
设计模式--行为型模式(下)
备忘录模式:
为了使软件的使用更加人性化,对于误操作,我们需要提供一种类似“后悔药”的机制,让软件系统可以回到误操作前的状态,
因此需要保存用户每一次操作时系统的状态,一旦出现误操作,可以把存储的历史状态取出即可回到之前的状态。
现在大多数软件都有撤销(Undo)的功能,快捷键一般都是Ctrl+Z,目的就是为了解决这个后悔的问题。
备忘录模式是一种给我们的软件提供后悔药的机制,通过它可以使系统恢复到某一特定的历史状态。
备忘录模式(Memento Pattern):在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,
这样可以在以后将对象恢复到原先保存的状态。它是一种对象行为型模式,其别名又叫做Token模式或快照模式(Snapshot Pattern) 。
备忘录模式的核心是备忘录类以及用于管理备忘录的负责人类的设计,其结构如下图所示。
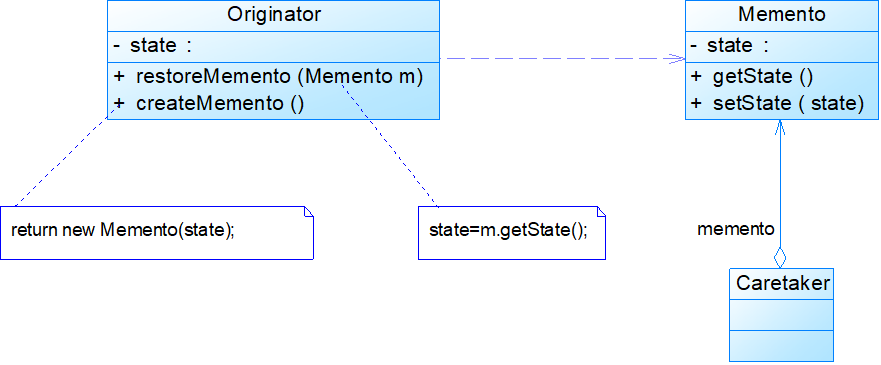
Originator:原发器,它是一个普通类,可以创建一个备忘录,并存储它的当前内部状态,也可以使用备忘录来恢复其内部状态,一般将需要保存内部状态的类设计为原发器。
Memento:备忘录,存储原发器的内部状态,根据原发器来决定保存哪些内部状态。备忘录的设计一般可以参考原发器的设计,
根据实际需要确定备忘录类中的属性。需要注意的是,除了原发器本身与负责人类之外,备忘录对象不能直接供其他类使用,原发器的设计在不同的编程语言中实现机制会有所不同。
Caretaker:负责人又称为管理者,它负责保存备忘录,但是不能对备忘录的内容进行操作或检查。在负责人类中可以存储一个或多个备忘录对象,它只负责存储对象,而不能修改对象,也无须知道对象的实现细节。
理解备忘录模式并不难,但关键在于如何设计备忘录类和负责人类。由于在备忘录中存储的是原发器的中间状态,因此需要防止原发器以外的其他对象访问备忘录,特别是不允许其他对象来修改备忘录。
模式分析:
使用备忘录模式时首先应该存在一个原发器类Originator,在真实业务中,原发器类是一个具体的业务类,它包含一些用于存储成员数据的属性,典型代码如下所示:
package dp.memento; public class Originator { private String state; public Originator(){ } // 创建一个备忘录对象 public Memento createMemento() { return new Memento(this); } // 根据备忘录对象恢复原发器状态 public void restoreMemento(Memento m) { state = m.state; } public void setState(String state) { this.state=state; } public String getState() { return this.state; } }
对于备忘录类Memento而言,它通常提供了与原发器相对应的属性(可以是全部,也可以是部分)用于存储原发器的状态,典型的备忘录类设计代码如下:
package dp.memento; class Memento { private String state; public Memento(Originator o) { state = o.getState(); } public void setState(String state) { this.state=state; } public String getState() { return this.state; } }
在设计备忘录类时需要考虑其封装性,除了Originator类,不允许其他类来调用备忘录类Memento的构造函数与相关方法,如果不考虑封装性,
允许其他类调用setState()等方法,将导致在备忘录中保存的历史状态发生改变,通过撤销操作所恢复的状态就不再是真实的历史状态,备忘录模式也就失去了本身的意义。
在实际开发中,原发器与备忘录之间的关系是非常特殊的,它们要分享信息而不让其他类知道,实现的方法因编程语言的不同而有所差异。
在C++中可以使用friend关键字,让原发器类和备忘录类成为友元类,互相之间可以访问对象的一些私有的属性;
在使用Java语言实现备忘录模式时,一般通过将Memento类与Originator类定义在同一个包(package)中来实现封装,
在Java语言中可使用默认访问标识符来定义Memento类,让它们之间满足默认的包内可见性,也可以将备忘录类作为原发器类的内部类,
使得只有原发器才可以访问备忘录中的数据,其他对象都无法使用备忘录中的数据。
对于负责人类Caretaker,它用于保存备忘录对象,并提供getMemento()方法用于向客户端返回一个备忘录对象,原发器通过使用这个备忘录对象可以回到某个历史状态。典型的负责人类的实现代码如下:
在Caretaker类中不应该直接调用Memento中的状态改变方法,它的作用仅仅用于存储备忘录对象。将原发器备份生成的备忘录对象存储在其中,当用户需要对原发器进行恢复时再将存储在其中的备忘录对象取出。
package dp.memento; public class Caretaker { private Memento memento; public Memento getMemento() { return memento; } public void setMemento(Memento memento) { this.memento=memento; } }
备忘录模式实例:
实例:用户信息操作撤销
某系统提供了用户信息操作模块,用户可以修改自己的各项信息。为了使操作过程更加人性化,现使用备忘录模式对系统进行改进,使得用户在进行了错误操作之后可以恢复到操作之前的状态。
实例结构:
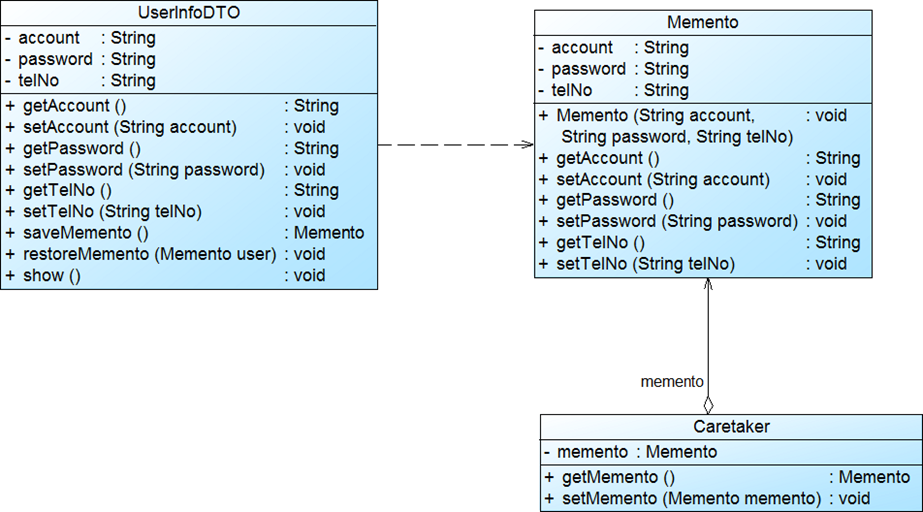
实例代码:
//============== //备忘录,存储中间状态 class Memento { private String account; private String password; private String telNo; public Memento(String account,String password,String telNo) { this.account=account; this.password=password; this.telNo=telNo; } public String getAccount() { return account; } public void setAccount(String account) { this.account=account; } public String getPassword() { return password; } public void setPassword(String password) { this.password=password; } public String