
Kubernetes 编写自定义 controller
原文链接:Kubernetes编写自定义controller
来自kubernetes官方github的一张图:
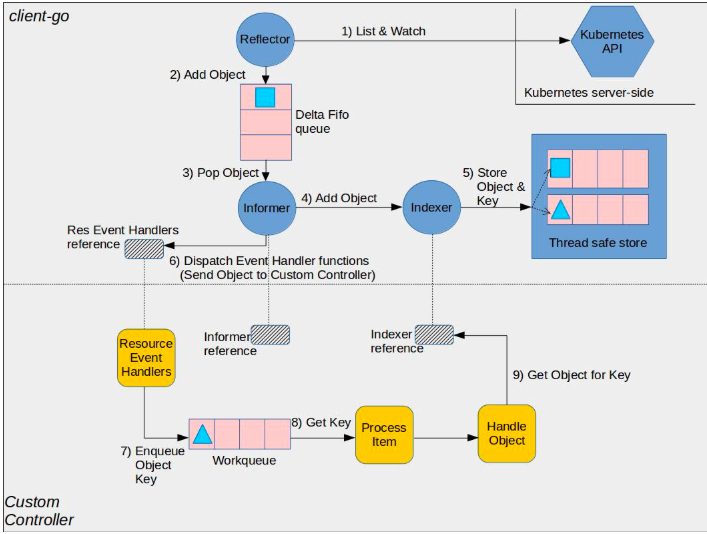
如图所示,图中的组件分为client-go和custom controller两部分:
-
client-go部分
- Reflector: 监视特定资源的k8s api, 把新监测的对象放入Delta Fifo队列,完成此操作的函数是ListAndWatch。
- Informer: 从Delta Fifo队列拿出对象,完成此操作的函数是processLoop。
- Indexer: 提供线程级别安全来存储对象和key。
-
custom-controller部分
- Informer reference: Informer对象引用
- Indexer reference: Indexer对象引用
- Resource Event Handlers: 被Informer调用的回调函数,这些函数的作用通常是获取对象的key,并把key放入Work queue,以进一步做处理。
- Work queue: 工作队列,用于将对象的交付与其处理分离,编写Resource event handler functions以提取传递的对象的key并将其添加到工作队列。
- Process Item: 用于处理Work queue中的对象,可以有一个或多个其他函数一起处理;这些函数通常使用Indexer reference或Listing wrapper来检索与该键对应的对象。
client-go官方代码例子
package main import ( "flag" "fmt" "time" "k8s.io/klog" "k8s.io/api/core/v1" meta_v1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/fields" "k8s.io/apimachinery/pkg/util/runtime" "k8s.io/apimachinery/pkg/util/wait" "k8s.io/client-go/kubernetes" "k8s.io/client-go/tools/cache" "k8s.io/client-go/tools/clientcmd" "k8s.io/client-go/util/workqueue" ) // 定义一个结构体Controller type Controller struct { indexer cache.Indexer queue workqueue.RateLimitingInterface informer cache.Controller } // 获取controller的函数 func NewController(queue workqueue.RateLimitingInterface, indexer cache.Indexer, informer cache.Controller) *Controller { return &Controller{ informer: informer, indexer: indexer, queue: queue, } } // 处理workqueue中的对象 func (c *Controller) processNextItem() bool { // Wait until there is a new item in the working queue key, quit := c.queue.Get() if quit { return false } // Tell the queue that we are done with processing this key. This unblocks the key for other workers // This allows safe parallel processing because two pods with the same key are never processed in // parallel. defer c.queue.Done(key) // Invoke the method containing the business logic err := c.syncToStdout(key.(string)) // Handle the error if something went wrong during the execution of the business logic c.handleErr(err, key) return true } // syncToStdout is the business logic of the controller. In this controller it simply prints // information about the pod to stdout. In case an error happened, it has to simply return the error. // The retry logic should not be part of the business logic. func (c *Controller) syncToStdout(key string) error { obj, exists, err := c.indexer.GetByKey(key) if err != nil { klog.Errorf("Fetching object with key %s from store failed with %v", key, err) return err } if !exists { // Below we will warm up our cache with a Pod, so that we will see a delete for one pod fmt.Printf("Pod %s does not exist anymore\n", key) } else { // Note that you also have to check the uid if you have a local controlled resource, which // is dependent on the actual instance, to detect that a Pod was recreated with the same name fmt.Printf("Sync/Add/Update for Pod %s\n", obj.