

Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks - 1 - 论文学习
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
Abstract
注意力机制,尤其是自注意力(self-attention),在视觉任务的深度特征表征中起着越来越重要的作用。自注意力通过在所有位置上使用成对的affinities计算特征的加权和来更新每个位置上的特征,以捕获单个样本中的long-range依赖关系。然而,自注意力具有二次复杂度,且忽略了不同样本之间的潜在相关性。本文提出了一种新颖的外部注意力机制,即外部注意力机制(external attention),它基于两个外部的、小的、可学习的共享memories,只需简单地使用两个级联线性层和两个归一化层即可实现;使用起取代现有流行结构中的自注意力是很方便的。外部注意力具有线性复杂性,隐式考虑了所有数据样本之间的相关性。我们进一步将multi-head机制纳入到外部注意力中,以提供用于图像分类的all-MLP体系结构,即外部注意力MLP ( external attention MLP,EAMLP)。大量关于图像分类、目标检测、语义分割、实例分割、图像生成和点云分析的实验表明,我们的方法提供的效果等同或优于自注意力机制及其某些变量,而且计算和存储成本更低。
1 INTRODUCTION
由于其捕获长期依赖的能力,自注意力(self-attention)机制有助于提高各种自然语言处理[1]、[2]和计算机视觉[3]、[4]任务的性能。自注意力的工作原理是通过聚合单个样本中所有其他位置的特征来细化每个位置的表征,这导致了一个样本中关于位置数量的二次幂计算复杂度。因此,一些变体试图以较低的计算成本来近似自注意力方法[5],[6],[7],[8]。
此外,自注意力关注的是单个样本内不同位置之间的亲和度(affinities),而忽略了与其他样本之间的潜在相关性。很容易看出,合并不同样本之间的相关性有助于更好地表示特征。例如,在语义分割任务中,属于同一类别但分布在不同样本中的特征应该得到一致的处理,在图像分类和其他各种视觉任务中也有类似的观察结果。
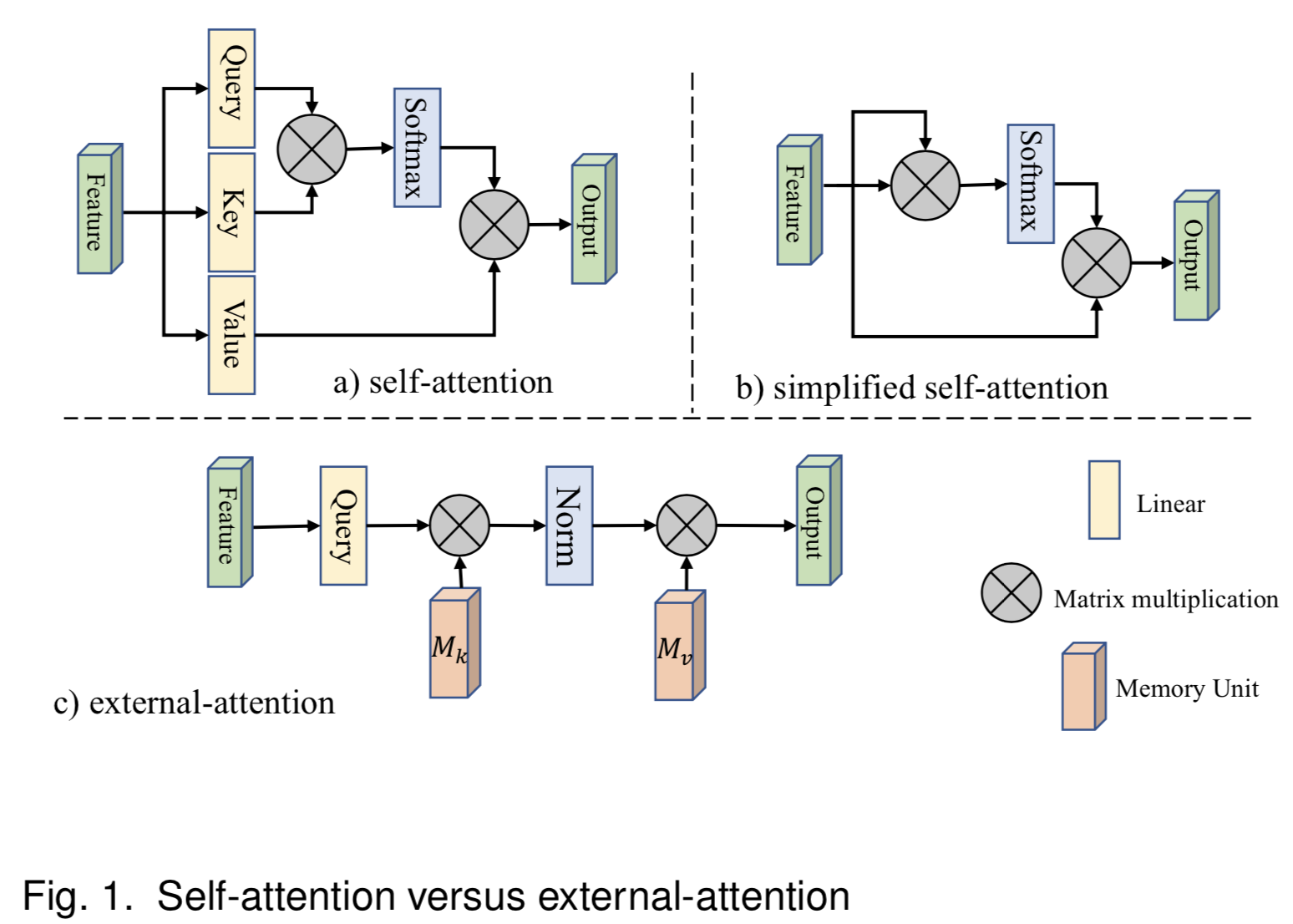
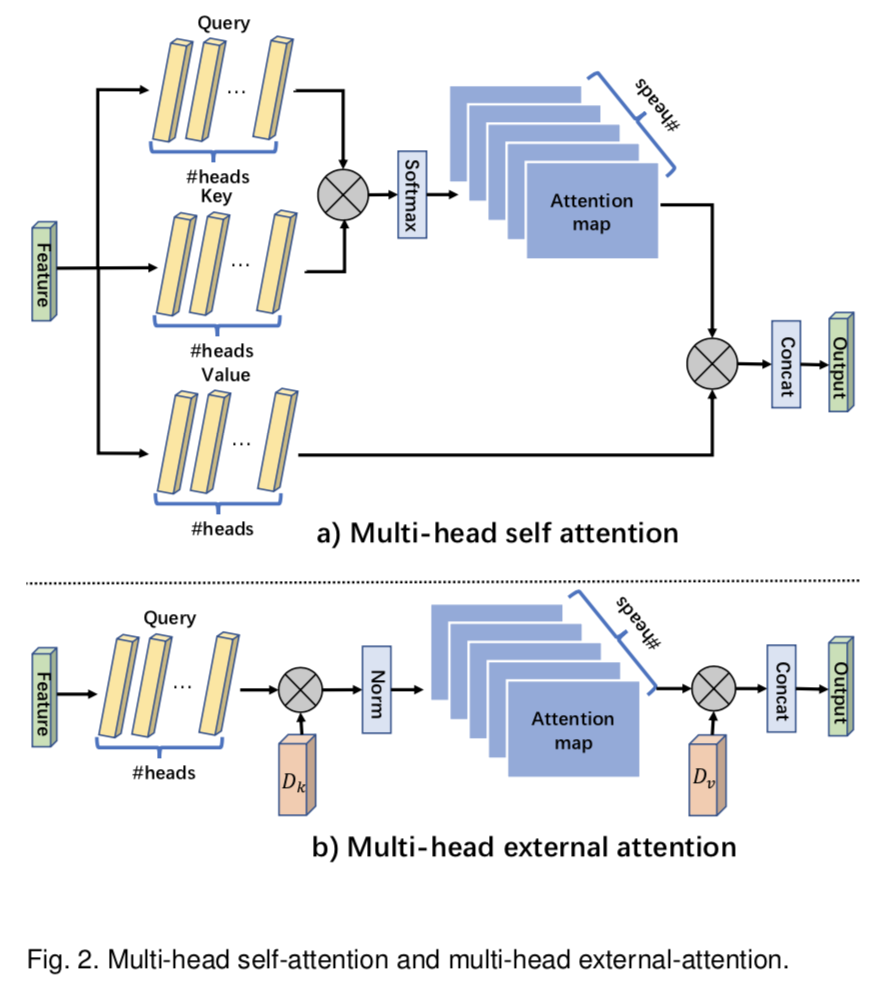
本文提出了一种新的轻量级注意机制,我们称之为外部注意力(external attention,见图1c)。如图1a)所示,计算自注意力需要首先通过计算self query vectors和self key vectors之间的亲和度来计算一个注意力map,然后通过该注意力map对self value vectors进行加权来生成一个新的特征map。外部注意力的工作原理是不同的。我们首先通过计算self query vectors与一个external learnable key memory之间的亲和度来计算注意力map,然后通过将该注意力map与另一个external learnable value memory相乘来得到一个精细的特征map。
