红楼梦作者解析
红楼梦作者解析
https://github.com/Adnios/RedDream.git程序代码放在了GitHub上了~~~~~~~~~~~~~~~~~~~~~~~
摘要
本文通过对120章回中主要人物名称出现的频率、虚词的词频、词与词之间的相关性以及前后的写作风格的比较来进行红楼梦作者异同的分析。
针对问题一,我们运用了Python工具分别统计主要人物分别在前八十和后四十出现的频数。我们得出前八十回与后四十回人物的出现频率与情节发展有关,并不能从中看出作者的差异。
针对问题二,我们先对前八十和后四十中出现的虚词和标点符号进行检索,再通过kNN算法对其进行分析,可以明显看出前八十回与后四十回的差异。
针对问题三,我们基于同一句话中两个人物出现的次数来提取人物关系,即若一句话中两个人物出现,则加两个节点name1-name2,weight=1,若以后在其他语句中再出现,则weight+1,以此类推,直到找到所有人物关系节点。分别建立前八十和后四十的人物节点图。
针对问题四,我们在语义用法方面对前八十章与后四十章的“这么”和“那么”进行了分析,并由此得出了其中的差异。
关键词:Python、主成分分析算法、降维、kNN算法、Gephi
问题重述
文本分析是指对文本的信息及其特征项的选取,是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化来表示文本信息。文本(text),与讯息(message)的意义大致相同,指的是由一定的符号或符码组成的信息结构体,这种结构体可采用不同的表现形态,如语言的、文字的、影像的等等。文本是由特定的人制作的,文本的语义不可避免地会反映人的特定立场、观点、价值和利益。因此,由文本内容分析,可以推断文本提供者的意图和目的。
作为中国古典四大名著的《红楼梦》,其影响深远,家喻户晓。历来红学家们都致力于研究《红楼梦》。本文基于Python语言对《红楼梦》中的语言进行一系列的处理,进而从中寻找一种能够推断《红楼梦》作者异同的方法。
判断后四十回是否曹雪芹本人所写是一个典型的文本分类(text category)问题。我们把每一回当成一个独立文本,对全书的一百二十回文本进行分类,若确实能分成两类,那就能说明问题了。
目前有关文本表示的研究主要集中于文本表示模型的选择和特征词选择算法的选取上。用于表示文本的基本单位通常称为文本的特征或特征项。特征项必须具备一定的特性:1)特征项要能够确实标识文本内容;2)特征项具有将目标文本与其他文本相区分的能力;3)特征项的个数不能太多;4)特征项分离要比较容易实现。在中文文本中可以采用字、词或短语作为表示文本的特征项。相比较而言,词比字具有更强的表达能力,而词和短语相比,词的切分难度比短语的切分难度小得多。因此,目前大多数中文文本分类系统都采用词作为特征项,称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算 。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大,从而导致计算量太大,在这样的情况下,要完成文本分类几乎是不可能的。特征抽取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。文本特征选择对文本内容的过滤和分类、聚类处理、自动摘要以及用户兴趣模式发现、知识发现等有关方面的研究都有非常重要的影响。通常根据某个特征评估函数计算各个特征的评分值,然后按评分值对这些特征进行排序,选取若干个评分值最高的作为特征词,这就是特征选择(Feature Selection)。
因此,我们通过前八十回和后四十回分别建立数学模型,分别从主要人物出现的频率、虚词的词频、词与词之间的相关性以及前后的艺术性来进行比较。
问题分析
本问题主要是通过不同的文本分析角度,建立数学模型,实现对文本的识别,来推断文本提供者的表述方式,意图和目的。
对于问题一,我们通过Python工具分别统计主要人物分别在前八十回和后四十回出现的频数。我们得出前八十回与后四十回作者存在的差异。
针对问题二,我们通过分析前八十和后四十中出现的虚词和标点符号,我们选择了
针对问题三,我们基于同一句话中两个人物出现的次数来提取人物关系,即一句话中两个人物出现,则加两个节点name1-name2,weight=1,若以后在其他语句中再出现,则weight+1,以此类推,直到找到所有人物关系节点。分别建立前八十和后四十的人物节点图。
基本假设
1、虚词的使用频率的不同足以充分区分作者的写作风格;
2、对于全文出现频率很低的人物名可以忽略,不会对结果产生影响;
3、忽略同名不同义的词对研究结果的影响。
问题一的求解
Python与文本挖掘
