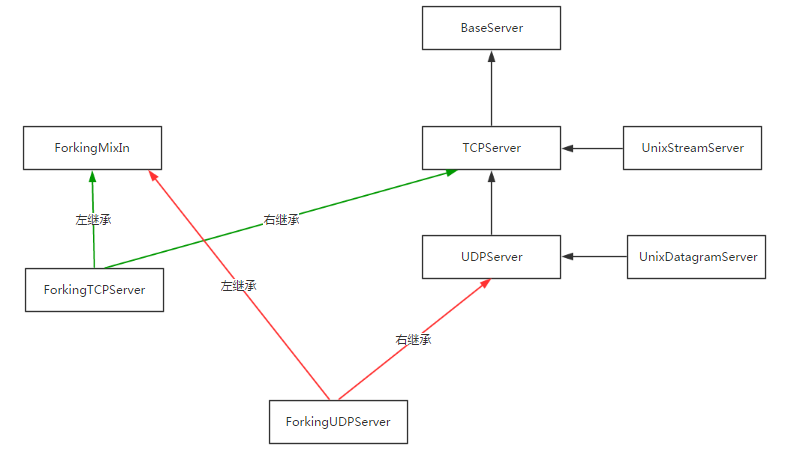
继承关系:
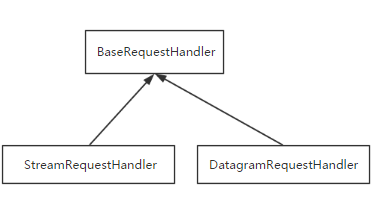
以下述代码为例,分析socketserver源码:
ftpserver=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FtpServer)
ftpserver.server_forever()
查找属性的顺序:ThreadingTCPServer ->ThreadingMixIn -> TCPServer -> BaseServer
1、实例化得到ftpserver,先找类ThreadingTCPServer的__init__,在TCPServer中找到,进而执行server_bind,server_active
2、找ftpserver下的server_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中
3、执行self._handle_request_noblock()进而执行request,client_address=self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request,client_address)
4、在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request,client_address)
5、上述四部分完成类链接循环,本部分开始进入处理通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找。。。
源码分析总结:
基于tcp的socketserver我们自己定义的类中的
1、self.server即套接字对象
2、self.request即一个链接
3、self.client_address和客户端地址
基于udp的socketserver我们自己定义的类中的
1、self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf',<socket.socket fd=200,family=AddressFamily.AF_INET,type=SocketKind.SOCK_DGRAM,proto=0,laddr=('127.0.0.1',8080)>)
2、self.client_address即客户端地址
#FTPServer
import socketserver
#解决链接,基于线程的ThreadingTCPServer,基于进程的ForkingTCPServer
class MyHandler(socketserver.BaseRequestHandler): #通信循环##self.request是conn赋值来的。
def handler(self):
while True:
res=self.request.recv(1024)
print('client %s msg :%s' %(self.client_address,res))
self.request.send(res.upper())
if __name__ == '__main__':
s=socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyHandler)
s.serve_forever() #链接循环
#FTPClient
import socket
import struct
import json
import os
class MYTCPClient:
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
allow_reuse_address = False
max_packet_size = 8192
coding='utf-8'
request_queue_size = 5
def __init__(self, server_address, connect=True):
self.server_address=server_address
self.socket = socket.socket(self.address_family,
self.socket_type)
if connect:
try:
self.client_connect()
except:
self.client_close()
raise
def client_connect(self):
self.socket.connect(self.server_address)
def client_close(self):
self.socket.close()
def run(self):
while True:
inp=input(">>: ").strip()
if not inp:continue
l=inp.split()
cmd=l[0]
if hasattr(self,cmd):
func=getattr(self,cmd)
func(l)
def put(self,args):
cmd=args[0]
filename=args[1]
if not os.path.isfile(filename):
print('file:%s is not exists' %filename)
return
else:
filesize=os.path.getsize(filename)
head_dic={'cmd':cmd,'filename':os.path.basename(filename),'filesize':filesize}
print(head_dic)
head_json=json.dumps(head_dic)
head_json_bytes=bytes(head_json,encoding=self.coding)
head_struct=struct.pack('i',len(head_json_bytes))
self.socket.send(head_struct)
self.socket.send(head_json_bytes)
send_size=0
with open(filename,'rb') as f:
for line in f:
self.socket.send(line)
send_size+=len(line)
print(send_size)
else:
print('upload successful')
client=MYTCPClient(('127.0.0.1',8080))
client.run()
FtpClient
udp客户端
from socket import *
c=socket(AF_INET,SOCK_DGRAM)
#因为没有链接,因此在这里也没有connect,对用着tcp中的accept。
while True:
msg=input('>>:').strip()
c.sendto(msg.encode('utf-8'),('127.0.0.1',8080))