在实践中,这两个memories是用线性层实现的,因此可以通过端到端反向传播的方式进行优化。它们独立于单个样本,并在整个数据集中共享,起到了很强的正则化作用,提高了注意力机制的泛化能力。外部注意力的轻量级本质的关键在于,memories中的元素数量比输入特征中的元素数量要少得多,这就产生了关于输入元素数量的线性计算复杂度。外部memories的目的是学习整个数据集中最具区别性的特征,捕捉信息最丰富的部分,以及排除其他样本的干扰信息。在稀疏编码(sparse coding)[9]或字典学习(dictionary learning)[10]中也可以找到类似的思想。然而,与这些方法不同的是,我们既没有尝试重建输入特征,也没有对注意力map应用任何显式稀疏正则化。
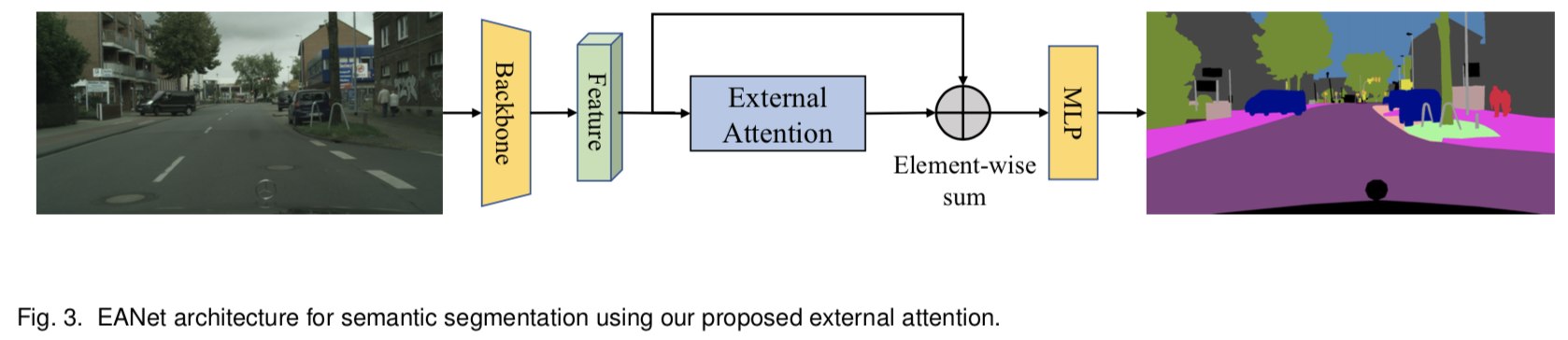
虽然所提出的外部注意力方法很简单,但它对各种视觉任务都是有效的。由于它的简单性,它可以很容易地合并到现有的流行的基于自注意力的架构中,如DANet [4], SAGAN[11]和T2T-Transformer[12]。图3展示了一个典型的架构,它用我们的外部注意力来代替自注意力来完成图像语义分割任务。我们使用不同的输入模式(图像和点云),在诸如分类、目标检测、语义分割、实例分割和生成等基本视觉任务上进行了广泛的实验。结果表明,我们的方法以更低的计算代价获得了与原自注意力机制及其某些变体相当或更好的结果。
我们将multi-head机制引入到外部注意力中,以提高外部注意力的能力。受益于提出的multi-head外部注意力,我们设计了一个名为EAMLP的全新的all-MLP体系结构,它可以媲美CNNs和原始的Transformers来完成图像分类任务。
本文的主要贡献总结如下:
- 提出一个新的复杂度为O(n)的注意力机制 - 外部注意力;它可以取代现有架构中的自注意力。它可以挖掘整个数据集的潜在关系,具有很强的正则化作用,提高了注意力机制的泛化能力。
- multi-head外部注意力,这有利于我们构建一个all MLP体系结构;它在ImageNet-1K数据集上实现了79.4%的top-1准确度。
- 利用外部注意力对图像分类,目标检测,语义分割,实例分割,图像生成,点云分类和点云分割进行了广泛的实验。在计算工作量必须保持在较低水平的情况下,它能获得比原始的自注意力机制及其某些变体更好的结果
2 Related work
由于对注意力机制的全面回顾超出了本文的范围,我们只讨论视觉领域中与之最密切相关的文献。
2.1 The attention mechanism in visual tasks
