
人脸识别(Unseen Domains) - 1 - Learning Meta Face Recognition in Unseen Domains - 1 - 论文学习
Learning Meta Face Recognition in Unseen Domains
Abstract
人脸识别系统在实际应用中往往面临未知领域,由于其泛化能力较差,导致性能不理想。例如,一个训练良好的webface数据模型不能处理监视场景中的ID vs. Spot任务。在本文中,我们的目的是学习一个可以直接处理新的未知域的泛化模型,而不需要任何模型更新。为此,我们提出了一种基于元学习的人脸识别方法,命名为Meta Face Recognition (MFR)。MFR用一个元优化目标函数来合成源/目标域偏移,这要求模型不仅学习合成源域上的有效表征,而且学习合成目标域上的有效表征。具体来说,我们通过域级采样策略构建domain-shift batches,通过优化多域分布得到合成源/目标域的反向梯度/元梯度。在此基础上,进一步结合元梯度对模型进行了更新,提高了模型的泛化能力。此外,我们还提出了两种用于泛化人脸识别评价的基准。通过与一些基线和其他最先进技术比较,在我们的基准上的实验验证了我们的方法的泛化能力。代码可见https://github.com/cleardusk/MFR
1. Introduction
人脸识别是研究领域的一个长期课题。最近的研究[1,2,3,4,5,6,7,8]在一些常见的基准上,如LFW [9], YTF[10]和megface[11],将性能推到了一个非常高的水平。这些方法是基于CASIA-Webface[12]、MS-Celeb[13]等训练集和测试集具有相似的分布的假设的。然而,在人脸识别的实际应用中,在源域![]() 上训练的模型通常部署在具有不同分布的另一个域
上训练的模型通常部署在具有不同分布的另一个域![]() 中。有两种场景:(i)目标域
中。有两种场景:(i)目标域![]() 已知,数据可访问。(二)目标域没见过。第一种场景的方法被分类为域自适应人脸识别(domain adaptation for face recognition),其中常见的设置是源域
已知,数据可访问。(二)目标域没见过。第一种场景的方法被分类为域自适应人脸识别(domain adaptation for face recognition),其中常见的设置是源域![]() 包含有标签的人脸域,目标域
包含有标签的人脸域,目标域![]() 包含有或没有标签的人脸。域自适应方法试图将从
包含有或没有标签的人脸。域自适应方法试图将从![]() 中学习到的知识应用到
中学习到的知识应用到![]() 中,使模型在
中,使模型在![]() 中具有较好的通用性。第二种场景可以看作是人脸识别的域泛化,我们称之为泛化人脸识别,因为训练的模型通常部署在未知的场景中,面对没见过的数据。如图1所示,部署的模型应该能够推广到未知的领域,而不需要任何更新或微调。
中具有较好的通用性。第二种场景可以看作是人脸识别的域泛化,我们称之为泛化人脸识别,因为训练的模型通常部署在未知的场景中,面对没见过的数据。如图1所示,部署的模型应该能够推广到未知的领域,而不需要任何更新或微调。

与域自适应方法相比,泛化人脸识别研究较少,且具有较大的挑战性,因为它不对目标域进行假设。据我们所知,目前还没有关于泛化人脸识别问题的相关研究。一个相关的任务是视觉识别的域泛化,它假设源域和目标域共享相同的标签空间,并且是一个小的集合,如7个类别[14]。然而,泛化人脸识别是一个open-set问题,具有更大的类别规模,现有的方法对其不适用。
