
【SqlServer系列】集合运算
1 概述
已发布【SqlServer系列】文章如下:
- 【SqlServer系列】SQLSERVER安装教程
- 【SqlServer系列】数据库三大范式
- 【SqlServer系列】表单查询
- 【SqlServer系列】表连接
- 【SqlServer系列】子查询
- 【SqlServer系列】远程访问
本篇文章接着写【SqlServer系列】集合运算,主要内容为:1、并集(UNION)运算、交集(INTERSECT)运算、差集(EXCEPT)运算 2、集合运算优先级 3、避开不支持的逻辑查询处理
1.2 关于三种运算简要概述

1.3 本章测试样表和SQL
业务场景
有两张表,分别为员工表(员工ID,员工姓名,职位,学位,籍贯,电话)和销售表(销售ID,员工ID,员工姓名,职位,学位,销售额)

(1)创建集合DB:WJM_CollectDemo
1 IF DB_ID('WJM_CollectDemo') IS NOT NULL
2 DROP DATABASE WJM_CollectDemo
3 GO
4 CREATE DATABASE WJM_CollectDemo
(2)创建员工表并初始化
1 USE WJM_CollecDemo
2
3 --CREATE TABLE(Employees) AND INITIAL
4 CREATE TABLE Employees
5 (
6 empID INT IDENTITY(1,1) PRIMARY KEY NOT NULL,
7 empName VARCHAR(50),
8 position VARCHAR(50),
9 degree VARCHAR(50),
10 jiGuan VARCHAR(50),
11 tel VARCHAR(50),
12 )
13
14 INSERT INTO Employees VALUES
15 ('张三','销售经理','本科','上海','021-298989'),
16 ('李四','销售','本科','北京','010-298181'),
17 ('李明','销售','','深圳','0755-698988'),
