
Lucene.Net 实现搜索功能
一、 Lucene.Net介绍:
1. Lucene.Net是由Java版本的Lucene(卢思银)移植过来的,所有的类、方法都几乎和Lucene一模一样,因此使用时参考Lucene 即可。Lucene.Net只是一个全文检索开发包,不是一个成型的搜索引擎,它的功能就是:把数据扔给Lucene.Net ,查询数据的时候从Lucene.Net 查询数据,可以看做是提供了全文检索功能的一个数据库。Lucene.Net不管文本数据怎么来的。用户可以基于Lucene.Net开发满足自己需求的搜索引擎。 Lucene.Net只能对文本信息进行检索。如果不是文本信息,要转换为文本信息,比如要检索Excel文件,就要用NPOI把Excel读取成字符串,然后把字符串扔给Lucene.Net。Lucene.Net会把扔给它的文本切词保存,加快检索速度。midomi.com。因为是保存的时候分词(切词),所以搜索速度非常快!

2. 分词介绍:分词分为三种,一元分词,二元分词,词库分词,主要用到的是词库分词
- 分词是核心的算法,搜索引擎内部保存的就是一个个的“词(Word)”。英文分词很简单,按照空格分隔就可以。中文则麻烦,把“北京,Hi欢迎你们大家” 拆成“北京 Hi 欢迎 你们 大家”。
- “the”,“,”,“和”,“啊”,“的”等对于搜索来说无意义的词一般都属于不参与分词的无意义单词(noise word)。
- Lucene.Net中不同的分词算法就是不同的类。所有分词算法类都从Analyzer类继承,不同的分词算法有不同的优缺点。
- (*)内置的StandardAnalyzer是将英文按照空格、标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词。代码见备注
- (*)二元分词算法,每两个汉字算一个单词,“欢迎你们大家”会分词为“欢迎 迎你 你们 们大 大家”,网上找到的一个二元分词算法CJKAnalyzer。面试的时候能说出不同的分词算法的差异。
- 基于词库的分词算法,基于一个词库进行分词,可以提高分词的成功率。有庖丁解牛、盘古分词等。效率低。
3. 分词使用:首先导入dll文件。log4net.dll与Lucene.NET.dll将dll文件放置在项目的Lib文件夹中

4. 插入一个知识点:把winform窗口程序执行结果该成控制台程序
右击项目文件,点击属性,点击输出类型

5. 一元分词实现代码:一元分词是Lucene.net自带的所以只需要引入dll文件便可
/// <summary> /// 一元分词 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void button1_Click(object sender, EventArgs e) { Analyzer analyzer = new StandardAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("", new StringReader("北京,Hi欢迎你们大家")); Lucene.Net.Analysis.Token token = null; while ((token = tokenStream.Next()) != null) { Console.WriteLine(token.TermText()); } }
6. 二元分词:二元分词需要导入一个类文件,因为该分词不是自带的。
类文件:


using System.Collections; using System.IO; using Lucene.Net.Analysis; namespace NSharp.SearchEngine.Lucene.Analysis.Cjk { /**/ /** * Filters CJKTokenizer with StopFilter. * * @author Che, Dong */ public class CJKAnalyzer : Analyzer { //~ Static fields/initializers --------------------------------------------- /**/ /** * An array containing some common English words that are not usually * useful for searching and some double-byte interpunctions. */ public static string[] STOP_WORDS = { "a", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "s", "such", "t", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with", "", "www" }; //~ Instance fields -------------------------------------------------------- /**/ /** * stop word list */ private Hashtable stopTable; //~ Constructors ----------------------------------------------------------- /**/ /** * Builds an analyzer which removes words in {@link #STOP_WORDS}. */ public CJKAnalyzer() { stopTable = StopFilter.MakeStopSet(STOP_WORDS); } /**/ /** * Builds an analyzer which removes words in the provided array. * * @param stopWords stop word array */ public CJKAnalyzer(string[] stopWords) { stopTable = StopFilter.MakeStopSet(stopWords); } //~ Methods ---------------------------------------------------------------- /**/ /** * get token stream from input * * @param fieldName lucene field name * @param reader input reader * @return TokenStream */ public override TokenStream TokenStream(string fieldName, TextReader reader) { TokenStream ts = new CJKTokenizer(reader); return new StopFilter(ts, stopTable); //return new StopFilter(new CJKTokenizer(reader), stopTable); } } }
二元分词实现代码:
/// <summary> /// 二元分词 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void button2_Click(object sender, EventArgs e) { Analyzer analyzer = new CJKAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("", new StringReader("北京,Hi欢迎你们大家")); Lucene.Net.Analysis.Token token = null; while ((token = tokenStream.Next()) != null) { Console.WriteLine(token.TermText()); } }
7. 盘古分词:是属于基于词库的分词,所以会有词库文件夹
需要导入盘古分词dll文件,同样放在lib文件夹下,然后导入点击选中dll文件

将dict文件夹放置在项目文件夹中,并且将文件夹中的文件全部选中,右击属性,设置总是复制最新。

运行结果:

8. 添加索引库,就是指盘古分词的词库:相关代码实现如下,但是该添加索引库只是考虑到单个用户,并没有考虑到高并发,下面会讲到如何实现如何处理该并发。