在这篇文章中,我们的目的是学习一个模型的泛化人脸识别问题。一旦在一组源域上进行了训练,模型就可以直接部署到一个未知域上,而不需要任何模型更新。受[14,15]的启发,我们提出了一种新的元学习人脸识别框架,命名为Meta face recognition (MFR)。MFR通过一个元优化目标函数来模拟源/目标域的移动,优化模型不仅在合成源域上学习有效的人脸表征,而且在合成目标域上学习有效的人脸表征。采用域级采样策略模拟域转移,将源域划分为元训练域/元测试域。为了优化多域分布,我们提出了三种方法:1)hard-pair注意损失优化了hard pairs的局部分布;2)soft分类损失考虑了batch中的全局关系;3)域对齐损失学习通过对齐域中心来减少元训练域差异。将这三种损失结合起来学习域不变且具有区分度的人脸表征。通过元优化,将来自元训练域和元测试域的元梯度进行聚合,并用于更新网络以提高模型泛化能力。与传统的元学习方法相比,我们的MFR不需要对目标域进行模型更新,可以直接处理未知域。
我们的主要贡献包括:(i)我们首次强调了泛化人脸识别问题,这需要一个训练有素的模型在未知域上很好地泛化,而不需要任何更新。(ii)提出了一种新的Meta Face Recognition(MFR)框架来解决泛化人脸识别问题,该框架通过跨域元学习可迁移的知识来改善模型的泛化能力。(iii)设计了两个通用的人脸识别基准进行评价。在提出的基准上的大量实验验证了我们方法的有效性。
2. Related work
Domain Generalization. 域泛化可以追溯到[16,17]。DICA[17]采用基于内核的优化方法去学习域不变特征。CCSA[18]可以通过将源域分布对齐到目标域分布来处理域自适应和域泛化问题。MLDG[14]首先采用元学习方法MAML[15]进行域泛化。与域自适应相比,域泛化是一个研究较少的问题。此外,上述域泛化工作主要集中在源域和目标域共享相同标签空间的closed-set类别级识别问题。相比之下,我们的泛化人脸识别问题更具挑战性,因为目标类与源类是不相交的。这意味着泛化人脸识别是一个open-set问题,而不是像MLDG[14]那样的closed-set问题,我们必须同时处理域间隙和不相交的标签空间。一个相关的工作是DIMN[19],但是它在任务和方法上都与我们不同。
Meta Learning. 最近的元学习研究主要集中在:(1)学习一个好的权值初始化以快速适应新任务,如基础MAML[15]及其变体Reptile[20]、meta-transfer learning[21]、iMAML[22]等。(ii)使用设计良好的分类器学习嵌入空间,该分类器可以直接对新任务中的样本进行分类,无需快速适应[23,24,25]。(iii)在整个训练集上预训练一个好的特征提取器后,学习预测分类器参数[26,27]。这些工作集中于few-shot学习,通常设置是目标任务有很少的数据点(1/5/20 shots per class)。相比之下,泛化人脸识别应该处理数千个类别,这使其更具挑战性和普遍适用性。我们的方法与MAML[15]最为相关,它试图学习一个可转移的权值初始化。然而,MAML需要快速适应目标任务,而我们的MFR不需要任何模型更新,因为目标域是未知的。
3. Methology
本节描述提出的MFR方法是如何解决泛化人脸识别问题。MFR由三部分组成:(i)域级采样策略。(ii)用于优化多域分布以学习域不变且具有区分度的人脸表征的三个损失。(三)改进模型泛化能力的元优化流程如图3所示。概述如图2和算法1所示。
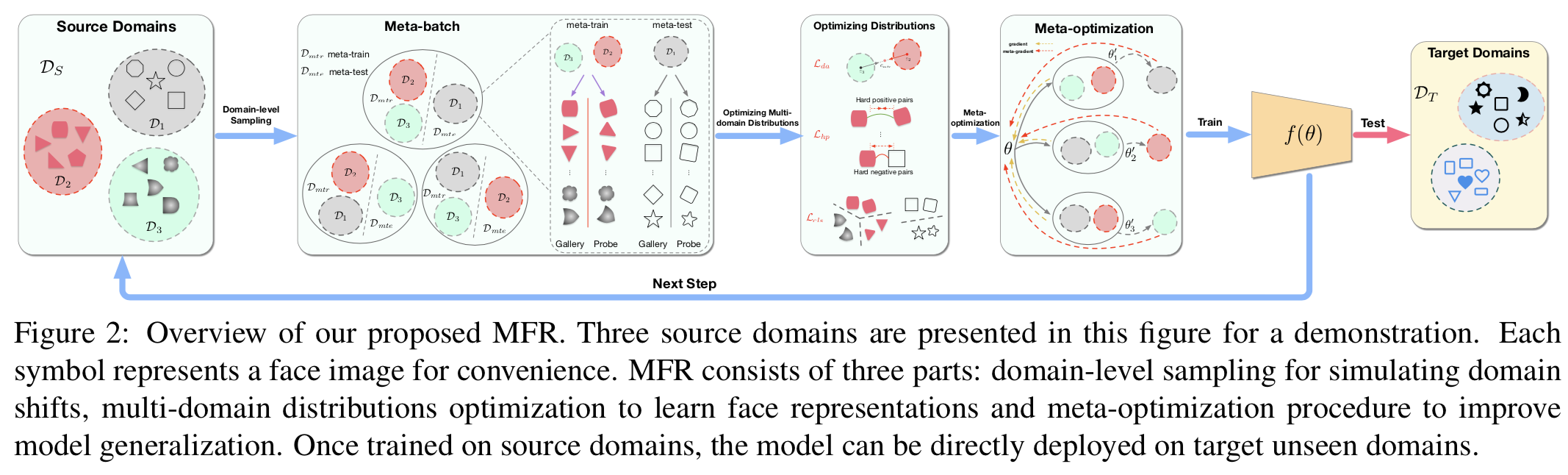
3.1. Overview
在训练阶段,我们访问了N个源域![]() ,每个域
,每个域![]() 都有自己的标签集。在测试阶段,训练好的模型在一个或几个未知目标域
都有自己的标签集。在测试阶段,训练好的模型在一个或几个未知目标域![]() 上评估,且不需任何模型更新。除此之外,目标域的标签集
上评估,且不需任何模型更新。除此之外,目标域的标签集![]() 和源域的标签集
和源域的标签集![]() 无关,使得该问题是open-set的。在训练中,我们定义了一个使用参数为