getTelNo() { return telNo; } public void setTelNo(String telNo) { this.telNo=telNo; } } //======================= //负责人类,保管着备忘录类,但不清楚备忘录内部细节 //Client与caretaker交互 public class Caretaker { private Memento memento; public Memento getMemento() { return memento; } public void setMemento(Memento memento) { this.memento=memento; } } //=================== //原发器,可以保存当前状态到备忘录,也可以从备忘录中加载状态 public class UserInfoDTO { private String account; private String password; private String telNo; public String getAccount() { return account; } public void setAccount(String account) { this.account=account; } public String getPassword() { return password; } public void setPassword(String password) { this.password=password; } public String getTelNo() { return telNo; } public void setTelNo(String telNo) { this.telNo=telNo; } public Memento saveMemento() { return new Memento(account,password,telNo); } public void restoreMemento(Memento memento) { this.account=memento.getAccount(); this.password=memento.getPassword(); this.telNo=memento.getTelNo(); } public void show() { System.out.println("Account:" + this.account); System.out.println("Password:" + this.password); System.out.println("TelNo:" + this.telNo); } } //=================== //Client端使用 public class Client { public static void main(String a[]) { UserInfoDTO user=new UserInfoDTO(); Caretaker c=new Caretaker(); user.setAccount("zhangsan"); user.setPassword("123456"); user.setTelNo("13000000000"); System.out.println("状态一:"); user.show(); c.setMemento(user.saveMemento());//保存备忘录 System.out.println("---------------------------"); user.setPassword("111111"); user.setTelNo("13100001111"); System.out.println("状态二:"); user.show(); System.out.println("---------------------------"); user.restoreMemento(c.getMemento());//从备忘录中恢复 System.out.println("回到状态一:"); user.show(); System.out.println("---------------------------"); } }
备忘录模式的注意事项和细节
1) 给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态
2) 实现了信息的封装,使得用户不需要关心状态的保存细节
3) 如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存, 这个需要注意
4) 适用的应用场景:
1、后悔药。
2、打游戏时的存档。
3、Windows 里的 ctri + z。
4、IE 中的后退。
5、数据库的事务管理
5) 为了节约内存,备忘录模式可以和原型模式配合使用
解释器模式:
智能手机上的计算器应用,只要输入一个表达式,它就能够计算出表达式结果,如图所示,当输入字符串表达式为“1 + 2 + 3 – 4 + 1”时,将输出计算结果为3。
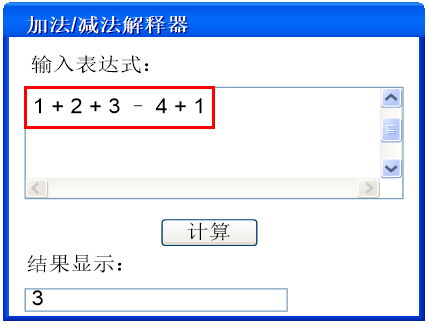
我们知道,像C++、Java和C#等语言无法直接解释类似“1+ 2 + 3 – 4 + 1”这样的字符串(如果直接作为数值表达式时可以解释),因此,计算器应用必须定义一套文法规则来实现对这些语句的解释。
假如要开发一套机器人控制程序,提供图形化的设置界面,用户通过对界面进行操作可以创建一个机器人控制指令,机器人在收到指令后将按照指令的设置进行移动,
例如输入控制指令:up move 5,则“向上移动5个单位”;输入控制指令:down run 10 and left move 20,则“向下快速移动10个单位再向左移动20个单位”。
开发人员就要编写代码来解析控制指令的文法规则,并按指令要求来驱动机器人完成相应动作。
如果在系统中某一特定类型的问题发生的频率很高,此时可以考虑将这些问题的实例表述为一个语言中的句子,然后可以构建一个解释器,该解释器通过解释这些句子来解决这些问题。
在实际开发中,这些简单的自定义语言可以基于现有的编程语言来设计,如果所基于的编程语言是面向对象语言,此时可以使用解释器模式来实现自定义语言。
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子。
在前面所提到的加法/减法解释器中,每一个输入表达式,例如“1 + 2 + 3 – 4 + 1”,都包含了三个语言单位,可以使用如下文法规则来定义:
expression ::= value | operation operation ::= expression '+' expression | expression '-' expression value ::= an integer //一个整数值
该文法规则包含三条语句,第一条表示表达式的组成方式,其中value和operation是后面两个语言单位的定义