说起科学计算,首先会被提到的可能是MATLAB。然而除了MATLAB中一些专业性很强的工具箱还无法被替代之外,MATLAB的大部分常用功能都可以在Python世界中找到相应的扩展库。和MATLAB相比,用Python做科学计算有如下优点:1、与MATLAB相比,Python是一门更易学、更严谨的程序设计语言。它能让用户编写出更易读、易维护的代码。2、MATLAB主要专注于工程和科学计算。然而在计算领域,我们经常会需要进行文件管理、界面设计、网络通信等工作。由于Python有着丰富的扩展库,所以可以轻易完成各种高级任务,开发者可以用Python实现完整应用程序所需的各种功能。
文本挖掘是从大量文本中抽取出有价值的内容,并利用这些内容创造出价值,实现变现的过程,目的是把文本信息转化为人类可利用的工具。Python中有许多强大的库,可以用于文本挖掘,所以我们采用Python对《红楼梦》进行文本挖掘。
对于问题一,我们采用了Python的jieba库,jieba库是Python中的中文分词组件。其具有三种模式。精确模式,可以将句子最精确地分开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
为了更好地比较《红楼梦》前八十回和后四十回的差异并保证每个样品数据量的相等,我们通过层次划分,将前八十回平均分为两层,最后得到三个样本(前四十回,中四十回,后四十回),再通过Python对其进行文本挖掘。
《红楼梦》作为四大名著之一,其对于生活的描述十分细腻,人物更是纷繁复杂,我们需要对人物的出现次数进行统计,由于中文文章的分析需要用到分词手段才能进行词频统计,所以这里我们用到第三方库 jieba对其进行分析。初步我们将所有可能的情况都进行记录,其统计结果如图所示:

图1 初始统计结果
这里只截取了部分数据,从图中不难看出有很多非人名的词如:“寿星”、“小老婆”、“雪浪笺”、“秋霜”等混杂在其中,显然这属于无效信息,应将其过滤。所以我们将代码进行了修改,只统计出现频率超过一百次的人名,以使其能够将非人名信息筛选掉。
在增加条件后我们所检索出的数据与之前相比的确减少了很多,将检索出的数据导入Excel中并针对每个数据的出现次数进行降序排列可以得出如下图所示的数据表格,并对表格中的数据转化为饼状图及气泡图以观察其差异。
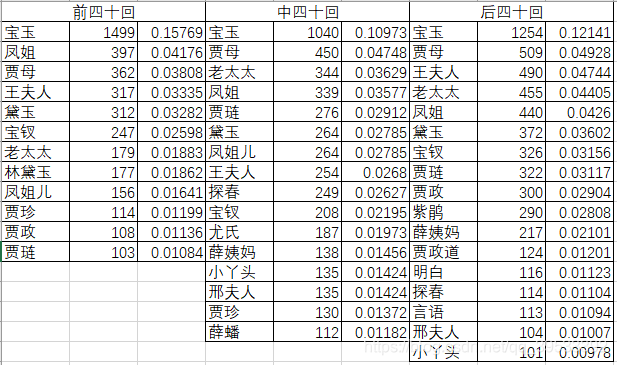
图2 Excel数据表格
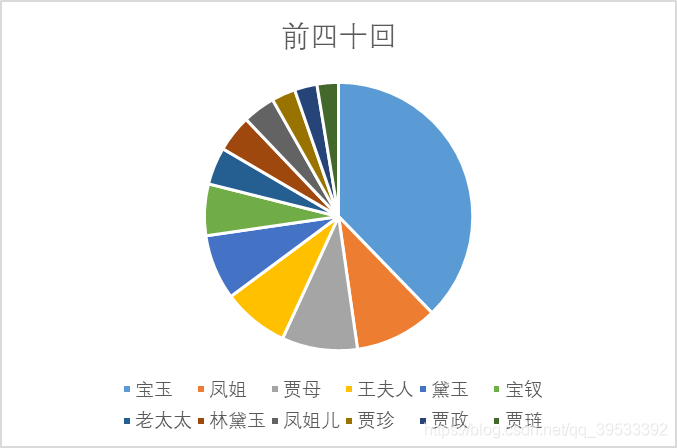
图3 前四十回饼状图
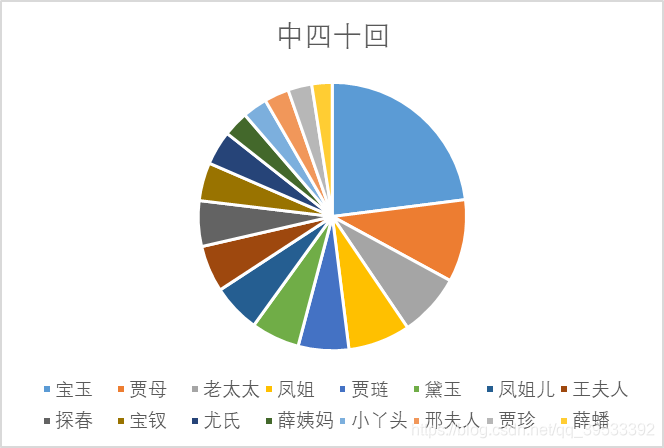
图4 中四十回饼状图
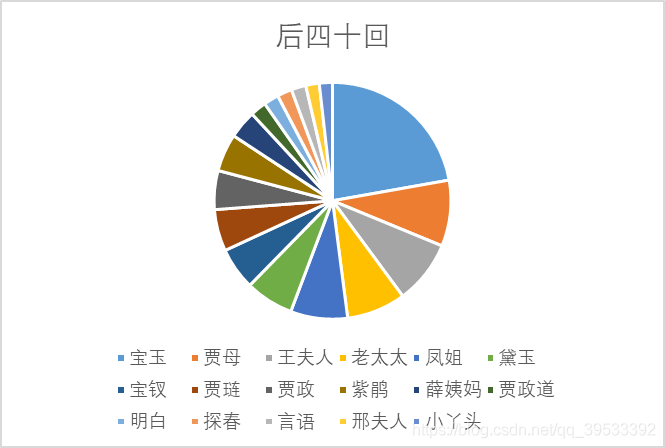
图5 后四十回饼状图
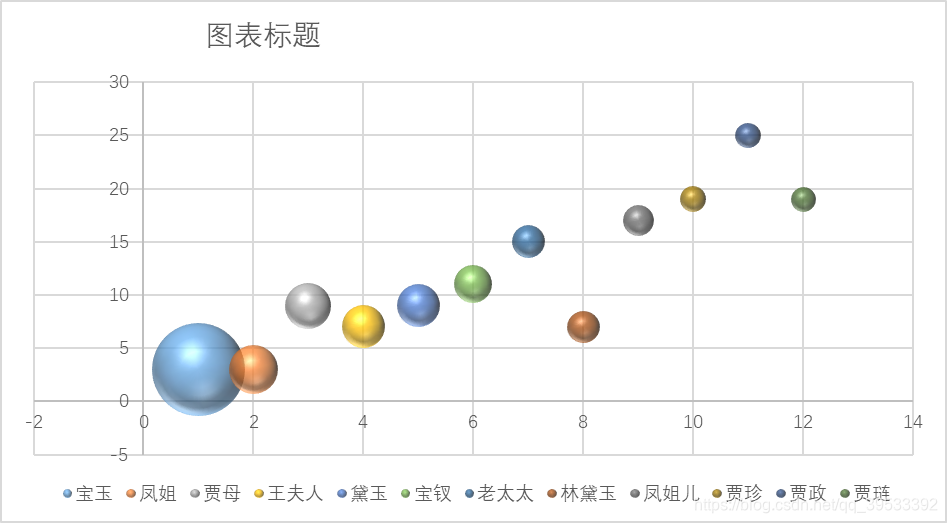
图6 前四十回气泡图
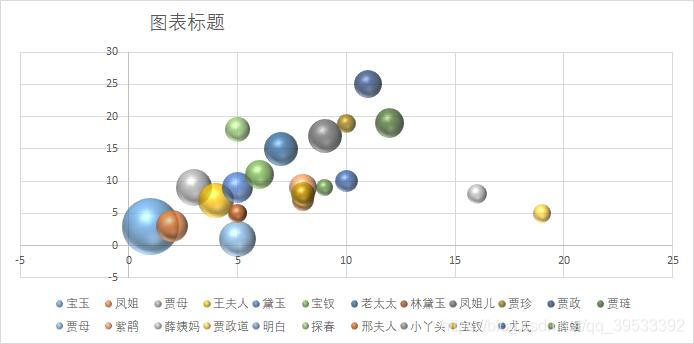
图7 中四十回气泡图
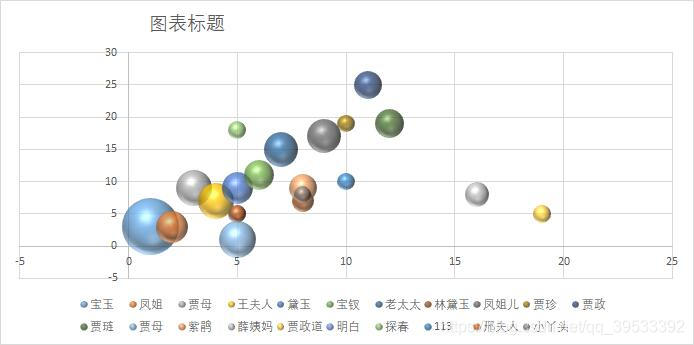
图8 后四十回气泡图
从饼图以及气泡图中可以看出只有个别人物具有较高的出现频率且人物排序在三部分中难以看出作者的不同。我们分析这是由于《红楼梦》本身作为一部长篇小说,其中人物的出现频率与小说的剧情发展有着较大的关联,而为了保证情节的连续性,改变作者并不会对其中人物的出现频率产生较大的影响,所以我们认为分析人物的出现频率并不能用于证明不同章回之间作者的异同。
问题二的求解
章回的向量化
文本分类(text category)是用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记。判断后四十回是不是曹雪芹所写,这是其实就是一个典型的文本分类问题。我们把每一回当成一个独立文本,对全书的一百二十回文本进行分类,若确实能分成两类,那就能说明问题了。
一般来说,文本分类问题是将不同主题的文本划分为不同的类别。 比如,数学上的常用词是:矩阵、向量、乘积、旋转、坐标等等,文学上的常用词则是:人物、诗词、时间等等。但是,在我们这个应用场景下,文本主题显然不是分类的依据。因为全书在故事情节上是一体的,讨论的话题也是一致的。如果还是按照话题来划分,估计全书会被划作一类。
所以,要判断后四十回和前八十回是不是一个人写的,应该看的是写作风格。一个人或许可以写不同情节的故事,但是不同故事的写作风格应该是一致的。我们选择虚词作为判别文风的证据。所谓虚词就是副词、介词、连接词之类不表达具体含义,只有语法功能的词。这些词的使用频率与具体的故事情节、写作话题无关,而主要与作者的使用习惯有关。同一个作者,虽然文章主题不同,但是虚词的使用频率应该是十分接近的。那么,我们就从《红楼梦》中每一回目中出现的虚词频率入手,来判断作者的文风。[1-3]
大部分虚词其实都只有一个字,我们把词频转化为字频,这样连分词这一步就可以省略了。