无关,使得该问题是open-set的。在训练中,我们定义了一个使用参数为![]() 的参数化函数
的参数化函数![]() 表示的单一模型。我们提出的MFR的目的是在源域
表示的单一模型。我们提出的MFR的目的是在源域![]() 上训练
上训练![]() ,这样它能够在目标未知域
,这样它能够在目标未知域![]() 上很好地实现泛化,如图1所示
上很好地实现泛化,如图1所示
3.2. Domain-level Sampling
为了实现域泛化,在每个训练迭代中,我们将源域分割成元训练(meta-train)和元测试(meta-test)域。具体说来,即我们将N个源域![]() 分割成N-1个meta-train域
分割成N-1个meta-train域![]() 和一个meta-test目标域
和一个meta-test目标域![]() ,用来模拟现实场景中存在的域转变问题。这样,模型就被鼓励学习可转移的知识,这些知识有关如何在有着不同分布的未知域上很好地进行泛化。我们进一步构建一个由多个batches组成的meta-batch,如下:(i)在N个源域上迭代;(ii)在第i个迭代中,
,用来模拟现实场景中存在的域转变问题。这样,模型就被鼓励学习可转移的知识,这些知识有关如何在有着不同分布的未知域上很好地进行泛化。我们进一步构建一个由多个batches组成的meta-batch,如下:(i)在N个源域上迭代;(ii)在第i个迭代中,![]() 被选中为meta-test域
被选中为meta-test域![]() ;(iii)剩下的作为meta-train域
;(iii)剩下的作为meta-train域![]() ;(iv)随机选择meta-train域中的B个身份和meta-test域中的B个身份,每个身份选取两个人脸图像,一张图作为gallery,另一张图作为probe。至此,一个N个batches的meta-batch就构建好了。然后,我们的模型通过每个meta-batch的累积梯度进行更新。具体方法见算法1。与MAML[15]不同的是,我们的采样是域级的,适用于open-set人脸识别。MLDG[14]也进行了类似的采样,但是它们的域在每次训练迭代中是随机划分的,并且没有建立meta-batch。
;(iv)随机选择meta-train域中的B个身份和meta-test域中的B个身份,每个身份选取两个人脸图像,一张图作为gallery,另一张图作为probe。至此,一个N个batches的meta-batch就构建好了。然后,我们的模型通过每个meta-batch的累积梯度进行更新。具体方法见算法1。与MAML[15]不同的是,我们的采样是域级的,适用于open-set人脸识别。MLDG[14]也进行了类似的采样,但是它们的域在每次训练迭代中是随机划分的,并且没有建立meta-batch。
3.3. Optimizing Multi-domain Distributions
为了聚合每个batch的反向传播梯度,我们优化了多域分布,使相同身份映射成相近的表征,不同的身份则映射为互相远离的表征。传统的度量损失,如contrastive[28,29]和triplet[3],采用随机抽样的对或triplets来构建训练batches。这些batches由许多简单对或triplets组成,导致训练收敛缓慢。为了解决这个问题,我们建议使用三个组件(即三个损失)去优化和学习域不变且有区分度的表征。hard-pair注意损失优化了hard对的局部分布,soft分类损失考虑了batch的全局分布,域对齐损失学习去对齐域中心。
Hard-pair Attention Loss. hard-pair注意损失专注于优化hard正对和负对。采样B个身份的batch,每个身份包含一个gallery人脸和一个probe人脸。我们表示输入为![]() ,抽取的gallery和probe嵌入为:
,抽取的gallery和probe嵌入为:![]() ,C表示维度长度。对
,C表示维度长度。对![]() 和
和![]() L2归一化后,我们可以通过计算
L2归一化后,我们可以通过计算![]() 来高效地构建一个相似度矩阵。然后我们使用正对阈值
来高效地构建一个相似度矩阵。然后我们使用正对阈值![]() 和负对阈值
和负对阈值![]() 去过滤hard正对和负对:
去过滤hard正对和负对:![]() 和
和![]() 。该操作复杂度只有
。该操作复杂度只有![]() ,且定义如下:
,且定义如下:

其中![]() 为由阈值
为由阈值![]() 过滤后的hard正对集,
过滤后的hard正对集,![]() 为由阈值
为由阈值![]() 过滤后的hard负对集
过滤后的hard负对集
Soft-classification Loss. hard-pair注意力损失只集中在hard对上,并趋向于收敛到局部最优。为了解决这个问题,我们引入了一个特定的soft分类损失来进行batch内的分类。损失公式为:
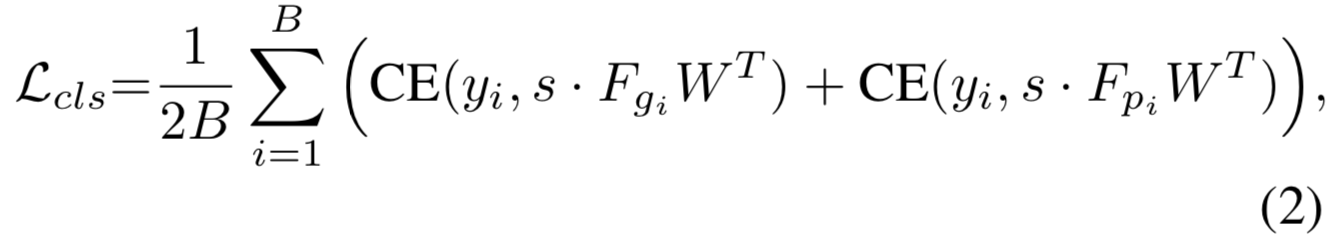
其中yi=i表示第i个身份,![]() 或
或![]() 是第i个身份的对数,s是一个常量尺寸因子。
是第i个身份的对数,s是一个常量尺寸因子。![]() 初始化为
初始化为![]() ,且每一行进行L2归一化
,且每一行进行L2归一化
Domain Alignment Loss. 我们发现在meta-train域之间的负对比在域内的负对更容易(即更容易区分他们是负对)。通过加入域对齐正则化使嵌入具有域不变性,可以减小不同meta-train域的域间隙。这样,跨meta-train域的负对变得更难区分,这样有利于学习更具区分度的表征。为了实现域对齐,我们让多个meta-train域的平均嵌入接近彼此。具体来说,我们首先计算meta-train域的所有平均嵌入的嵌入中心,然后优化所有平均嵌入与该嵌入中心的差异。由于meta-test只有一个域,所以域对齐损失只适用于meta-train域。损失公式为:
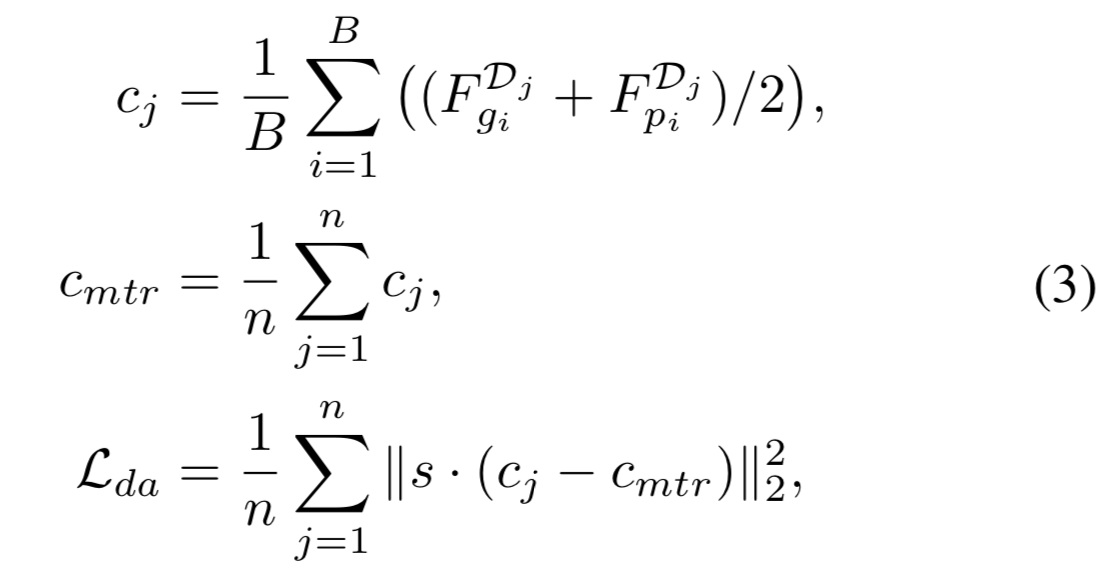
其中,![]() 是归一化后的嵌入,
是归一化后的嵌入,![]() 是从域
是从域![]() 中采样的batch的平均嵌入,
中采样的batch的平均嵌入,![]() 是meta-train域中所有平均嵌入的嵌入中心,n是meta-train域的个数,s是尺寸因子。在meta-optimization中,我们将会使用来自这三个损失的后向传播信号去优化模型泛化能力。
是meta-train域中所有平均嵌入的嵌入中心,n是meta-train域的个数,s是尺寸因子。在meta-optimization中,我们将会使用来自这三个损失的后向传播信号去优化模型泛化能力。

(所以一个meta-batch迭代n次,因为有n个域,因此一个meta-batch中有n个batches。这里的meta-batch和batch是这个意思。然后对一个meta-batch中n个batches的梯度进行累积,一个meta-batch进行一个参数更新)
3.4. Meta-optimization
本节介绍如何优化模型以提高模型泛化能力。整个元优化过程总结在算法1中,如图3所示。

Meta-train. 基于域级采样,在一个meta-batch的每个batch中,我们采样N-1个源域![]() ,然后从
,然后从![]() 中采样B个图像对
中采样B个图像对![]() 。然后在每个batch中计算损失,如下所示:
。然后在每个batch中计算损失,如下所示:
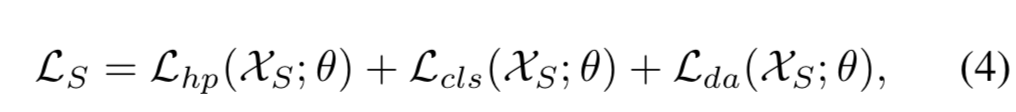
其中![]() 表示模型参数。模型接下来使用梯度
表示模型参数。模型接下来使用梯度![]() 进行更新:
进行更新:![]() 。该更新步骤和传统的度量学习是相似的。
