模块的研究
# import tbjx
# import tbjx
# import tbjx
# import tbjx
import tbjx
#
# print(tbjx.name)
# tbjx.read1()
# 模块首次引用,加载到内存,如果在引用此模块,直接从内存中读取。
# 执行文件:解释器运行的文件。
# 被引用文件:import.
# 模块引用发生了三件事:
'''
1, 他在内存中开辟了一个以tbix命名的空间。
2, 你模块中的所有内容都加载到内存。
2, 你要通过tbjx.的方式去引用模块中的对象。
'''
# 为模块起别名
# 1,将模块名较长的改成短的,便于操作 主要用途 # import tbjx as sm # # sm.read2() # 2,拓展代码 # import mysql1 # import oracle1 # sql = input('请输入').strip() # if sql == 'mysql': # import mysql1 as db # elif sql == 'oracle': # import oracle1 as db # db.sqlsentance()
# 导入多个模块
# import os # import time # import pickle
# from ... import ...
# import tbjx # tbjx.read1() # name = 'alex' # from tbjx import read1, name # 好处:方便使用 # 缺点:可能会与执行文件产生冲突。 # read1() # print(name) # print(name)
# 改名
# from tbjx import read1 as f1 # f1()
# from ... import *
# from ... import * 不建议使用,或者是在一定条件下使用 # from tbjx import * # 不建议全部引用 * # read1() # read2() # 在一定条件下用: 在模块中添加:__all__ = ['read1', 'read2'] # read1() # read2() # change()
# py文件的功能:
# 1,可以被当成模块使用(被调用)。
# 2,可以执行本文件使用。
# import tbjx # print(__name__) # 当成执行文件:__main__ # 当模块被引用:模块名
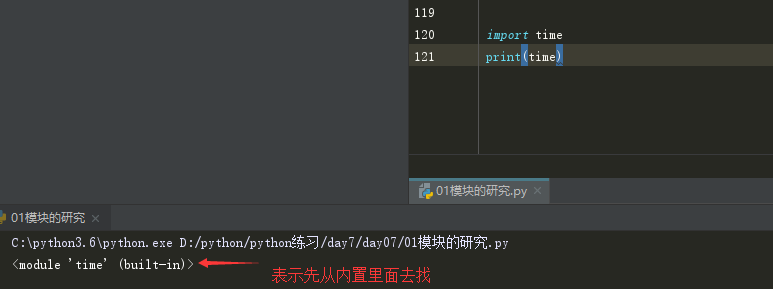
# 模块的引用顺序:
# 模块的引用顺序:先从内存 ---> 内置模块(os,time sys..) ---> sys.path 去找
# import sys
# print(sys.path)
# print(sys.modules) # python解释器运行时自动加载到内存的一些模块。、
在当前目录下创建了一个mk目录,里面有m1.py
# 找到m1文件的方式: # 方式一,将m1 路径 主动添加到sys.path # sys.path.append(r'D:\xxx\day07\mk') # import m1 # m1.func1() # 方式二: # from mk import m1 # m1.func1()


作者:wangkaiok —— 小菜鸟111
出处:http://www.cnblogs.com/wangkaiok/
本文版权归作者和博客园共有,但未经作者同意禁止转载,转载必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号