private void button4_Click(object sender, EventArgs e) { string indexPath = @"C:\lucenedir";//该路径,就是指将分词之后的索引词库放置的路径。注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下。 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());//指定索引文件(打开索引目录) FS指的是就是FileSystem bool isUpdate = IndexReader.IndexExists(directory);//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。 if (isUpdate) { //同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。 //如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决) if (IndexWriter.IsLocked(directory)) //如果加锁 { //解锁 IndexWriter.Unlock(directory); } } IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);//向索引库中写索引。这时在这里加锁。 for (int i = 1; i <= 10; i++) { string txt = File.ReadAllText(@"D:\text\0413班\OA\OA项目,搜索,Lucene.Net,盘古分词,Quartz.Net\资料\测试文件\" + i + ".txt", System.Text.Encoding.Default);//注意这个地方的编码 Document document = new Document();//表示一篇文档。 //Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存,表示是否进行盘古分词 document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询) //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。 干扰词的数量 document.Add(new Field("body", txt, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); writer.AddDocument(document); } writer.Close();//会自动解锁。 directory.Close();//不要忘了Close,否则索引结果搜不到 }
9. 实现搜索功能。
/// <summary> /// 搜索 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void button5_Click(object sender, EventArgs e) { string indexPath = @"C:\lucenedir"; //定位到索引的文件夹 string kw = "面向对象";//对用户输入的搜索条件进行拆分。 //创建一个打开文件夹 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); //创建一个读取文件夹 IndexReader reader = IndexReader.Open(directory, true); IndexSearcher searcher = new IndexSearcher(reader); //搜索条件 PhraseQuery query = new PhraseQuery(); //foreach (string word in kw.Split(' '))//先用空格,让用户去分词,空格分隔的就是词“计算机 专业” //{ // query.Add(new Term("body", word)); //} //query.Add(new Term("body","语言"));--可以添加查询条件,两者是add关系.顺序没有关系. // query.Add(new Term("body", "大学生")); query.Add(new Term("body", kw));//body中含有kw的文章 query.SetSlop(100);//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.(例如 “大学生”这个查询条件和"简历"这个查询条件之间如果间隔的词太多也就没有意义了。) //TopScoreDocCollector是盛放查询结果的容器 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true); searcher.Search(query, null, collector);//根据query查询条件进行查询,查询结果放入collector容器 ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;//得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容. //可以用来实现分页功能 this.listBox1.Items.Clear(); for (int i = 0; i < docs.Length; i++) { // //搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document. int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id) Document doc = searcher.Doc(docId);//找到文档id对应的文档详细信息 this.listBox1.Items.Add(doc.Get("number") + "\n");// 取出放进字段的值 this.listBox1.Items.Add(doc.Get("body") + "\n"); this.listBox1.Items.Add("-----------------------\n"); } }
二、 上方将的是相关Lucene.net的基础,现在将使用它完成第一个搜索的版本,在MVC项目中使用。
1. 引入相关dll文件:以下四个
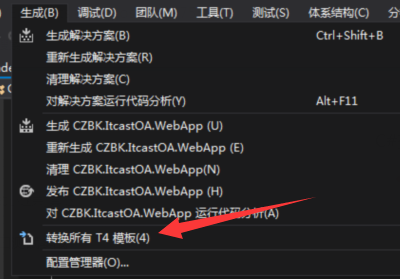
2 . 从数据库更新数据模型,添加books数据类,执行T4模板。
3. 新建一个SearchController 控制器,并且添加视图。此处需要注意几点:a. 提交方式改为get,b. 在展示搜索数据时,需要先进行if语句的嵌套,判断数据中是否有值,c. @MvcHtmlString.Create的用法,如果不加该方法,会对数据进行编码成文字,但是加上该功能。便会不进行字符转换。