。该更新步骤和传统的度量学习是相似的。
Meta-test. 在每个batch中,模型还在meta-test域![]() 上进行测试。该测试过程模拟了在有着不同分布的未知域上进行评估,来让模型学习跨域泛化。我们还从meta-test域
上进行测试。该测试过程模拟了在有着不同分布的未知域上进行评估,来让模型学习跨域泛化。我们还从meta-test域![]() 上采样了B个图像对
上采样了B个图像对![]() 。然后在更新后的参数
。然后在更新后的参数![]() 上计算损失,如下:
上计算损失,如下:
![]()
Summary. 为了同时优化meta-train和meta-test,最终的MFR目标函数为:
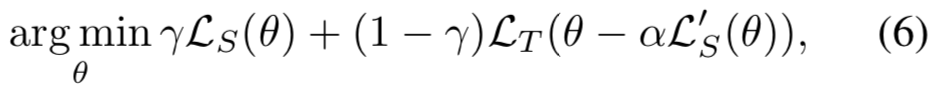
其中是α是meta-train的步长大小,γ用于平衡meta-train和meta-test。该目标函数的意义为:优化模型参数,这样在meta-train域中更新后,模型在meta-test域中也能表现得很好。从另一个角度来看,等式(6)的第二项作为额外的正则化去更新具有高阶梯度的模型,我们称其为meta-gradients。比如,给定三个源域![]() ,一个meta-batch有三种meta-train/meta-test分法:
,一个meta-batch有三种meta-train/meta-test分法:![]() 和
和![]() 。对于每种划分或batch,一个梯度和meta-gradient分别在meta-train和meta-test中后向传播。通过累积meta-batch中的所有梯度和meta-gradients,模型最终优化为能够在meta-train和meta-test上实现良好的模型。图3说明了梯度和meta-gradients在计算图上是怎么流动的。
。对于每种划分或batch,一个梯度和meta-gradient分别在meta-train和meta-test中后向传播。通过累积meta-batch中的所有梯度和meta-gradients,模型最终优化为能够在meta-train和meta-test上实现良好的模型。图3说明了梯度和meta-gradients在计算图上是怎么流动的。
4. Experiments
为了评估我们提出的用于泛化人脸识别问题的MFR方法,我们在两个我们提出的基准上进行了几个实验。
4.1. GFR Benchmark and Protocols
泛化人脸识别一直没有引起人们的重视,我们也没有一个通用的评估协议,因此我们引入了两个设计良好的基准来评估模型的泛化能力。其中一个基准是跨种族评估(crossing race evaluation),命名为GFR-R,另一个基准是跨人脸多样性( crossing facial variety),命名为GFR-V。我们在这里使用多样性来强调在GFR-V的源域和目标未知域之间有很大的差距。
在现实世界的场景中,像MS-Celeb[13]这样的大型基础数据集通常用于预训练,但是模型在具有不同分布的新领域上可能泛化较差。为了模拟它,我们使用MS-Celeb作为基础数据集。RFW[35]最初被提出来研究人脸识别中的种族偏见,它标记了MS-Celeb的四个人种数据集(高加索人、亚洲人、非洲人、印度人)。我们选择这四个数据集作为我们的四个种族域。注意,由于RFW[35]与MS-Celeb[13]重叠,我们根据身份关键字将所有重叠的身份从MS-Celeb中删除,从而构建了名为MS-Celeb-NR的基础数据集,即不包含RFW的MS-Celeb。MS-Celeb-NR可以看作是4个种族的独立基数据集。
GFR-R. 每个种族都有大约2K到3K的身份。我们随机选择1K个身份进行测试,剩余的1K个~ 2K个身份进行训练。数据集详细信息如表1所示。在我们的实验设置中,每个种族被视为一个域。我们在四个域中随机选取三个域作为源域,其余的一个域作为测试域,测试域在训练中是不可访问的。因此,我们为GFR-R构建了四个子协议,如表2所示。
