python之内置函数
python之内置函数
# locals: 当前作用域的所有的变量 **
# globals: 永远获取的是全局作用所有的变量等。 **
name = '太白' age = 25 def func1(): a1 = 'Ws' b1 = {'name': '二狗'} print(globals()) #全局 print(locals()) # 当前作用域的 func1()

name = '太白' age = 25 def func1(): a1 = 'Ws' b1 = {'name': '二狗'} # print(globals()) #全局 # print(locals()) # 当前作用域的 func1() print(globals()) #在外面打印都是一样的 print(locals()) #在外面打印都是一样的

# eval : 执行字符串中的代码并将结果返回给执行者。 慎用
# exec : 执行字符串中的代码 往往执行代码流。 慎用。
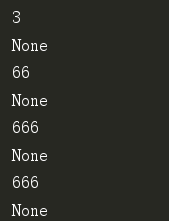
s1 = '1 + 2' print(eval(s1)) print(exec(s1)) s2 = '33 * 2' print(eval(s2)) print(exec(s2)) s3 = 'print(666)' print(eval(s3)) print(exec(s3))
# print()
print(1, 2, 3) print(1, 2, 3, sep='|') #在中间增加分隔符 print(1, 2, 3, end='!') #在结尾在增加字符
print(help(str)) #查看str的帮助
# callable 判断对象是否可调用 **
a1 = 'barry' def func1(): print(666) print(callable(a1)) #False print(callable(func1)) #True
# dir
print(dir('alex'))

# bin 十进制转换成二进制
print(bin(100))
# divmod() 分页会用到。返回 (商2,余数1) **
print(divmod(7, 3)) #(2, 1)
# sum:对可迭代对象进行求和计算(可设置初始值)。
print(sum([i for i in range(10)])) #求0-9的和 print(sum([i for i in range(10)], 100)) #设定初始大小为100,从100+0+1+2+..+9
# min:返回可迭代对象的最小值(可加key,key为函数名,通过函数的规则,返回最小值)。 ***
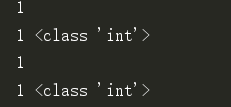
print(min(1,2,3,4,5)) #1 a = min(1,2,3,4,5) print(a,type(a)) print(min([1,2,3,4,5])) #1 b = min([1,2,3,4,5]) print(b,type(b))
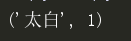
l1 = [('alex', 3), ('太白', 1), ('wS', 2)] def func(x): #把l1列表里面的每个元素传给了x #print(x) #打印的3个元祖 return x[1] #根据索引返回最小的元素('太白', 1) print(min(l1,key=func))
# max:返回可迭代对象的最大值(可加key,key为函数名,通过函数的规则,返回最大值)。 ***
# 与上面一致。 l1 = [('alex', 3), ('太白', 1), ('wS', 2)] def func(x): #把l1列表里面的每个元素传给了x # print(x) #打印的3个元祖 return x[1] #根据索引返回最小的元素('太白', 1) print(max(l1,key=func))

# reversed 返回一个新的翻转的迭代器 ***
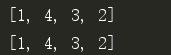
#1 l1 = [2, 3, 4, 1] l1.reverse() print(l1) # 1 4 3 2 #2 l1 = [2, 3, 4, 1] l2 = reversed(l1) print(list(l2)) # 1 4 3 2
# format()
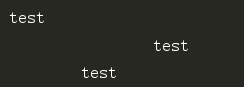
print(format('test', '<20')) print(format('test', '>20')) print(format('test', '^20'))
# bytes:用于不同编码之间的转化。 **
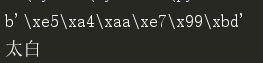
s1 = '太白' # unicode ---> utf-8 bytes b1 = s1.encode('utf-8') print(b1) # # utf-8 bytes ---> unicode s2 = b1.decode('utf-8') print(s2)
s1 = '太白' # unicode ---> utf-8 bytes b1 = bytes(s1, encoding='utf-8') print(b1)