注意力机制可以看作是一种根据激活的重要性来重新分配资源的机制。它在人类视觉系统中起着重要的作用。在过去十几年中,该领域得到了蓬勃的发展[3] [13] [14] [15] [16] [17] [18]。Hu等人提出了SENet[15],表明注意力机制可以降低噪声,提高分类性能。随后,许多其他论文将其应用于视觉任务。Wang等人提出了用于视频理解的non-local网络[3],Hu等人[19]将注意力用于目标检测,Fu等人提出用于语义分割的DANet[4],Zhang等人[11]演示在图像生成中注意力机制的有效性,和Xie等人提出A-SCN[20]进行点云处理。
2.2 Self-attention in visual tasks
自注意力是注意力的一种特殊情况,许多论文[3],[4],[11],[17],[21]都考虑了视觉的自注意力机制。自注意力的核心思想是计算特性之间的亲和度,以捕获长期依赖关系。但是,随着特征map的增大,计算和内存开销会呈幂次增长。为了减少计算和内存开销,Huang等人提出了criss-cross注意力,它依次考虑行注意和列注意来捕获全局上下文。Li等[6]采用期望最大化(EM)聚类优化自注意力。Yuan等人提出使用object-contextual向量来处理注意力;然而,它依赖于语义标签。Geng等[8]研究表明,在语义分割和图像生成中,矩阵分解是一种更好的全局上下文建模方法。其他研究[22],[23]也探索了使用自注意力机制提取局部信息。
与通过计算self queries和self keys之间的亲和度来获得注意力map的自注意力不同,我们的外部注意力计算self queries和一个更小的可学习key memory之间的关系,后者捕获数据集的全局上下文。外部注意力不依赖于语义信息,可以通过反向传播算法进行端到端的优化,而不需要迭代算法。
2.3 Transformer in visual tasks
基于transformer的模型在自然语言处理[1]、[2]、[16]、[24]、[25]、[26]、[27]方面取得了巨大的成功。最近,他们也展示了其在视觉任务的巨大潜力。Carion等人[28]提出了一种端到端detection transformer,它以CNN特征作为输入,用transformer生成bounding boxes。Dosovitskiy[18]提出了基于patch encoding和transformer的ViT,表明在有足够的训练数据的情况下,transformer比传统的CNN具有更好的性能。Chen等人提出了基于transformer的iGPT图像生成方法。
随后,transformer方法已经成功应用于许多视觉任务,包括图像分类[12]、[30]、[31]、[32]、目标检测[33]、低级视觉(lower-level vision)[34]、语义分割[35]、跟踪[36]、视频实例分割[37]、图像生成[38]、多模态学习(multimodal learning)[39]、目标再识别(object re-identification)[40]、图像字幕[41],点云学习[42],自监督学习[43]。读者可以参考最近的调查[44],[45],以更全面地了解transformer方法在视觉任务中的使用。