在汉语中虚词有数百多个,如何正确地选择虚词以更好地分析写作风格。首先如果某个虚词只在某几个回目中出现,这种虚词对我们作者解析帮助不大。为了使我们使用的虚词具有统计意义,我们要求在一百二十回中都出现的虚词才算做统计对象。
我们通过Python运行得到的结果如下图所示:

图9 出现的虚词
首先统计每一回中上述虚词的出现次数,仔细观察会发现,这里面包括了标点符号。因为标点符号从某一方面也可以反应作者的写作风格,所以我们认为将标点符号算入虚词对最终的结果不会产生影响。从结果也可以看出,算上标点符号,也只有117个字在全书的每个章回出现过。
我们在第一回中得到的这些虚词出现的频率如图所示:

图10 虚词出现频率
将得到的120章回的字频合在一起,便构成117维的向量。于是我们可以将每一个章回抽象成一个向量。接下来,我们利用kNN(k-nearest neighbors)算法检验是否可以将120个章回分成两类。
主成分分析算法
在进行分类之前,我们直观上看一看,前八十回和后四十回到底有没有区别。现在每一回都变为了一个117维的向量,我们没有办法把这么高维度的数据画出来。为此,我们采用了主成分分析(Principal Component Analysis,PCA)算法。
主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。这种方法在引进多方面变量的同时将复杂因素归结为几个主成分,使问题简单化,同时得到的结果更加科学有效的数据信息。在实际问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。主成分分析算法实际上是数据降维方法。
我们将每个回目的117维向量降维到3维,在3维空间中画出每个回目的散点图。

图11 三维空间回目散点图
图中红色圆圈表示的是前八十回的回目,蓝色圆圈表示的是后四十回的回目。从图中可以看出,前八十回和后四十回确实分散在空间中不同的区域。
kNN(k-nearest neighbors)算法
我们先将前八十回所属的类别称之为类别1,后四十回所属的类别称之为类别2。从这种空间散布特征出发,提出一个分类算法:
1、先给出一些回目作为种子,这些种子标明了类别。比如我们将第20回~29回作为类别1的种子,第110回~119回作为类别2的种子。
2、分析回目n与这些种子的距离,找出离回目n最近的3个种子。假设第75回离得最近的三个种子为21回、28回、115回。
3、根据种子的类别,进行投票,投票胜出的即为回目n的类别。由于21回、28回、115回这三个种子中两个为类别1,一个为类别2,所以我们可以判定第75回属于类别1。
这就是kNN(k-nearest neighbors)算法,其实就是一个投票算法而已。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合
在我们处理数据的过程中,k就是寻找最近的k个种子的意思,上边的例子中k取为3。
一般来说k越大,算法抵御噪声的能力就越强,但是分类的边界就越不准确。所以综合考虑后在这个问题的研究中我们将k取为3。
经过我们的3NN算法一阵运转,最终分别得到了全书一百二十回所属的类别。如下图:

图12 3NN算法运行结果
可以看出,前80回中大多数都被判定为类别1,只有6个误判。后四十回中大部分都被判定为类别2,只有7个误判。
由此我们可以得出结论,《红楼梦》的前80回与后40回的写作风格有着明显的区分。这与文学界所认为的后40回并非曹雪芹本人所写而是后人补写的结论一致。
问题三的求解
为了判断章回中是否存在异同,我们在第一问的基础上,通过判断同一句话中另个人物名称出现的次数进而进行词于词之间的相关性的分析。通过分析同一句中人物的同时出现的次数,我们可以得到两个人物之间的关系亲密程度。我们基于同一句话中两个人物出现的次数来提取人物关系,即若一句话中两个人物出现,则加两个节点name1-name2,weight=1,若以后在其他语句中再出现,则weight+1,以此类推,直到找到所有人物关系节点。
为了更好地比较前八十回和后四十后之间的差异,我们依旧将前八十回平均分为两层,最后得到三个样本(前四十回,中四十回,后四十回)。

图13 人物关系运行结果
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件,,其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。在本次实验中,我们利用了Gephi绘制人物关系图。
我们通过Gephi得到三个样本人物的关系图,如下:

图14 前四十章人物关系图

图15 中四十章人物关系图

图16 后四十章人物关系图
通过Gephi所得到的图像可以推断出:前四十章和中间四十章差异不大,几乎温和;后四十章与前四十章和中间四十章存在明显的差异。因此,我们得出:前八十章和后四十章属于不同的写作风格,可以推断属于不同的作者缩写。