18 ('王华','销售','本科','杭州','0571-593132')
执行查询语句
1 SELECT *
2 FROM Employees
查询结果为:
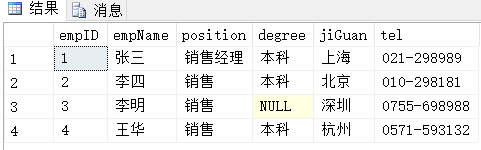
(3)创建销售表并初始化
1 USE WJM_CollectDemo
2
3 --CREATE TABLE(Sales) AND INITIAL
4 CREATE TABLE Sales
5 (
6 salesID INT IDENTITY(1,1) PRIMARY KEY NOT NULL,
7 empID INT,
8 empName VARCHAR(50),
9 position VARCHAR(50),
10 degree VARCHAR(50),
11 SaleCount VARCHAR(100)
12 )
13
14 INSERT INTO Sales VALUES
15 ('1','张三','销售经理','本科','5000w'),
16 ('3','李明','销售','','100w'),
17 ('4','王华','销售','本科','1500w'),
18 ('','张涛','外聘销售','硕士','2000w')
执行查询语句
1 SELECT *
2 FROM Sales
查询结果
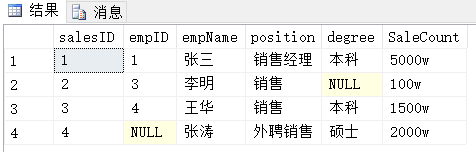
2 三种基本的集合运算
2.1 并集运算(UNION)
(1)UNION ALL(不删除重复行)
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION ALL
4 SELECT empID,empName,position,degree
5 FROM Sales
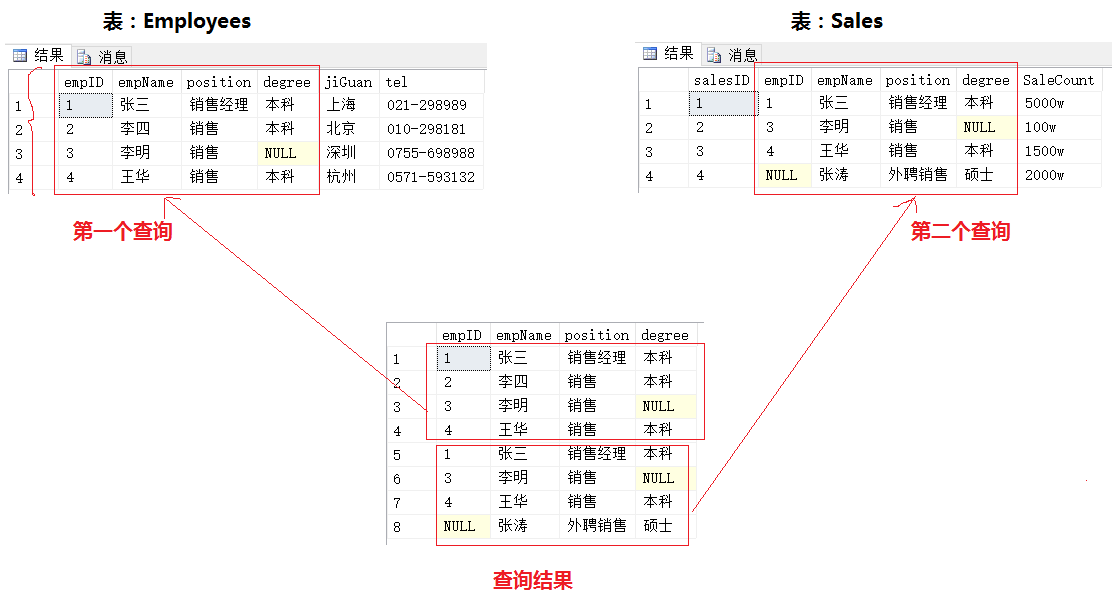
查询结果:
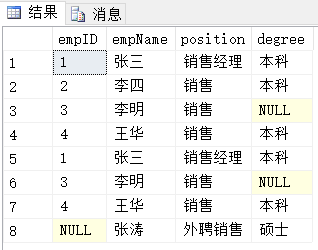
结果分析:
生成结果为:第一个查询结果集与第二个查询结果集简单的组合,保留重复行。
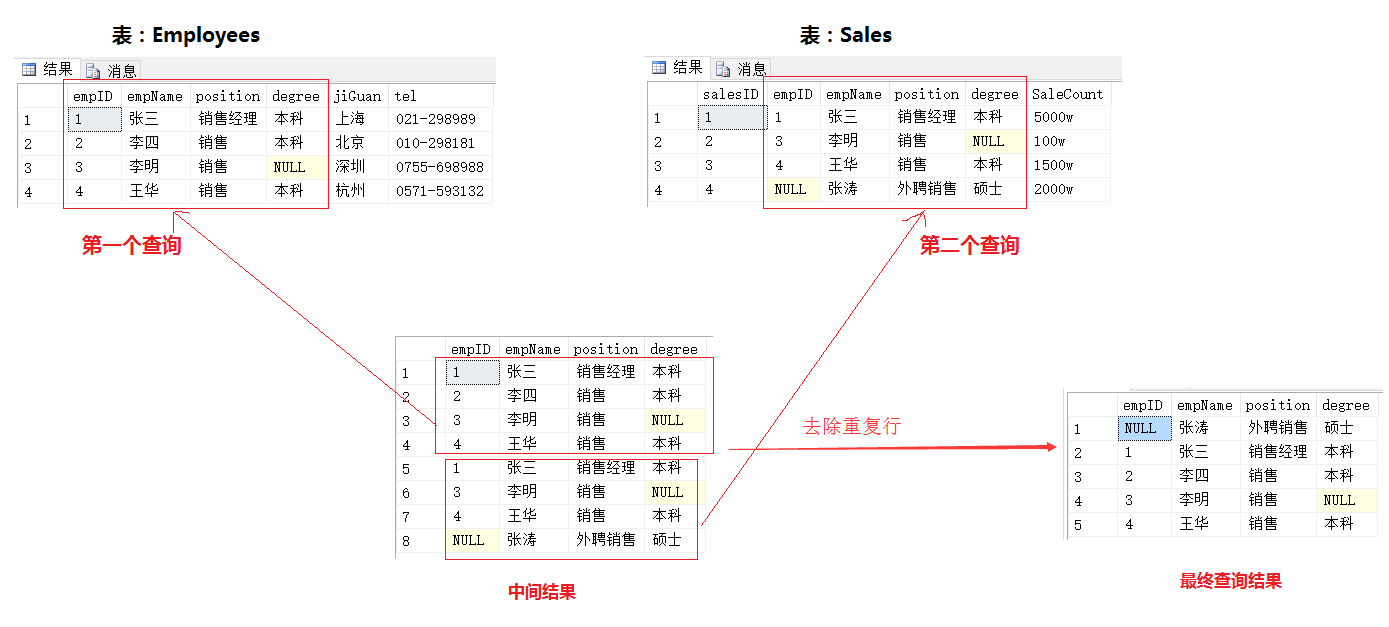
