
推荐 - 1 - Wide & Deep Learning for Recommender Systems - 1 - 论文学习
Wide & Deep Learning for Recommender Systems
ABSTRACT
具有非线性特征变换的广义线性模型被广泛应用于具有稀疏输入的大规模回归和分类问题。通过一系列cross-product特征变换的特征交互的记忆(memorization)是有效且可解释的,而泛化则需要更多的特性工程工作。由于较少的特征工程,深度神经网络可以通过为了稀疏特征学习的低维密集嵌入来更好地泛化没见过的特征组合。然而,当用户与物品之间的交互是稀疏的、high-rank的时,带有嵌入的深度神经网络会过度泛化并推荐相关度较低的物品。在本文中,我们提出了Wide & Deep learning——联合训练wide 线性模型和deep神经网络——将记忆(memorization)和泛化(generalization)的好处结合到推荐系统中。我们在Google Play上对该系统进行了实验和评估,Google Play是一个拥有超过10亿活跃用户和100多万应用程序的商业移动应用商店。在线实验结果显示,与wide-only模式和deep-only模式相比,Wide & Deep模式显著增加了应用获取量。我们还在TensorFlow中开源了我们的实现代码。
1. INTRODUCTION
推荐系统可以看作是搜索排名系统,其中输入查询是一组用户和上下文信息,输出是条目的排名列表。给出一个查询,推荐任务就是在数据库中找到相关的商品,然后根据特定的目标, 如点击或购买,对这些商品进行排名。
与一般的搜索排名问题类似,推荐系统面临的一个挑战是同时实现记忆(memorization)和泛化(generalization)。记忆可以被宽泛地定义为学习项目或特征的频繁共现,并利用历史数据中可用的相关性。另一方面,泛化是基于相关性的传递性,探索过去从未或很少发生的新特征组合。基于记忆的推荐通常更具有针对性,并且与用户已经执行了操作的项目直接相关。与记忆相比,泛化倾向于提高推荐项目的多样性。在本文中,我们主要关注Google Play商店的apps推荐问题,但这种方法应该适用于一般的推荐系统。
对于工业背景下的大规模在线推荐和排名系统,广义线性模型(如logistic回归)因其简单、可扩展和可解释而被广泛使用。模型通常采用one-hot编码的二值化稀疏特征进行训练。例如,如果用户安装了netflix,二进制特征“user_installed_app=netflix”的值为1。使用稀疏特征的cross-product转换可以有效地实现记忆,例如AND(user_installed_app=netflix,impression_app=pandora "),如果用户安装了Netflix,然后显示的是Pandora,则AND的值为1。这解释了特征对的共现如何与目标标签相关联。泛化可以通过使用更细粒度的特征来添加,例如AND(user_installed_category=video,impression_app=music),但通常需要手动的特征工程。cross-product转换的一个限制是,它们不能泛化到没有出现在训练数据中的query-item特征对。
