
MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video - 1 - 论文学习
MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video
ABSTRACT
个性化推荐在许多在线内容分享平台中扮演着核心角色。为了提供高质量的微视频推荐服务,考虑用户与项目(即微视频)之间的交互以及来自各种模态(如视觉、听觉、文字)的项目内容是至关重要。现有的多媒体推荐工作主要利用多模式内容来丰富产品表征,较少利用用户与产品之间的信息交互来增强用户表征,并进一步捕捉用户在不同模式下的细粒度偏好。
在本文中,我们提出利用用户-项目交互来指导每种形式的表示学习,并进一步实现个性化的微视频推荐。基于图神经网络的消息传递思想,我们设计了一个多模态图卷积网络(Multi-modal Graph Convolution Network,MMGCN)框架,该框架可以生成用户和微视频特定模态的表征,以更好地捕捉用户的偏好。具体地说,我们在每个模态上构造一个用户-项目二分图(bipartite graph),并用其邻接节点的拓扑结构和特征来丰富每个节点的表征。通过在三个公开可用的数据集(Tiktok、Kwai和MovieLens)上的大量实验,我们证明了我们提出的模型显著优于最先进的多模式推荐方法。
1 INTRODUCTION
个性化推荐已经成为许多在线内容分享服务的核心组成部分,从图像、博客到音乐推荐。近年来,Tiktok、Kwai等微视频分享平台的成功,使得微视频推荐受到越来越多的关注。微视频不同于这些仅仅来自单一模态的项目内容(如图像、音乐),微视频包含丰富的多媒体信息——画面、音频和描述——涉及视觉、听觉和文本的多种模态[24,25,28]。
将这种多模式信息整合到用户和微视频之间的历史交互中,有助于建立对用户偏好的深入理解:
- 不同模态之间存在语义差异。以图1为例,虽然微视频 i1和 i2有视觉上相似的画面,但是由于主题词的不同,它们的文本表示却不一样。在这种情况下,忽略这种模态差异会误导对项目表示的建模。
- 用户可能对微视频的模态有不同的品味。例如,用户会被画面吸引,但可能会对其糟糕的音频感到失望。因此,多种模态对用户的偏好有不同的贡献。
- 不同的模态是探索用户兴趣的不同渠道。在图1中,如果用户u1更关心画面,则推荐i2更合适;然而,u1可能会因为对文本描述感兴趣而点击i3。
因此,区分和考虑特定模态的用户偏好至关重要。
然而,现有的多媒体推荐研究[8,17]主要将多模态信息作为一个整体,并将其纳入协同过滤(CF)框架,缺乏特定模态用户偏好的建模。具体来说,就是将每个项目的多模态特征统一为一个单一的表征,反映其内容的相似性;然后,这些表征与CF框架派生的用户和项目表征合并,如MF[30]。例如,VBPR[17]利用视觉特性来丰富项目的ID embedding;ACF[8]使用用户历史的注意力机制,将历史项目和项目内容的两级个人品味编码到用户表征中。这种信号可以概括为基于历史交互的目标用户与物品之间的连接路径[38,41]。例如,给定两条路径p1 := u1 → i1 → u2 → i2和p2 :=u1 → i1 → u2 → i3,这表明u1可能对i2和i3感兴趣。然而,我们认为这些信号不足以得出这样的结论。关键原因是它们忽略了不同模态之间的差异和用户偏好。
为了解决这些限制,我们专注于用户和项目之间的信息交换的多种模式。受最近成功的图卷积网络(GCNs)[14,22]的启发,我们使用信息传播机制在用户和微视频之间编码每个模态的高阶连通性,从而捕捉用户对特定模态内容的偏好。为此,我们提出了一种多模态图卷积网络(MMGCN,Multi-modal Graph Convolution Network)。具体地说,我们在每个模态上构造一个user-item二分图。直观上,用户的历史行为反映了个人兴趣;同时,用户组也可以侧写项目[38,41]。因此,在每个模态(例如,视觉)中,我们从交互项的相应内容(例如,帧)中聚合信号,并将它们合并到用户表示中;与此同时,我们使用项目的用户组去增强项目的表示。通过递归地执行这些聚合和组合操作,我们可以强制用户和项目表示捕获来自多跳邻居的信号,这样用户特定于模态的偏好就可以在他/她的表示中很好地表示出来。最终,一个看不见的交互的预测可以被计算为用户和微视频表示之间的相似性。我们通过三个公开可访问的数据集验证我们的框架——Tiktok、Kwai和Movielens。实验结果表明,该模型具有良好的性能。此外,我们可视化了不同模式下的用户偏好,这清楚地显示了不同用户在特定模式偏好上的差异。
这项工作的主要贡献有三个方面:
- 我们探讨不同模式的信息交换如何反映用户偏好并影响推荐性能。
- 我们开发了一种新的方法MMGCN,它利用模态感知的二分user-item图的信息传播来获得基于物品内容信息的更好的用户表示。
- 我们在三个公共数据集上进行了大量的实验,以证明我们提出的模型优于几种最先进的推荐方法。此外,我们还发布了我们的代码、参数和基线,以方便其他人进一步研究。(https://github.com/weiyinwei/MMGCN.)