3 METHODOLOGY
在这一节中,我们将从分析最初的自注意力(self-attention)机制开始。然后我们详细介绍了我们定义的新方法:外部注意力(external attention)。只需使用两个线性层和两个归一化层,就可以很容易地实现它,如算法1所示。

3.1 Self-Attention and External Attention
我们首先回顾一下自注意力机制(可见图1a)。给定一个输入特征map ![]() ,其中N是元素数量(或图像像素数量),d是特征维度数,自注意力线性投射输入为一个query矩阵
,其中N是元素数量(或图像像素数量),d是特征维度数,自注意力线性投射输入为一个query矩阵![]() 、一个key矩阵
、一个key矩阵![]() 和一个value矩阵
和一个value矩阵![]() [16]。自注意力公式为:
[16]。自注意力公式为:
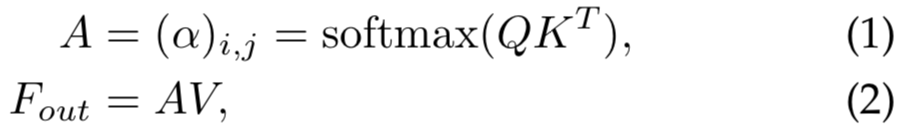
其中![]() 是注意力矩阵,
是注意力矩阵,![]() 是第i个和第j个元素的成对亲和度值。
是第i个和第j个元素的成对亲和度值。
自注意力的一个常用简化版变体(图1b)直接从输入特征![]() 计算了一个注意力map,式子如下:
计算了一个注意力map,式子如下:
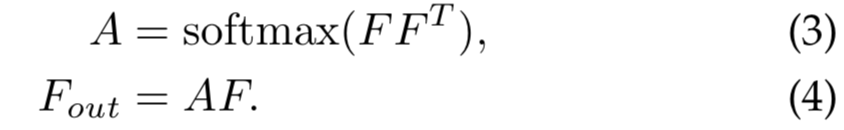
这里通过在特征空间中计算像素级相似度得到注意力map,输出是输入的精细化特征表征。
然而,即使经过简化,O(dN2)的高计算复杂度也给自注意力的使用带来了一个重大缺陷。输入像素数的二次复杂度使得将自注意力直接应用于图像是不可行的。因此,之前的工作[18]利用对patches而不是像素的自注意力来减少计算工作量。
自注意力可以看作是self values的线性组合来细化输入特征。然而,在这个线性组合中,我们是否真的需要N × N的自注意矩阵和N个元素的self value矩阵,这一点并不明显。此外,自注意力只考虑了数据样本中元素之间的关系,而忽略了不同样本中元素之间的潜在关系,潜在地限制了自注意力的能力和灵活性。
因此,我们提出了新的注意力模块,命名为外部注意力(external attention),用于计算输入像素和一个external memory单元![]() 的注意力,公式为:
的注意力,公式为:
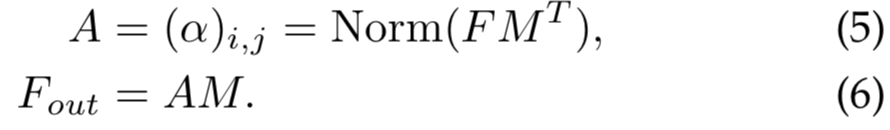
和自注意力不同,等式(5)中的![]() 是第i个像素和M第j行的相似度,其中M是一个独立于输入的可学习参数,其作为整个训练数据集的memory。A是从该已学好的dataset-level先验知识推导得到的注意力map;以相同的方法归一化为自注意力(可见3.2节)。最后,我们通过A的相似度更新M的输入特性。