基于embedding的模型,如factorization machines[5]或深度神经网络,可以通过学习每个query和item特征的低维密集embedding向量来推广到之前未见过的query-item特征对,减少了特征工程的负担。然而,当底层query-item矩阵是稀疏的且high-rank时,很难学习queries和items的有效低维表征,例如具有特定偏好的用户或具有狭窄吸引力的小众项目。在这种情况下,大多数query-item对之间应该没有交互,但密集的嵌入将导致对所有query-item对的非零预测,从而可能过度泛化,并给出相关性较低的推荐。另一方面,具有cross-product特征转换的线性模型可以用更少的参数记住这些“异常规则(exception rules)”。
在该论文中,我们提出了Wide & Deep学习框架,通过共同训练一个线性模型和一个神经网络去在一个模型中同时得到记忆和泛化能力,如图1所示。
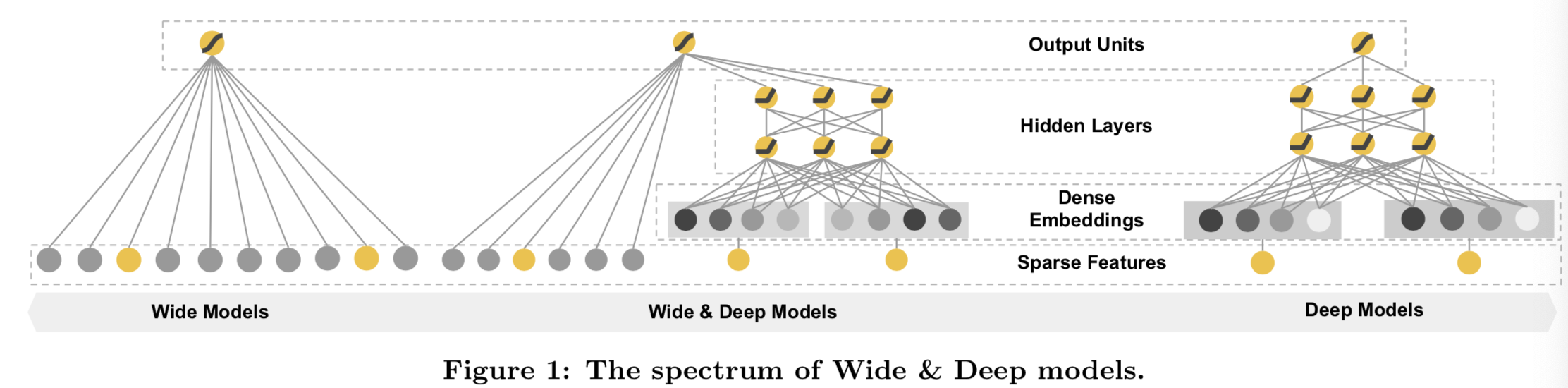
该论文的主要贡献有:
为具有稀疏输入的通用推荐系统联合训练带有embeddings的前馈神经网络和带有特征转换的线性模型的Wide & Deep学习框架。
•在Google Play上产生Wide & Deep推荐系统的实施和评估,Google Play是一个拥有超过10亿活跃用户和超过100万个应用程序的移动应用商店。
•我们在TensorFlow(See Wide & Deep Tutorial on http://tensorflow.org )中开源了我们的实现以及一个高级API。
虽然想法很简单,但我们发现Wide & Deep框架在满足训练和服务速度要求的同时,显著提高了移动app商店中的app获取率。
2. RECOMMENDER SYSTEM OVERVIEW
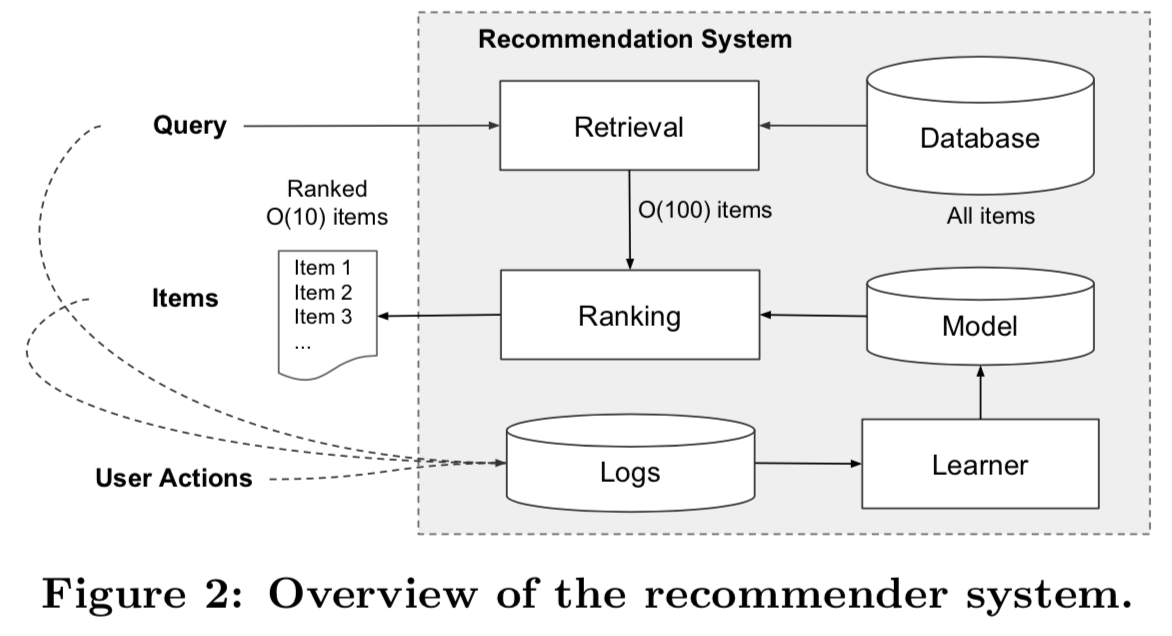
应用推荐系统的概述如图2所示。当用户访问应用商店时,会生成一个query,其中可以包含各种用户和上下文特征。推荐系统会返回一个apps列表(也称为impressions),用户可以在该列表上进行点击或购买等操作。这些用户操作,连同queries和impressions,作为学习者的训练数据记录在日志中。
