
细粒度 - Learning to Navigate for Fine-grained Classification - 1 - 论文学习
代码 https://github.com/yangze0930/NTS-Net
Learning to Navigate for Fine-grained Classification
Abstract
细粒度分类由于难以找到有区分度的特征而具有很大的挑战性。要找到这些微妙的特征来完全描述物体并不是一件简单的事。针对这种情况,我们提出了一种新的自我监督机制,在不需要限定bounding box/part标注的情况下,有效地定位信息区域。我们的模型被称为NTS-Net的Navigator-Teacher-Scrutinizer 网络,由Navigator agent、Teacher agent和Scrutinizer agent组成。考虑到区域的信息量与为ground truth类的概率之间的内在一致性,我们设计了一种新的训练范式,使Navigator能够在Teacher的指导下检测出信息量最大的区域。然后,仔细检查Navigator推荐的区域并做出预测。我们的模型可以看作是一个多agent的合作,agent之间相互受益,共同进步。NTS-Net可以端到端的训练,同时在推理过程中提供精确的细粒度分类预测以及高信息量的区域。我们在广泛的基准数据集上实现了最先进的性能。
1 Introduction
细粒度分类的目的是区分一个普通类的从属类,例如区分野鸟种类、汽车型号等。这些从属类通常由领域专家用复杂的规则定义,这些规则通常关注特定区域的细微差异。虽然深度学习推动了许多计算机视觉任务的研究[24,38,33],但其在细粒度分类中的应用或多或少不尽人意,这在很大程度上是由于难以找到信息区域并从中提取有区分度的特征。对于像鸟一样摆出各种姿势的从属类来说,情况更糟。
因此,细粒度分类的关键在于开发自动方法来准确地识别图像中的信息区域。之前的一些研究[45,8,3,46,13,2,29]利用了细粒度的人工标注,如鸟类分类中的鸟类parts标注。虽然获得了不错的结果,但它们所需的细粒度人工注释代价高昂,使得这些方法在实践中不太适用。其他方法[49,47,48,43]采用无监督学习方案来定位信息区域。它们消除了对昂贵注释的需要,但缺乏一种机制来保证模型关注正确的区域,这通常会导致准确性下降。
在本文中,我们提出了一种新的自监督机制来有效地定位信息区域,而不需要细粒度的bounding-box/part标注。我们所开发的模型,即我们称之为NTS-Net的Navigator-Teacher-Scrutinizer网络,采用多agent合作学习方案来解决准确识别图像中的信息区域的问题。从直观上看,被分配为ground-truth类的概率较高的区域应该包含更多的对象特征语义,从而提高整个图像的分类性能。因此,我们设计了一种新的损失函数来优化所选区域的信息量,使其具有与ground truth类的概率相同的次序,并以全图像的ground turth类作为区域的ground turth类。