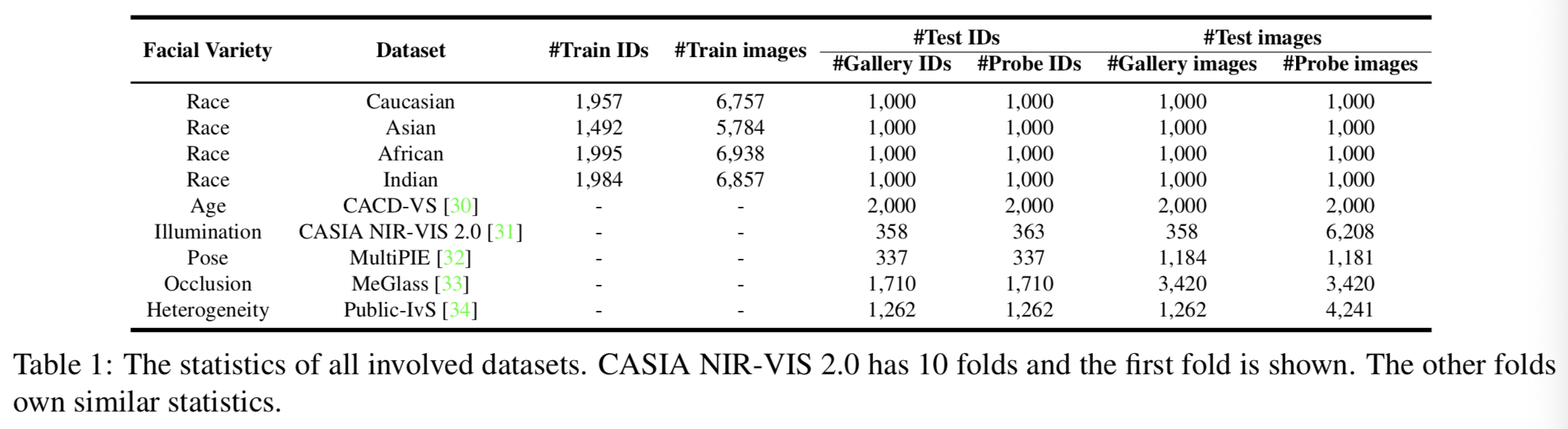

GFR-V. GFR-V基准用于跨人脸多样性评估,设置较困难,能更好地反映模型的泛化能力。如表2所示,将4个种族数据集(高加索、亚洲、非洲、印度)作为源域,第5个数据集作为目标域。具体来说,目标数据集包括CACD-VS[30]、CASIA NIR-VIS 2.0[31]、MultiPIE[32]、MeGlass[33]、Public-IvS[34]。对于CASIA NIR-VIS 2.0,我们遵循view2评估[31]中的标准方案,并报告10折的平均值。对于MeGlass和Public-IvS,我们遵循标准的检测方案[34,33]。对于CACD-VS,除了标准的[30]协议外,我们使用提供的2000个跨年龄图像正对,并将它们分成gallery和probe,以进行ROC/Rank-1评价。对于Multi-PIE,我们选择337个身份,每个身份包含大约3~ 4个正面gallery图和3~ 4个45◦视图的probe图。
Benchmark Protocols. 对于每幅图像,提取原始图像和翻转图像的特征,然后串联作为最终表征。分数是通过两个表征的余弦距离来测量的。对于性能评估,我们使用 receiver operating characteristic (ROC) curve和Rank-1 accuracy。对于ROC,我们报告在低误接受率(FAR)如1%,0.1%和0.01%下的验证率(VR)。在Rank-1评价中,将每个probe图像与所有gallery图像进行匹配,如果top-1的结果是相同的,则为正确。
4.2. Implementation Details
我们的实验是基于PyTorch[37]的。在对比实验中将随机种子设置为固定值2019,以便进行公平比较。我们使用一个28层的ResNet作为我们的backbone,但是通道数乘数(channel-number multiplier)为0.5。我们的backbone只有1.287亿次FLOPs和464万参数,这是相对轻量的。输出嵌入的维数是256。在MS-Celeb-NR上使用CosFace[38]对模型进行预训练。在训练期间,所有的脸都被裁剪和调整到120×120。然后通过减去127.5并除以128对输入进行标准化。分别将meta-train步长α、meta optimization步长β、和用来平衡meta-train和meta-test 损失权重γ初始化为0.0004、0.0004和0.5。batch size B设为128,soft-classification 损失和domain alignment 损失的尺寸因子s设为64。步长α和β每1K步衰减一次,衰减率为0.5。正阈值![]() 和负阈值
和负阈值![]() 的分别初始化为0.3、0.04,并更新为
的分别初始化为0.3、0.04,并更新为![]() = 0.3 + 0.1n和
= 0.3 + 0.1n和![]() = 0.04/0.5n,其中n为衰减数。对于meta-optimization,我们使用SGD来优化网络,权重衰减为0.0005,动量为0.9。
= 0.04/0.5n,其中n为衰减数。对于meta-optimization,我们使用SGD来优化网络,权重衰减为0.0005,动量为0.9。
4.3. GFR-R Comparisons