是第i个像素和M第j行的相似度,其中M是一个独立于输入的可学习参数,其作为整个训练数据集的memory。A是从该已学好的dataset-level先验知识推导得到的注意力map;以相同的方法归一化为自注意力(可见3.2节)。最后,我们通过A的相似度更新M的输入特性。
实际上,我们使用两个不同的memory单元![]() 和
和![]() 作为key和value,去增强网络的能力。因此外部注意力的计算变为:
作为key和value,去增强网络的能力。因此外部注意力的计算变为:
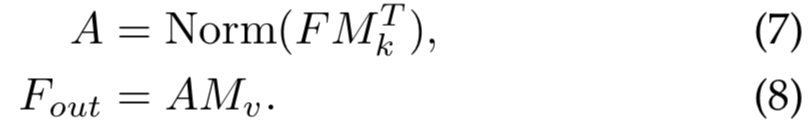
外部注意力的计算复杂度是O(dSN);d和S是超参数,该算法在像素数上是线性的。实际上,我们发现一个小的S,如64,就能在实验中得到好效果。因此,外部注意力是比自注意力高效的,允许其直接应用到大尺度输入中。我们还注意到外部注意力的计算负载粗略等价于1x1卷积。
3.2 Normalization
自注意力中使用Softmax去归一化注意力map,因此![]() 。然而,注意力map是通过矩阵乘法计算出来的。与余弦相似度不同,注意力map对输入特征的scale非常敏感。为了避免这个问题,我们选择[42]中提出的double-normalization,它分别归一化列和行。这种double-normalization 公式为:
。然而,注意力map是通过矩阵乘法计算出来的。与余弦相似度不同,注意力map对输入特征的scale非常敏感。为了避免这个问题,我们选择[42]中提出的double-normalization,它分别归一化列和行。这种double-normalization 公式为:
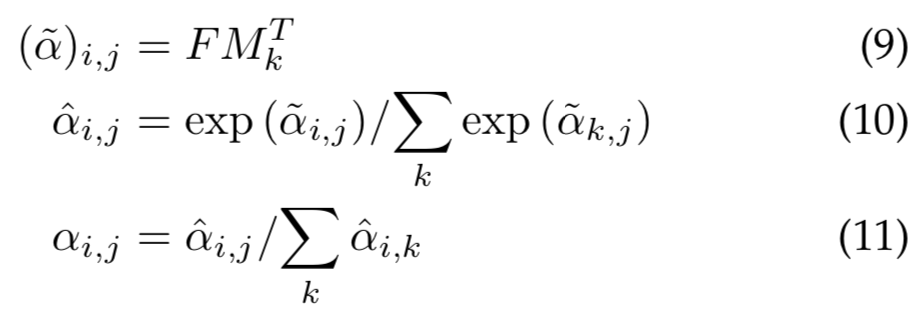
外部注意力的python版伪代码为:

3.3 Multi-head external attention
在Transformer[16]中,自注意在不同的输入channels上计算多次,这称为multi-head注意力。multi-head注意力可以捕获tokens之间的不同关系,提高了single head注意力的能力。我们对
multi-head外部注意力可以写成:
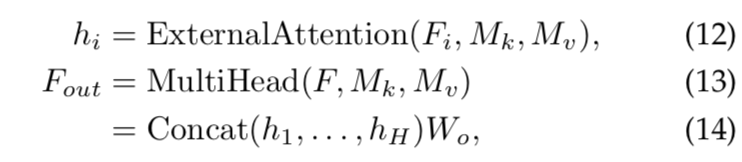
其中hi是第i个head,H是heads的数量,Wo是一个用来保持输入输出维度一致的线性转换矩阵。![]() 和
和![]() 是不同heads共享的memory单元
是不同heads共享的memory单元
这种架构的灵活性允许我们在共享memory单元中平衡head H的数量和元素S的数量。例如,我们可以用H乘以k,同时用S除以k。
4 EXPERIMENTS