问题四的求解
关于“这么、那么”这一形式的来源,很多学者都进行过相关论述。冯春田的 《近代汉语语法研究》中说到:“晚唐五代就有指示代词‘没’、‘么(麼)’、‘者莽’等,按说应该是指示代词‘这(那)么’的早期形式。”;袁宾在《近代汉语概要》中里写道: “唐宋文献里有‘只么(麼)’一词,是‘这么,如此’的意思, ‘只’和‘这’声母相同,可能同出一源。”;向熹的《简明汉语史》中讲到:“‘这么’,用于指状态、方式、程度,一般在句中作状语。明以前只作‘这们’, 《红楼梦》里才开始用‘这么’。‘那么’指代事物的性质、程度或行为方式。”;俞光中、植田均的《近代汉语语法研究》中讲到:“现代汉语‘这么’、‘那么’源于‘这(那)’与历时最长的形状动作指示代词‘么’的结合”。
从以上各家对“这么”、“那么”来源的论述,可以看出,其在《红楼梦》时期的形式成熟并得以广泛运用,是这一时期典型的语言现象。因此我们对它们在《红楼梦》中的用法作详尽的分类描述,以窥其时代特色,并对前后使用的情况作细致的比较,以深入探讨这两个词所体现出的《红楼梦》前后言语差异。
“这么”在全书中共329例,均出现在人物对话体中,叙述体中未见。A中200例,B中129例。在A中的平均使用率: 2.5次/回,在B中的平均使用率: 3.225次/回。

图17 “这么”语义功能和使用频率统计表
从使用率上看, B是A的1.29倍,显然B中的平均使用率高于A,除了在使用率上存在差异外,我们在统计过程中还发现: “这么”的几个变体形式“这们”、 “这麽”在A均有3个以上的用例,在B却未见一例。从形式上看,“这么”在B中书写更规范更统一。
“那么”全书共31例,基本用于《红楼梦》的对话体(仅有一例用于描写人物心理活动),叙述体中未见。A中15例, B中16例。在A中的平均使用率:0.188次/回,在B中的平均使用率: 0.4次/回。
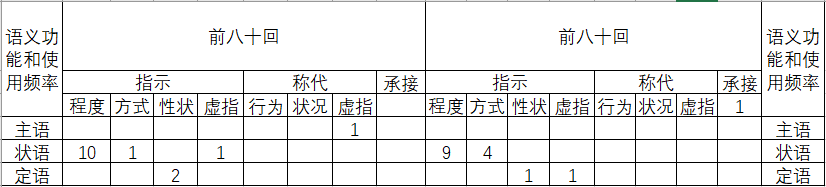
图18 “那么”语义功能和使用频率统计表
通过表格,可以清晰地看到:就平均使用率来讲, “那么”的使用情况在A、 B存在较大的差异,在B中的使用率远远高于在A中的使用率,是A的两倍多。
前面考察的“那么”、“这么”的前后用法情况,通过以上的比较,我们发现其差异主要体现在平均使用率上,其次是语法功能、语用功能,仅就“这么”而言还有书写形式上的差异。另外接近现代汉语的语法功能和语用功能的用法,在B中的使用频率较高。
我们分析出现这些差异的原因会有很多,在此仅作一些初步推断。一表达需要的不同,二创作风格的不同,即作者写作在用词习惯上的差异。使用平均率的差异可以从作者创作的用词习惯上解释;导致语法功能和语用功能差异的原因要复杂得多,这里难以下结论,初步推断,可能是表达需要的不同,作者创作风格的不同等;至于书写的形式是否统一这一差异,主要的原因应该是作者书写的习惯不同,另外创作年代的先后也有一定的影响,可能在一段时期里, “这么”的书写形式有很多种,随着语言的发展,书写形式便逐渐归于统一。[4]
模型评价与分析
优点
由于该模型所研究的范围具有普适性,所以该模型在分析不同文章的写作风格时可以起到很好的分析作用。该模型认为虚词的使用频率能够反映出作者的写作风格,对于全文中出现频率很低的人物名认为可以忽略并忽略同名不同义的词对研究结果的影响。我们利用此模型结合主成分分析算法和kNN算法实现了对数据的简化及分类,得到了与现实情况比较吻合的实验。在通过虚词出现频率来寻找作者差异的过程中,此模型能够给予与现实十分相符的结论。又因为该模型所研究的对象是文章中人物名字出现的频率、虚词出现的频率以及人物之间的关系,这几项指标皆会出现在小说类文章中,所以此模型能够在小说类文章的分析中发挥令人满意的效果。
缺点
在特征词量化方面,由于中文含义上的多样性,存在人名用代词替换的情况,使频数出现误差;同名不同义的特征词出现也会造成频数误差(如:宝玉、通灵宝玉)。
文本层次划分由于特征词的选用是根据《红楼梦》文本的标题决定的,该文本标题是全文内容的概括,出现人名就是故事主要人物,但这类文本不具有普遍性,故几乎不可用于其他文本结构分析上,不具有普遍性。
张首映指出,单个作家的“语言风格”是不可求证的。单个作家的“语言风格”,无论在时间之轴上,还是在空间之维中,都必定不可能产生。林语堂式的幽默,沈从文式的淡雅,都是不同的言语风格,而不是语言风格。因此计算起来可能很难。这一论断表明,我们不可能以量化的数值来表示绝对的作家风格。计算风格学的量化指标都只能作相对参考。
参考文献
[1]李贤平,《红楼梦》成书新说,复旦大学学报社科版,1987,(5):3-16.
[2]韦博成,红楼梦前80回与后40回某些文风差异的统计分析,应用概率统计,2009,25(4):441-448.
[3]施建军,基于支持向量机技术的《红楼梦》作者研究,红楼梦学刊,2011 (5) :35-52.