Settings. 我们将我们的模型与几个基线进行比较,包括基本模型和几个域聚合基线。为了进一步将我们的方法与其他域泛化方法进行比较,我们将MLDG[14]引入open-set设置,使其能够应用于我们的协议中。结果如表3所示。对于GFR-R中的四种协议,我们报告了在1%、0.1%、0.01%的低FAR 下的VRs和Rank-1准确度。具体来说,我们的比较包括:(i) Base:仅使用CosFace[38]在MS-Celeb-NR上预训练的模型。注意MS-Celeb-NR与四个种族数据集(高加索、亚洲、非洲和印度)没有重叠的身份,可以认为是一个独立的数据集。(ii) Base-Agg:用CosFace[38]在MS-Celeb-NR和聚合的源域上(即上面MS-Celeb-NR去掉的那部分数据)训练模型。以GFR-R-I为例,Base-Agg在MS-Celeb-NR和高加索、亚洲、非洲三个源域上共同训练。这是为了与我们的MFR进行公平比较,其中涉及到相同的训练数据集。 (iii)Base-FT rnd:Base模型在聚合的源域上进行了进一步的微调。最后一个全连接层的分类模板被随机初始化。(iv) Base-FT imp: Base模型在聚合的源域上进一步微调,但分类模板初始化为对应身份的嵌入均值。其使用weight-imprinted[36]进一步精炼而成。(v) MLDG:适用于泛化人脸识别问题的MLDG[14]。
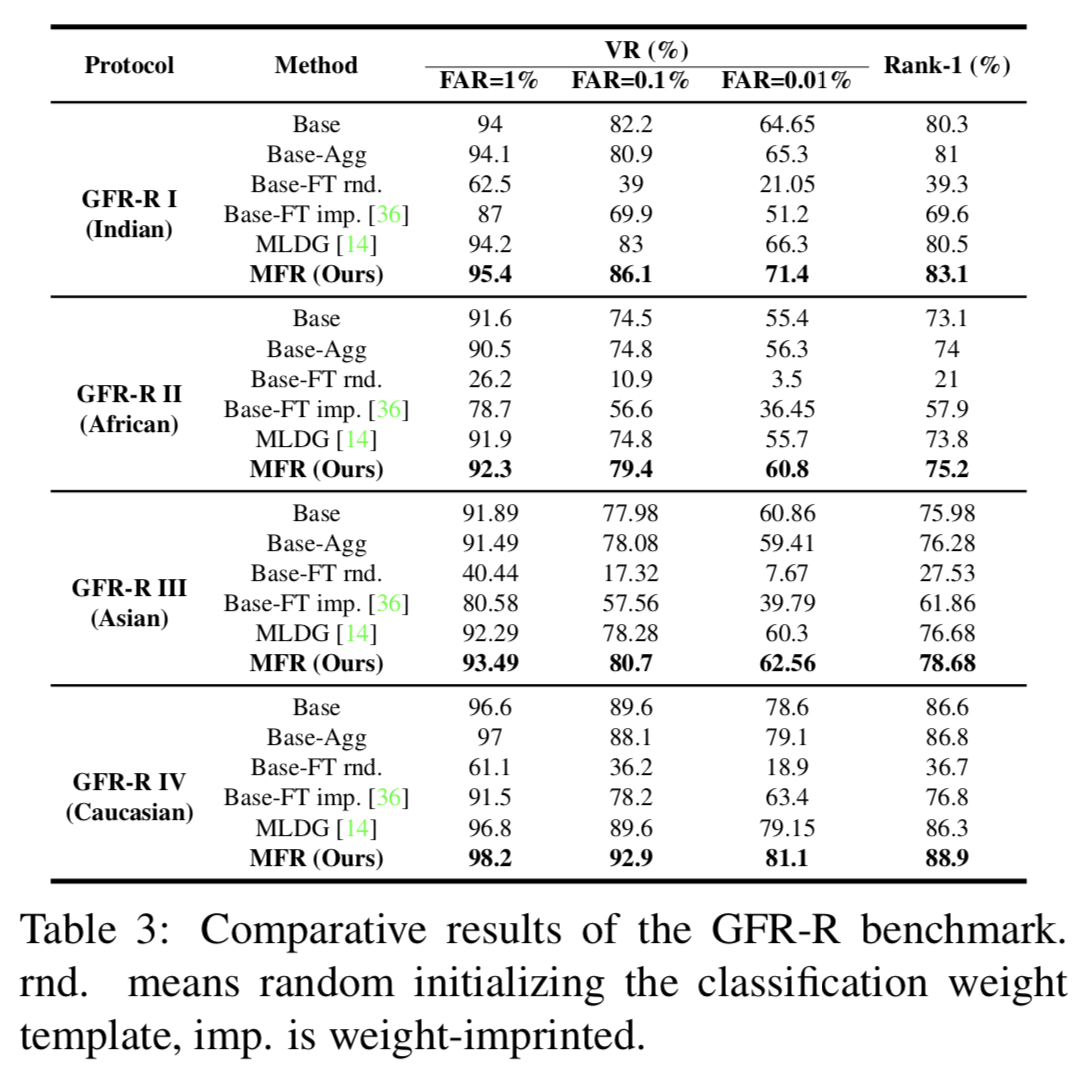
Results. 从表3的结果可以看出:(i)总的来说,在所有比较的设置和方法中,我们的方法在四种GFR-R协议上取得了最好的结果。(2)在MS-Celeb-NR上训练的Base模型较强,但对目标域的泛化效果不佳,尤其是印度、非洲、亚洲。原因可能是MS-Celeb-NR大多数是高加索人。(iii) MS-Celeb-NR和源域联合训练的效果略好于Base模型,但仍不能与我们的MFR方法相比较。(iv) Base-FT rnd的性能急剧下降,我们将其归因于源域上的过度拟合。weight-imprinted(Base-FT imp)可以在一定程度上减少这种过拟合,但其性能仍低于Base模型。(v) MLDG[14]最初是为closed-set和类别级识别问题设计的,在open-set泛化人脸识别问题上无法与我们的方法竞争。
4.4. GFR-V Comparisons
GFR-V基准用于跨人脸多样性评价,能更好地反映模型泛化能力。
Settings. 我们将我们的模型与两个强基线Base, Base-Agg,an adapted MLDG[14]和其他竞争对手(如果存在的话)相比较。由于5个目标域的标准协议不同,我们分别在表4、5、6、7、8中显示它们的结果。
CACD-VS. CACD-VS[30]用于跨年龄评估,每对图像包含一张年轻的脸和一张年老的脸。我们报告ROC/Rank-1以及提供的标准方案的结果。其他竞争对手只根据标准协议进行评估。表4中的结果表明,我们的MFR不仅击败了基线,而且击败了使用跨年龄数据集进行训练的竞争对手。

CASIA NIR-VIS 2.0. CASIA NIR-VIS 2.0[31]中gallery图像是在可见光下采集的,而probe图像是在近红外光下采集的,因此模态差距很大。表5显示:(i)当FAR=0.1%(0.01%)时,我们的性能从89.89%(69.27%)的Base提高到95.97%(81.92%)。(ii)即使存在如此巨大的模态差异,我们的性能仍可与几种基于CNN的方法相比较[43,44],这些方法使用MS-Celeb进行预训练,使用目标域NIR-VIS数据集进行微调。相比之下,我们的模型在训练过程中没有看到任何近红外样本。

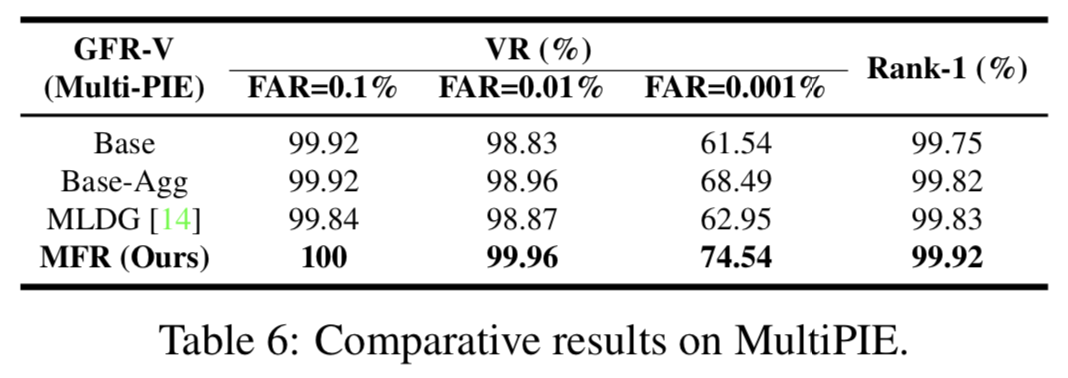
Multi-PIE. 使用Multi-PIE,在跨姿态评估中将我们的模型与两个基线和MLDG进行比较。表6验证了我们的MFR相对于基线和MLDG的改进。
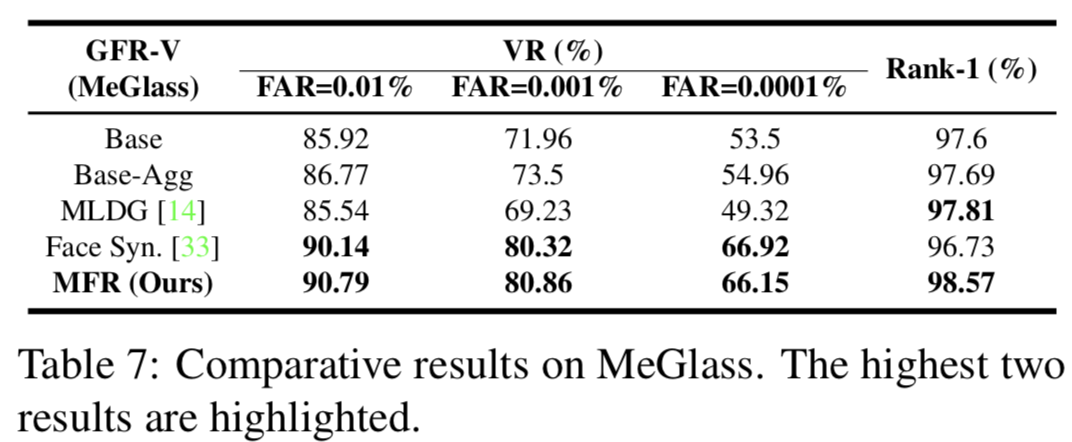
MeGlass. MeGlass[33]着重研究了眼镜遮挡对人脸识别的影响。我们选择最困难的IV协议进行评估。如表7所示,我们的方法在0.001%的low FAR时,从Base模型的71.96%(53.5%)提高到80.86%(66.15%),甚至略好于[33],该方法合成了整个MS-Celeb佩戴眼镜后的图像进行训练。