由于数据库中有超过100万个apps,所以很难在服务延迟要求(通常是O(10)毫秒)内,为每个查询都对每个app进行全面评分。因此,接收到查询的第一步是检索(retrieval)。检索系统使用各种信号(通常是机器学习模型和人类定义的规则的组合)返回与查询最匹配的items的简短列表。在减少候选池后,排名(ranking)系统将根据所有项目的得分对其进行排名。分数通常是P(y|x),即给定特征x(包括用户特征(如国家,语言,人口统计),上下文特征(如设备,hour of the day,day of the week)和impression特征(如app年龄,app的历史统计数据))的用户操作标签y的概率(即在给定x的条件下,用户选择y的概率)。在本文中,我们主要研究使用Wide & Deep学习框架的排名(ranking)模型。
3. WIDE & DEEP LEARNING
3.1 The Wide Component
Wide部分是一个广义线性模型,即![]() ,如图1(left)所示。y是预测结果,
,如图1(left)所示。y是预测结果,![]() 是一个d维特征向量,
是一个d维特征向量,![]()
![]() 是模型参数,b是bias。特征集包含原始输入特征和转换特征。最重要的转换是cross-product转换,定义为:
是模型参数,b是bias。特征集包含原始输入特征和转换特征。最重要的转换是cross-product转换,定义为:

(缺点:Wide部分还是需要人工特征工程)
其中![]() 是一个布尔变量,当第i个特征是第k个转换
是一个布尔变量,当第i个特征是第k个转换![]() 的一部分时,值为1;否则为0。对于二进制特征,一个cross-product转换(如“AND(gender=female, language=en)”)当且仅当特征 (“gender=female” and “language=en”)都为1时其值才为1,否则为0。其捕获了二进制特征之间的交互,并添加了非线性性到广义线性模型中。
的一部分时,值为1;否则为0。对于二进制特征,一个cross-product转换(如“AND(gender=female, language=en)”)当且仅当特征 (“gender=female” and “language=en”)都为1时其值才为1,否则为0。其捕获了二进制特征之间的交互,并添加了非线性性到广义线性模型中。
3.2 The Deep Component
Deep部分则是一个前馈神经网络,如图1(right)所示。对于类别特征,原始输入为特征字符(如“language=en”)。这些稀疏且高维的类别特征首先转变为一个低维且密集的实值向量,一般被称为一个embedding向量。embeddings的维度大小通常为O(10)到O(100)。embeddings向量先是随机初始化,然后在模型训练中,训练值去最小化最终的损失函数。这些低维的密集embedding向量将在前向传播中被输入到一个神经网络的隐藏层。具体说来,每个隐藏层的实现如下所示:
![]()
其中![]() 是层数,f是激活函数,一般是ReLUs。
是层数,f是激活函数,一般是ReLUs。![]() 分别是第
分别是第![]() 层的激活函数输出、bias和模型权重。