具体来说,我们的NTS-Net由一个Navigator agent、一个Teacher agent和一个Scrutinizer agent组成。Navigator导航模型以关注信息最丰富的区域:对于图像中的每个区域,Navigator预测该区域的信息含量,并使用预测结果推荐信息最丰富的区域。Teacher对Navigator提出的区域进行评价并提供反馈:对于每个提出的区域,Teacher对其属于ground-truth类的概率进行评价;置信度评估引导Navigator使用我们的顺序一致(ordering-consistent)损失函数提出更多的信息区域。Scrutinizer从Navigator中审查建议的区域,并进行细粒度的分类:每个建议的区域被扩大到相同的大小,Scrutinizer从中提取特征;将区域特征和整体图像特征进行联合处理,进行细粒度分类。从整体上看,我们的方法可以看作是强化学习中的actor-critic[21]方案,Navigator是actor,Teacher是critic。当Teacher提供更精确的指导时,Navigator将定位更具信息的区域,这反过来也将使Teacher受益。结果,各agent共同进步,最终得到一个模型,该模型提供精确的细粒度分类预测以及信息丰富的区域。图1显示了我们方法的概述。
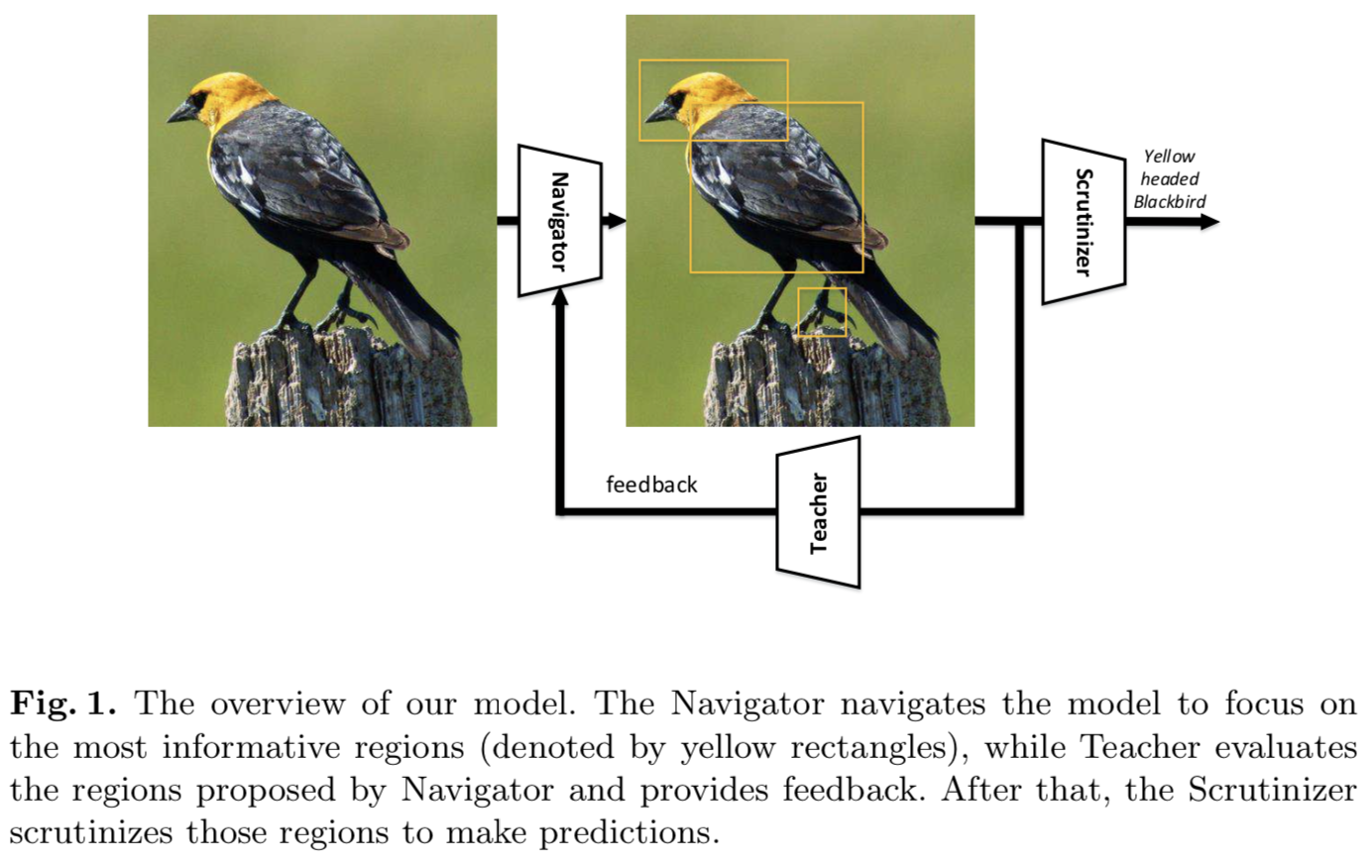
我们的主要贡献总结如下:
-我们提出了一种新的多agent合作学习方案,以解决在细粒度分类任务中不需要bounding-box/part标注的情况下准确识别信息区域的问题。
-我们设计了一种新的损失函数,通过使区域的信息量和其被判定为ground-truth类的概率具有一致性,Teacher可以引导Navigator定位图像中信息量最高的区域。
-我们的模型可以端到端的训练,同时提供精确的细粒度分类预测,以及在推理过程中提供高信息区域。我们在广泛的基准数据集上实现了最先进的性能。
本文的其余部分组织如下:我们将在第2节回顾相关的工作。在第3节中,我们将阐述我们的方法。实验结果在第4节给出并分析,最后在第5节总结。
2 Related Work
2.1 Fine-grained classification
有各种各样的方法被设计来区分细粒度的类别。由于一些细粒度分类数据集提供了bounding-box/part注释,早期的作品[45,8,2]在训练和推理阶段都利用了这些注释。然而,在实际部署模型时,将没有可用的人工注释。后来,一些作品[3,46]只在训练阶段使用bounding-box/part注释。在这种设置下,框架非常类似于检测:选择区域,然后对pose-normalized 的对象进行分类。Jonathan等人[22]使用共分割和对齐的方法生成没有part标注的part,但训练时使用了bounding-box标注。最近,出现了一种更普遍的设置,它在训练或推理时都不需要bounding-box/part注释。这个设置使细粒度分类在实践中更有用。本文主要考虑最后一种设置,即在训练或推理阶段不需要bounding-box/part标注。
