
浅析关于java的一些基础问题(上篇)
要想让一个问题变难,最基本有两种方式,即极度细化和高度抽象。对于任何语言的研究,良好的基础至关重要,本篇文章,将从极度细化的角度
来解析一些java中的基础问题,这些问题也是大部分编程人员的软肋或易混淆点。
一 关于String问题
1.String是基本类型(值类型)还是引用类型?
(1)String是引用类型。通过查看jdk,String是一个类,既然是一个类,那么就是引用类型;
(2)基本类型包括:int,float,boolean,byte,凡是通过new关键字的,都属于引用类型,如
一般情况,引用类型是通过new关键字,如ClassA a=new ClassA() ,a就是引用类型,引用类型存储在内存堆中,而值类型存储在内存栈中。
堆和栈的区别是,栈存取速度快,固定存储长度;而堆长度根据运行时实际情况分配,速度慢。
2.String str1=“Alan”与String str2=new String("Alan")区别?
回答该问题,就涉及到java虚拟机常量池问题
(1)在常量池中,不存在两个相同的变量。
String str1="Alan_beijing"; String str2="Alan_beijing"; System.out.println(str1==str2);//true System.out.println(str1.equals(str2));//true
说明str1和str2指向同一个对象。
(2)每new一个对象,就新增加一个对象,不管常量池中是否存在相同的变量
String str1="Alan_beijing"; String str2=new String("Alan_beijing"); System.out.println(str1==str2);//false System.out.println(str1.equals(str2));//true
3.equals和==区别?
(1)核心区别:equals比较对象值是否相等,==比较是否是同一个对象。
String str1="Alan_beijing"; String str2=new String("Alan_beijing"); System.out.println(str1==str2);//false System.out.println(str1.equals(str2));//true
4.为什么StringBuilder相对于String字符串拼接比较快?
知道了1-3答案,这个问题就非常容易解决了,因为每拼接一个字符串,就要new一个对象,占用内存堆,而StringBuilder不需要,故比较快。
String str="a"+"b"+"c"+"d";//要额外增加3个变量,“ab”,"abc",'abcd'
5.考虑如下问题答案
String str0="Alan"; String str1="Alan"; String str2="A"+"lan"; String str3=new String("Alan1"); String str4="A"+new String("lan"); String str5=str3.intern(); System.out.println(str0==str1); System.out.println(str1==str2); System.out.println(str1==str3); System.out.println(str3==str4); System.out.println(str1==str5);
Tip:如下为String.equals()方法jdk源码
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
源码很清楚,有三个逻辑
(1)自身与自身比较,则返回true;
(2)当与其他对象比较,比较的是字符串序列,字符序列相同,返回true,否则返回false;
(3)当不满足(1)(2),则直接返回false
二 关于集合问题
1.HashMap,TreeMap,HashSet和HashTable比较