我们在图像分类、目标检测、语义分割、实例分割、图像生成、点云分类和点云分割任务上进行了实验,以评估我们提出的外部注意方法的有效性。所有实验都是用Jittor[86]和/或Pytorch[87]深度学习框架上实现的。
4.1 Ablation study
为了在我们的完整模型中验证所提出的模块,我们在PASCAL VOC分割数据集上进行了实验[88]。图3描述了用于消融研究的架构,该架构以FCN[46]为特征backbone。batch size和总迭代次数分别设置为12和30000次。我们关注memory单元的数量、自注意力与外部注意力、backbone、归一化方法和backbone的输出步幅。如表1所示,在Pascal VOC数据集上,我们可以观察到外部注意力比自注意力具有更好的准确性。选择合适数量的memory单元对结果的质量很重要。归一化方法可以对外部注意力产生巨大的积极影响,并对自注意力效果进行改善。

4.2 Visual analysis
使用外部注意力进行分割的注意力map(见图3)和使用multi-head 外部注意力进行分类的注意力map(见章节4.3)分别如图4和图5所示。我们从一个层的memory单元Mk中随机选择一行![]() 。然后通过计算
。然后通过计算![]() 对输入特征的注意力来绘制注意力map。我们观察到,在分割任务中,学习到的注意力map集中在有意义的物体或背景上,如图4所示。图5中最后两行说明Mk的不同行注意的区域不同。multi-head外部注意力的每个head都能不同程度地激活兴趣区域,如图5所示,提高了外部注意力的表征能力。
对输入特征的注意力来绘制注意力map。我们观察到,在分割任务中,学习到的注意力map集中在有意义的物体或背景上,如图4所示。图5中最后两行说明Mk的不同行注意的区域不同。multi-head外部注意力的每个head都能不同程度地激活兴趣区域,如图5所示,提高了外部注意力的表征能力。


4.3 Image classification
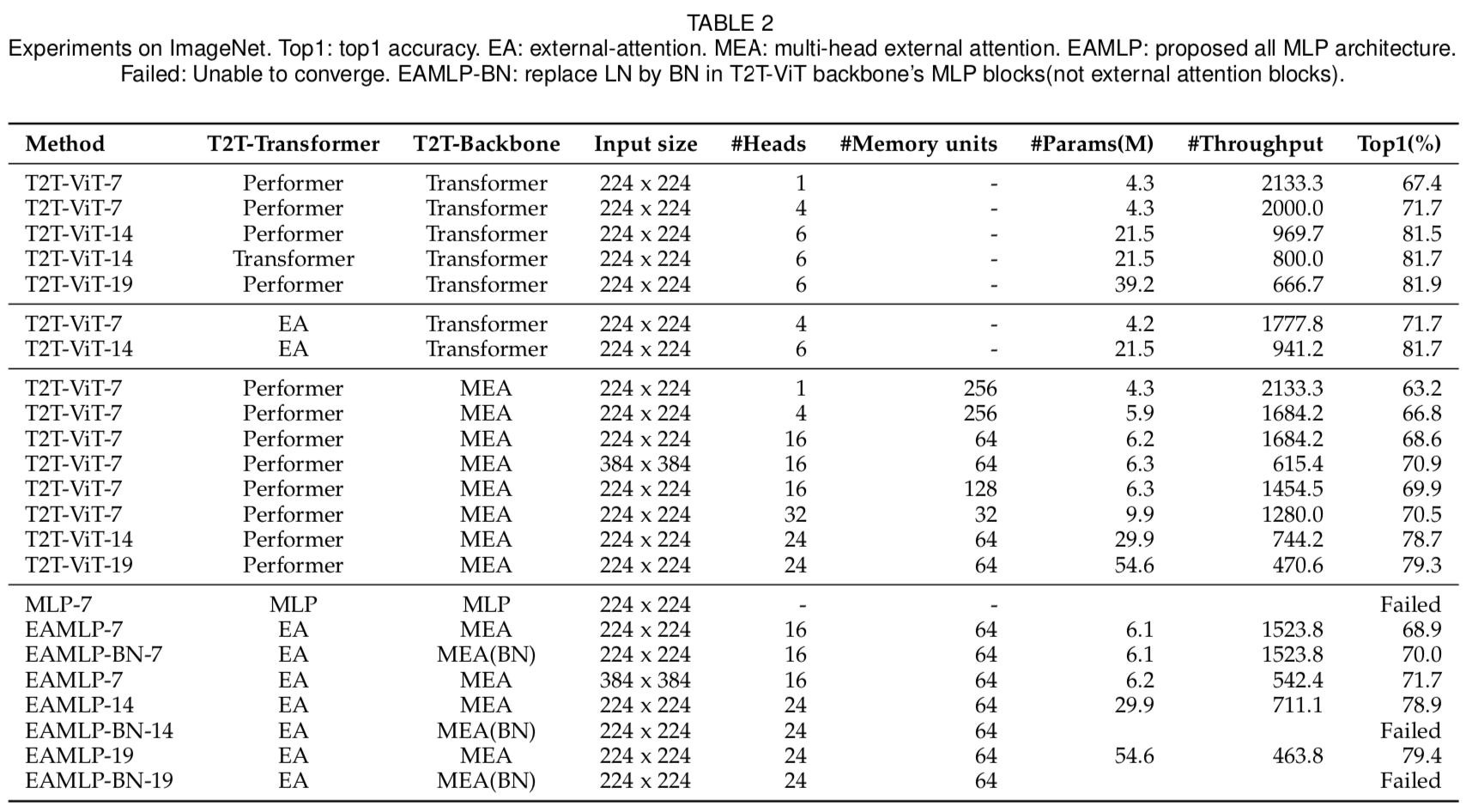
ImageNet-1K[89]是一种广泛用于图像分类的数据集。我们将T2T-ViT[12]中的Performer[90]和multi-head自注意力块替换为外部注意力和multi-head外部注意力。为公平起见,其他超参数设置与T2T-ViT相同。表2的实验结果表明,外部注意力的结果比Performer[90]更好,比multi-head注意力的结果低约2%。我们发现multi-head机制对自注意力和外部注意力都是必要的。我们还尝试了MoCo V3[43]提出的策略,以BatchNorm(BN)[92]替代T2T-ViT backbone的MLP块(非外部注意力块)中的LayerNorm(LN)[91]。我们观察到我们的EAMLP-7有1%的改善。然而,它在我们的大型模型EAMLP-14和EAMLP-19中产生了失败的效果。