2 MODEL FRAMEWORK
在本节中,我们将详细阐述我们的框架。如图2所示,我们的框架由三个组件组成——聚合层、组合层和预测层。通过叠加多个聚合层和组合层,将用户和项目之间的信息交换编码到每个模态的表示学习中。最后,融合多模态表示,在预测层中预测每个用户与每个微视频之间的交互。接下来,我们将详细介绍每个组件。
2.1 Modality-aware User-Item Graphs
我们不是统一多模态信息,而是独立地对待每个模态。特别是,我们有用户与微视频之间的历史互动信息(如观看、浏览或点击)。在这里,我们将交互数据表示为一个二分user-item图![]() ,其中
,其中![]() 和
和![]() 分别表示用户和微视频集。边缘yui=1表示user u 和微视频 i 之间观察到的交互;否则yui=0。
分别表示用户和微视频集。边缘yui=1表示user u 和微视频 i 之间观察到的交互;否则yui=0。
在交互以外,每个微视频还有多种模态 - 视觉、听觉和文本(visual, acoustic, and textual )特征。简单来说,我们使用![]() 表示模态指示器,其中v、a和t分别表示视觉、听觉和文本模态。为了准确捕捉到特定模态m中用户的偏好,我们通过仅保持模态m中的特征来从
表示模态指示器,其中v、a和t分别表示视觉、听觉和文本模态。为了准确捕捉到特定模态m中用户的偏好,我们通过仅保持模态m中的特征来从![]() 中分离出
中分离出![]() 。
。
2.2 Aggregation Layer
直观上,我们可以利用交互数据来丰富用户和项目的表示。更具体地说,用户的历史交互可以描述用户的兴趣,并捕捉与其他用户的行为相似性。同时,微视频的用户群可以为其多模态内容提供互补的数据。因此,我们将信息交换纳入表示学习。
受GCN消息传递机制的启发,对于二分图![]() 中的用户(或微视频)节点,我们采用聚合函数f(·)量化其邻居的影响(即被传播的表示),然后输出一个表示,如下:
中的用户(或微视频)节点,我们采用聚合函数f(·)量化其邻居的影响(即被传播的表示),然后输出一个表示,如下:
![]()
其中![]() 表示用户 u的邻居,即交互的微视频。f(·)有两种:
表示用户 u的邻居,即交互的微视频。f(·)有两种:
- Mean Aggregation 对模态特征采用平均池化操作,并采用非线性变换,如下所示:
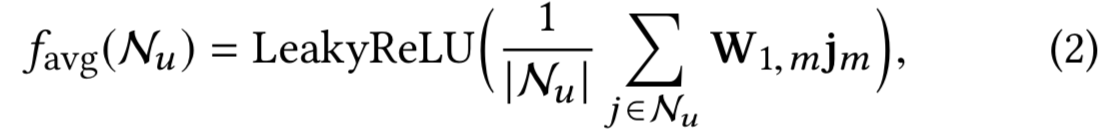
其中![]() 是微视频 j 在模态m中的dm维表示;
是微视频 j 在模态m中的dm维表示;![]() 是用于蒸馏有用知识的可训练的变换矩阵,其中
是用于蒸馏有用知识的可训练的变换矩阵,其中![]() 是变换大小;选择LeakyReLU(.)作为非线性激活函数[38,41]。该聚合方法假设不同的邻居对用户u有着相同的贡献,即用户u的邻居对它的影响是相同的。
是变换大小;选择LeakyReLU(.)作为非线性激活函数[38,41]。该聚合方法假设不同的邻居对用户u有着相同的贡献,即用户u的邻居对它的影响是相同的。
- Max Aggregation 利用最大池化操作来执行感知维度的特征选择,如下所示:
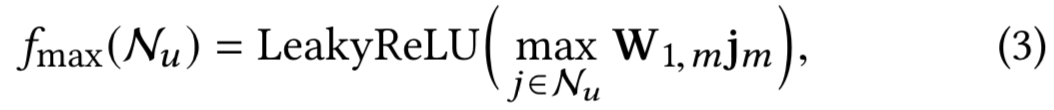
其中hm的每个维度都设置为相应邻居值的最大值。因此,不同的邻居对输出表示有不同的贡献。
因此,聚合层能够将邻居的结构信息和分布编码为用户的表示;类似地,我们可以更新项目节点的表示。
2.3 Combination Layer
在包含邻居传播的信息的同时,这种表示放弃了用户u自身的特征和不同模式之间的交互。然而,现有的GNN工作(例如,GCN [22], GraphSage [14], GAT[33])只考虑来自一个数据源的同质特性。因此,直接应用它们的组合操作并不能捕获不同模式之间的相互作用。
在本节中,我们提出了一个新的组合层,它将结构信息hm、内在信息um和模态连接uid整合成一个统一的表示形式,具体表示为:
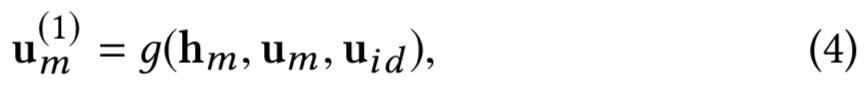
其中![]() 是用户u在模态m的表示;