为了在没有细粒度注释的情况下学习,Jaderberg等人提出了Spatial Transformer Network来显式地操作网络内的数据表征,并预测信息区域的位置。Lin等[28]使用双线性模型构建整幅图像有区分度的特征;模型能够捕获不同从属类之间的细微差别。Zhang等人[47]提出了一种两步法来学习一组part检测器和part显著性映射。Fu等[12]使用替代优化方案训练注意力proposal网络和基于区域的分类器;它们表明两项任务是相关的,并且可以相互受益。Zhao等人[48]提出了Diversified Visual Attention Network (DVAN),明确追求注意力的多样性,更好地收集具有区分度的信息。Lam等人[25]提出了一种Heuristic-Successor Network (HSNet)来将细粒度分类问题制定为图像中信息区域的顺序搜索问题。
2.2 Object detection
早期目标检测方法采用SIFT[34]或HOG[10]特征。最近的工作主要集中在卷积神经网络。R-CNN[14]、OverFeat[40]、SPPnet[16]等方法采用传统的图像处理方法生成对象proposals,并进行类别分类和bounding box回归。稍后的工作,如Faster R-CNN[38]提出 Region Proposal Network (RPN),以生成proposal。YOLO[37]和SSD[31]通过采用single-shot架构,在Faster R-CNN[38]上提高了检测速度。另一方面,Feature Pyramid Networks (FPN)[27]专注于更好地解决多尺度问题,并从多个特征maps生成anchors。我们的方法需要选择信息区域,这也可以看作是目标检测。据我们所知,我们是第一个将FPN引入细粒度分类的人,同时消除了人工注释的需要。
2.3 Learning to rank
在机器学习和信息检索领域[30]中,排名学习正在引起人们的关注。训练数据由带有指定顺序的item列表组成,而目标是学习item列表的顺序。设计了排序损失函数来惩罚排序错误的配对。![]() 表示用于排序的对象,
表示用于排序的对象,![]() 表示对象的索引,其中
表示对象的索引,其中![]() 表示
表示![]() 应该排在
应该排在![]() 的前面。
的前面。![]() 表示排序函数的假设集。其目标是找到能够最小化定义在
表示排序函数的假设集。其目标是找到能够最小化定义在![]() 的某损失函数的排序函数
的某损失函数的排序函数![]() 。有很多的排序方法。通常,这些方法被分成三类:the point-wise approach [9], pair-wise approach [18,4] 和list-wise approach[6,44]。