层的激活函数输出、bias和模型权重。
3.3 Joint Training of Wide & Deep Model
使用Wide部分和Deep部分输出对数的加权和作为预测值,然后输入到一个常用的逻辑损失函数来联合训练( joint training )。请注意, joint training 和ensemble是有区别的。在ensemble中, 每个模型在互不认识的情况下被单独训练,它们的预测只在推断时结合,而不是在训练时结合。而joint training 则是在训练时同时考虑Wide部和Deep部,并考虑Wide部和Deep部之和的权重,同时优化各参数。对模型大小也有影响:对于ensemble来说,由于训练是不相交的,每个单独的模型通常需要更大(例如,有更多的特征和转换)的大小,以达到合理的精度,使ensemble有用。相比之下,对于 joint training,Wide部分只需要通过少量的cross-product特征变换来弥补deep部分的不足,而不需要full-size wide模型。
采用mini-batch随机优化方法,将梯度从输出同时反向传播到模型的wide和deep部分,从而实现Wide & Deep模型的联合训练。在实验中,我们对模型的wide部分采用Follow-the-regularization-leader (FTRL)算法[3],其中L1正则化作为优化器,对模型的deep部分采用AdaGrad[1]进行优化。
组合模型如图1(中间)所示。对于逻辑回归问题,模型的预测为:
![]()
其中Y是二进制类标签,σ(.)是sigmoid函数,Φ(x)是原始特征x的cross product转换,b为bias项。wwide是所有wide模型权重,wdeep是应用在最后一个激活输出![]() 的权重
的权重
4. SYSTEM IMPLEMENTATION
apps推荐pipeline的实现包括三个阶段:数据生成、模型训练和模型服务,如图3所示。
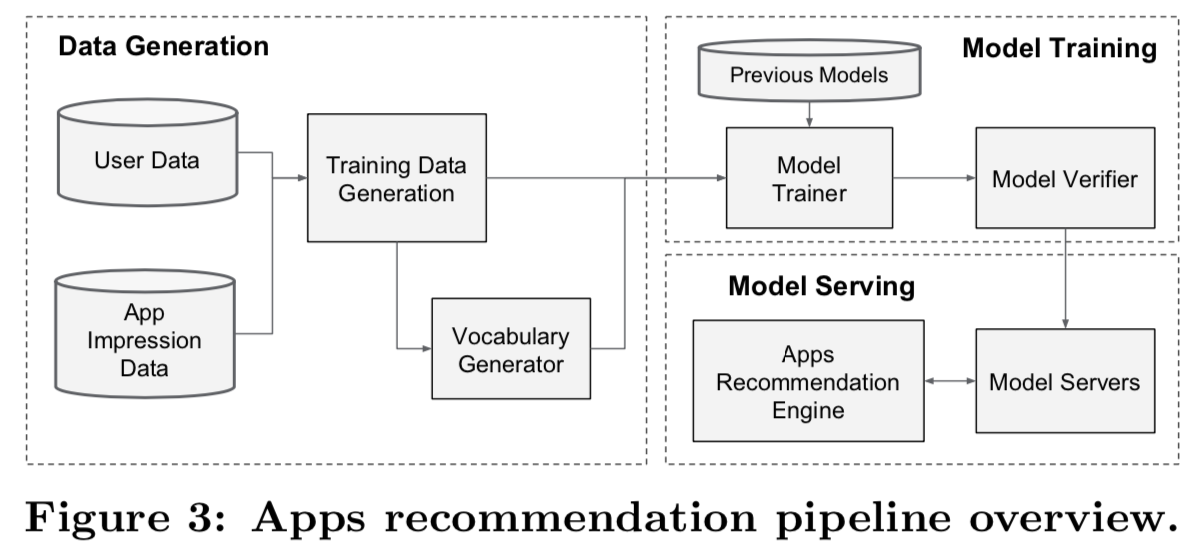
4.1 Data Generation
在这个阶段,使用一段时间内的用户和app impression数据来生成训练数据。每个例子对应一个impression。标签表示app acquisition: 如果impressed app已经安装,则为1,否则为0。
词汇表(vocabularies ,即将类别特征字符串映射到整数IDs的表)也在这个阶段生成。系统计算出现次数超过最小次数的所有字符串特征的ID空间。通过将特征值x映射到其累积分布函数P (x≤x),将连续实值特征归一化到[0,1],然后然后分解为 nq分位数。对于在第i个分位数的值,归一化值为![]() 。分位数边界在数据生成过程中计算得到。
。分位数边界在数据生成过程中计算得到。
4.2 Model Training
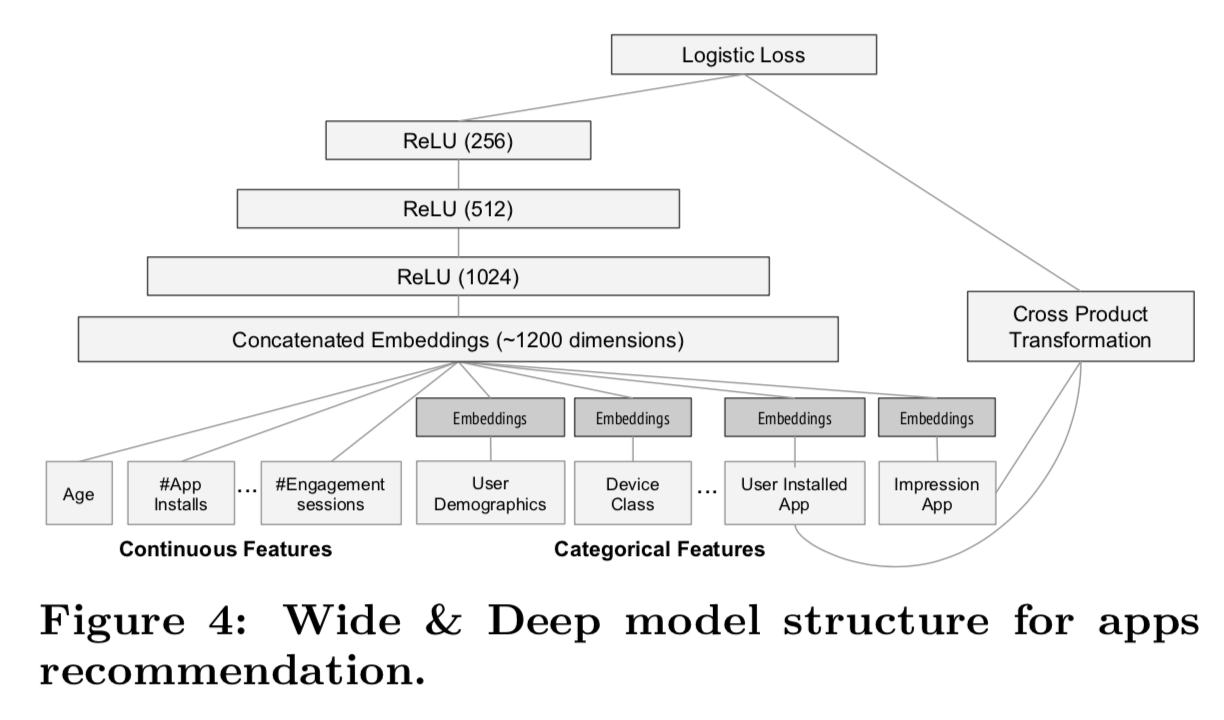