server_msg,server_addr=c.recvfrom(1024)
print('client %s msg %s' %(server_addr,server_msg))
六、基于udp的套接字
服务端
from socket import *
c=socket(AF_INET,SOCK_DGRAM)
c.bind(('127.0.0.1',8080))
#udp服务端不需要监听,因为它是基于数据报协议的,因此没有tcp的那种三次握手,不需要建立链接。
while True:
client_msg,s=c.recvfrom(1024)
print(client_msg)
c.sendto(client_msg.upper(),s)
客户端
'''
tcp协议比udp可靠是因为,tcp发送一波数据,先放在自己的缓存区,等到对方全部接收完毕才情况缓存,而udp不管对面有没有接收完成,只管发送,发送完后就清空缓存区。因此会丢包
'''
from socket import *
c=socket(AF_INET,SOCK_DGRAM)
#因为没有链接,因此在这里也没有connect,对用着tcp中的accept。
while True:
msg=input('>>:').strip()
c.sendto(msg.encode('utf-8'),('127.0.0.1',8080))
server_msg,server_addr=c.recvfrom(1024)
print('client %s msg %s' %(server_addr,server_msg))
七、事件Event
同进程一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其它线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要用threading库中的Event对象。对象包含一个可由线程设置的信号标识,它允许线程等待某些事件的发送。初始情况下,Event对象中的信号标志被设置为假,如果有线程等待一个Event对象,而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,则将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件,继续执行
#常用方法: event.isSet():返回event的状态值; event.wait() :如果event.isSet()==False将阻塞线程; event.set():设置event的状态值为True,所有阻塞池的线程激活进入就绪状态,等待操作系统调度; event.clear() :恢复event的状态值为False。
from threading import Event,Thread
import threading,time
#e=Event()
# e.set()#设置,默认情况下相当于False,一旦设置就改为True
# e.wait() #一旦set() ,wait就由阻塞变为可以运行的类
#链接MySQL客户端,先验证客户端是否正常,如果正常则链接
def conn_mysql():
print('%s waiting...' % threading.current_thread().getName())
e.wait()
print('%s start to connect mysql...' % threading.current_thread().getName())
time.sleep(2)
def check_mysql():
print('%s checking...' %threading.current_thread().getName())
time.sleep(4)
e.set() #上面遇到e.wait()先阻塞,一旦e.set()则在e.wait()那里就可以往下执行了
if __name__ == '__main__':
e = Event() # 先创建事件对象
c1=Thread(target=conn_mysql)
c2=Thread(target=conn_mysql)
c3=Thread(target=conn_mysql)
c4=Thread(target=check_mysql)
c1.start()
c2.start()
c3.start()
c4.start()
八、同步锁、 死锁和递归锁
#线程锁
#首先创建线程锁对象,用的时候,将需要枷锁保护的数据用with lock1对象包起来
# from threading import Thread,Lock
# import time
# count =100
# def work():
# with lock1:
# lock1.re
# global count
# num=count
# time.sleep(1)
# count=num-1
#
# if __name__ == '__main__':
# lock1=Lock()
# t_l=[]
# for i in range(100):
# t=Thread(target=work)
# t_l.append(t)
# t.start()
# for t in t_l:
# t.join()
# print(count)
#不加锁的情况下执行结果为99
##############
#互斥锁与递归锁
from threading import Thread,Lock,RLock#递归锁
import time
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print('\033[45m%s 拿到A锁\033[0m' % self.name)
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' % self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
time.sleep(1)
print('\033[43m%s 拿到B锁\033[0m' % self.name)
mutexA.acquire()
print('\033[45m%s 拿到A锁\033[0m' % self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
mutexA=mutexB=RLock()
#递归锁,这两个锁合称一个递归锁,遇到任何一个mutexA/mutexB锁,则acquire计数加1,只有当
#该锁的线程的acquire计数为0时,别的线程才能抢,只要不为0,则不管是mutexA/还是mutexB都不能被别的线程抢到。因此不会出现死锁现象
#死锁:线程A拿着锁A,线程B拿着锁B,而线程A需要锁B,线程B也需要锁A,锁A、B又相互不释放。形成互锁、
for i in range(20):
t=MyThread()
t.start()
# mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
九、信号量Semahpore
同进程一样
Semaphore管理一个内置的计数器,每当调用acquire()时内置计数器-1;调用release()时内置计数器+1;计数器不能小于0,;当计数器为0时,acquire()将阻塞线程直到其它线程调用release()。
from threading import Thread,Semaphore
import time
#信号量:
def work(id):
with sem:
time.sleep(3)
print('%s say hello' %id)
if __name__ == '__main__':
sem=Semaphore(5)
#信号量:相比于锁(一个坑位的厕所),信号量(有多个坑位的厕所),
#可以允许多个线程一块执行某任务,
#相比于进程池:
#进程池:我总共要执行20个进程,而进程池中只有4个,则进程是4个4个的建立
#信号量是20个线程一块建立出来,阻塞在信号量的地方,先执行5个在执行5个
for i in range(20):
t=Thread(target=work,args=(i,))
t.start()
单线程实现并发的爬取网页:
# import requests
# import time
# response=requests.get('https://www.python.org')
# print(response.status_code) #查看状态吗
# print(response.text) #以文本的形式显示代码 也是一种阻塞操作
# def get_page(url):
# print('GET page :%s' %url)
# response=requests.get(url)
# if response.status_code==200:
# print(response.text)
#
# start_time=time.time()
# get_page('https://www.python.org')
# get_page('https://www.yahoo.com')
# get_page('https://www.github.com')
# stop_time=time.time()
# print('run time is :%s' %(stop_time-start_time))
from gevent import monkey;monkey.patch_all()
import requests
import time
import gevent
def get_page(url):
print('GET page :%s' %url)
response=requests.get(url)
if response.status_code==200:
print(response.text)
start_time=time.time()
g1=gevent.spawn(get_page,'https://www.python.org')
g2=gevent.spawn(get_page,'https://www.yahoo.com')
g3=gevent.spawn(get_page,'https://www.github.com')
stop_time=time.time()
gevent.joinall([g1,g2,g3]) #join全部
print('run time is :%s' %(stop_time-start_time))
单线程实现并发的socket编程服务端
from gevent import monkey;monkey.patch_all()
from socket import * #或者直接用gevent模块下面的socket
from threading import Thread
import gevent
def server(ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
print('client',addr)
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
if not res:break
print('地址:%s,端口:%s,内容:%s' %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception:
pass
多线程基础
线程为执行单位,一个进程下最少有一个线程。
#创建线程的两种方式
# from threading import Thread
# def work(name):
# print('%s is work' % name)
#
# if __name__ == '__main__':
# t1=Thread(target=work,args=('agen',)) #同进程一样,args传入的一定是元组,最后加逗号
# t1.start()
#
# #方法二,创建类,继承与Thread
# class work(Thread):
# def run(self):
# print('%s is working' % self.name) #Thread 有自己的名字,默认是Thread-1,按顺序递增。
#
# t2=work()
# t2.start()
#由于线程间是共享所在进程的所有资源,因此创建线程比创建进程要快的多
#查看线程及进程的pid
# from multiprocessing import Process
# from threading import Thread
# import os
# def work():
# print('hello',os.getpid())
# #从打印顺序也可以看出创建线程比创建进程要快的多。先打印的是t1、t2,之后就执行类第一个打印主进程pid,之后是执行第二个打印pid,最后才是执行p1/p2
# if __name__ == '__main__':
# #在主进程下开启多个线程,每个线程的pid跟主进程的pid是一样的
# t1=Thread(target=work)
# t2=Thread(target=work)
# t1.start() #hello 2172
# t2.start() #hello 2172
# print('主进程pid', os.getpid()) #主进程pid 2172
# #在主进程下开启多个进程,每个进程的pid跟主进程的pid都是不同的
# p1=Process(target=work)
# p2=Process(target=work)
# p1.start() #hello 1844
# p2.start() #hello 1356
# print('主进程pid', os.getpid())
多线程socket客户端
from threading import Thread
from socket import *
s=socket(AF_INET,SOCK_STREAM)