。有很多的排序方法。通常,这些方法被分成三类:the point-wise approach [9], pair-wise approach [18,4] 和list-wise approach[6,44]。
point-wise方法为每个数据赋予一个数值分数,learning-to-rank问题被看作回归问题,使用L2损失函数,如下:
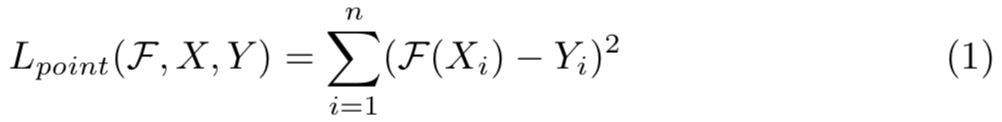
pair-wise排序方法中,learning-to-rank问题被看作分类问题,即学习一个二分类器去选择概率最高的对。假设![]() 的值为0或1,
的值为0或1,![]() =0意味着
=0意味着![]() 排在
排在![]() 前面。然后损失被定义在所有的对上,如等式2所示,其目标是找到最优
前面。然后损失被定义在所有的对上,如等式2所示,其目标是找到最优![]() 去最小化错序对的平均数量:
去最小化错序对的平均数量:

list-wise方法直接优化整个列表,可见其看作排列的分类问题。![]() 为排序函数,损失定义为:
为排序函数,损失定义为:

在我们的方法中,我们的navigator损失函数采用了multi-rating pair-wise排序损失,使区域的信息量和被判定为ground truth类的概率之间具有一致性。
3 Methods
3.1 Approach Overview
我们的方法是基于信息区域有助于更好地描述目标的假设,因此将信息区域的特征与完整图像融合将获得更好的性能。因此,目标是定位对象中信息最丰富的区域。我们假设所有区域都是矩形的,我们将![]() 表示为给定图像中所有区域的集合。我们定义信息函数
表示为给定图像中所有区域的集合。我们定义信息函数![]() 以评估区域
以评估区域![]() 有多少的信息,且定义置信度函数
有多少的信息,且定义置信度函数![]() 为分类器去评估区域属于ground turth类的置信度。如第一节所说的,有着更多信息的区域应该有着更高的置信度,因此下面的条件应被满足:
为分类器去评估区域属于ground turth类的置信度。如第一节所说的,有着更多信息的区域应该有着更高的置信度,因此下面的条件应被满足:
![]()
我们使用Navigator网络去近似信息函数![]() ,Teacher网络去近似置信度函数
,Teacher网络去近似置信度函数![]() 。为了简化,在区域空间
。为了简化,在区域空间![]() 选择M个区域
选择M个区域![]() ,对于每个区域
,对于每个区域![]() ,Navigator网络评估其信息量
,Navigator网络评估其信息量![]() ,Teacher网络评估其置信度
,Teacher网络评估其置信度![]() 。为了满足条件1(condition 1),我们优化Navigator网络去使
。为了满足条件1(condition 1),我们优化Navigator网络去使![]() 有相同的顺序。