(2)UNION(隐式DINSTINCT,删除重复行)
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION
4 SELECT empID,empName,position,degree
5 FROM Sales
查询结果:
结果分析:
UNION(隐式DISTINCT)相当与把UNION ALL当作中间结果,然后在其基础上通过DISTINCT过滤掉重复行;
(3)小结
a.并集为两个查询结果集的简单组合;
b.多集指集合中有重复的行,单集指集合中没有重复行; c.UNION ALL一般为多集,UNION(UNION DISTINCT)一般为集合; d.具有对称性,即无论哪个查询在前面,查询结果都是一样的;
e.进行null值比较时,认为是相等的,而内连接,EXISTS谓词在进行null比较结果为UNKNOWN;
2.2 交集(INTERSECT)
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 INTERSECT
4 SELECT empID,empName,position,degree
5 FROM Sales
查询结果:

结果分析:
交集为第一个查询结果集和第二个查询结果集公有的部分
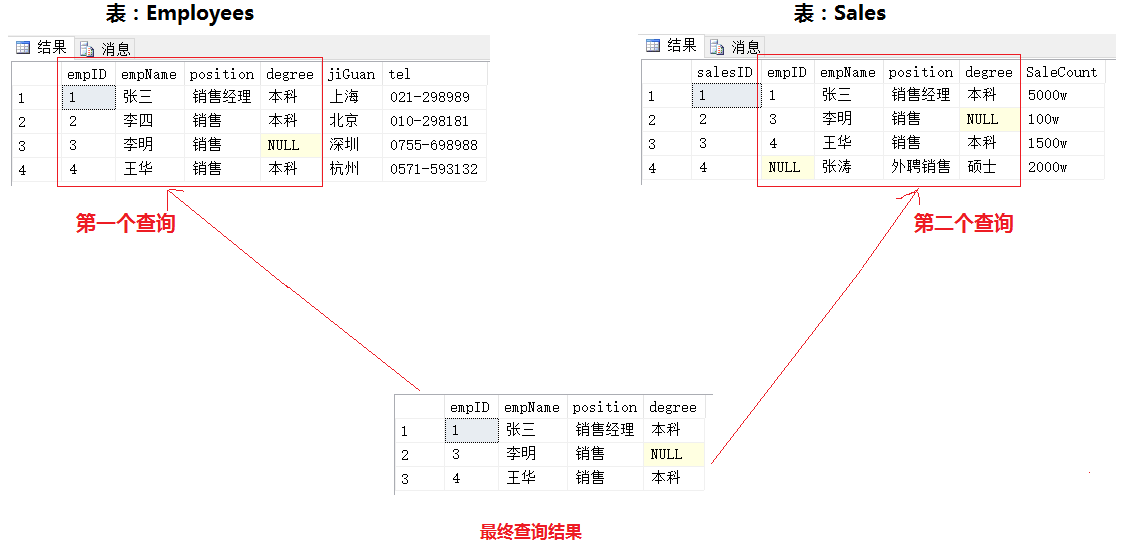
小结
a.交集为第一个查询结果集和第二个查询结果集公有的部分;
b.进行null值比较时,认为是相等的,而内连接,EXISTS谓词在进行null比较结果为UNKNOWN; c.有两种INTERSECT和INTETSECT ALL(SQL2008版本没实现); d.具有对称性,即无论哪个查询在前面,查询结果都是一样的;
2.3 差集
Code:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 EXCEPT
4 SELECT empID,empName,position,degree
5 FROM Sales
查询结果:
![]()
结果分析:
差集运算对两个输入查询的结果集进行操作,返回出现在第一个结果集,但不出现在第二个结果集中的所有行
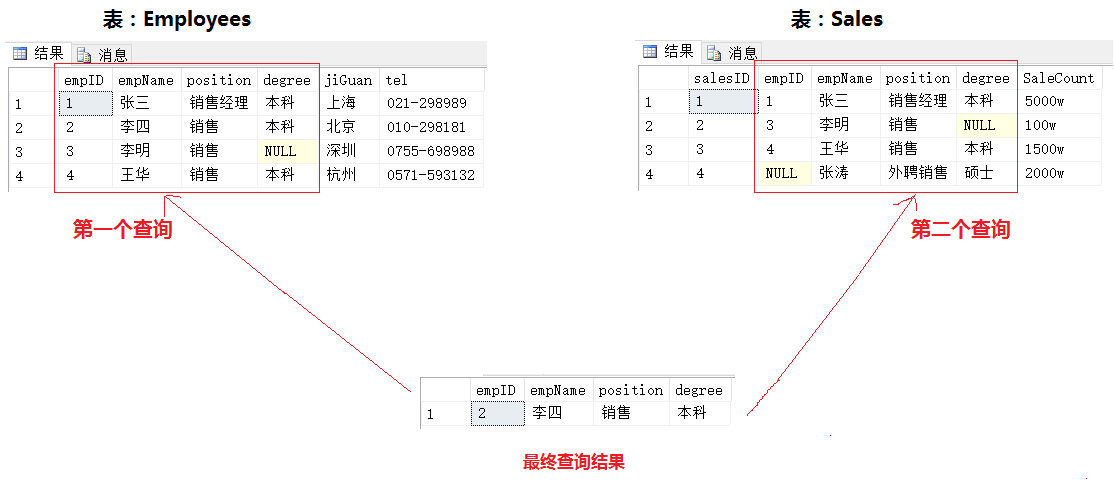
小结:
a. EXCEPT运算对两个输入查询的结果集进行操作,返回出现在第一个结果集,但不出现在第二个结果集中的所有行; b.不具有对称性;
c.有两种EXCEPT和EXCEPT ALL(SQL2008版本没实现);
3 集合运算的优先级
SQL定义了集合运算之间的优先级。INTERSECT优先级比UNION和EXCEPT高,UNION和EXCEPT优先级一样。执行顺序为从左到右执行。
CODE:
1 SELECT empID,empName,position,degree
2 FROM Employees
3 UNION
4 SELECT empID,empName,position,degree
5 FROM Sales
6 INTERSECT
7 SELECT empID,empName,position,degree
8 FROM Employees
查询结果:
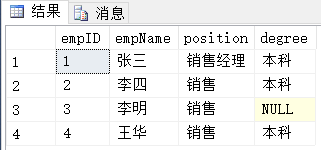
结果分析:

小结:
a.INTERSECT优先级最高,UNION和EXCEPT优先级一样;
b.按照从左=>右的执行顺序执行;
4 避开不支持的查询处理
略(高级部分讲解)
5 参考文献
【01】Microsoft SqlServer 2008技术内幕:T-SQL 语言基础
【02】Microsoft SqlServer 2008技术内幕:T-SQL 查询
6 版权
- 感谢您的阅读,若有不足之处,欢迎指教,共同学习、共同进步。
- 博主网址:http://www.cnblogs.com/wangjiming/。
- 极少部分文章利用读书、参考、引用、抄袭、复制和粘贴等多种方式整合而成的,大部分为原创。
- 如您喜欢,麻烦推荐一下;如您有新想法,欢迎提出,邮箱:2016177728@qq.com。
- 可以转载该博客,但必须著名博客来源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号