# 通过输入字符找到 Unicode 对应的位置
print(ord('中')) print(ascii('a')) print(ascii('中'))

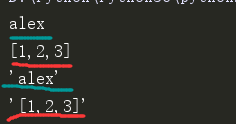
# repr:返回一个对象的string形式(原形毕露)。 ***
s1 = "alex" l3 = '[1,2,3]' print(s1) print(l3) print(repr(s1)) print(repr(l3))
# 格式化输入里面的%r 也能原形毕露 s1 = '我叫%s, 我是%r' % ('alex', 'sb') print(s1)

# sorted ***
l1 = [1, 2, 7, 6, 5, 4] l2 = sorted(l1) print(l2)

# 用key的方式排序
l1 = [('alex', 3), ('太白', 1), ('wS', 2), ('wS', 4)] def func(x): #把l1列表里面的每个元素传给了x return x[1] ##根据索引排序 new_l = sorted(l1,key=func,reverse=True) print(new_l)
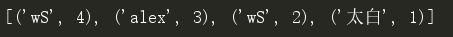
# enumerate 枚举***
# 先不用枚举的方式 l1 = ['太白%s' % i for i in range(10)] for index in range(len(l1)): print(index, l1[index])

# 先这个查看一下 l1 = ['太白%s' % i for i in range(10)] for i in enumerate(l1): print(i)

# 最终 l1 = ['太白%s' % i for i in range(10)] for index, i in enumerate(l1): print(index, i)

增加初始值
l1 = ['太白%s' % i for i in range(10)] for index, i in enumerate(l1, 10): #后面的10是设定的初始值 print(index, i)

# all:可迭代对象中,全是真的才是True **
# any:可迭代对象中,只要有一个是真的就是真的 **
print(all([1,2,True,100])) #True print(any(['', 0])) # False print(any(['1', 0])) #** True
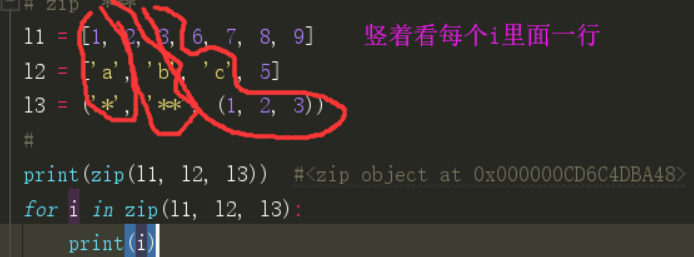
# zip ***
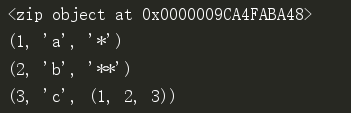
l1 = [1, 2, 3, 6, 7, 8, 9] l2 = ['a', 'b', 'c', 5] l3 = ('*', '**', (1, 2, 3)) # print(zip(l1, l2, l3)) #<zip object at 0x000000CD6C4DBA48> for i in zip(l1, l2, l3): print(i)
# filter 返回是迭代器 类比成列表推导式:筛选模式 ***
对已存在的列表进行筛选
l1 = [i for i in range(100) if i % 2 == 0] #使用列表推导式进行筛选 print(l1) #[0, 2, 4, 6, 8, 10, 12, 14....96,98]
将1-6里面的偶数留下来 l1 = [1, 2, 3, 4, 5, 6] def func(x): #x是1 2 3 4 5 6 return x % 2 == 0 obj1 = filter(func,l1) #注意格式,先函数名后列表 print(obj1) #<filter object at 0x0000001E36708278> #返回的是 print(list(obj1)) #[2, 4, 6]

# map: 返回一个迭代器 类比成列表推导式:循环模式 ***
# 他不仅可以操作列表,可迭代对象、迭代器都可以操作
l1 = [1, 2, 3, 4, 5, 6] def func(x): return x ** 2 print(list(map(func, l1)))

作者:wangkaiok —— 小菜鸟111
出处:http://www.cnblogs.com/wangkaiok/
本文版权归作者和博客园共有,但未经作者同意禁止转载,转载必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号