

Hive sql
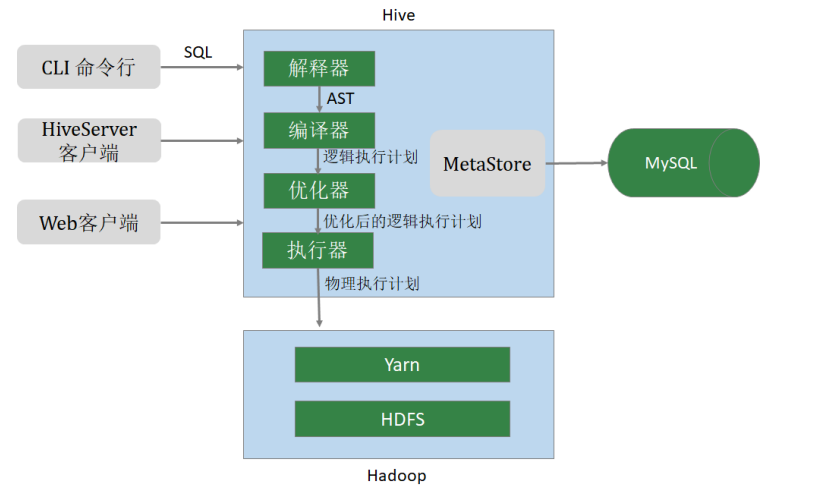
hive 架构
hive 数据类型分基本数据类型 和集合数据类型
隐式转换:
hive> select '1.0'+2; // 数字字符串转double OK 3.0 hive> select '1111' > 10; hive> select 1 > 0.8;
显式转换:
hive> select cast('1111s' as int); OK NULL hive> select cast('1111' as int); OK 1111
集合数据类型:
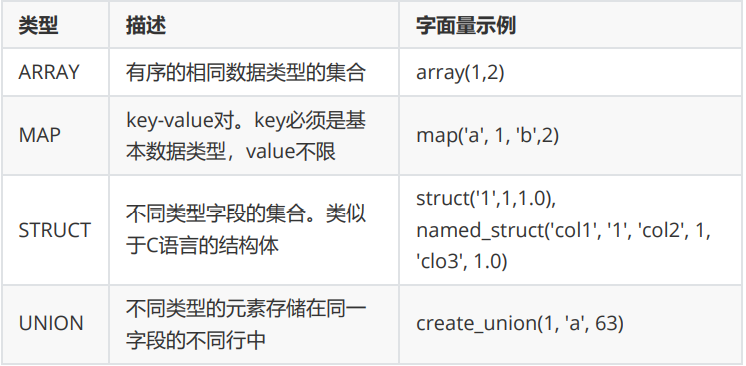
集合测试:
hive> select array(1,2,3); OK [1,2,3] -- 使用 [] 访问数组元素 hive> select arr[0] from (select array(1,2,3) arr) tmp; hive> select map('a', 1, 'b', 2, 'c', 3); OK {"a":1,"b":2,"c":3} -- 使用 [] 访问map元素 hive> select mymap["a"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp; -- 使用 [] 访问map元素。 key 不存在返回 NULL hive> select mymap["x"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp; NULL hive> select struct('username1', 7, 1288.68); OK {"col1":"username1","col2":7,"col3":1288.68} -- 给 struct 中的字段命名 hive> select named_struct("name", "username1", "id", 7, "salary", 12880.68); OK {"name":"username1","id":7,"salary":12880.68} -- 使用 列名.字段名 访问具体信息 hive> select userinfo.id > from (select named_struct("name", "username1", "id", 7, "salary", 12880.68) userinfo) tmp; -- union 数据类型 hive> select create_union(0, "zhansan", 19, 8000.88) uinfo;
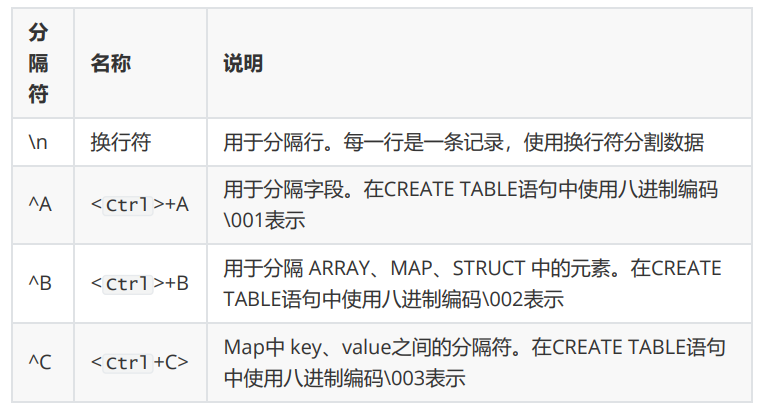
Hive 默认分隔符:
Hive DDL:
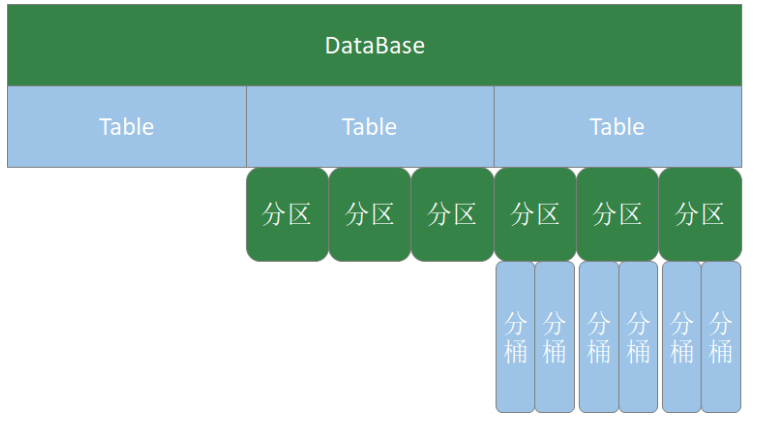
创建数据库:
-- 创建数据库,在HDFS上存储路径为 /user/hive/warehouse/*.db hive (default)> create database mydb; hive (default)> dfs -ls /user/hive/warehouse; -- 避免数据库已经存在时报错,使用 if not exists 进行判断【标准写法】 hive (default)> create database if not exists mydb; -- 创建数据库。添加备注,指定数据库在存放位置 hive (default)> create database if not exists mydb2 comment 'this is mydb2' location '/user/hive/mydb2.db';
查看数据库:
-- 查看所有数据库 show database; -- 查看数据库信息 desc database mydb2; desc database extended mydb2; describe database extended mydb2;
使用数据库:
use mydb;
删除数据库:
-- 删除一个空数据库 drop database databasename; -- 如果数据库不为空,使用 cascade 强制删除 drop database databasename cascade; //慎用,防止删库跑路
创建表:
语法:
create [external] table [IF NOT EXISTS] table_name [(colName colType [comment 'comment'], ...)] [comment table_comment] [partition by (colName colType [comment col_comment], ...)] [clustered BY (colName, colName, ...) [sorted by (col_name [ASC|DESC], ...)] into num_buckets buckets] [row format row_format] [stored as file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]; CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path];
字段解释:
1. CREATE TABLE。按给定名称创建表,如果表已经存在则抛出异常。可使用if not exists 规避。 2. EXTERNAL关键字。创建外部表,否则创建的是内部表(管理表)。 删除内部表时,数据和表的定义同时被删除; 删除外部表时,仅仅删除了表的定义,数据保留; 在生产环境中,多使用外部表; 3. comment。表的注释 4. partition by。对表中数据进行分区,指定表的分区字段 5. clustered by。创建分桶表,指定分桶字段 6. sorted by。对桶中的一个或多个列排序,较少使用
存储子句:
ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
7.stored as TEXTFILE ORC PARQUET
8.LOCATION。表在HDFS上的存放位置
9.AS。后面可以接查询语句,表示根据后面的查询结果创建表
create table xxx as select ... 这种方式不会复制分区,分桶
10.like 复制表结构,不复制数据
内部表 & 外部表:
- 内部表、管理表 表和数据绑定,一起删除
- 外部表,删除表不影响数据
-- 内部表转外部表 alter table t1 set tblproperties('EXTERNAL'='TRUE'); -- 查询表信息,是否转换成功 desc formatted t1; -- 外部表转内部表。EXTERNAL 大写,false 不区分大小 alter table t1 set tblproperties('EXTERNAL'='FALSE'); -- 查询表信息,是否转换成功 desc formatted t1;

分区表:
为了避免全表扫描,将数据存储在不同子目录中,每个子目录对应一个分区
分区表创建与数据加载示例:
-- 创建表 create table if not exists t3( id int ,name string ,hobby array<string> ,addr map<String,string> ) partitioned by (dt string) row format delimited fields terminated by ';' collection items terminated by ',' map keys terminated by ':'; -- 加载数据。 load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt="2020-06-01"); load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt="2020-06-02");
备注:分区字段不是表中已经存在的数据,可以将分区字段看成伪列
修复分区:msck repair table 表名 ,先有分区和数据,后有表
查看分区:
show partitions t3;
新增分区并设置数据:
-- 增加一个分区,不加载数据 alter table t3 add partition(dt='2020-06-03'); -- 增加多个分区,不加载数据 alter table t3 add partition(dt='2020-06-05') partition(dt='2020-06-06'); -- 增加多个分区。准备数据 hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01 /user/hive/warehouse/mydb.db/t3/dt=2020-06-07 hdfs dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2020-06-01 /user/hive/warehouse/mydb.db/t3/dt=2020-06-08 -- 增加多个分区。加载数据 alter table t3 add partition(dt='2020-06-07') location '/user/hive/warehouse/mydb.db/t3/dt=2020-06-07' partition(dt='2020-06-08') location '/user/hive/warehouse/mydb.db/t3/dt=2020-06-08'; -- 查询数据 select * from t3
修改分区的hdfs 路径:
alter table t3 partition(dt='2020-06-01') set location '/user/hive/warehouse/t3/dt=2020-06-03';
删除分区:
-- 可以删除一个或多个分区,用逗号隔开 alter table t3 drop partition(dt='2020-06-03'), partition(dt='2020-06-04');
分桶表:
当单个的分区或者表的数据量过大,分区不能更细粒度的划分数据,就需要使用分桶。
分桶原理:分桶字段.hashCode % 分桶个数
分桶表测试:
create table course( id int, name string, score int ) clustered by (id) into 3 buckets row format delimited fields terminated by "\t";
-- 创建普通表 create table course_common( id int, name string, score int ) row format delimited fields terminated by "\t"; -- 普通表加载数据 load data local inpath '/home/hadoop/data/course.dat' into table course_common; -- 通过 insert ... select ... 给桶表加载数据 insert into table course select * from course_common; -- 观察分桶数据。数据按照:(分区字段.hashCode) % (分桶数) 进行分区
备注:
- 分桶规则:分桶字段.hashCode % 分桶数
- 分桶表加载数据时,使用 insert... select ... 方式进行
- 网上有资料说要使用分区表需要设置 hive.enforce.bucketing=true,那是Hive 1.x 以前的版本;Hive 2.x 中,删除了该参数,始终可以分桶;
修改表 & 删除表:
-- 修改表名。rename alter table course_common rename to course_common1; -- 修改列名。change column alter table course_common1 change column id cid int; -- 修改字段类型。change column alter table course_common1 change column cid cid string; -- The following columns have types incompatible with the existing columns in their respective positions -- 修改字段数据类型时,要满足数据类型转换的要求。如int可以转为string,但是 string不能转为int -- 增加字段。add columns alter table course_common1 add columns (common string); -- 删除字段:replace columns -- 这里仅仅只是在元数据中删除了字段,并没有改动hdfs上的数据文件 alter table course_common1 replace columns( id string, cname string, score int); -- 删除表 drop table course_common1;
数据导入:
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL:
- LOAD DATA LOCAL ... 从本地文件系统加载数据到Hive表中。本地文件会拷 贝到Hive表指定的位置
- LOAD DATA ... 从HDFS加载数据到Hive表中。HDFS文件移动到Hive表指定 的位置
- INPATH:加载数据的路径
- OVERWRITE:覆盖表中已有数据;否则表示追加数据
- PARTITION:将数据加载到指定的分区
插入数据:
常用于从普通表插入数据到分区表,或orc ,parquet 存储格式的表
-- 插入数据 insert into table tabC partition(month='202001') values (5, 'wangwu', 'BJ'), (4, 'lishi', 'SH'), (3, 'zhangsan', 'TJ'); -- 插入查询的结果数据 insert into table tabC partition(month='202002') select id, name, area from tabC where month='202001'; -- 多表(多分区)插入模式 from tabC insert overwrite table tabC partition(month='202003') select id, name, area where month='202002' insert overwrite table tabC partition(month='202004') select id, name, area where month='202002'; // from 提前,这样可以减少hive sql的stage
创建表并插入数据:
-- 根据查询结果创建表 create table if not exists tabD as select * from tabC;
数据导出:
-- 将查询结果导出到本地 insert overwrite local directory '/home/hadoop/data/tabC' select * from tabC; -- 将查询结果格式化输出到本地 insert overwrite local directory '/home/hadoop/data/tabC2' row format delimited fields terminated by ' ' select * from tabC; -- 将查询结果导出到HDFS insert overwrite directory '/user/hadoop/data/tabC3' row format delimited fields terminated by ' ' select * from tabC; -- dfs 命令导出数据到本地。本质是执行数据文件的拷贝 dfs -get /user/hive/warehouse/mydb.db/tabc/month=202001 /home/hadoop/data/tabC4
-- hive 命令导出数据到本地。执行查询将查询结果重定向到文件 hive -e "select * from tabC" > a.log -- export 导出数据到HDFS。使用export导出数据时,不仅有数还有表的元数据信 息 export table tabC to '/user/hadoop/data/tabC4'; -- export 导出的数据,可以使用 import 命令导入到 Hive 表中 -- 使用 like tname创建的表结构与原表一致。create ... as select ... 结构可能不一致 create table tabE like tabc; import table tabE from ''/user/hadoop/data/tabC4'; -- 截断表,清空数据。(注意:仅能操作内部表) truncate table tabE; -- 以下语句报错,外部表不能执行 truncate 操作 alter table tabC set tblproperties("EXTERNAL"="TRUE"); truncate table tabC;
Hive DQL :
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT [offset,] rows]
基本查询:
-- 省略from子句的查询 select 8*888 ; select current_date ; -- 使用列别名 select 8*888 product; select current_date as currdate; -- 全表查询 select * from emp; -- 选择特定列查询 select ename, sal, comm from emp; -- 使用函数 select count(*) from emp; -- count(colname) 按字段进行count,不统计NULL select sum(sal) from emp; select max(sal) from emp; select min(sal) from emp; select avg(sal) from emp; -- 使用limit子句限制返回的行数 select * from emp limit 3;
where 子句:
where 字句中不能使用列的别名
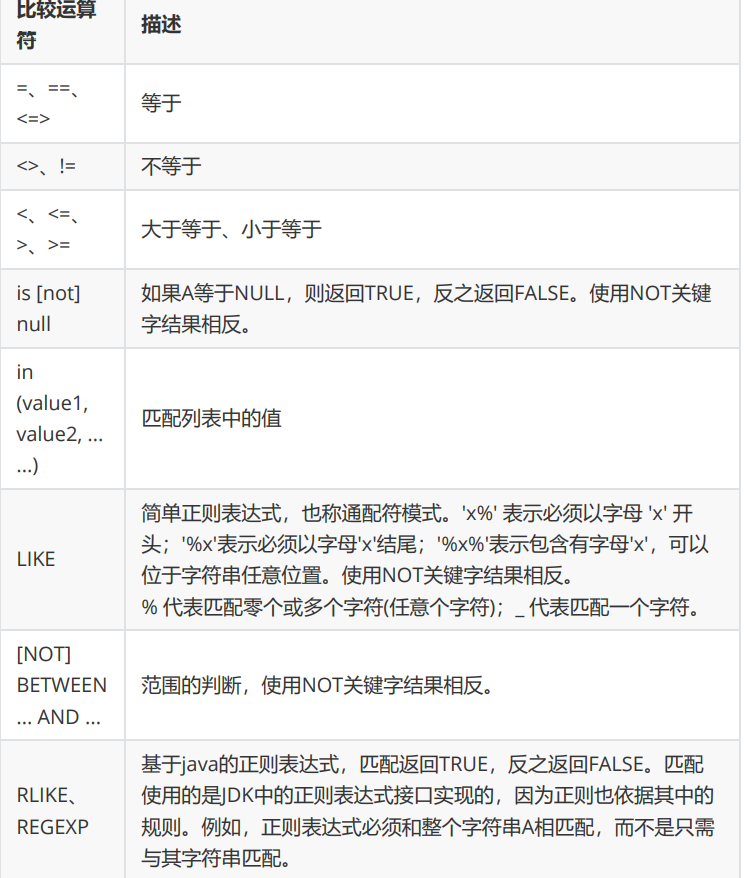
rlike 可以写正则表达式。
group by 字句:
-- 计算emp表每个部门的平均工资 select deptno, avg(sal) from emp group by deptno; -- 计算emp每个部门中每个岗位的最高薪水 select deptno, job, max(sal) from emp group by deptno, job;
- where 针对表数据过滤
- having 针对group by的结果过滤
- group by 中不能使用别名
表连接:
1. 内连接: [inner] join 2. 外连接 (outer join) - 左外连接。 left [outer] join,左表的数据全部显示 - 右外连接。 right [outer] join,右表的数据全部显示 - 全外连接。 full [outer] join,两张表的数据都显示
排序字句:
全局排序 order by :
- order by 子句出现在select语句的结尾;
- order by子句对最终的结果进行排序;
- 默认使用升序(ASC);可以使用DESC,跟在字段名之后表示降序;
ORDER BY执行全局排序,只有一个reduce;
-- 普通排序 select * from emp order by deptno; -- 按别名排序 select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm, deptno from emp order by salcomm desc; -- 多列排序 select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm, deptno from emp order by deptno, salcomm desc; -- 排序字段要出现在select子句中。以下语句无法执行(因为select子句中缺少 deptno): select empno, ename, job, mgr, sal + nvl(comm, 0) salcomm from emp order by deptno, salcomm desc;
注意排序字段需要出现在select语句中。
分区排序(distribute by):
结合sort by 使用。 使得结果分区内有序。
-- 启动2个reducer task;先按 deptno 分区,在分区内按 sal+comm 排序 set mapreduce.job.reduces=2; -- 将结果输出到文件,观察输出结果 insert overwrite local directory '/home/hadoop/output/distBy' select empno, ename, job, deptno, sal + nvl(comm, 0) salcomm from emp distribute by deptno sort by salcomm desc;
当distribute by 与 sort by是同一个字段时,可使用cluster by简化语法;
cluster by 只能是升序,不能指定排序规则;
-- 语法上是等价的 select * from emp distribute by deptno sort by deptno; select * from emp cluster by deptno;
Hive 函数:
-- 显示自带函数的用法 desc function upper; desc function extended upper;
日期相关函数:
-- 当前前日期 select current_date; select unix_timestamp(); -- 建议使用current_timestamp,有没有括号都可以 select current_timestamp(); -- 时间戳转日期 select from_unixtime(1505456567); select from_unixtime(1505456567, 'yyyyMMdd'); select from_unixtime(1505456567, 'yyyy-MM-dd HH:mm:ss'); -- 日期转时间戳 select unix_timestamp('2019-09-15 14:23:00'); -- 计算时间差 select datediff('2020-04-18','2019-11-21'); select datediff('2019-11-21', '2020-04-18'); -- 查询当月第几天 select dayofmonth(current_date); -- 计算月末: select last_day(current_date); -- 当月第1天: select date_sub(current_date, dayofmonth(current_date)-1) -- 下个月第1天: select add_months(date_sub(current_date, dayofmonth(current_date)-1), 1) -- 字符串转时间(字符串必须为:yyyy-MM-dd格式) select to_date('2020-01-01'); select to_date('2020-01-01 12:12:12'); -- 日期、时间戳、字符串类型格式化输出标准时间格式 select date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss'); select date_format(current_date(), 'yyyyMMdd'); select date_format('2020-06-01', 'yyyy-MM-dd HH:mm:ss');