有相同的顺序。
随着Navigator网络按照Teacher网络的要求进行改进,它将产生更具信息的区域,帮助Scrutinizer网络做出更好的细粒度分类结果。
在3.2节中,我们将描述Navigator如何在Teacher的监督下提出信息区域。在第3.3节中,我们将介绍如何从Scrutinizer获得细粒度的分类结果。3.4节和3.5节将分别详细介绍网络架构和优化。
3.2 Navigator and Teacher
导航到可能的信息区域可以看作是一个区域推荐问题,该问题在[41,11,1,7,20]中得到了广泛的研究。其中大多数都基于滑动窗口搜索机制。Ren等人[38]引入了一种新的区域推荐网络(region proposal network ,RPN),该网络与分类器共享卷积层,并降低了计算proposals的边际成本。他们使用anchors来同时预测多个区域proposals。每个anchor都与滑动窗口的位置、长宽比和方框比例相关联。受anchors想法的启发,我们的Navigator网络将图像作为输入,生成一系列的长方形区域![]() ,每个区域都有一个表示区域信息量的分数(图2表示了我们anchors的设计)。对于大小为448的输入图像X,我们选择尺度为{48,96,192}、比率为{1:1, 3:2, 2:3}的anchors,然后Navigator网络将生成表示所有anchors信息量的列表。我们如等式4一样排序信息列表,其中A表示anchors的数量,
,每个区域都有一个表示区域信息量的分数(图2表示了我们anchors的设计)。对于大小为448的输入图像X,我们选择尺度为{48,96,192}、比率为{1:1, 3:2, 2:3}的anchors,然后Navigator网络将生成表示所有anchors信息量的列表。我们如等式4一样排序信息列表,其中A表示anchors的数量,![]() 表示顺序信息列表中的第i个元素:
表示顺序信息列表中的第i个元素:
![]()

为了减少区域的冗余量,我们在区域中,基于其信息量,采用non-maximum suppression (NMS)方法。然后我们使用top-M的信息区域![]() ,并将他们输入Teacher网络去得到置信度
,并将他们输入Teacher网络去得到置信度![]() 。图3展示了M=3的概述,其中M是一个表示有多少区域被用来训练Navigator网络的超参数。我们优化Navigator网络去使
。图3展示了M=3的概述,其中M是一个表示有多少区域被用来训练Navigator网络的超参数。我们优化Navigator网络去使![]() 有相同的顺序。每个推荐的区域通过最小化ground truth类和预测置信度之间的交叉熵损失去有优化Teacher。
有相同的顺序。每个推荐的区域通过最小化ground truth类和预测置信度之间的交叉熵损失去有优化Teacher。
3.3 Scrutinizer