[4] 刘钧杰,《红楼梦》前八十回与后四十回言语差异考察,语言研究,1986, (1).
附录
所用软件:
JetBrains PyCharm Community Edition 2018.2.2 x64
Gephi0.92
源代码:
import codecs
import jieba.posseg as pseg
import jieba
names = {}# 保存人物,键为人物名称,值为该人物在全文中出现的次数
relationships = {}#保存人物关系的有向边,键为有向边的起点,值为一个字典 edge ,edge 的键为有向边的终点,值是有向边的权值
lineNames = []# 缓存变量,保存对每一段分词得到当前段中出现的人物名称
print("开始执行")
jieba.load_userdict("name.txt")#加载人物表
with codecs.open("前四十回.txt", 'r', 'utf8') as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词,返回词性
lineNames.append([]) # 为本段增加一个人物列表
for w in poss:
if w.flag != 'nr' or len(w.word) < 2:
continue # 当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名
lineNames[-1].append(w.word) # 为当前段的环境增加一个人物2
if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
print("输出人物统计次数")
# 输出人物出现次数统计结果
cnt=0
for name, times in names.items():
cnt=cnt+times
print(name, times)
# 对于 lineNames 中每一行,我们为该行中出现的所有人物两两相连。如果两个人物之间尚未有边建立,则将新建的边权值设为 1,
# 否则将已存在的边的权值加 1。这种方法将产生很多的冗余边,这些冗余边将在最后处理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
# 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边,
# 为此可设置阈值为100,即当边出现10次以上则认为不是冗余
print("问题一所用的前四十回主要人物出场频率.txt")
with codecs.open("前四十回主要人物出场频率.txt", "w", "utf8") as f:
#f.write("ID Label Weight\r\n")
for name, times in names.items():
if times > 100:
f.write(name + " " + str(times) + " " + str(times/cnt) + "\r\n")
print("问题三所用的前四十回主要人物关系.txt")
with codecs.open("前四十回主要人物关系.txt", "w", "utf8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 50:
f.write(name + " " + v + " " + str(w) + "\r\n")
import codecs
import jieba.posseg as pseg
import jieba
names = {}# 保存人物,键为人物名称,值为该人物在全文中出现的次数
relationships = {}#保存人物关系的有向边,键为有向边的起点,值为一个字典 edge ,edge 的键为有向边的终点,值是有向边的权值
lineNames = []# 缓存变量,保存对每一段分词得到当前段中出现的人物名称
print("开始执行")
jieba.load_userdict("name.txt")#加载人物表
with codecs.open("中四十回.txt", 'r', 'utf8') as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词,返回词性
lineNames.append([]) # 为本段增加一个人物列表
for w in poss:
if w.flag != 'nr' or len(w.word) < 2:
continue # 当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名