-- 计算emp表中,每个人的工龄
select *, round(datediff(current_date, hiredate)/365,1) workingyears from emp;
字符串相关函数:
-- 转小写。lower select lower("HELLO WORLD"); -- 转大写。upper select lower(ename), ename from emp; -- 求字符串长度。length select length(ename), ename from emp; -- 字符串拼接。 concat / || select empno || " " ||ename idname from emp; select concat(empno, " " ,ename) idname from emp; -- 指定分隔符。concat_ws(separator, [string | array(string)]+) SELECT concat_ws('.', 'www', array('lagou', 'com')); select concat_ws(" ", ename, job) from emp; -- 求子串。substr SELECT substr('www.lagou.com', 5); SELECT substr('www.lagou.com', -5); SELECT substr('www.lagou.com', 5, 5); -- 字符串切分。split,注意 '.' 要转义 select split("www.lagou.com", "\\.");
数学相关函数:
-- 四舍五入。round select round(314.15926); select round(314.15926, 2); select round(314.15926, -2); -- 向上取整。ceil select ceil(3.1415926); -- 向下取整。floor select floor(3.1415926);
条件函数:
-- if (boolean testCondition, T valueTrue, T valueFalseOrNull) select sal, if (sal<1500, 1, if (sal < 3000, 2, 3)) from emp; -- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END -- 将emp表的员工工资等级分类:0-1500、1500-3000、3000以上 select sal, if (sal<=1500, 1, if (sal <= 3000, 2, 3)) from emp; -- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END -- 复杂条件用 case when 更直观 select sal, case when sal<=1500 then 1 when sal<=3000 then 2 else 3 end sallevel from emp; -- 以下语句等价 select ename, deptno, case deptno when 10 then 'accounting' when 20 then 'research' when 30 then 'sales' else 'unknown' end deptname from emp; select ename, deptno, case when deptno=10 then 'accounting' when deptno=20 then 'research' when deptno=30 then 'sales' else 'unknown' end deptname from emp; -- COALESCE(T v1, T v2, ...)。返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL select sal, coalesce(comm, 0) from emp; -- isnull(a) isnotnull(a) select * from emp where isnull(comm); select * from emp where isnotnull(comm); -- nvl(T value, T default_value) // 如果value 为null,则赋值 default_value
select empno, ename, job, mgr, hiredate, deptno, sal + nvl(comm,0) sumsal from emp;
-- nullif(x, y) 相等为空,否则为a
SELECT nullif("b", "b"), nullif("b", "a");
UDTF 函数:
一行输 入,多行输出。