是用户u在模态m的表示;![]() 是用户ID的d维嵌入,保持不变并作为模态间的连接。
是用户ID的d维嵌入,保持不变并作为模态间的连接。
受之前多模态表示研究[3]的启发,我们首先应用协调fashion的想法,即分开投射![]() 到和uid相同的潜在空间中:
到和uid相同的潜在空间中:
![]()
其中![]() 是将um转移到ID嵌入空间的可训练权重矩阵。因此,不同模态的表示在同一超平面上具有可比性。同时,ID嵌入uid本质上弥补了特定模态表示之间的差距,并在梯度反向传播过程中跨模态传播信息。在本工作中,我们通过以下两种方法实现了组合函数g(·):
是将um转移到ID嵌入空间的可训练权重矩阵。因此,不同模态的表示在同一超平面上具有可比性。同时,ID嵌入uid本质上弥补了特定模态表示之间的差距,并在梯度反向传播过程中跨模态传播信息。在本工作中,我们通过以下两种方法实现了组合函数g(·):
- Concatenation Combination 使用非线性变换将两个表示连接起来:
![]()
其中||是串联操作,![]()
![]() 是可训练的模型参数
是可训练的模型参数
- Element-wise Combination 考虑两种表示之间的元素特征交互:
![]()
其中![]() 表示将当前表示转移到常见空间的权重矩阵。在element-wise的连接中,两个表示之间的交互也被考虑了,同时在concatenation连接中,两个表示假设是独立的。
表示将当前表示转移到常见空间的权重矩阵。在element-wise的连接中,两个表示之间的交互也被考虑了,同时在concatenation连接中,两个表示假设是独立的。
2.4 Model Prediction
通过叠加更多的聚合(aggregation)和组合(combination)层,我们探索了user-item图中固有的高阶连通性。因此,我们可以模仿用户的探索过程,收集模态m中来自![]() 跳邻居的信息。形式上,用户u的
跳邻居的信息。形式上,用户u的![]() 跳邻居表示和第
跳邻居表示和第![]() 个多模态组合层的输出递归表示为:
个多模态组合层的输出递归表示为:
![]()
其中![]() 是之前的层生成的表示,记录来自(
是之前的层生成的表示,记录来自(![]() -1)跳邻居的信息。
-1)跳邻居的信息。![]() 在初始迭代中设置为um。用户u与可训练向量
在初始迭代中设置为um。用户u与可训练向量![]() 相关联 ,该向量是随机初始化得到的;同时,项目i和预抽取的特征
相关联 ,该向量是随机初始化得到的;同时,项目i和预抽取的特征![]() 相关联。最后,
相关联。最后,![]()
在模态m中描述了用户对项目特征的偏好,并考虑了反映模态之间潜在关系的模态交互的影响。
将L个单模态聚合层和多模态组合层叠加后,通过多模态表示的线性组合,得到用户u和微视频i的最终表示,为:
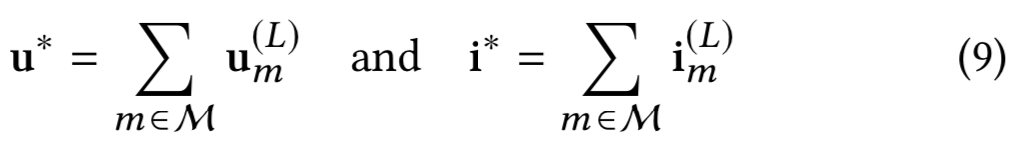
2.5 Optimization
为了预测用户与微视频之间的交互,我们融合了用户与微视频的特定模态表示,并采用Bayesian Personalized Ranking (BPR)[30]作为学习模型,这是一个著名的成对排名优化框架。特别地,我们建立了一个由一个用户和两个微视频组成的三元组,其中一个微视频被观察到,而另一个则没有观察到:
![]()
其中![]() 由与u相关的所有微视频组成,
由与u相关的所有微视频组成,![]() 为训练用的三元组集合。此外,我们假设用户更喜欢观察到的微视频而不是未观察到的微视频。因此,目标函数可以表示为:
为训练用的三元组集合。此外,我们假设用户更喜欢观察到的微视频而不是未观察到的微视频。因此,目标函数可以表示为:
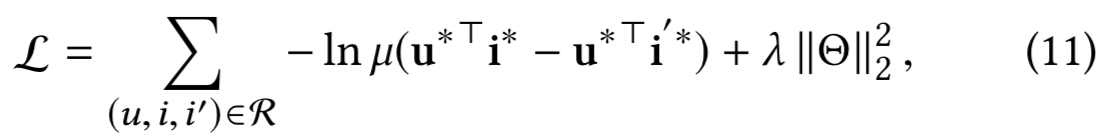
其中μ(.)为sigmoid函数;λ和Θ分别表示归一化权重和模型参数。
3 EXPERIMENTS
在本节中,我们在三个公开可用的数据集上进行实验,旨在回答以下研究问题:
- RQ1:在我们的任务中,与最先进的多模式推荐系统和其他基于GNN的方法相比,MMGCN的性能如何?