每一条语句所定义的字符串如operation和value称为语言构造成分或语言单位,符号“::=”表示“定义为”的意思,其左边的语言单位通过右边来进行说明和定义,语言单位对应终结符表达式和非终结符表达式。
如本规则中的operation是非终结符表达式,它的组成元素仍然可以是表达式,可以进一步分解,而value则是终结符表达式。
在文法规则定义中可以使用一些符号来表示不同的含义,如使用“|”表示或,使用“{”和“}”表示组合,使用“*”表示出现0次或多次等,其中使用频率最高的符号是表示“或”关系的“|”,
如文法规则“boolValue ::= 0 | 1”表示终结符表达式boolValue的取值可以为0或者1。
除了使用文法规则来定义一个语言,在解释器模式中还可以通过一种称之为抽象语法树(Abstract Syntax Tree, AST)的图形方式来直观地表示语言的构成,
每一棵抽象语法树对应一个语言实例,如加法/减法表达式语言中的语句“1+ 2 + 3 – 4 + 1”,可以通过如图所示抽象语法树来表示:
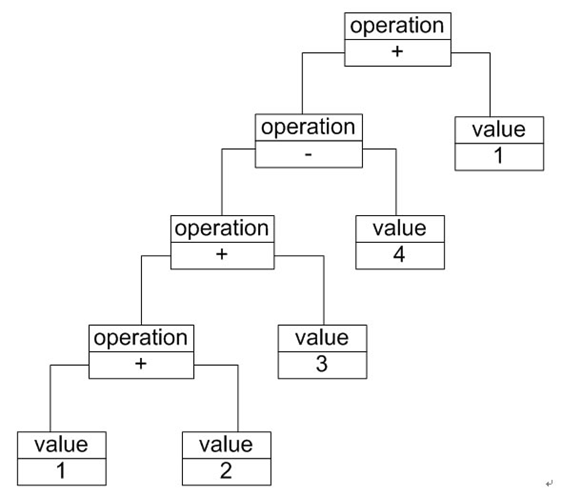
在该抽象语法树中,可以通过终结符表达式value和非终结符表达式operation组成复杂的语句,每个文法规则的语言实例都可以表示为一个抽象语法树,
即每一条具体的语句都可以用类似上图所示的抽象语法树来表示,在图中终结符表达式类的实例作为树的叶子节点,而非终结符表达式类的实例作为非叶子节点,
它们可以将终结符表达式类的实例以及包含终结符和非终结符实例的子表达式作为其子节点。抽象语法树描述了如何构成一个复杂的句子,
通过对抽象语法树的分析,可以识别出语言中的终结符类和非终结符类。
解释器模式是一种使用频率相对较低但学习难度较大的设计模式,它用于描述如何使用面向对象语言构成一个简单的语言解释器。
在某些情况下,为了更好地描述某一些特定类型的问题,我们可以创建一种新的语言,这种语言拥有自己的表达式和结构,即文法规则,这些问题的实例将对应为该语言中的句子。
此时,可以使用解释器模式来设计这种新的语言。对解释器模式的学习能够加深我们对面向对象思想的理解,并且掌握编程语言中文法规则的解释过程。
模式定义:
解释器模式(Interpreter Pattern) :定义一个语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”是指使用规定格式和语法的代码,解释器模式是一种类行为型模式。
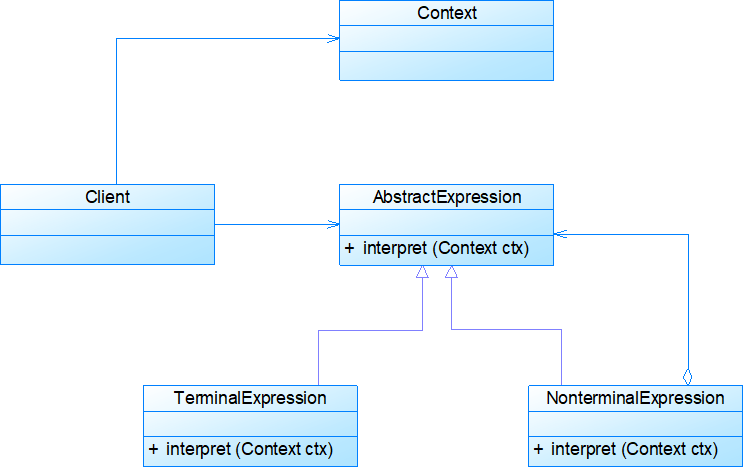
AbstractExpression: 抽象表达式声明了抽象的解释操作,它是所有终结符表达式和非终结符表达式的公共父类。
TerminalExpression: 终结符表达式是抽象表达式的子类,它实现了与文法中的终结符相关联的解释操作,在句子中的每一个终结符都是该类的一个实例。
通常在一个解释器模式中只有少数几个终结符表达式类,它们的实例可以通过非终结符表达式组成较为复杂的句子。
NonterminalExpression: 非终结符表达式也是抽象表达式的子类,它实现了文法中非终结符的解释操作,由于在非终结符表达式中可以包含终结符表达式,
也可以继续包含非终结符表达式,因此其解释操作一般通过递归的方式来完成。
Context: 环境类又称为上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
Client: 客户类,指的是使用解释器的客户端,通常在这里把遵循语言文法规则的表达式转换成为使用解释器对象描述的抽象语法树,然后调用解释操作。建树的操作也可以封装在Context环境类中。
模式分析:
在解释器模式中,每一种终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一条文法规则,所以系统将具有较好的灵活性和可扩展性。
对于所有的终结符和非终结符,我们首先需要抽象出一个公共父类,即抽象表达式类,其典型代码如下所示:
public abstract class AbstractExpression { public abstract void interpret(Context ctx); }
终结符表达式和非终结符表达式类都是抽象表达式类的子类,对于终结符表达式,其代码很简单,主要是对终结符元素的处理,其典型代码如下所示:
public class TerminalExpression extends AbstractExpression { public void interpret(Context ctx) { //对于终结符表达式的解释操作 } }
对于非终结符表达式,其代码相对比较复杂,因为可以通过非终结符将表达式组合成更加复杂的结构,对于包含两个操作元素的非终结符表达式类,其典型代码如下
public class NonterminalExpression extends AbstractExpression { private AbstractExpression left; private AbstractExpression right; public NonterminalExpression(AbstractExpression left,AbstractExpression right) { this.left=left; this.right=right; } public void interpret(Context ctx) { //递归调用每一个组成部分的interpret()方法 //在递归调用时指定组成部分的连接方式,即非终结符的功能 } }
环境类Context用于存储一些全局信息,通常包含一个HashMap或ArrayList等类型的集合对象(也可以直接由HashMap等集合类充当环境类),存储一系列公共信息,
如变量名与值的映射关系(key/value)等,用于在进行具体的解释操作时从中获取相关信息。其典型代码如下:
public class Context { private HashMap map = new HashMap(); public void assign(String key, String value) { //往环境类中设值 } public String lookup(String key) { //获取存储在环境类中的值 } }
客户类Client的典型代码如下:
public class Client { //主要按照文法规则对特定的句子构建抽象语法树 //然后调用解释操作 }
模式分析:
解释器模式的功能:解释器模式使用解释器对象来表示和处理相应的文法规则,一般一个解释器对象处理一条文法规则。
理论上来说,只要能用解释器对象把符合文法规则的表达式表示出来,而且能够构成抽象的语法树,那都可以使用解释器模式来处理。
文法规则和解释器之间是有对应关系的,一般一个解释器处理一条文法规则,但是反过来并不成立,一条文法规则是可以有多种解释和处理的,也就是一条文法规则可以对应多个解释器对象。
上下文在解释器模式中起到非常重要的作用,由于上下文会被传递到所有的解释器中,因此可以在上下文中存储和访问解释器的状态,比如前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象里面都可以调用。