-- explode,炸裂函数 -- 就是将一行中复杂的 array 或者 map 结构拆分成多行 select explode(array('A','B','C')) as col; select explode(map('a', 8, 'b', 88, 'c', 888)); -- UDTF's are not supported outside the SELECT clause, nor nested in expressions -- SELECT pageid, explode(adid_list) AS myCol... is not supported -- SELECT explode(explode(adid_list)) AS myCol... is not supported -- lateral view 常与 表生成函数explode结合使用 -- lateral view 语法: lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)* fromClause: FROM baseTable (lateralView)* -- lateral view 的基本使用 with t1 as ( select 'OK' cola, split('www.lagou.com', '\\.') colb ) select cola, colc from t1 lateral view explode(colb) t2 as colc;
记忆: lateral view explode 表名 as 列名
explode map 案例:
-- 数据准备 lisi|Chinese:90,Math:80,English:70 wangwu|Chinese:88,Math:90,English:96 maliu|Chinese:99,Math:65,English:60 -- 创建表 create table studscore( name string ,score map<String,string>) row format delimited fields terminated by '|' collection items terminated by ',' map keys terminated by ':'; -- 加载数据 load data local inpath '/home/hadoop/data/score.dat' overwrite into table studscore; -- 需求:找到每个学员的最好成绩 -- 第一步,使用 explode 函数将map结构拆分为多行 select explode(score) as (subject, socre) from studscore; --但是这里缺少了学员姓名,加上学员姓名后出错。下面的语句有是错的 select name, explode(score) as (subject, socre) from studscore; -- 第二步:explode常与 lateral view 函数联用,这两个函数结合在一起能关 联其他字段 select name, subject, score1 as score from studscore lateral view explode(score) t1 as subject, score1; -- 第三步:找到每个学员的最好成绩 select name, max(mark) maxscore from (select name, subject, mark from studscore lateral view explode(score) t1 as subject, mark) t1 group by name; with tmp as ( select name, subject, mark from studscore lateral view explode(score) t1 as subject, mark ) select name, max(mark) maxscore from tmp group by name;
总结:
- 将一行数据转换成多行数据,可以用于array和map类型的数据;
- lateral view 与 explode 联用,解决 UDTF 不能添加额外列的问题
窗口函数:
窗口函数相当于把聚合函数在聚合范围的每一行体现
-- 使用窗口函数,查询员工姓名、薪水、薪水总和 select ename, sal, sum(sal) over() salsum, concat(round(sal / sum(sal) over()*100, 1) || '%') ratiosal from emp;
如果over 中没有参数,默认是全部数据集。
partition by子句:
在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
-- 查询员工姓名、薪水、部门薪水总和 select ename, sal, sum(sal) over(partition by deptno) salsum from emp;
order by 子句:
对输入的数据进行排序。
-- 增加了order by子句;sum:从分组的第一行到当前行求和 select ename, sal, deptno, sum(sal) over(partition by deptno order by sal) salsum from emp;
注:如果只有partition by 没有order by ,窗口大小是整个分区大小
如果有order by ,窗口大小是分区第一条数据到当前行
window 子句:
如果要对窗口的结果做更细粒度的划分,使用window子句,有如下的几个选项:
- unbounded preceding。组内第一行数据
- n preceding。组内当前行的前n行数据
- current row。当前行数据
- n following。组内当前行的后n行数据
- unbounded following。组内最后一行数据
示例:
-- rows between ... and ... 子句 -- 等价。组内,第一行到当前行的和 select ename, sal, deptno, sum(sal) over(partition by deptno order by ename) from emp; select ename, sal, deptno, sum(sal) over(partition by deptno order by ename rows between unbounded preceding and current row ) from emp; -- 组内,第一行到最后一行的和 select ename, sal, deptno, sum(sal) over(partition by deptno order by ename rows between unbounded preceding and unbounded following ) from emp; -- 组内,前一行、当前行、后一行的和 select ename, sal, deptno, sum(sal) over(partition by deptno order by ename rows between 1 preceding and 1 following ) from emp;