lineNames[-1].append(w.word) # 为当前段的环境增加一个人物2
if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
print("输出人物统计次数")
# 输出人物出现次数统计结果
cnt=0
for name, times in names.items():
cnt=cnt+times
print(name, times)
# 对于 lineNames 中每一行,我们为该行中出现的所有人物两两相连。如果两个人物之间尚未有边建立,则将新建的边权值设为 1,
# 否则将已存在的边的权值加 1。这种方法将产生很多的冗余边,这些冗余边将在最后处理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
# 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边,
# 为此可设置阈值为100,即当边出现10次以上则认为不是冗余
print("中四十回主要人物出场频率.txt")
with codecs.open("中四十回主要人物出场频率.txt", "w", "utf8") as f:
#f.write("ID Label Weight\r\n")
for name, times in names.items():
if times > 100:
f.write(name + " " + str(times) + " " + str(times/cnt) + "\r\n")
print("中四十回主要人物关系.txt")
with codecs.open("中四十回主要人物关系.txt", "w", "utf8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 50:
f.write(name + " " + v + " " + str(w) + "\r\n")
import codecs
import jieba.posseg as pseg
import jieba
names = {}# 保存人物,键为人物名称,值为该人物在全文中出现的次数
relationships = {}#保存人物关系的有向边,键为有向边的起点,值为一个字典 edge ,edge 的键为有向边的终点,值是有向边的权值
lineNames = []# 缓存变量,保存对每一段分词得到当前段中出现的人物名称
print("开始执行")
jieba.load_userdict("name.txt")#加载人物表
with codecs.open("后四十回.txt", 'r', 'utf8') as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词,返回词性
lineNames.append([]) # 为本段增加一个人物列表
for w in poss:
if w.flag != 'nr' or len(w.word) < 2:
continue # 当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名
lineNames[-1].append(w.word) # 为当前段的环境增加一个人物2
if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
print("输出人物统计次数")
# 输出人物出现次数统计结果
cnt=0
for name, times in names.items():
cnt=cnt+times
print(name, times)
# 对于 lineNames 中每一行,我们为该行中出现的所有人物两两相连。如果两个人物之间尚未有边建立,则将新建的边权值设为 1,
# 否则将已存在的边的权值加 1。这种方法将产生很多的冗余边,这些冗余边将在最后处理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
# 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边,
# 为此可设置阈值为100,即当边出现10次以上则认为不是冗余
print("后四十回主要人物出场频率.txt")
with codecs.open("前四十回主要人物出场频率.txt", "w", "utf8") as f:
#f.write("ID Label Weight\r\n")
for name, times in names.items():
if times > 100:
f.write(name + " " + str(times) + " " + str(times/cnt) + "\r\n")
print("后四十回主要人物关系.txt")