在客户端构建抽象语法树,往往是比较麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。
如果文法规则简单,构建抽象语法树就不是特别困难的事,如果文法规则特别复杂,构建解释器模式需要的抽象语法树的工作是非常艰巨,解释器模式就不太适合。
解释器模式实例:
实例:数学运算解释器,现需要构造一个语言解释器,使得系统可以执行整数间的乘、除和求模运算。如用户输入表达式“3 * 4 / 2 % 4”,输出结果为2。使用解释器模式实现该功能。
实例结构:
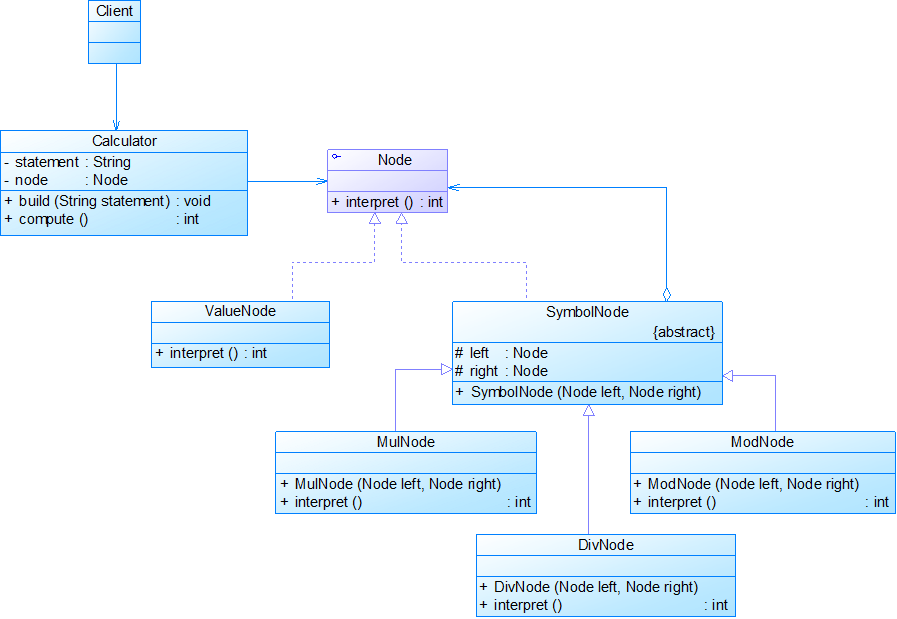
实例代码:
//================= public interface Node { public int interpret(); } //=============== public class ValueNode implements Node { private int value; public ValueNode(int value) { this.value=value; } public int interpret() { return this.value; } } //====================== public class DivNode extends SymbolNode { public DivNode(Node left,Node right) { super(left,right); } public int interpret() { return super.left.interpret() / super.right.interpret(); } } //===================== public abstract class SymbolNode implements Node { protected Node left; protected Node right; public SymbolNode(Node left,Node right) { this.left=left; this.right=right; } } //==================== public class ModNode extends SymbolNode { public ModNode(Node left,Node right) { super(left,right); } public int interpret() { return super.left.interpret() % super.right.interpret(); } } //===================== public class MulNode extends SymbolNode { public MulNode(Node left,Node right) { super(left,right); } public int interpret() { return super.left.interpret() * super.right.interpret(); } } //=========================== public class DivNode extends SymbolNode { public DivNode(Node left,Node right) { super(left,right); } public int interpret() { return super.left.interpret() / super.right.interpret(); } } //=========================== import java.util.*; public class Calculator { private String statement; private Node node; public void build(String statement) { Node left=null,right=null; Stack stack=new Stack(); String[] statementArr=statement.split(" "); for(int i=0;i<statementArr.length;i++) { if(statementArr[i].equalsIgnoreCase("*")) { left=(Node)stack.pop(); int val=Integer.parseInt(statementArr[++i]); right=new ValueNode(val); stack.push(new MulNode(left,right)); } else if(statementArr[i].equalsIgnoreCase("/")) { left=(Node)stack.pop(); int val=Integer.parseInt(statementArr[++i]); right=new ValueNode(val); stack.push(new DivNode(left,right)); } else if(statementArr[i].equalsIgnoreCase("%")) { left=(Node)stack.pop(); int val=Integer.parseInt(statementArr[++i]); right=new ValueNode(val); stack.push(new ModNode(left,right)); } else { stack.push(new ValueNode(Integer.parseInt(statementArr[i]))); } } this.node=(Node)stack.pop(); } public int compute() { return node.interpret(); } } //======================== public class Client { public static void main(String args[]) { String statement = "3 * 2 * 4 / 6 % 5"; Calculator calculator = new Calculator(); calculator.build(statement); int result = calculator.compute(); System.out.println(statement + " = " + result); } }
解释器模式的注意事项和细节
1) 当有一个语言需要解释执行,可将该语言中的句子表示为一个抽象语法树,就可以 考虑使用解释器模式,让程序具有良好的扩展性
2) 应用场景:编译器、运算表达式计算、正则表达式、机器人等
3) 使用解释器可能带来的问题:解释器模式会引起类膨胀、解释器模式采用递归调用 方法,将会导致调试非常复杂、效率可能降低.