- RQ2:不同的设计(如模态数、层数、组合层的选择)如何影响MMGCN的性能?
- RQ3: MMGCN能否捕捉用户在不同模式上的不一致偏好?
接下来,我们首先给出实验设置(即数据集、基线、评估协议和参数设置),然后回答上述三个问题。
3.1 Experimental Settings
Datasets. 为了评估我们的模型,我们实验了三个公开可用的数据集:Tiktok、Kwai和MovieLens。这些数据集的特征如表1所示。
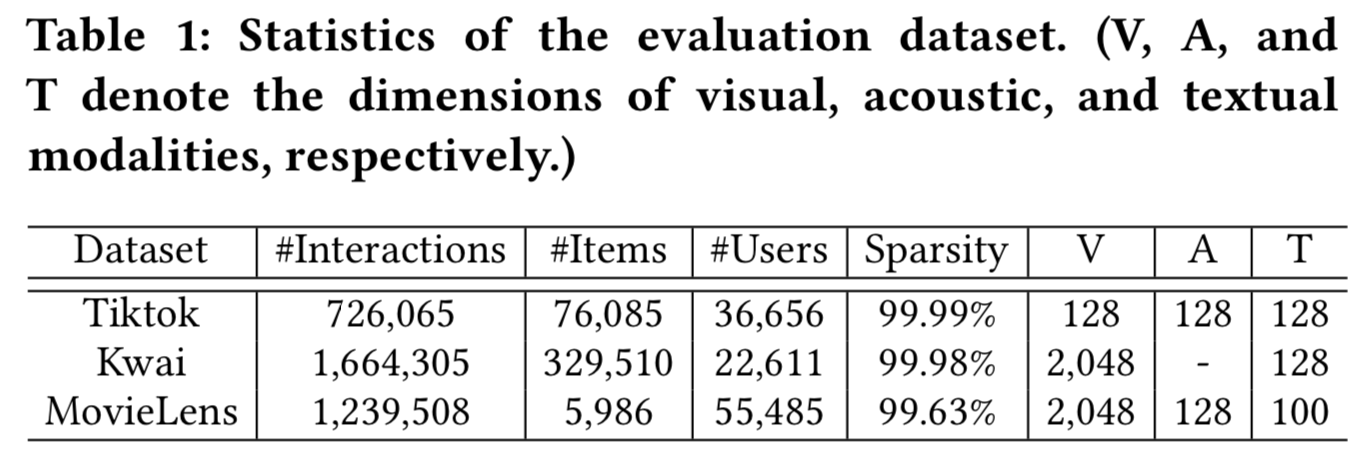
- Tiktok:(http://ai-lab-challenge.bytedance.com/tce/vc/.) 由微视频分享平台Tiktok发布,用户可以创建和分享时长为3-15秒的微视频。它由用户、微视频和他们的互动(如点击)组成。每个模态的微视频特征被提取并发布,而不提供原始数据。特别的是,文本特征是从用户给出的微视频字幕中提取出来的。
- Kwai: (https://www.kuaishou.com/activity/uimc.)作为一个受欢迎的微视频服务提供商,Kwai建立了一个大规模的微视频数据集。与Tiktok数据集类似,它包含保护隐私的用户信息、微视频内容特性和交互数据。然而,微视频的声音信息缺失。
- MovieLens: (https://grouplens.org/datasets/movielens/.)该数据集已被广泛用于评估推荐。为了构建数据集,我们从MoiveLens-10M数据集中收集电影的标题和描述,并抓取相应的预告片,而不是从Youtube(https://www.youtube.com/. )上抓取完整的视频。我们使用预先训练的ResNet50[16]模型从微视频提取的关键帧中提取视觉特征。在声音模态方面,我们使用FFmpeg(http://ffmpeg.org/. )分离音轨,采用VGGish[20]学习声音深度学习特征。对于文本模态,我们使用Sentence2Vector[1]从微视频的描述中提取文本特征。
Baselines. 为了评估我们模型的有效性,我们将MMGCN与以下最先进的基线进行比较。基线可以分为两类:基于CF (VBPR和ACF)和基于GCN (NGCF和GraphSAGE)的方法。
- VBPR[17]. 该模型将每个商品的内容特征和ID嵌入作为其表示,并使用矩阵分解(MF)框架重建用户与商品之间的历史交互。在实验中,我们使用多模态特征的串联作为内容信息来预测用户与微视频之间的交互。
- ACF[8]. 这是第一个用于处理多媒体推荐中隐式反馈的框架。它引入了两个注意模块来处理项目级和组件级隐式反馈。为了探究特定模态的用户偏好和微视频特征,我们将每个模态视为微视频的一个组成部分,这与标准ACF的思想是一致的。
- GraphSAGE[14]. 该模型基于通用归纳框架,利用节点特征信息更新之前未见数据的节点表示。特别是考虑了结构信息以及节点特征在邻域内的分布。为了公平比较,我们将多模态特征集成为节点特征,以学习每个节点的表示。
- NGCF[41]. 该方法提出了一种新的推荐框架,将user-item交互整合到嵌入过程中。通过利用来自user-item交互的高阶连接性,模态将协同过滤信号编码到表示中。为了公平比较,我们将微视频的多模态特征作为side信息,并将其输入到框架中来预测用户与项目之间的交互情况。