Public-IvS. Public-IvS[34]是一个用于ID vs. Spot (IvS)验证的测试平台。与Base和Base-Agg相比,我们的方法大大提高了泛化性能。另外两名选手都是在MS-Celeb上接受过预训练,并在CASIA-IvS上微调过。CASIA-IvS拥有200多万个身份,每个身份都有一个ID和Spot face。即使如此,我们的方法仍然比Contrastive[29]稍微好一些。

LFW. 我们对LFW[9]进行了广泛的评估,如表9所示。实验结果表明,在相似的目标域上,我们方法的泛化效果优于基准算法。
以上结果表明,我们的方法比基准方法有了很大的改进,性能优于最好的监督/非泛化方法。对于真实世界的人脸识别应用,我们的方法是第一选择,因为它在所有目标领域上都能很好地泛化,有着具有竞争力的性能。
4.5. Ablation Study and Analysis
Contribution of Different Components. 为了评估不同组件的贡献,我们将我们的完整MFR与四个降级版本进行比较。前三个组件是hard-pair attention损失, soft-classification损失和domain alignment损失,用于学习域不变且具有区分度的表征。第四个组件是meta-gradient。如果在等式(6)中α被设为0,则目标函数被降级为meta-train和meta-test的总和,没有了meta-gradient计算。表10显示了每个组件对性能的贡献。在三者中,meta-gradient是最重要的。例如,在没有meta-gradient的情况下,当FAR=0.01%时,GFR-R I的性能从71.4%下降到68.35%。

First Order Approximation. meta-gradient需要高阶导数,计算成本很高。因此,我们将其与一阶近似进行比较。为了得到一阶近似,我们仅将算法(1)中梯度聚合步骤中的![]() 更改为
更改为![]() 。从表10可以看出,一阶近似的性能接近于高阶。考虑到一阶近似只需要高阶82%的GPU内存和63%的时间(在我们的设置中),因此一阶近似可作为实现中高阶的替代品。
。从表10可以看出,一阶近似的性能接近于高阶。考虑到一阶近似只需要高阶82%的GPU内存和63%的时间(在我们的设置中),因此一阶近似可作为实现中高阶的替代品。
Impact of γ. 在等式(6)中,γ是一个加权meta-train和meta-test损失的超参数。消融结果如图4所示。值0.5给出了最好的结果,这表明meta-train域和meta-test域应该被同等地学习。
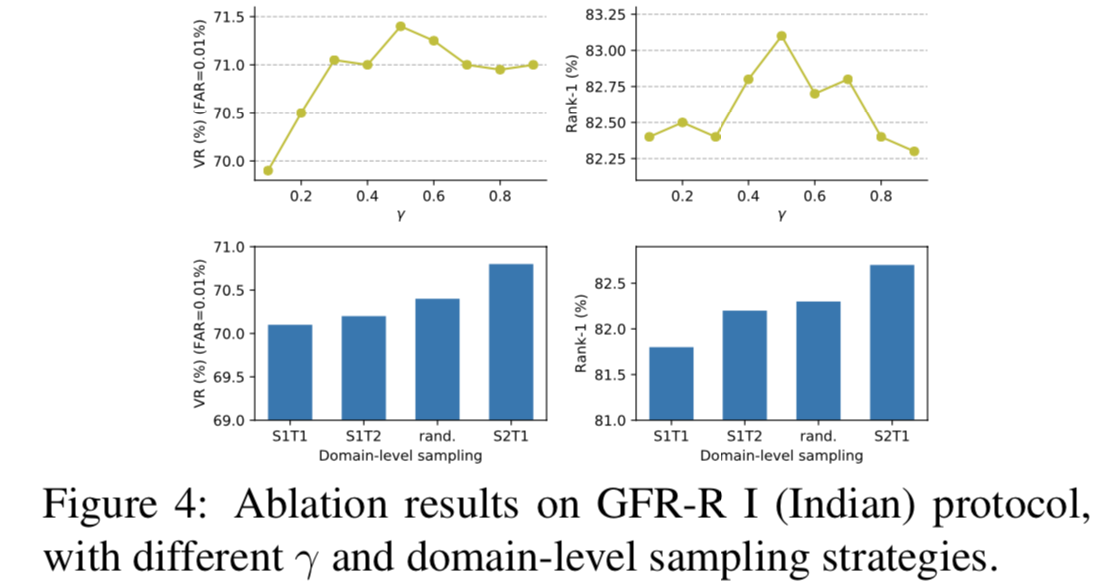
Domains-level Sampling. 由于在meta-train中只有一个域时不能应用域对齐损失,为了进行公平比较,我们去掉了域对齐损失。对于每个batch,SmTn (m,n∈{(1,1),(1,2),(2,1)})表示采样m个域作为meta-train,其他n个域作为meta-test。rand.表示随机选取m个域作为meta-train(m为随机数),剩下的1个域作为meta-test。从图4可以看出,设置m = 2和n = 1效果最好。
5. Conclusion
在本文中,我们强调了泛化人脸识别问题,并提出了一种Meta Face Recognition(MFR)方法来解决这一问题。一旦在一组源域上进行了训练,模型就可以直接部署到目标域上,而不需要任何模型更新。在两个新定义的泛化人脸识别基准上进行了大量的实验,验证了我们提出的泛化人脸识别基准的有效性。我们认为泛化人脸识别问题在实际应用中具有重要意义,我们的工作是未来工作的重要途径。