状态模式:
“人有悲欢离合,月有阴晴圆缺”,包括人在内,很多事物都具有多种状态,而且在不同状态下会具有不同的行为,这些状态在特定条件下还将发生相互转换。
就像水,它可以凝固成冰,也可以受热蒸发后变成水蒸汽,水可以流动,冰可以雕刻,蒸汽可以扩散。
在UML中可以使用状态图来描述对象状态的变化。

在软件系统中,有些对象也像水一样具有多种状态,这些状态在某些情况下能够相互转换,而且对象在不同的状态下也将具有不同的行为。
为了更好地对这些具有多种状态的对象进行设计,我们将学习用于描述对象状态及其转换的状态模式。
模式定义:
状态模式(State Pattern):允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。其别名为状态对象(Objects for States),状态模式是一种对象行为型模式。
状态模式用于解决系统中复杂对象的状态转换以及不同状态下行为的封装问题。状态模式将一个对象的状态从该对象中分离出来,封装到专门的状态类中,
使得对象状态可以灵活变化,对于客户端而言,无须关心对象状态的转换以及对象所处的当前状态,无论对于何种状态的对象,客户端都可以一致处理。
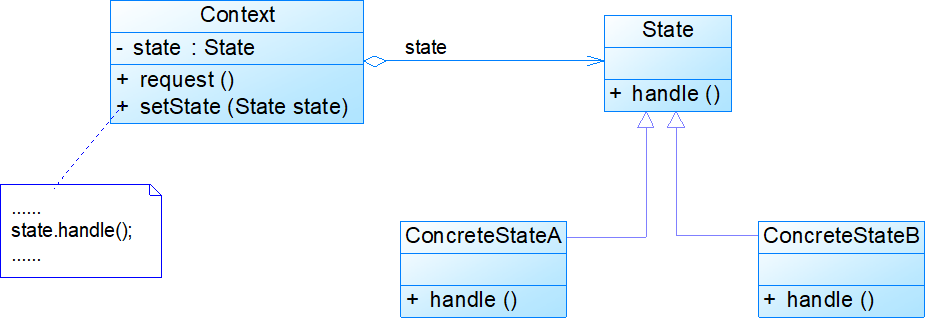
Context:环境类,又称为上下文类,它是拥有多种状态的对象。由于环境类的状态存在多样性且在不同状态下对象的行为有所不同,
因此将状态独立出去形成单独的状态类。在环境类中维护一个抽象状态类State的实例,这个实例定义当前状态,在具体实现时,它是一个State子类的对象。
State:抽象状态类,它用于定义一个接口以封装与环境类的一个特定状态相关的行为,在抽象状态类中声明了各种不同状态对应的方法,
而在其子类中实现类这些方法,由于不同状态下对象的行为可能不同,因此在不同子类中方法的实现可能存在不同,相同的方法可以写在抽象状态类中。
ConcreteState:具体状态类,它是抽象状态类的子类,每一个子类实现一个与环境类的一个状态相关的行为,每一个具体状态类对应环境的一个具体状态,不同的具体状态类其行为有所不同。
模式分析:
状态模式的关键是引入了一个抽象类来专门表示对象的状态,而对象的每一种具体状态类都继承了该类,并在不同具体状态类中实现了不同状态的行为,包括各种状态之间的转换。
典型的抽象状态类代码如下所示:
abstract class State { //声明抽象业务方法,不同的具体状态类可以不同的实现 public abstract void handle(); }
具体状态类中实现了在抽象状态类中声明的业务方法,在实际使用时,可能包含多个业务方法,如果某些业务方法的实现完全相同,可以将这些方法移至抽象状态类,实现代码的复用。典型的具体状态类代码如下:
class ConcreteState extends State { public void handle() { //方法具体实现代码 } }
环境类维持一个对抽象状态类的引用,典型代码如下所示:
class Context { private State state; //维持一个对抽象状态对象的引用 private int value; //其他属性值,该属性值的变化可能会导致对象状态发生变化 public void setState(State state) { //注入不同的具体状态对象 this.state = state; } public void request() { //其他代码 state.handle(); //调用状态对象的业务方法 //其他代码 } }
模式分析:
环境类实际上是真正拥有状态的对象,我们只是将环境类中与状态有关的代码提取出来封装到专门的状态类中。
在状态模式结构图中,环境类Context与抽象状态类State之间存在单向关联关系,在Context中定义了一个State对象。在实际使用时,
它们之间可能存在更为复杂的关系,State与Context之间可能也存在依赖或者关联关系。
在状态模式的使用过程中,一个对象的状态之间还可以进行相互转换,通常有两种实现状态转换的方式。
(1) 统一由环境类来负责状态之间的转换,此时,它充当了状态管理器(State Manager)角色,在它的业务方法中通过对某些属性值的判断实现状态转换,
还可以提供一个专门的方法用于实现属性判断和状态转换,如下代码段所示:
public void changeState() { if (value == 0) { //判断属性值,根据属性值进行状态转换 this.setState(new ConcreteStateA()); } else if (value == 1) { this.setState(new ConcreteStateB()); } }
(2) 由具体状态类来负责状态之间的转换,可以在其业务方法中判断环境类的某些属性值为它设置新的状态对象,实现状态转换,
也可以提供一个专门的方法来负责属性判断和状态转换。此时,两者之间就存在依赖或关联关系。
public void changeState(Context ctx) { if (ctx.getValue() == 1) { //根据环境对象中的属性值进行状态转换 ctx.setState(new ConcreteStateB()); } else if (ctx.getValue() == 2) { ctx.setState(new ConcreteStateC()); } }
状态类的产生是由于环境类存在多个状态,同时还满足两个条件:这些状态经常需要切换,在不同的状态下对象的行为不同。
因此可以将不同状态下的行为单独提取出来封装在具体的状态类中,使得环境类对象在其内部状态改变时可以改变它的行为,对象看起来似乎修改了它的类,
而实际上是通过切换到不同的具体状态类实现的。由于环境类可以设置为任一具体状态类,因此它针对抽象状态类进行编程,
在程序运行时可以将任一具体状态类的对象设置到环境类中,从而使得环境类可以改变内部状态,并且改变行为。
状态模式实例:
实例一:论坛用户等级。在某论坛系统中,用户可以发表留言,发表留言将增加积分;用户也可以回复留言,回复留言也将增加积分;
用户还可以下载文件,下载文件将扣除积分。该系统用户分为三个等级,分别是新手、高手和专家,这三个等级对应三种不同的状态,这三种状态分别定义如下:
(1) 如果积分小于100分,则为新手状态,用户可以发表留言、回复留言,但是不能下载文件。
(2) 如果积分大于等于100分但小于1000分,则为高手状态,用户可以发表留言、回复留言,还可以下载文件,而且用户在发表留言时可以获取双倍积分。
如果下载文件后积分小于0,则不能下载该文件。
(3) 如果积分大于等于1000分,则为专家状态,用户可以发表留言、回复留言和下载文件,用户除了在发表留言时可以获取双倍积分外,
下载文件只扣除所需积分的一半。如果下载文件后积分小于0,则不能下载该文件。
实例结构:
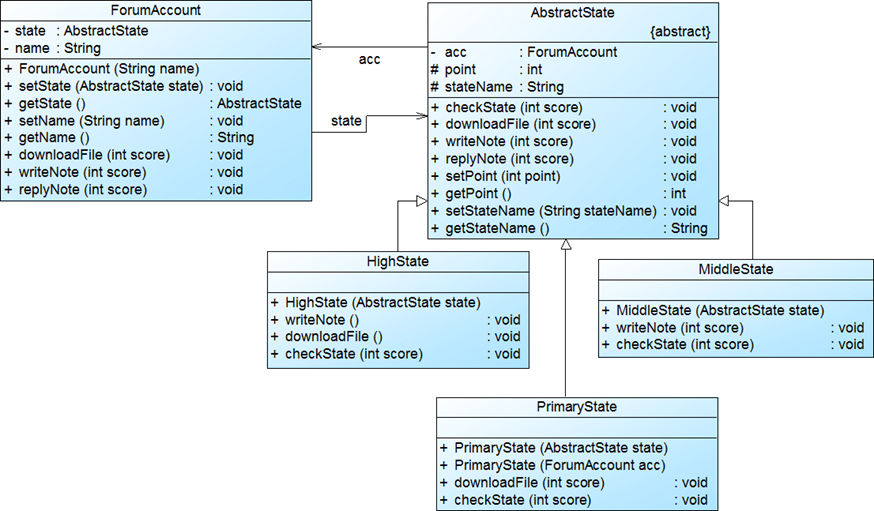
实例代码:
//================== //抽象状态类,除了基本的积分和称号,还有对环境类的引用,这是为了方便当状态类发生变化时,在状态类中,就能改变环境类中的状态类 public abstract class AbstractState { protected ForumAccount acc; protected int point; protected String stateName; public abstract void checkState(int score); //设置为抽象类,是检查完当前积分,直接修改环境类状态(更改称号,保留对环境类的引用与积分) public void downloadFile(int score) { System.out.println(acc.getName() + "下载文件,扣除" + score + "积分。"); this.point-=score; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void writeNote(int score) { System.out.println(acc.getName() + "发布留言" + ",增加" + score + "积分。"); this.point+=score; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void replyNote(int score) { System.out.println(acc.getName() + "回复留言,增加" + score + "积分。"); this.point+=score; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void setPoint(int point) { this.point = point; } public int getPoint() { return (this.point); } public void setStateName(String stateName) { this.stateName = stateName; } public String getStateName() { return (this.stateName); } } //====================== //环境类,用户论坛信息。有对状态抽象类的引用,因为环境类方法内部会调用状态类的方法来实现 //用户名不随状态改编,不必放到状态类中 public class ForumAccount { private AbstractState state; private String name; public ForumAccount(String name) { this.name=name; this.state=new PrimaryState(this); System.out.println(this.name + "注册成功!"); System.out.println("---------------------------------------------"); } public void setState(AbstractState state)//需要调整状态类的引用 { this.state=state; } public AbstractState getState() { return this.state; } public void setName(String name) { this.name=name; } public String getName() { return this.name; } public void downloadFile(int score) { state.downloadFile(score); } public void writeNote(int score) { state.writeNote(score); } public void replyNote(int score) { state.replyNote(score); } } //================= //具体状态类 public class PrimaryState extends AbstractState { public PrimaryState(AbstractState state) { this.acc=state.acc; this.point=state.getPoint(); this.stateName="新手"; } public PrimaryState(ForumAccount acc) { this.point=0; this.acc=acc; this.stateName="新手"; } public void downloadFile(int score)//重写了该方法,因为新手没有下载权限 { System.out.println("对不起," + acc.getName() + ",您没有下载文件的权限!"); } public void checkState(int score)//每次执行与积分相关的操作,都要检查自己的积分处于什么状态,让环境类指向这个类型的状态类。 { if(point>=1000) { acc.setState(new HighState(this)); } else if(point>=100) { acc.setState(new MiddleState(this)); } } } //================= public class MiddleState extends AbstractState { public MiddleState(AbstractState state) { this.acc=state.acc; this.point=state.getPoint(); this.stateName="高手"; } public void writeNote(int score) { System.out.println(acc.getName() + "发布留言" + ",增加" + score + "*2个积分。"); this.point+=score*2; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void checkState(int score) { if(point>=1000) { acc.setState(new HighState(this)); } else if(point<0) { System.out.println("余额不足,文件下载失败!"); this.point+=score; } else if(point<=100) { acc.setState(new PrimaryState(this)); } } } /============================= public class HighState extends AbstractState { public HighState(AbstractState state) { this.acc=state.acc; this.point=state.getPoint(); this.stateName="专家"; } public void writeNote(int score) { System.out.println(acc.getName() + "发布留言" + ",增加" + score + "*2个积分。"); this.point+=score*2; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void downloadFile(int