我们在实验中使用的模型结构如图4所示。
(这里的embeddings一开始的值是随机初始化来进行赋值的,然后后向传播进行训练)
在训练过程中,我们的输入层接收训练数据和词汇表,并与标签一起生成稀疏和密集的特征。wide部分包括用户安装apps和impression apps的cross-product转换。对于模型的deep部分,对每个类别特征学习一个32维的embedding向量。我们将所有embedding与密集特征连接在一起,产生一个大约1200维的密集向量。然后,连接的向量被送入3个ReLU层,最后是逻辑输出单元。
wide & deep模型训练了超过5000亿个样例。每当一组新的训练数据到达时,就需要对模型进行重新训练。然而,每次从头开始进行重新训练在计算上是非常昂贵的,并且会延迟从数据到达 到 服务更新模型的时间。为了解决这一挑战,我们实现了一个warm-starting系统,该系统使用先前模型的embeddings和线性模型权重初始化一个新模型。
在将模型加载到模型服务器之前,要对模型进行一次dry run,以确保它不会在服务实时流量时造成问题。经验上来说,我们将前一个模型作为sanity check,与其相比来验证模型的质量。
4.3 Model Serving
一旦模型经过训练和验证,我们就将它加载到模型服务器中。对于每个请求,服务器从app检索(retrieval)系统接收一组app候选和用户特征,对每个app进行评分。然后,应用从高分到低分进行排名,我们按照这个顺序将apps展示给用户。分数是通过在Wide & Deep模型上运行向前推理来计算的。
为了为每个请求提供10毫秒量级的服务,我们使用多线程并行优化了性能,通过并行运行更小的batches,而不是在单个batch推理步骤中对所有候选apps打分。
5. EXPERIMENT RESULTS
为了评估Wide & Deep learning在真实世界推荐系统中的有效性,我们进行了现场实验,并从app获取和服务性能两个方面对系统进行了评估。
5.1 App Acquisitions
我们在A/B测试框架中进行了3周的在线实验。在对照组中,随机选择1%的用户,并向其提供由之前版本的排名模型生成的推荐,该模型是一个高度优化的仅有wide部分的逻辑回归模型,具有丰富的cross-product特征转换。对于实验组,1%的用户被提供了由Wide & Deep模型生成的推荐,该模型使用相同的特征集进行训练。如表1所示,与对照组相比,Wide & Deep模型使app商店主登录页面的app获取率提高了+3.9%(具有统计学意义)。结果还与另外1%组(即仅使用模型的deep部分,具有相同的特征和神经网络结构)进行了比较,Wide & Deep模式在仅有deep部分的模型的基础上有+1%的增益(具有统计学意义)。