4.4 Object detection and instance segmentation
MS COCO数据集[93]是一个流行的目标检测和实例分割基准。它包含超过200,000张图片,其中包含来自80个类别的500,000多个带注释的对象实例。
MMDetection[47]是一个被广泛使用的用于对象检测和实例分割的工具包。我们使用基于RestNet-50 backbone的MMDetection对COCO数据集进行了目标检测和实例分割实验。我们只是在Resnet stage 4的末尾才增加了外部注意力。表3和表4的结果显示,外部注意力使目标检测和实例分割任务的准确率都提高了1%。

4.5 Semantic segmentation
在本次实验中,我们采用图3中的语义分割架构,将其称为EANet,并将其应用于Pascal VOC[88]、ADE20K[94]和cityscapes[95]数据集。
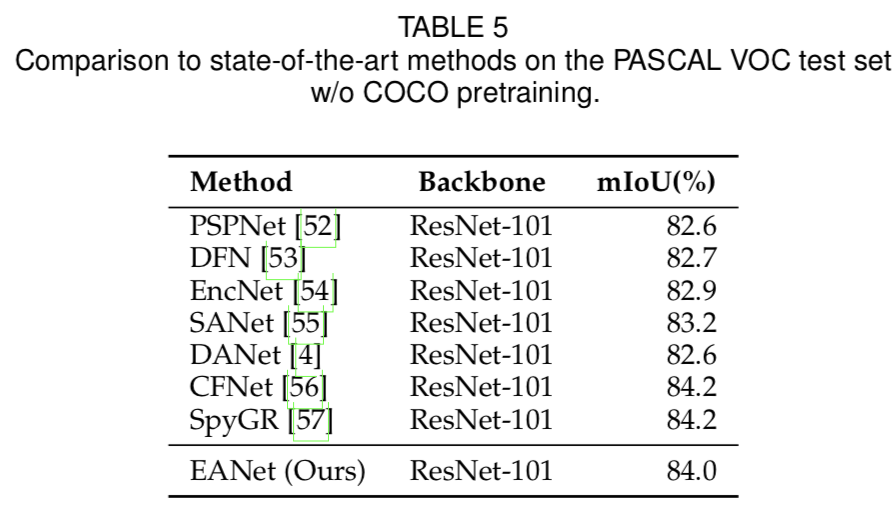
Pascal VOC包含10,582张用于训练的图像,1,449张用于验证的图像,1,456张用于测试的图像。在分割中,它有20个foreground对象类和一个的背景类。与所有比较方法一样,我们使用输出stride为8的dilated ResNet-101作为backbone;它是在ImageNet-1K上进行预训练的。在训练过程中采用了多元学习率策略(poly-learning rate policy)。初始学习率、batch size和输入大小分别设置为0.009、16和513 × 513。我们首先在训练集上训练了45k次迭代,然后在trainval集上微调了15k次迭代。最后,我们在测试集上使用了multi-scale和flip测试。可视化结果如图4所示,定量结果如表5所示:我们的方法可以达到与现有方法相当的性能。
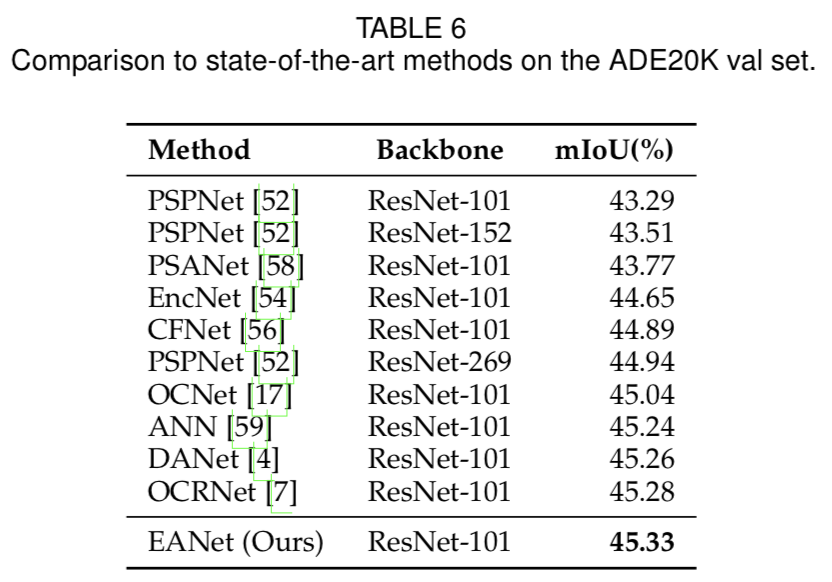
ADE20K是一个更具挑战性的数据集,它有150个类,以及20K、2K和3K张分别用于训练、验证和测试的图像。我们采用dilated ResNet-101作为backbone,输出stride为8。实验配置与mmsegmentation[60]相同,训练ADE20K进行160k次迭代。表6的结果显示,我们的方法在ADE20K val集上优于其他方法。
Cityscapes在19个用于城市场景理解的语义类中包含了5000个高质量且具有像素级精细注释的标签。每个图像都是1024×2048像素。分为2975张、500张和1525张,分别用于训练、验证和测试。(它还包含2万张粗略标注的图像,我们在实验中没有使用它们)。我们采用dilated ResNet-101作为所有方法的backbone,输出stride为8。实验配置与mmsegmentation相同,用80k次迭代训练Cityscapes。表7的结果显示,在cityscapes val集合上,我们的方法获得了与最先进的方法(即DANet[4])相当的结果。