@{ Layout = null; } @using Models <!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width" /> <title>搜索</title> <style type="text/css"> .search-text2{ display:block; width:528px; height:26px; line-height:26px; float:left; margin:3px 5px; border:1px solid gray; outline:none; font-family:'Microsoft Yahei'; font-size:14px;} .search-btn2{width:102px; height:32px; line-height:32px; cursor:pointer; border:0px; background-color:#d6000f;font-family:'Microsoft Yahei'; font-size:16px;color:#f3f3f3;} .search-list-con{width:640px; background-color:#fff; overflow:hidden; margin-top:0px; padding-bottom:15px; padding-top:5px;} .search-list{width:600px; overflow:hidden; margin:15px 20px 0px 20px;} .search-list dt{font-family:'Microsoft Yahei'; font-size:16px; line-height:20px; margin-bottom:7px; font-weight:normal;} .search-list dt a{color:#2981a9;} .search-list dt a em{ font-style:normal; color:#cc0000;} </style> </head> <body> <div> <form method="get" action="/Search/SearchContent"> <input type="text" name="txtSearch" class="search-text2" /> <input type="submit" value="搜一搜" name="btnSearch" class="search-btn2" /> @* <input type="submit" value="创建索引库" name="btnCreate" />*@ </form> <br /> <div class="search-list-con"> <dl class="search-list"> @*此处首先要判断list中是否有数据,才可以执行下方的代码,不然会出错,并且if语句属于代码段,所以其中foreach处不需要再使用多余@符号*@ @if(ViewData["list"]!=null) { foreach (ViewModelContent viewModel in (List<ViewModelContent>)ViewData["list"]) { <dt><a href="javascript:void(0)"> @viewModel.Title</a></dt> <dd>@MvcHtmlString.Create(viewModel.Content)</dd> } } </dl> </div> </div> </body> </html>
4. 引入dict文件夹,其中记录了一些重要的文件,并且设置dict文件夹中的文件的属性,设置为如果较新复制。
5. 实现搜索的功能的相关代码。
using CZBK.ItcastOA.Model; using CZBK.ItcastOA.WebApp.Models; using Lucene.Net.Analysis.PanGu; using Lucene.Net.Documents; using Lucene.Net.Index; using Lucene.Net.Search; using Lucene.Net.Store; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Web; using System.Web.Mvc; namespace CZBK.ItcastOA.WebApp.Controllers { public class SearchController : Controller { // // GET: /Search/ IBLL.IBooksService BooksService { get; set; } public ActionResult Index() { return View(); } /// <summary> /// 表单中有多个Submit,单击每个Submit都会提交表单,但是只会将用户所单击的表单元素的value值提交到服务端。 /// </summary> /// <returns></returns> public ActionResult SearchContent() { //如果等于查询 if (!string.IsNullOrEmpty(Request["btnSearch"])) { List<ViewModelContent>list=ShowSearchContent(); ViewData["list"] = list; //视图重载,表示返回到index对应的视图 return View("Index"); } //添加词库,但是此处的添加功能不再使用,因为被封装了 else { CreateSerachContent(); } return Content("ok"); } /// <summary> /// 实现搜索功能, /// </summary> /// <returns></returns> private List<ViewModelContent> ShowSearchContent() { string indexPath = @"C:\lucenedir"; //下面出需要把盘古分词类放置在common文件夹中,并且引用 List<string> list =Common.WebCommon.PanGuSplitWord(Request["txtSearch"]);//使用盘古分词对用户输入的搜索条件进行拆分,并且接受用户的输入信息。 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); IndexReader reader = IndexReader.Open(directory, true); IndexSearcher searcher = new IndexSearcher(reader); //搜索条件 PhraseQuery query = new PhraseQuery(); //因为前面的只是查询一个词,所以不需要for循环 foreach (string word in list)//先用空格,让用户去分词,空格分隔的就是词“计算机 专业” { query.Add(new Term("Content", word)); } //query.Add(new Term("body","语言"));--可以添加查询条件,两者是add关系.顺序没有关系. // query.Add(new Term("body", "大学生")); // query.Add(new Term("body", kw));//body中含有kw的文章 query.SetSlop(100);//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.(例如 “大学生”这个查询条件和"简历"这个查询条件之间如果间隔的词太多也就没有意义了。) //TopScoreDocCollector是盛放查询结果的容器 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true); searcher.Search(query, null, collector);//根据query查询条件进行查询,查询结果放入collector容器 ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;//得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容. //可以用来实现分页功能,此处需要在model中定义ViewModelContent类 List<ViewModelContent> viewModelList = new List<ViewModelContent>(); for (int i = 0; i < docs.Length; i++) { // //搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document. ViewModelContent viewModel = new ViewModelContent(); int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id) Document doc = searcher.Doc(docId);//找到文档id对应的文档详细信息 viewModel.Id=Convert.ToInt32(doc.Get("Id"));// 取出放进字段的值 viewModel.Title=doc.Get("Title"); viewModel.Content =Common.WebCommon.CreateHightLight(Request["txtSearch"],doc.Get("Content"));//将搜索的关键字高亮显示。 