with codecs.open("后四十回主要人物关系.txt", "w", "utf8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 50:
f.write(name + " " + v + " " + str(w) + "\r\n")
import re
from collections import Counter
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
# 红楼梦的章回数
CHAPTER_NUM = 120
# 将红楼梦全书按回目切分,并保存在data目录中
def cut_book_to_chapter(book_path, save_path_prefix):
chapter_begin_pattern = '[('
chapter_end_pattern = '(本章完)'
#import ipdb; ipdb.set_trace()
with open(book_path, 'r', encoding = 'utf-8') as f:
book = f.read()
beg_pos = book.find(chapter_begin_pattern)
chapter_index = 1
while beg_pos != -1:
end_pos = book.find(chapter_end_pattern, beg_pos)
end_pos += len(chapter_end_pattern)
current_chapter = book[beg_pos:end_pos+1]
current_chapter_path = save_path_prefix + str(chapter_index)
with open(current_chapter_path, 'w', encoding = 'utf-8') as f:
f.write(current_chapter)
beg_pos = book.find(chapter_begin_pattern, end_pos)
chapter_index += 1
# 对每一章节预处理
def preprocess_chapter(raw_text):
# 去除第一行和最后一行
pos1 = raw_text.find('\n')
pos2 = raw_text.rfind('\n')
chapter = raw_text[pos1:pos2].strip()
# 去除空格和换行符号
chapter = re.sub('[\s]', '', chapter)
return chapter
# 找到每一回都出现的字,即停用字
def get_stop_chars(dir_prefix):
stop_chars = set()
for i in range(1, CHAPTER_NUM+1):
file_path = dir_prefix + str(i)
# 读取章节文本
with open(file_path, 'r', encoding = 'utf-8') as f:
raw_text = f.read().strip()
# 预处理
chapter = preprocess_chapter(raw_text)
# 求每个章节的交集
if i == 1:
stop_chars = set(chapter)
else:
stop_chars &= set(chapter)
return list(stop_chars)
# 求出每个停用字的字频,保存到向量中
def convert_chapter_to_vector(chapter, stop_chars):
# 得到每个字的出现次数
char_counter = Counter(chapter)
# 得到该回目总字数
chapter_char_num = sum(char_counter.values())
# 当前回目的特征向量
feature_vector = np.zeros(len(stop_chars), dtype='float32')
for i, c in enumerate(stop_chars):
feature_vector[i] = char_counter[c]
feature_vector /= chapter_char_num
print(feature_vector)
return feature_vector
# 将每一章节的向量作为一行,构成矩阵
def convert_book_to_matrix(dir_prefix, stop_chars):
observations = np.zeros((CHAPTER_NUM, len(stop_chars)), dtype='float32')
