
云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作。
“云计算分布式大数据Hadoop实战高手之路”之完整发布目录
云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云计算实战性资料,欢迎大家加入!
首先我们看一些比较常用的Hadoop文件系统的操作命令:
第一个常用命令:hadoop fs –ls
例如使用以下命令是列出文件系统根目录下的文件和文件夹,具体效果如下图所示:

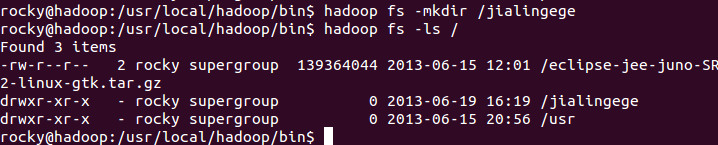
第二个常用命令:hadoop fs –mkidr
例如使用以下命令是在HDFS中的根目录下创建一个子目录,具体效果如下图所示:
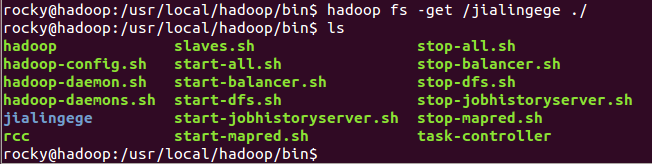
第三个常用的命令:hadoop fs –get
例如使用以下命令是把HDFS中的根目录中的jialingege这个文件夹复制到本地,具体效果如下图所示:
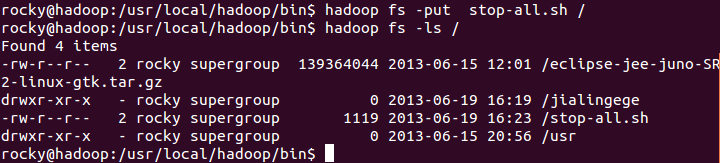
第四个常用的命令:hadoop fs –put srcfile /desfile
例如使用以下命令是把当前目录中的stop-all.sh复制到HDFS中的根目录中,具体效果如下图所示
Hadoop文件系统更多的操作命令打开官方网站中文件系统的操作命令页面:http://hadoop.apache.org/docs/stable/file_system_shell.html
可以看出很多命令和Linux文件操作系统的命令是一样的,例如cat这个命令在Linux中的含义是将一个文件的内容在屏幕上打印出来,在Hadoop文件系统中的含义是一样的,需要注意的一点是在hadoop 1.1.2文档中文件系统操作命令有所改变,但是官方网站却没有相应的改变,例如我们看cat命令:
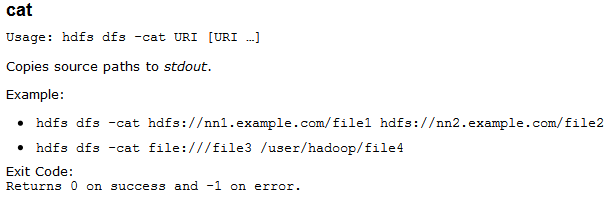
此时操作文件系统时是“dfs”,而实际上在hadoop 1.1.2版本的时候是“fs”,我们在前面HDFS命令行工具实战的时候也看到了这一点。
关于Hadoop文件系统的操作,大家跟着官方文档一步步做小实验即可,这里不再赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号