viewModelList.Add(viewModel); } return viewModelList; } /// <summary> /// 实现插入功能,该功能被封装在indexManager中,下面的注释,并且不使用 /// </summary> private void CreateSerachContent() { //string indexPath = @"C:\lucenedir";//注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下。//将路径写到配置文件中。 //FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());//指定索引文件(打开索引目录) FS指的是就是FileSystem //bool isUpdate = IndexReader.IndexExists(directory);//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。 //if (isUpdate) //{ // //同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。 // //如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决) // if (IndexWriter.IsLocked(directory)) // { // IndexWriter.Unlock(directory); // } //} //IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);//向索引库中写索引。这时在这里加锁。 //List<Books>list=BooksService.LoadEntities(b=>true).ToList(); //foreach (var bookModel in list) //{ // Document document = new Document();//表示一篇文档。 // //Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存 // document.Add(new Field("Id", bookModel.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); // //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询) // //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。 // document.Add(new Field("Title", bookModel.Title, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); // document.Add(new Field("Content", bookModel.ContentDescription, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); // writer.AddDocument(document); //} //writer.Close();//会自动解锁。 //directory.Close();//不要忘了C } } }
6. 实现往Lucene中插入的相关代码:该出主要考虑到插入和删除还有修改,但是修改不需要,因为此处的思路是先删除后添加,所以不需要添加修改方法。并且该处采用的是单例模式,就是指将该类设置成只能被单一的引用,不能被继承等等。
using CZBK.ItcastOA.Model.EnumType; using Lucene.Net.Analysis.PanGu; using Lucene.Net.Documents; using Lucene.Net.Index; using Lucene.Net.Store; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Threading; using System.Web; namespace Models { public sealed class IndexManager { //创建单例模式,首先第一步,定义一个静态示例的IndexManager类 private static readonly IndexManager indexManager = new IndexManager(); /// <summary> /// 第二步,提供一个私有的构造方法,指不能被继承, 只能在本类中使用 /// </summary> private IndexManager() { } //第三部,该方法是公开的,因为需要在类的外面调用类的实例 public static IndexManager GetInstance() { return indexManager; } public Queue<ViewModelContent> queue = new Queue<ViewModelContent>(); /// <summary> /// 向队列中添加数据 /// </summary> /// <param name="id"></param> /// <param name="title"></param> /// <param name="content"></param> public void AddQueue(int id, string title, string content) { ViewModelContent viewModel = new ViewModelContent(); viewModel.Id = id; viewModel.Title = title; viewModel.Content = content; viewModel.LuceneTypeEnum = LuceneTypeEnum.Add; queue.Enqueue(viewModel); } /// <summary> /// 要删除的数据 /// </summary> /// <param name="id"></param> public void DeleteQueue(int id) { ViewModelContent viewModel = new ViewModelContent(); viewModel.Id = id; viewModel.LuceneTypeEnum = LuceneTypeEnum.Delete; queue.Enqueue(viewModel); } /// <summary> /// 开始一个线程 /// </summary> public void StartThread() { Thread thread = new Thread(WriteIndexContent); thread.IsBackground = true; thread.Start(); } /// <summary> /// 检查队列中是否有数据,如果有数据获取。 /// </summary> private void WriteIndexContent() { while (true) { if (queue.Count > 0) { CreateIndexContent(); } else { Thread.Sleep(3000); } } } private void CreateIndexContent() { string indexPath = @"C:\lucenedir";//注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下。//将路径写到配置文件中。 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());//指定索引文件(打开索引目录) FS指的是就是FileSystem bool isUpdate = IndexReader.IndexExists(directory);//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。 