4.6 Image generation
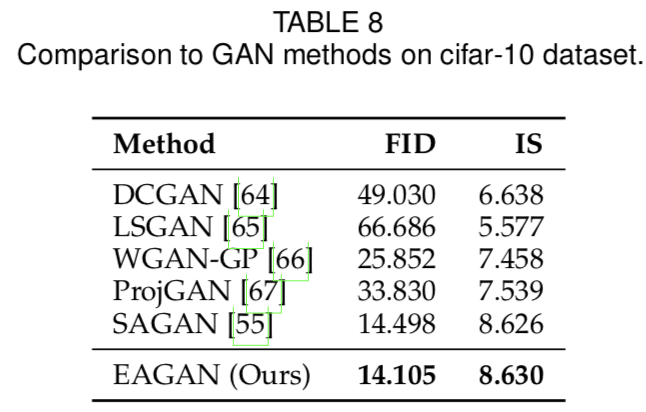
自注意力是图像生成中常用的方法,典型的方法是SAGAN[11]。我们将SAGAN生成器和鉴别器中的自注意力机制替换为我们的外部注意力方法,从而得到我们的EAGAN模型。所有实验都基于流行的PyTorch-StudioGAN repo[96]。超参数使用SAGAN的默认配置。我们使用Frechet Inception Distance (FID)[97]和Inception Score (IS)[98]作为我们的评估指标。部分生成的图像如图6所示,定量结果在表8和表9中给出:外部注意力为SAGAN和其他的GANs提供了更好的结果。


4.7 Point cloud classification
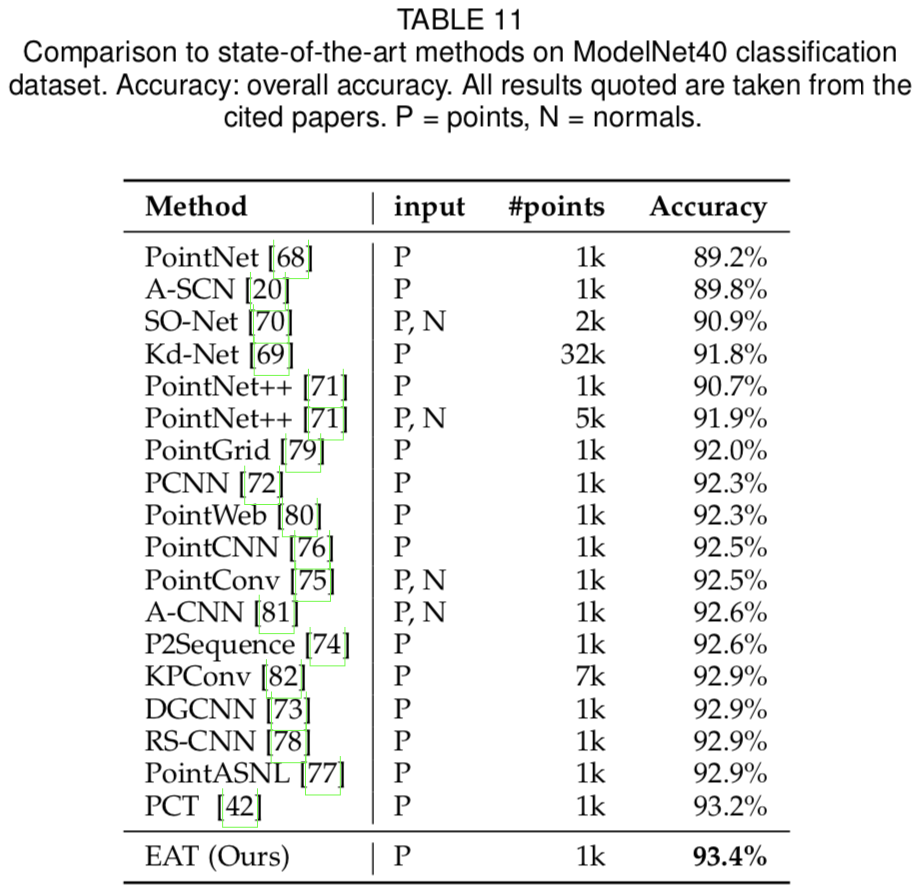
ModelNet40[99]是一种流行的3D形状分类基准,包含40个类别的12,311个CAD模型。它有9843个训练样本和2468个测试样本。我们的EAT模型取代了PCT[42]中的所有自注意力模块。我们在每个形状上取样1024个点,并使用如PCT[42]中的随机平移、anisotropic缩放和dropout 增强输入。表11表明,我们的方法优于其他所有方法,包括其他基于注意力的方法,如PCT,我们提出的方法为2D和3D视觉提供了一个出色的backbone。
4.8 Point cloud segmentation
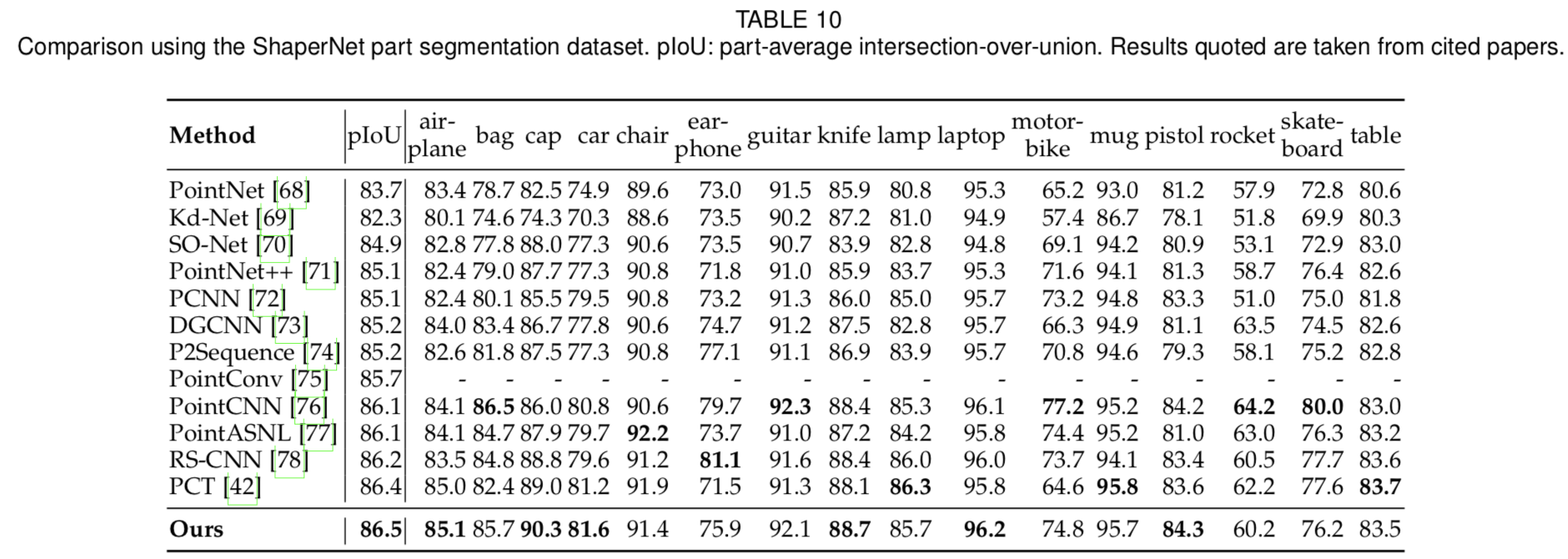
我们在ShapeNet部分数据集上进行了点云分割实验[100]。训练集中有14006个3D模型,评估集中有2874个。每个形状被分割成parts,共16个对象类别和50个part标签。我们遵循PCT[42]的实验设置。EAT在这个数据集上取得了最好的结果,如表10所示。
4.9 Computational requirements
关于输入大小的线性复杂度带来了效率上的显著优势。我们在输入大小为1 × 512 × 128 × 128的情况下,将外部注意力(EA)模块与标准自注意力(SA)[16]及其几个变体在参数数量和推理操作方面进行了比较,结果如表12所示。外部注意力只需要自注意力所需参数的一半,而且速度要快32倍。与最好的变体相比,外部注意力的速度仍然是前者的两倍。

5 CONCLUSIONS
本文提出了一种新型的、轻量级的、有效的、适用于各种视觉任务的注意机制——外部注意力。外部注意力所采用的两个外部memory单元可以看作是整个数据集的字典,能够学习更多的输入的代表性特征,同时降低计算代价。我们希望外部注意力能够激发它在其他领域的实际应用和研究,比如自然语言处理。
