Java中实现hash算法
Hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。根据散列值作为地址存放数据,这种转换是一种压缩映射,简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。查找关键字数据(如K)的时候,若结构中存在和关键字相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。我们称这个对应关系f为散列函数(Hash function),按这个事件建立的表为散列表。
综上所述,根据散列函数f(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
Hash冲突
对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称hash冲突。即:key1通过f(key1)得到散列地址去存储key1,同理,key2发现自己对应的散列地址已经被key1占据了。
解决办法(总共有四种):
1.开放寻址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 。
开放寻址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1). di=1,2,3,…,m-1,称线性探测再散列;
2). di=1^2,(-1)^2,2^2,(-2)^2,(3)^2,…,±(k)^2,(k<=m/2)称二次探测再散列;
3). di=伪随机数序列,称伪随机探测再散列。
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术(线性探测法、二次探测法(解决线性探测的堆积问题)、随机探测法(和二次探测原理一致,不一样的是:二次探测以定值跳跃,而随机探测的散列地址跳跃长度是不定值))在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止插入即可。
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。 我们用散列函数f(key) = key mod l2
当计算前S个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入:

计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。于是将37存入下标为2的位置:

2.再哈希
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数去计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3.链地址法(Java hashmap就是这么做的)
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,将所有关键字为同义词的结点链接在同一个单链表中,如:
设有 m = 5 , H(K) = K mod 5 ,关键字值序例 5 , 21 , 17 , 9 , 15 , 36 , 41 , 24 ,按外链地址法所建立的哈希表如下图所示: 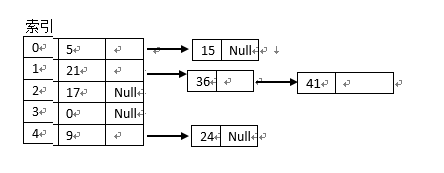
4.建立一个公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
代码实现:
Person类:
关于Java中的hashCode方法,详情请见:
https://www.cnblogs.com/dolphin0520/p/3681042.html
1 package my.hash; 2 3 /** 4 * Person类 5 * 重写hashCode方法和equals方法 6 * hashCode方法计算该对象的散列码 7 * Java中每个对象都有一个散列码 8 * @author ASUS 9 * 10 */ 11 12 public class Person { 13 private String name; 14 private int age; 15 16 //set和get方法 17 public String getName() { 18 return name; 19 } 20 public void setName(String name) { 21 this.name = name; 22 } 23 public int getAge() { 24 return age; 25 } 26 public void setAge(int age) { 27 this.age = age; 28 } 29 30 //构造器 31 public Person(String name,int age){ 32 super(); 33 this.age=age; 34 this.name=name; 35 } 36 37 //输出方法 38 public String toString() { 39 return "Person [name="+name+",age="+age+"]"; 40 } 41 42 //重写hashcode方法 43 public int hashCode() { 44 final int prime=31; 45 int result=1; 46 result=prime*result+age; 47 result=prime*result+((name==null)?0:name.hashCode()); 48 return result; 49 } 50 51 /*重写equals方法 52 * 重写该方法时必须重写hashCode方法,因为要确保一个对象映射到同一个存储地址 53 */ 54 public boolean equals(Object object) { 55 if(this==object){ 56 return true; 57 } 58 if(object==null){ 59 return false; 60 } 61 if(getClass()!=object.getClass()){ 62 return false; 63 } 64 Person other=(Person)object; 65 if(age!=other.age){ 66 if(other.name!=null){ 67 return false; 68 } 69 }else if (!name.equals(other.name)) { 70 return false; 71 } 72 return true; 73 } 74 }
关于该Java代码中的getClass方法,详情请见:
https://blog.csdn.net/mark_to_win/article/details/38757259
测试类:
1 package my.hash; 2 3 import java.util.HashSet; 4 5 public class Test { 6 public static void main(String[] args) { 7 //构造6个person对象 8 Person p1=new Person("sam", 10); 9 Person p2=new Person("amy", 13); 10 Person p3=new Person("lili", 22); 11 Person p4=new Person("daming", 34); 12 Person p5=new Person("a", 2); 13 Person p6=new Person("b", 2); 14 15 //输出a和b的hashcode值 16 System.out.println("a的hashcode值:"+p5.hashCode()+" b的hashcode值:"+p6.hashCode()); 17 18 //定义一个HashSet,将Person对象存储在该集合中 19 HashSet<Person> set=new HashSet<Person>(); 20 21 //将Person对象添加进HashSet集合中 22 set.add(p6); 23 set.add(p5); 24 set.add(p4); 25 set.add(p3); 26 set.add(p2); 27 set.add(p1); 28 29 //遍历HashSet,若p5和p6的hashCode一致,但是却添加进了集合set,说明hashset底层解决了hash冲突的问题。 30 for(Person person :set){ 31 System.out.println(person); 32 } 33 } 34 }
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号