if (isUpdate) { //同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。 //如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决) if (IndexWriter.IsLocked(directory)) { IndexWriter.Unlock(directory); } } IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);//向索引库中写索引。这时在这里加锁。 //如果队列中有数据,获取队列中的数据写到Lucene.Net中。 while(queue.Count>0) { ViewModelContent viewModel=queue.Dequeue(); writer.DeleteDocuments(new Term("Id",viewModel.Id.ToString()));//删除 if (viewModel.LuceneTypeEnum == LuceneTypeEnum.Delete) { continue; } Document document = new Document();//表示一篇文档。 //Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存 document.Add(new Field("Id", viewModel.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询) //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。 document.Add(new Field("Title", viewModel.Title, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); document.Add(new Field("Content", viewModel.Content, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); writer.AddDocument(document); } writer.Close();//会自动解锁。 directory.Close();//不要忘了C } } }
7. 需要在common中添加一个盘古分词的方法还有一个设置高亮显示的方法,高亮显示就是指将某一些数据显示成执行的样式。或者红色,或者字体加粗,等等...备注: 设置高亮显示需要导入pangu.highlight.dll 文件,还是和以往的一样,放置在lib文件夹中,然后引用。
using Lucene.Net.Analysis; using Lucene.Net.Analysis.PanGu; using PanGu; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; namespace Common { public class WebCommon {
//盘古分词,此处返回的是一个list集合 public static List<string> PanGuSplitWord(string msg) { Analyzer analyzer = new PanGuAnalyzer(); TokenStream tokenStream = analyzer.TokenStream("", new StringReader(msg)); Lucene.Net.Analysis.Token token = null; List<string> list = new List<string>(); while ((token = tokenStream.Next()) != null) { list.Add(token.TermText()); } return list; } // /创建HTMLFormatter,参数为高亮单词的前后缀 public static string CreateHightLight(string keywords, string Content) { PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"red\">", "</font>"); //创建Highlighter ,输入HTMLFormatter 和盘古分词对象Semgent PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment()); //设置每个摘要段的字符数 highlighter.FragmentSize = 150; //获取最匹配的摘要段 return highlighter.GetBestFragment(keywords, Content); } } }
8. 上面还需要添加在MVC的model中添加一个数据类,类名ViewModelContent
using CZBK.ItcastOA.Model.EnumType; using System; using System.Collections.Generic; using System.Linq; using System.Web; namespace Models { public class ViewModelContent { public int Id { get; set; } //文章标题 public string Title { get; set; } //文章内容 public string Content { get; set; } //枚举类型的删除还是添加 public LuceneTypeEnum LuceneTypeEnum { get; set; } } }
9. 在model中类文件中添加一个枚举类型的LuceneTypeEnum类。
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace EnumType { public enum LuceneTypeEnum { /// <summary> /// 添加 /// </summary> Add, /// <summary> /// 删除 /// </summary> Delete } }
10. 在Global.asax文件的Application_Start()方法中添加一句如下代码。表示调用该实例,并且启动其中的线程。
IndexManager.GetInstance().StartThread();//开始线程扫描LuceneNet对应的数据队列。
11. 使用插入和删除的方法与思路。先插入到数据库中,并且返回主键ID,再插入到Lucene.net文件中,删除,直接调用删除的方法,修改也是调用添加的方法。
public ActionResult TestCreate() { Model.Books model = new Model.Books(); model.AurhorDescription = "jlkfdjf"; model.Author = "asfasd"; model.CategoryId = 1; model.Clicks = 1; model.ContentDescription = "Ajax高级编程"; model.EditorComment = "adfsadfsadf"; model.ISBN = "111111111111111111"; model.PublishDate = DateTime.Now; model.PublisherId = 72; model.Title = "Ajax"; model.TOC = "aaaaaaaaaaaaaaaa"; model.UnitPrice = 22.3m; model.WordsCount = 1234; //1.将数据先存储到数据库中。并且获取刚插入的数据的主键ID值。插入到数据库中代码省略掉 //第二步才是插入到luncene.net的文件中。 IndexManager.GetInstance().AddQueue(9999, model.Title, model.ContentDescription);//添加一个刚刚插入的主键ID的值,标题,还有内容,并且向队列中添加该数据 return Content("ok"); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号