score) { System.out.println(acc.getName() + "下载文件,扣除" + score + "/2积分。"); this.point-=score/2; checkState(score); System.out.println("剩余积分为:" + this.point + ",当前级别为:" + acc.getState().stateName + "。"); } public void checkState(int score) { if(point<0) { System.out.println("余额不足,文件下载失败!"); this.point+=score; } else if(point<=100) { acc.setState(new PrimaryState(this)); } else if(point<=1000) { acc.setState(new MiddleState(this)); } } } //================== //Client端的调用,状态类对客户端是隐藏的,客户端看来论坛账户是可以自动更改状态,并且执行对应的状态下的权限方法。 public class Client { public static void main(String args[]) { ForumAccount account=new ForumAccount("张三"); account.writeNote(20); System.out.println("--------------------------------------"); account.downloadFile(20); System.out.println("--------------------------------------"); account.replyNote(100); System.out.println("--------------------------------------"); account.writeNote(40); System.out.println("--------------------------------------"); account.downloadFile(80); System.out.println("--------------------------------------"); account.downloadFile(150); System.out.println("--------------------------------------"); account.writeNote(1000); System.out.println("--------------------------------------"); account.downloadFile(80); System.out.println("--------------------------------------"); } }
状态模式的注意事项和细节
1) 代码有很强的可读性。状态模式将每个状态的行为封装到对应的一个类中
2) 方便维护。将容易产生问题的if-else语句删除了,如果把每个状态的行为都放到一 个类中,每次调用方法时都要判断当前是什么状态,不但会产出很多if-else语句, 而且容易出错。
3) 符合“开闭原则”。容易增删状态
4) 会产生很多类。每个状态都要一个对应的类,当状态过多时会产生很多类,加大维护难度
5) 应用场景:当一个事件或者对象有很多种状态,状态之间会相互转换,对不同的状态要求有不同的行为的时候,可以考虑使用状态模式.
策略模式:
俗话说:条条大路通罗马。在很多情况下,实现某个目标的途径不止一条,例如我们在外出旅游时可以选择多种不同的出行方式,
如骑自行车、坐汽车、坐火车或者坐飞机,可根据实际情况(目的地、旅游预算、旅游时间等)来选择一种最适合的出行方式。
完成一项任务,往往可以有多种不同的方式,每一种方式称为一个策略,我们可以根据环境或者条件的不同选择不同的策略来完成该项任务。
在软件开发中也常常遇到类似的情况,实现某一个功能有多个途径,此时可以使用一种设计模式来使得系统可以灵活地选择解决途径,也能够方便地增加新的解决途径。
在软件系统中,要实现如查找/排序的功能,有许多算法可以实现。一种常用的方法是硬编码(Hard Coding)在一个类中,如需要提供多种查找算法,
可以将这些算法写到一个类中,在该类中提供多个方法,每一个方法对应一个具体的查找算法;当然也可以将这些查找算法封装在一个统一的方法中,
通过if…else…等条件判断语句来进行选择。这两种实现方法我们都可以称之为硬编码,如果需要增加一种新的查找算法,需要修改封装算法类的源程序;
更换查找算法,也需要修改客户端调用代码。在这个算法类中封装了大量查找算法,该类代码将较复杂,维护较为困难。
除了提供专门的查找算法类之外,还可以在客户端程序中直接包含算法代码,这种做法更不可取,将导致客户端程序庞大而且难以维护,如果存在大量可供选择的算法时问题将变得更加严重。
为了解决这些问题,可以定义一些独立的类来封装不同的算法,每一个类封装一个具体算法,
在这里,每一个封装算法的类都可以称之为策略(Strategy),为了保证这些策略的一致性,一般会用一个抽象的策略类来做算法的定义,而具体每种算法则对应于一个具体策略类。
模式定义:
策略模式(Strategy Pattern):定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化,也称为政策模式(Policy)。策略模式是一种对象行为型模式。
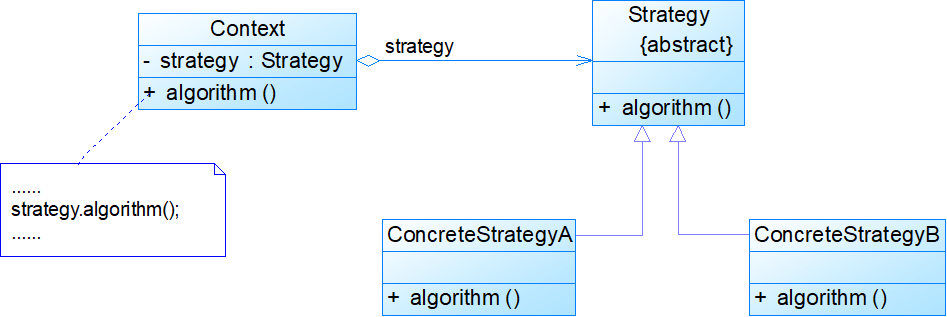
Context:环境类是使用算法的角色,它在解决某个问题(即实现某个方法)时可以采用多种策略。在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略。
Strategy:抽象策略类为所支持的算法声明了抽象方法,是所有策略类的父类,它可以是抽象类或具体类,也可以是接口。环境类通过抽象策略类中声明的方法在运行时调用具体策略类中实现的算法。
ConcreteStrategy:具体策略类实现了在抽象策略类中声明的算法,运行时具体策略对象将覆盖环境类中定义的抽象策略对象,使用一种具体的算法实现某个业务处理。
策略模式是一个比较容易理解和使用的设计模式,策略模式是对算法的封装,它把算法的责任和算法本身分割开,委派给不同的对象管理。策略模式通常把一个系列的算法封装到一系列具体策略类里面,作为抽象策略类的子类。环境类是需
要使用算法的类。在一个系统中可以存在多个环境类,它们可能需要重用一些相同的算法。
使用策略模式时,需要将算法从Context类中提取出来,首先应该创建一个抽象策略类,其典型代码如下所示:
abstract class AbstractStrategy { public abstract void algorithm(); //声明抽象算法 }
然后再将封装每一种具体算法的类作为该抽象策略类的子类,如下代码所示:
class ConcreteStrategyA extends AbstractStrategy { //算法的具体实现 public void algorithm() { //算法A } }
对于Context类而言,在它与抽象策略类之间建立一个关联关系,其典型代码如下所示:
在Context类中定义一个AbstractStrategy类型的对象strategy,通过注入的方式在客户端传入一个具体策略对象
class Context { private AbstractStrategy strategy; //维持一个对抽象策略类的引用 public void setStrategy(AbstractStrategy strategy) { this.strategy= strategy; } //调用策略类中的算法 public void algorithm() { strategy.algorithm(); } }
客户端代码片段如下所示:
在客户端代码中只需注入一个具体策略对象,可以将具体策略类类名存储在配置文件中,通过反射来动态创建具体策略对象,从而使得用户可以灵活地更换具体策略类,增加新的具体策略类也很方便。
…… Context context = new Context(); AbstractStrategy strategy; strategy = new ConcreteStrategyA(); //可在运行时指定类型 context.setStrategy(strategy); context.algorithm(); ……
策略模式实例:
实例:排序策略
某系统提供了一个用于对数组数据进行操作的类,该类封装了对数组的常见操作,如查找数组元素、对数组元素进行排序等。现以排序操作为例,使用策略模式设计该数组操作类,使得客户端可以动态地更换排序算法,可以根据需要选择冒泡排序或选择排序或插入排序,也能够灵活地增加新的排序算法。
实例结构: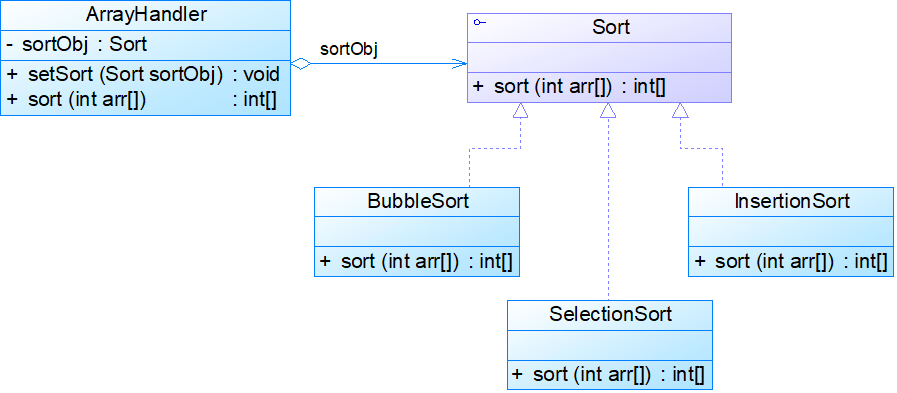
实例代码:
//================== //排序策略接口 public interface Sort { public abstract int[] sort(int arr[]); } //=============== //排序具体实现 public class SelectionSort implements Sort { public int[] sort(int arr[]) { int len=arr.length; int temp; for(int i=0;i<len;i++) { temp=arr[i]; int j; int samllestLocation=i; for(j=i+1;j<len;j++) { if(arr[j]<temp) { temp=arr[j]; samllestLocation=j; } } arr[samllestLocation]=arr[i]; arr[i]=temp; } System.out.println("选择排序"); return arr; } } //================== public class QuickSort implements Sort { public int[] sort(int arr[]) { System.out.println("快速排序"); sort(arr,0,arr.length-1); return arr; } public void sort(int arr[],int p, int r) { int q=0; if(p<r) { q=partition(arr,p,r); sort(arr,p,q-1); sort(arr,q+1,r); } } public int partition(int[] a, int p, int r) { int x=a[r]; int j=p-1; for(int i=p;i<=r-1;i++) { if(a[i]<=x) { j++; swap(a,j,i); } } swap(a,j+1,r); return j+1; } public void swap(int[] a, int i, int j) { int t = a[i]; a[i] = a[j]; a[j] = t; } } //================ public class InsertionSort implements Sort { public int[] sort(int arr[]) { int len=arr.length; for(int i=1;i<len;i++) { int j; int temp=arr[i]; for(j=i;j>0;j--) { if(arr[j-1]>temp) { arr[j]=arr[j-1]; }else break; } arr[j]=temp; } System.out.println("插入排序"); return arr; } } //================= public class BubbleSort implements Sort { public int[] sort(int arr[]) { int len=arr.length; for(int i=0;i<len;i++) { for(int j=i+1;j<len;j++) { int temp; if(arr[i]>arr[j]) { temp=arr[j]; arr[j]=arr[i]; arr[i]=temp; } } } System.out.println("冒泡排序"); return arr; } } //=============== //环境类,在里面使用排序策略接口 public class ArrayHandler { private Sort sortObj; public int[] sort(int arr[]) { sortObj.sort(arr); return arr; } public void setSortObj(Sort sortObj) { this.sortObj = sortObj; } } //================= Client使用 public class Client { public static void main(String args[]) { int arr[]={1,4,6,2,5,3,7,10,9}; int result[]; ArrayHandler ah=new ArrayHandler(); Sort sort; sort=(Sort)XMLUtil.getBean(); ah.setSortObj(sort); //设置具体策略 result=ah.sort(arr); for(int i=0;i<result.length;i++) { System.out.print(result[i] + ","); } } }
策略模式的注意事项和细节
1) 策略模式的关键是:分析项目中变化部分与不变部分
2) 策略模式的核心思想是:多用组合/聚合 少用继承;用行为类组合,而不是行为的继承。更有弹性
3) 体现了“对修改关闭,对扩展开放”原则,客户端增加行为不用修改原有代码,只要添加一种策略(或者行为)即可,避免了使用多重转移语句(if..else if..else)
4) 提供了可以替换继承关系的办法: 策略模式将算法封装在独立的Strategy类中使得你可以独立于其Context改变它,使它易于切换、易于理解、易于扩展
5) 需要注意的是:每添加一个策略就要增加一个类,当策略过多是会导致类数目庞大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号