评估协议和参数设置. 我们将数据集按8:1:1的比例随机分割为训练集、验证集和测试集,并基于随机负采样的方法创建训练三元组。对于测试集,我们将每个观察到的user-item对与1000个未观察到的用户之前没有交互的微视频配对。我们使用广泛使用的协议[8,19]:Precision@K, Recall@K,和NDCG@K来评估top-K推荐的性能。这里我们设置K = 10,并报告测试集中的平均分数。为了训练我们提出的模型,我们使用高斯分布随机初始化模型参数,并使用LeakyReLU作为激活函数,并使用随机梯度下降(SGD)优化模型。在{128,256,512}中选择batch大小,在{32,64,128}中选择潜在特征维数,在{0.0001,0.0005,0.001.0.005,0.01}中选择学习率,在{0,0.00001,0.0001,0.001,0.01,0.1}中选择正则化器。由于在潜在向量的不同维度上结果是一致的,如果没有特别说明,我们只显示64的结果,这是一个相对较大的数字,返回良好的准确性。
3.2 Performance Comparison (RQ1)
表2总结了比较结果。从这张表中,我们可以得出以下几点意见:
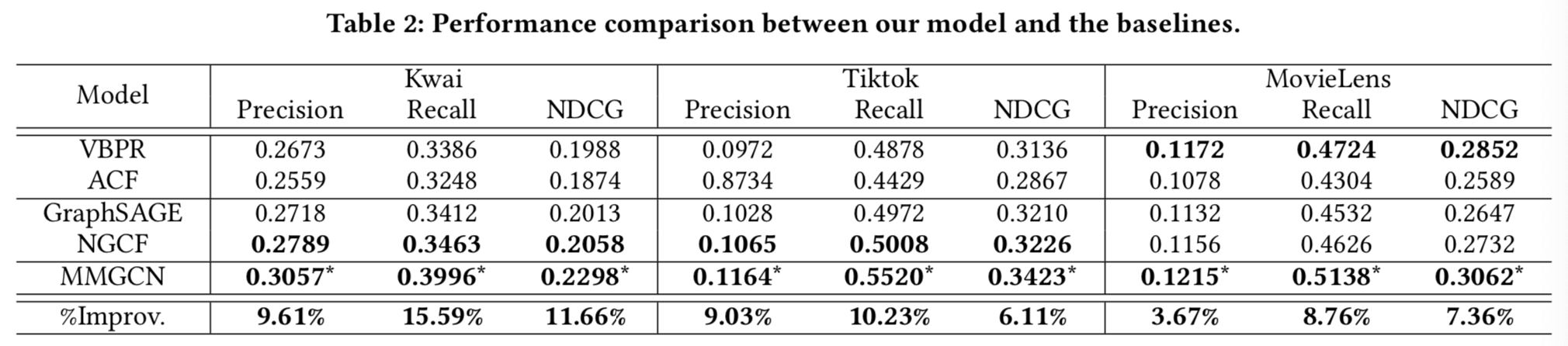
- 在大多数情况下,MMGCN显著优于所有其他基线,验证了我们模型的有效性。特别是,MMGCN提高了Recal上的最强基线 ,在三个数据集上分别提高了15.59%、10.23%和8.76%。我们将这些显著的改进归功于特定模态表示的学习,从而有效地捕捉用户的偏好。
- 在Kwai和Tiktok上,基于GNN的模型优于基于CF的模型。这些改进归功于图的卷积层。这种操作不仅可以获取局部结构信息,还可以了解每个ego节点的邻居特征分布情况,从而提高表示的表现力。
- 一般来说,在大多数情况下,NGCF在三个数据集上都比其他基线有更好的性能。这是合理的,因为NGCF很容易推广,利用内容信息来描述用户和微视频。
- 出乎意料的是,ACF在所有数据集上的性能都很差。其原因可能是由于我们在ACF模型实现期间所做的修改,为了进行公平的比较,我们用特定模态的信息替换了组件级特征建模。
3.3 Study of MMGCN (RQ2)
3.3.1 Effects of Modalities. 为了探索不同模式的效果,我们比较了三个数据集上不同模式的结果,如图3所示。它显示了K范围为1到10的top-K推荐列表的性能。从图3可以看出:
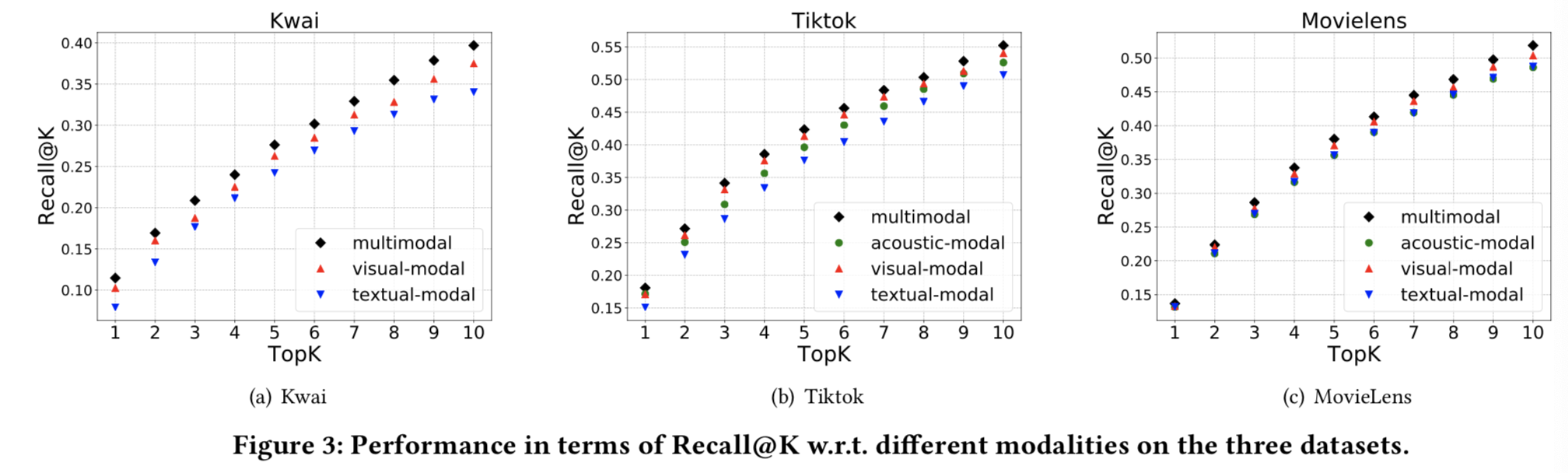
- 正如预期的那样,在MMGCN中,在所有三个数据集上,具有多模态特征的方法优于具有单模态特征的方法。结果表明,用多模态信息表示用户具有较高的准确性。它进一步说明用户表示与项的内容密切相关。此外,它表明我们的模型可以从内容信息中捕获用户特定模态的偏好。
- 视觉模态是三种模态中最有效的。这是有道理的,因为当用户选择玩什么游戏时,他们通常会更关注视觉信息而不是其他模态信息。
- 与文本特征相比,声音模态提供了更重要的推荐信息。特别是对于Tiktok数据集,声音信息甚至具有与视觉形态相当的表达能力。