(1)实现接口不一样。HashMap和HashTable实现Map接口,而HashSet实现Set接口
(2)线程安全性不一样。HashMap线程不安全(异步锁),HashTable线程安全(同步锁),HashSet线程不安全,因为它的底层
是由HashMap不重复key实现的。
(3)性能从高到底
HashMap>HashSet>HashTable
(4)K,V是否为null
HashMap的K,V都可以存放null;
HashTable的K,V不能存放null;
HashSet只能V存放nll,K不能存放null
(5)存储内容差异
HashMap<k,v>和HashTable<k,v>存储k,v,而HashSet<E>存储对象
(6)HashMap和TreeMap区别
TreeMap保存对象排列次序,HashMap不须保存对象排列次序
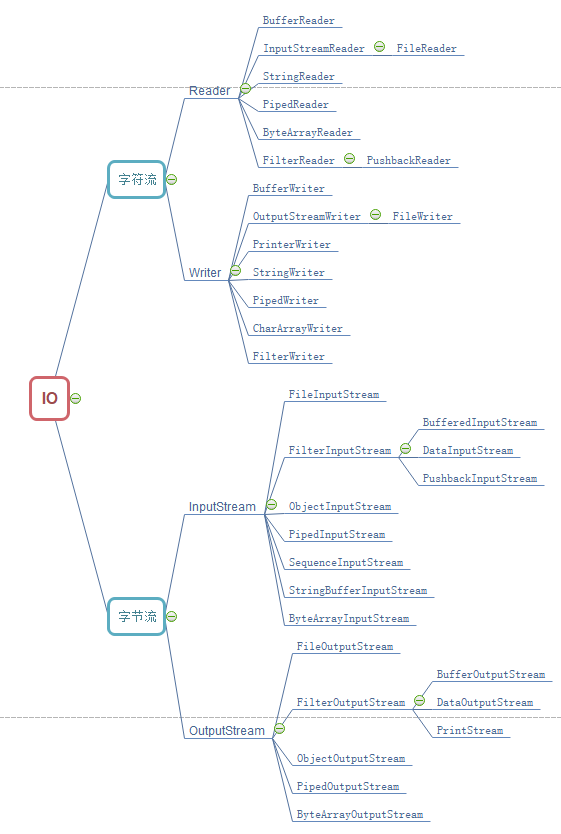
三 关于IO种类划分问题
IO从种类上,一般划分为字符流和字节流两大类,其中,字符流是以Reader或Writer结尾的,如InputStreamReader,
OutputStreamWriter;而字节流是以Stream结尾的,如InputStream,OutputStream。他们的继承关系如下:
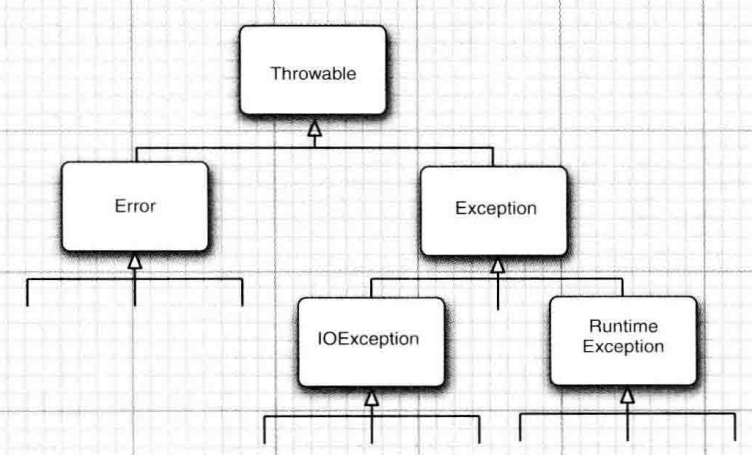
四 关于异常问题
(1)所有的异常类继承类Throwable
(2)异常从种类上来划分,分为非受查异常(派生于所有Error或RuntimeException)和受查异常
(3)自定义异常类,只需继承Exception类或Exception下的任何子类即可
(4)何为异常传递?指异常传递给调用的子类,而不在自己内部实现异常,通过throws向调用的类传递异常。
五 值传递和引用传递
值传递传递的是值,引用传递传递的是地址(也可叫做指针)
下面的的代码,最终输出结果为15 0 20,请考虑为什么?
package demo.test; import org.junit.Test; public class MGenalTest { @Test public void test(){ first(); } public void first(){ int i=5; Value v=new Value(); v.i=25; second(v,i); System.out.println(v.i); } public void second(Value v,int i){ i=0; v.i=20; Value val=new Value(); v=val; System.out.println(v.i+" "+i); } } class Value{ public int i=15; }
六 反射
Java中的反射是一种强大的工具,它能够创建灵活的代码,这些代码可以在运行时装配,无须再组件之间进行链接,反射允许
在编写与执行时,使程序代码能够接入装载到JVM中的类的内部信息,而不是源代码中选定的类协作的代码。
七 序列化
关于序列化,只需实现接口Serializable即可
public interface Serializable { }
八 JVM
关于JVM,重点了解JVM垃圾回收机制,一般情况地,对象在垃圾回收前,会先调用方法finalize(),然后再调用gc()方法。
关于垃圾回收机制问题,有很多回收算法,不同的算法,实现不同的机制。
九 算法
关于算法,递归算法考察比较多,如斐波拉列数列 1,1,2,3,5,8,。。。。
十 版权区
- 转载博客,必须注明博客出处
- 博主网址:http://www.cnblogs.com/wangjiming/
- 如您有新想法,欢迎提出,邮箱:2098469527@qq.com
- 专业.NET之家技术QQ群:490539956
- 专业化Java之家QQ群:924412846
- 有问必答QQ群:2098469527
- 一对一技术辅导QQ:2098469527

 浙公网安备 33010602011771号
浙公网安备 33010602011771号