排名函数:
- row_number()。排名顺序增加不会重复;如1、2、3、4、... ...
- RANK()。 排名相等会在名次中留下空位;如1、2、2、4、5、... ...
- DENSE_RANK()。 排名相等会在名次中不会留下空位 ;如1、2、2、3、4、... ...
-- 按照班级,使用3种方式对成绩进行排名 select cname, sname, score, row_number() over (partition by cname order by score desc) rank1, rank() over (partition by cname order by score desc) rank2, dense_rank() over (partition by cname order by score desc) rank3 from t2; -- 求每个班级前3名的学员--前3名的定义是什么--假设使用dense_rank select cname, sname, score, rank from (select cname, sname, score, dense_rank() over (partition by cname order by score desc) rank from t2) tmp where rank <= 3;
序列函数:
- lag。返回当前数据行的上一行数据
- lead。返回当前数据行的下一行数据
- first_value。取分组内排序后,截止到当前行,第一个值
- last_value。分组内排序后,截止到当前行,最后一个值
- ntile。将分组的数据按照顺序切分成n片,返回当前切片值
-- lag。返回当前数据行的上一行数据 -- lead。功能上与lag类似 select cid, ctime, pv, lag(pv) over(partition by cid order by ctime) lagpv, lead(pv) over(partition by cid order by ctime) leadpv from userpv; -- first_value / last_value select cid, ctime, pv, first_value(pv) over (partition by cid order by ctime rows between unbounded preceding and unbounded following) as firstpv, last_value(pv) over (partition by cid order by ctime rows between unbounded preceding and unbounded following) as lastpv from userpv; -- ntile。按照cid进行分组,每组数据分成2份 select cid, ctime, pv, ntile(2) over(partition by cid order by ctime) ntile from userpv;
SQL 案例1: 连续7天登陆:


-- 数据。uid dt status(1 正常登录,0 异常) 1 2019-07-11 1 1 2019-07-12 1 1 2019-07-13 1 1 2019-07-14 1 1 2019-07-15 1 1 2019-07-16 1 1 2019-07-17 1 1 2019-07-18 1 2 2019-07-11 1 2 2019-07-12 1 2 2019-07-13 0 2 2019-07-14 1 2 2019-07-15 1 2 2019-07-16 0 2 2019-07-17 1 2 2019-07-18 0 3 2019-07-11 1 3 2019-07-12 1 3 2019-07-13 1 3 2019-07-14 0 3 2019-07-15 1 3 2019-07-16 1 3 2019-07-17 1 3 2019-07-18 1
-- 建表语句 create table ulogin( uid int, dt date, status int ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/home/hadoop/data/ulogin.dat' into table ulogin;
整体思路:
-- 1、使用 row_number 在组内给数据编号(rownum) -- 2、某个值 - rownum = gid,得到结果可以作为后面分组计算的依据 -- 3、根据求得的gid,作为分组条件,求最终结果
核心sql: 得到每一个用户 相同的日期(说明连续),对这个值group by 求count ,可以求出连续天数
select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) gid from ulogin where status=1;
最终sql: select uid, count(*) logincount from (select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) gid from ulogin where status=1) t1 group by uid, gid having logincount>=7;