(*v1.Pod).GetName()) } return nil } // handleErr checks if an error happened and makes sure we will retry later. func (c *Controller) handleErr(err error, key interface{}) { if err == nil { // Forget about the #AddRateLimited history of the key on every successful synchronization. // This ensures that future processing of updates for this key is not delayed because of // an outdated error history. c.queue.Forget(key) return } // This controller retries 5 times if something goes wrong. After that, it stops trying. if c.queue.NumRequeues(key) < 5 { klog.Infof("Error syncing pod %v: %v", key, err) // Re-enqueue the key rate limited. Based on the rate limiter on the // queue and the re-enqueue history, the key will be processed later again. c.queue.AddRateLimited(key) return } c.queue.Forget(key) // Report to an external entity that, even after several retries, we could not successfully process this key runtime.HandleError(err) klog.Infof("Dropping pod %q out of the queue: %v", key, err) } func (c *Controller) Run(threadiness int, stopCh chan struct{}) { defer runtime.HandleCrash() // Let the workers stop when we are done defer c.queue.ShutDown() klog.Info("Starting Pod controller") go c.informer.Run(stopCh) // Wait for all involved caches to be synced, before processing items from the queue is started if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) { runtime.HandleError(fmt.Errorf("Timed out waiting for caches to sync")) return } for i := 0; i < threadiness; i++ { go wait.Until(c.runWorker, time.Second, stopCh) } <-stopCh klog.Info("Stopping Pod controller") } func (c *Controller) runWorker() { for c.processNextItem() { } } func main() { var kubeconfig string var master string // 指定kubeconfig文件 flag.StringVar(&kubeconfig, "kubeconfig", "", "absolute path to the kubeconfig file") flag.StringVar(&master, "master", "", "master url") flag.Parse() // creates the connection config, err := clientcmd.BuildConfigFromFlags(master, kubeconfig) if err != nil { klog.Fatal(err) } // creates the clientset clientset, err := kubernetes.NewForConfig(config) if err != nil { klog.Fatal(err) } // create the pod watcher podListWatcher := cache.NewListWatchFromClient(clientset.CoreV1().RESTClient(), "pods", v1.NamespaceDefault, fields.Everything()) // create the workqueue queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter()) // Bind the workqueue to a cache with the help of an informer. This way we make sure that // whenever the cache is updated, the pod key is added to the workqueue. // Note that when we finally process the item from the workqueue, we might see a newer version // of the Pod than the version which was responsible for triggering the update. indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{ AddFunc: func(obj interface{}) { key, err := cache.MetaNamespaceKeyFunc(obj) if err == nil { queue.Add(key) } }, UpdateFunc: func(old interface{}, new interface{}) { key, err := cache.MetaNamespaceKeyFunc(new) if err == nil { queue.Add(key) } }, DeleteFunc: func(obj interface{}) { // IndexerInformer uses a delta queue, therefore for deletes we have to use this // key function. key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj) if err == nil { queue.Add(key) } }, }, cache.Indexers{}) controller := NewController(queue, indexer, informer) // We can now warm up the cache for initial synchronization. // Let's suppose that we knew about a pod "mypod" on our last run, therefore add it to the cache. // If this pod is not there anymore, the controller will be notified about the removal after the // cache has synchronized. indexer.Add(&v1.Pod{ ObjectMeta: meta_v1.ObjectMeta{ Name: "mypod", Namespace: v1.NamespaceDefault, }, }) // Now let's start the controller stop := make(chan struct{}) defer close(stop) go controller.Run(1, stop) // Wait forever select {} }