- 对于交互预测来说,文本模态的描述性最弱,特别是在Kwai和Tiktok数据集上。这是合理的,因为我们发现这两个数据集中的文本质量很低,即描述是有噪声的,不完整的,甚至与微视频内容无关。然而,这种方式为MovieLens数据集提供了重要的线索。因为文字的描述是视频的故事情节,与内容高度相关,有些用户会根据故事情节播放视频。这种现象与我们认为用户偏好与内容信息密切相关的观点是一致的。
- 随着K的增加,MMGCN的Recall@K始终高于其他变体。结果表明,基于每种模态的用户偏好表示更接近于用户的真实偏好,有助于预测用户与物品之间的交互。根据用户对各种模态的偏好进行建模可以得到高质量的多模态个性化推荐。
3.3.2 Effect of Combination Layers. 在模型中,我们设计了一种新的组合层,将局部结构信息与节点特征相结合,促进了多模态表示的融合。其中,组合函数可以通过两种不同的方式实现(参见式(6)和式(7))。这里我们比较了这些不同的实现,并评估了提出的组合层的有效性,其中gco−id和gele−id分别表示两种没有id嵌入的实现。如表3所示,我们有以下发现:

- 就这三个指标而言,gele在这三个数据集上取得了最好的性能。这可能是因为组合层保留了特定模态的特征来表示用户和微视频。它展示了我们的组合层的有效性。
- 比较这些方法,我们发现带有id嵌入的方法明显优于其他方法。这再次证明了我们的新组合层的有效性。此外,我们认为共享id嵌入通过在反向传播中传播共享信息来连接不同的模态。
- 比较这两种实现,我们发现基于元素的实现比串联的实现更好。我们推测,具有全连接层的串联数据训练难度更大,特别是在像Kwai这样的spare数据集上。
3.3.3 Effect of Model Depth. 为了评估层叠加的有效性,我们在三个不同的层上进行了实验,如表4所示。从结果中,我们观察到:
- 在三个指标上,两层模型取得了更好的结果,这表明增加层并不会带来更好的结果。这似乎表明,随着层数的增加,节点的判别性正在降低。我们认为增加层使节点的邻居更加相似,并进一步使节点表示更加相似。
- 对比单层模型和双层模型,Tiktok和Kwai上的结果改善更为明显,而MovieLens上的结果改善不明显。结果表明,集成局部结构信息可以增强节点表示。
- 将两层模型与三层模型进行比较,三层模型的效果不如两层模型。这可能是由于数据的稀疏性导致的过拟合。
- 将单层模型与三层模型进行比较,我们发现单层模型的结果略低于三层模型。假设单层模型的局部结构信息不足导致节点表示质量较低。这再次证明了节点表示中的内容信息的有效性。
3.4 Case Study (RQ3)
我们进行了实验来可视化我们的特定模态表示。特别是,我们随机抽取了5名用户,收集了他们玩过的微视频。为了验证我们的假设,即用户在不同模式上的偏好是不同的,我们使用t-分布随机邻居嵌入(t-SNE,t-Distributed Stochastic Neighbor Embedding)在二维中将这些表示可视化,如图4所示。
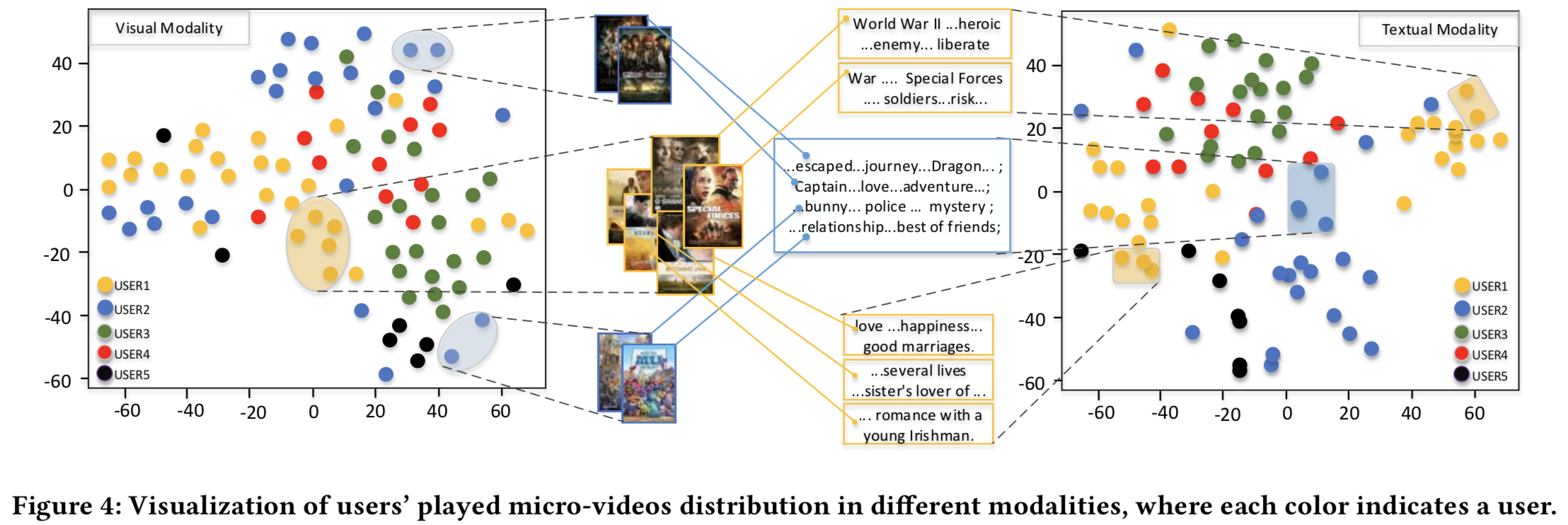
从左到右的坐标图分别表示视觉和文本模态。图中的点代表用户播放的视频,它们的颜色代表不同的用户。由于声音模态难以可视化,我们只分析视觉模态和文本模态的结果。