除了在线实验外,我们还在离线状态下给出了Area Under Receiver Operator Characteristic Curve (AUC)。虽然Wide & Deep的AUC仅仅只是略高于其他两个模型,但其对在线流量的影响更大。一个可能的原因是,离线数据集中的impressions和标签是固定的,而在线系统可以通过混合泛化和记忆生成新的探索性推荐,并从新的用户反馈中学习。
5.2 Serving Performance
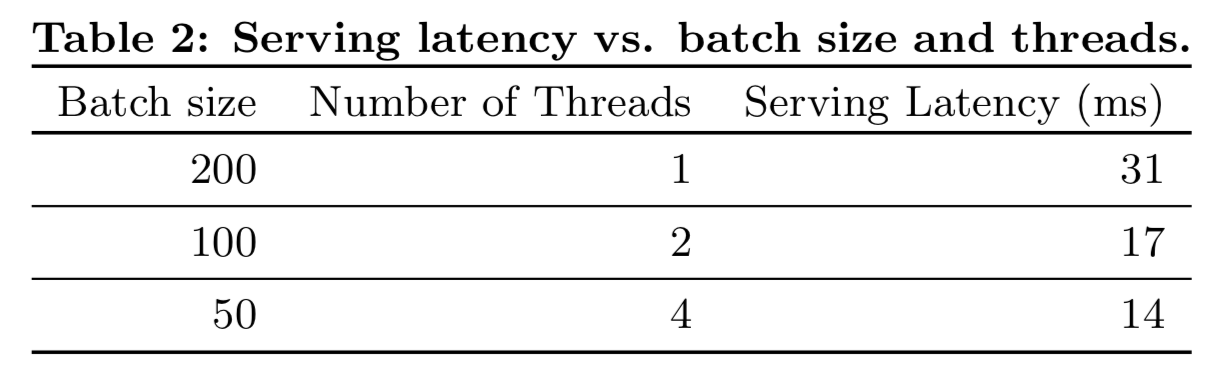
对于我们的商业移动app商店来说,高流量和低延迟的服务是一个挑战。在流量高峰时,我们的推荐服务器每秒会为超过1000万个apps打分。使用单线程,在单个batch中对所有候选人打分需要31毫秒。我们实现了多线程,并将每个batch分割成更小的大小,这将客户端延迟显著降低到14毫秒(包括服务开销),如表2所示。
6.RELATED WORK
将带有cross-product特征变换的wide线性模型和带有密集embeddings的深度神经网络相结合的想法是受到以前工作的启发,例如factorization machines[5],它通过将两个变量之间的相互作用分解为两个低维embedding向量之间的点积来对线性模型进行泛化。在本文中,我们通过神经网络学习embeddings之间高度非线性的交互来扩展了模型的容量,而不是通过点积。
在语言模型中,提出了联合训练递归神经网络(RNNs)和具有n-gram特征的最大熵模型,通过学习输入和输出[4]之间的直接权值,显著降低RNN的复杂性(如隐藏层大小)。在计算机视觉中,深度残差学习[2]已经被用来降低训练深度模型的难度,并通过shortcut连接跳过一个或多个层来提高精度。神经网络与图形模型的联合训练也被应用于从图像[6]中估计人体姿态。在这项工作中,我们探索了前馈神经网络和线性模型的联合训练,将稀疏特征和输出单元直接连接起来,用于具有稀疏输入数据的通用推荐和排序问题。
在推荐系统文献中,通过将内容信息的深度学习和ratings矩阵[7]的协同过滤(CF)耦合在一起,对协作深度学习进行了探索。之前也有用于移动app推荐系统的工作,如AppJoy是在用户的app使用记录[8]上使用CF。与之前的基于CF或基于内容的方法不同,我们联合使用用户和impression数据训练Wide & Deep模型,用于app推荐系统。
7. CONCLUSION
记忆和泛化对于推荐系统都很重要。wide线性模型可以通过cross-product特征变换有效地记忆稀疏特征交互,而深度神经网络可以通过低维embeddings来推广之前未见过的特征交互。我们提出了Wide & Deep学习框架,结合了两种模型的优点。我们在大型商业app商店Google Play的推荐系统上进行了框架的制作和评估。在线实验结果表明,与仅有Wide和仅有Deep的模型相比,Wide & Deep模型在app获取上有显著改善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号