SQL 案例2:编写sql语句实现每班前三名,分数一样并列,同时求出前三名按名次排序的分差
-- 数据。sid class score 1 1901 90 2 1901 90 3 1901 83 4 1901 60 5 1902 66 6 1902 23 7 1902 99 8 1902 67 9 1902 87 -- 待求结果数据如下: class score rank lagscore 1901 90 1 0 1901 90 1 0 1901 83 2 -7 1901 60 3 -23 1902 99 1 0 1902 87 2 -12 1902 67 3 -20
-- 建表语句 create table stu( sno int, class string, score int )row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/home/hadoop/data/stu.dat' into table stu;
求解思路:
-- 1、上排名函数,分数一样并列,所以用dense_rank -- 2、将上一行数据下移,相减即得到分数差 -- 3、处理 NULL
with tmp as ( select sno, class, score, dense_rank() over (partition by class order by score desc) as rank from stu ) select class, score, rank, nvl(score - lag(score) over (partition by class order by score desc), 0) lagscore from tmp where rank<=3;
SQL 案例:行<=>列
-- 数据:id course 1 java 1 hadoop 1 hive 1 hbase 2 java 2 hive 2 spark 2 flink 3 java 3 hadoop 3 hive 3 kafka

-- 建表加载数据 create table rowline1( id string, course string )row format delimited fields terminated by ' '; load data local inpath '/root/data/data1.dat' into table rowline1;
select id, sum(case when course="java" then 1 else 0 end) as java, sum(case when course="hadoop" then 1 else 0 end) as hadoop, sum(case when course="hive" then 1 else 0 end) as hive, sum(case when course="hbase" then 1 else 0 end) as hbase, sum(case when course="spark" then 1 else 0 end) as spark, sum(case when course="flink" then 1 else 0 end) as flink, sum(case when course="kafka" then 1 else 0 end) as kafka from rowline1 group by id;
例2:
-- 数据。id1 id2 flag a b 2 a b 1 a b 3 c d 6 c d 8 c d 8 -- 编写sql实现如下结果 id1 id2 flag a b 2|1|3 c d 6|8 -- 创建表 & 加载数据 create table rowline2( id1 string, id2 string, flag int ) row format delimited fields terminated by ' '; load data local inpath '/root/data/data2.dat' into table rowline2;
-- 第一步 将元素聚拢 select id1, id2, collect_set(flag) flag from rowline2 group by id1, id2; select id1, id2, collect_list(flag) flag from rowline2 group by id1, id2; select id1, id2, sort_array(collect_set(flag)) flag from rowline2 group by id1, id2; -- 第二步 将元素连接在一起 select id1, id2, concat_ws("|", collect_set(flag)) flag from rowline2 group by id1, id2; -- 这里报错,CONCAT_WS must be "string or array<string>"。加一个类 型转换即可 select id1, id2, concat_ws("|", collect_set(cast (flag as string))) flag from rowline2 group by id1, id2; -- 创建表 rowline3 create table rowline3 as select id1, id2, concat_ws("|", collect_set(cast (flag as string))) flag from rowline2 group by id1, id2; -- 第一步:将复杂的数据展开 select explode(split(flag, "\\|")) flat from rowline3; -- 第二步:lateral view 后与其他字段关联 select id1, id2, newflag from rowline3 lateral view explode(split(flag, "\\|")) t1 as newflag;