s.connect(('127.0.0.1', 8080))
while True:
msg=input(">>:")
if not msg:continue
s.send(msg.encode('utf-8'))
return_msg=s.recv(1024)
print(return_msg)
多线程socket服务端
#多线程服务端
from socket import *
from threading import Thread
import time,random
def server(ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
print('client' ,addr)
t=Thread(target=walk,args=(conn,addr,))
t.start()
def walk(conn,addr):
try:
while True:
data=conn.recv(1024)
if not data:break
print('ip:%s,port:%s,msg:%s' % (addr[0],addr[1],data))
conn.send(data.upper())
except Exception:
pass
if __name__ == '__main__':
while True:
server('127.0.0.1',8080)
多线程实现文本编辑器
#输入、格式化、保存三个功能,多线程操作
from threading import Thread
res_l=[]
format_l=[]
def talk():
while True:
msg=input('>>:')
if not msg:continue
res_l.append(msg)
def format():
while True:
if res_l:
res=res_l.pop() #只要有值传入则获取该值并删除
format_l.append(res) #将获取的值放入另一个列表中
print(format_l)
def save():
while True:
if format_l:
res=format_l.pop() #另一个列表中一旦有值传入,则同样删除并获取该值,并保存。否则这里保存的值会累积的。
with open('db','a',encoding='utf-8') as f:
f.write('%s\n' % res)
if __name__ == '__main__':
t1=Thread(target=talk)
t2=Thread(target=format)
t3=Thread(target=save)
t1.start()
t2.start()
t3.start()
多线程udp服务器
import socketserver
class MyUDPHandler(socketserver.BaseRequestHandler):
def handler(self):
client_msg,s=self.request
s.sendto(client_msg.upper(),self.client_address)
if __name__ == '__main__':
s=socketserver.ThreadingUDPServer(('127.0.0.1',8080),MyUDPHandler)
s.serve_forever()
定时器
#定时器用法:Timer模块属于threading模块
#用时是先创建定时器对象,参数1是需要多少秒之后执行,参数2:延时启动的对象名
#对面名。start()方法执行
from threading import Timer
def hello():
print('哈哈哈')
t= Timer(3,hello)
t.start()
多线程实现单个客户端并发
from threading import Thread
import socket
import threading
def client(server_ip,port):
c=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
c.connect((server_ip,port))
count=0
while True:
c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(500):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()
线程queue
import queue
#线程queue有三种:queue.Queue、queue.LifoQueue、queue.PriorityQueue
q=queue.Queue(3) #先进先出--》队列
#用法同进程的Queue
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
q=queue.LifoQueue(3) # Last in first out 先进后出---》堆栈
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
q=queue.PriorityQueue(3)#优先级queue:元组形式的,数字越小优先级越高
q.put((2,'first'))
q.put((1,'second'))
q.put((3,'third'))
print(q.get())
print(q.get())
print(q.get())
gevent:遇到IO自动切换
# from gevent import monkey;monkey.patch_all()
# import gevent#在gevent模块前加补丁
# import time
#
# def eat(name):
# print('%s eat food first' % name)
# #gevent.sleep(20) #模拟IO阻塞:借助第三方模块gevent模块模拟IO操作,第三方模块不能识别其它的如sleep的IO等
# #如果需要gevent模块能够识别除了自己以为的阻塞操作,需要打一个补丁,如果不做这种补丁操作,程序还是顺序执行
# time.sleep(5)
# print('%s eat food second' % name)
#
# def play(name):
# print('%s play phone 1' % name)
# #gevent.sleep(10)
# time.sleep(3)
# print('%s play phone 2' % name)
#
# g1=gevent.spawn(eat,'egon')
# g2=gevent.spawn(play,'egon')
#
# g1.join()
# g2.join() #遇到IO阻塞就切换,谁先好,谁执行
# print('哈哈哈哈')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号