for i in range(1, CHAPTER_NUM+1):
file_path = dir_prefix + str(i)
# 读取章节文本
with open(file_path, 'r', encoding = 'utf-8') as f:
raw_text = f.read().strip()
# 预处理
chapter = preprocess_chapter(raw_text)
# 得到当前回目的向量
observations[i-1, :] = convert_chapter_to_vector(chapter, stop_chars)
return observations
# 降维到3维,并可视化
def scatters_in_3d(samples, is_labelled = False):
# PCA 降维到2维便于可视化
pca = PCA(n_components=3)
reduced_data = pca.fit_transform(samples)
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=9, azim=-170)
for c, rng in [('r', (0, 80)), ('b', (80, 120))]:
xs = reduced_data[rng[0]:rng[1], 0]
ys = reduced_data[rng[0]:rng[1], 1]
zs = reduced_data[rng[0]:rng[1], 2]
ax.scatter(xs, ys, zs, c=c)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
if is_labelled:
for ix in np.arange(len(samples)):
ax.text(reduced_data[ix, 0], reduced_data[ix, 1],reduced_data[ix, 2],
str(ix+1), verticalalignment='center', fontsize=10)
plt.show()
# 构建训练数据并用kNN分类器分类
def knn_clf(observations, n_neighbors):
# 构建训练数据
range1 = [20, 30]
len1 = len(range(range1[0], range1[1]))
range2 = [110, 120]
len2 = len(range(range2[0], range2[1]))
training_index = list(range(range1[0], range1[1])) + list(range(range2[0],
range2[1]))
training_data = observations[training_index, :]
training_label = np.ones(len1+len2, dtype='int32')
training_label[len1:] = 2
# 最近邻分类器
knn = KNeighborsClassifier(n_neighbors = 3)#, weights = 'distance')
knn.fit(training_data, training_label)
# 预测
knn_pre = knn.predict(observations)
print('第一回至第八十回')
for i in range(8):
print(knn_pre[i*10:(i+1)*10])
print('第八十一回至第一百二十回')
for i in range(8,12):
print(knn_pre[i*10:(i+1)*10])
if __name__ == '__main__':
chapter_prefix = 'data/chapter-'
# 将红楼梦全书分回目存储
cut_book_to_chapter('./data/dream_of_red_chamber.txt', chapter_prefix)
# 获取每个章节都出现过的字
stop_chars = get_stop_chars(chapter_prefix)
print(stop_chars)
# 将全书转换为特征矩阵
observations = convert_book_to_matrix(chapter_prefix, stop_chars)
# 降维并画图
scatters_in_3d(observations, True)
# kNN分类
knn_clf(observations, 3)
#import ipdb; ipdb.set_trace()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号