- 在视觉模态中,user1的点是分散的,其中一些点与user2、user3和user4的点混合在一起。另一方面,来自user1的点在文本模态中形成了两个集中的区域,它们彼此相距很远。点的分布意味着用户在文本模态中有两个不同的偏好主题。而他/她对视觉模态没有特别的偏好。user2的点在视觉模态的三个区域聚类;而在文本模态中,它们是分散的,并与其他用户的观点混合在一起。从user2的分布模式可以看出,他/她在视觉模态中有三个偏好主题。user3的点在两种模态中都有很好的聚类分布,这表明用户对每种模态都有特殊的偏好。user4和user5的点分布是分散的,与其他用户点混在一起。
- 利用点的分布进行分析仍然是抽象的。图中显示了每个点所代表的视频的多模态信息,以便进一步说明。以user1和user2为例,他们喜欢的一些视频的视觉和文本模态显示在图4中,用视频海报和故事线表示。我们观察到user1播放的视频在视觉上没有明显的主题,因为他/她喜欢的海报涵盖了很多不同的品种。然而,这些视频的故事情节或文本模态只包含两个主题:战争和浪漫。从user2我们观察到,他/她对视觉模态的偏好明显分为动画和古典风格,而他/她对故事情节的偏好则不明显。这些现象支持了我们的假设,即用户在不同的模式中有不同的偏好。
4 RELATED WORK
在本节中,我们介绍了一些与我们的研究相关的工作,包括多模态个性化推荐、多模态融合和图卷积网络。
4.1 Multi-modal Personalized Recommendation
由于CF方法在推荐系统中的成功,早期的多模态推荐算法主要基于CF模型[6,18,38-40]。基于CF的模型利用用户反馈(如隐式反馈和显式反馈)来预测用户与产品之间的交互作用。尽管这些方法对于有足够反馈的项目很有效,但对于那些反馈很少的项目却不太适用,这导致了低质量的推荐。因此,基于CF的方法受到数据稀疏性的限制。
为了弥补基于CF模型的不足,研究人员开发了融合item内容信息和协同过滤效应的混合推荐方法。例如Chen等[7]构造了一个user-video-query 的三分图,并进行图传播,将用户和视频之间的内容和反馈信息结合起来。最近,Chen等人的[8]研究了项目中的细粒度用户偏好,并引入了一种新颖的注意机制来解决多媒体推荐中具有挑战性的项目和组件级反馈。在该方法中,用户既具有协同过滤效果,又具有参与items的内容信息。虽然该方法学习了用户偏好的两个层次,但未能在不同的模态上对用户偏好进行建模,这是第1节提到的多模态推荐的关键。为了填补特定模态特征表示的空白,我们的模型构建了每个模态的图,并使用GCN技术表示特定模型特征,该技术集成了局部结构信息和邻近的内容信息分布。
4.2 Multi-modal Representation
多模态表示是多模态应用中最重要的问题之一。然而,在多模式个性化推荐领域,之前只有很少的工作专注于多模式表示。
现有的多模态表示可以分为两类:联合(joint)表示和协调(coordinated)表示[3]。联合表示通常将各种单模态信息组合成单一表示,并将其投影到相同的表示空间中。联合表示的最简单实现是单模态特征的串联。近年来,随着神经网络在计算机视觉[2,15,23]和自然语言处理[9,32]方面的成功,神经网络越来越多地应用于多模态领域,尤其是多模态表示领域[10,11,35 - 37,43]。利用神经网络,可以学习将不同模态信息融合成联合(joint)表示的函数。此外,概率图形模型(probabilistic graphical models)[4,13]是利用潜在随机变量构造多模态信息联合表示的另一种方法。尽管这些方法学习了一个联合表示来建模多模态数据,但它们适用于在推理过程中所有模态都存在的情况,这在社交平台中很难保证。
与联合表示法不同,协调表示法学习每个模态的单独表示,但使用约束进行协调。为了表示多模态信息,Frome等人[12]提出了一种深度视觉语义嵌入模型,该模型将视觉信息和语义信息投影到一个受视觉嵌入与对应词嵌入距离限制的公共空间中。类似地,Wang等人[34]构造了一个协调空间,使得意义相似的图像彼此更接近。然而,由于特定模态的信息是导致每个模态信号差异的因素,因此,通过这些相似的约束,特定模型的特征不可避免地被丢弃。
而在我们的模型中,我们引入了一种新的表示方法,分别对特征的公共部分和特定部分进行建模,从而解决了上述问题。
4.3 Graph Convolution Network
如上所述,我们提出的模型使用GCN技术来表示用户和微视频,这在推荐系统中非常普遍[21,22,26,29]。对于视频推荐,Hamilton等人[14]提出了一个通用的归纳框架,利用内容信息为未见过的数据生成节点表示。基于这种方法,Ying等[42]在Pinterest开发并部署了一个用于图像推荐的大规模深度推荐引擎。该模型采用图卷积和随机游走(random walks)相结合的方法生成节点的表示。同时,Berg等人[5]将推荐系统视为图上的链接(link)预测视图,提出了一种基于二分交互图上消息传递的图自动编码器框架。此外,side信息可以通过单独的处理通道集成到节点表示中。然而,可以看到,这些方法未能捕获多模态推荐中每个节点的特定模态表示,这是我们工作的主要关注点。
5 CONCLUSION AND FUTURE WORK
在本文中,我们明确地建模特定模态的用户偏好,以增强微视频推荐。我们设计了一个新的基于GCN的框架,称为MMGCN,利用用户和微视频之间在多种模态上的信息交换,细化他们特定模态的表示,并进一步建模用户对微视频的细粒度偏好。在三个公开的微视频数据集上的实验结果验证了我们的模型。此外,我们可视化了一些示例,以说明特定模态的用户偏好。
这项工作研究了不同模态的信息交换如何影响用户偏好。这是将基于模态的结构信息编码到表征学习中的初步尝试。这是一个很有前途的解决方案,可以理解用户行为,并提供更准确、多样化和可解释的推荐。在未来,我们将在几个方向扩展MMGCN。首先,我们构建多模态知识图谱来表示微视频[31]中的对象及其之间的关系,然后将其应用到MMGCN中来建模更细粒度的内容分析。它将以更细粒度的方式探索用户的兴趣,并提供对用户意图的深入理解。它还可以提供更准确、多样化和可解释的推荐。其次,我们将探索社会领袖如何影响推荐,即整合社会网络与user-item图。我们还希望将多媒体推荐纳入对话系统,以实现更智能的对话推荐。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2018-09-29 secp256k1如何使用
2018-09-29 椭圆曲线签名算法的v的定义
2018-09-29 the security of smart contract- 1
2018-09-29 call()、delegatecall()
2018-09-29 the security of smart contract- 2
2018-09-29 solidity ecrecover
2018-09-29 ethereum/EIPs-1271 smart contract