随着Navigator网络的逐步收敛,将产生具有对象特征的信息区域,帮助Scrutinizer网络进行决策。我们使用top-k个信息区域结合完整图像作为输入来训练Scrutinizer网络。换句话说,这些K个区域用于促进细粒度识别。图4展示了K = 3时的过程。Lam等人的[25]表明,使用信息区域可以减少类内方差,并有可能在正确的标签上产生更高的置信度分数。我们的对比实验表明,添加信息区域显著提高了大量数据集的细粒度分类结果,包括CUB-200-2001、FGVC Aircraft和Stanford Cars,如表2、3所示。
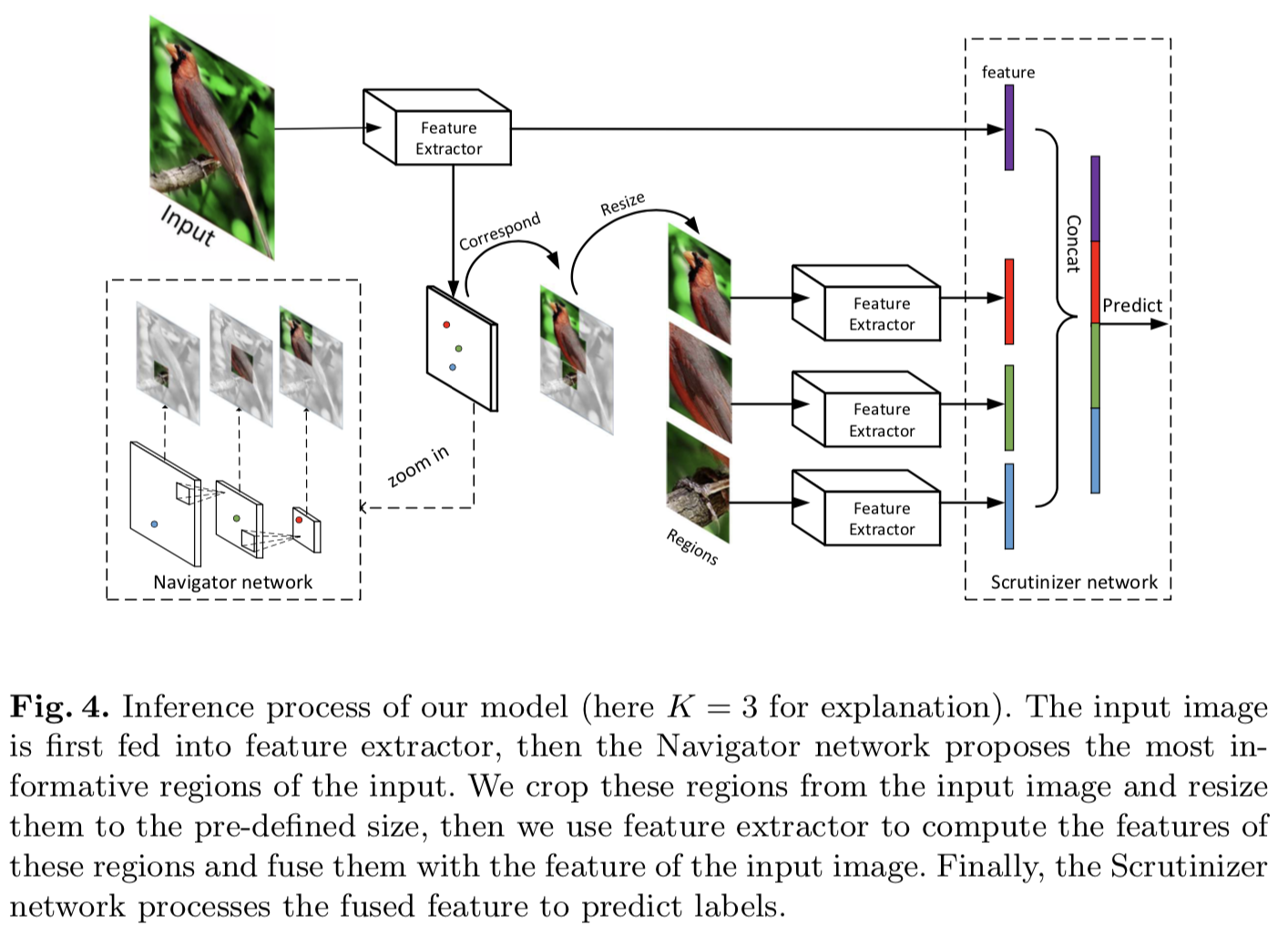
3.4 Network architecture
为了获得区域proposals与特征图中特征向量的对应关系,我们使用不使用全连接层的全卷积网络作为特征提取器。其中,我们选择在ILSVRC2012[39]上预训练好的ResNet-50[17]作为CNN特征提取器,Navigator、Scrutinizer、Teacher network都共享特征提取器中的参数。我们表示特征提取器中的参数为W。对于输入图像X,提取的深度表征被表示为X⊗W,⊗表示卷积、池化和激活操作的组合。
Navigator network. 受Feature Pyramid Networks (FPN) [27]设计的启发,我们使用了一个具有横向连接的自顶向下结构来检测多尺度区域。我们使用卷积层逐层计算特征层次,后面跟着ReLU激活和max-pooling。然后我们得到一系列不同空间分辨率的特征图。较大的特征maps中的anchors对应较小的区域。图4中的Navigator网络显示了我们的设计草图。利用不同层次的多尺度特征图,可以生成不同尺度和比例的区域信息。在我们的设置中,我们使用尺度为{48×48,96×96,192×192}的区域对应尺度为{14×14,7×7,4×4}的特征图。我们将Navigator网络中的参数表示为![]() (包括特征提取器中的共享参数)。
(包括特征提取器中的共享参数)。
Teacher network. Teacher网络(图3)近似于映射![]() ,表示每个区域的置信度。接收M个来自Navigator网络的尺度归一化后(224×224)的信息区域
,表示每个区域的置信度。接收M个来自Navigator网络的尺度归一化后(224×224)的信息区域![]() ,Teacher网络输出置信度作为teaching信号,帮助Navigator网络学习。除了特征提取器中的共享层外,Teacher网络还有一个全连接层,共有2048个神经元。为方便起见,我们将Teacher网络中的参数表示为
,Teacher网络输出置信度作为teaching信号,帮助Navigator网络学习。除了特征提取器中的共享层外,Teacher网络还有一个全连接层,共有2048个神经元。为方便起见,我们将Teacher网络中的参数表示为![]() 。
。
Scrutinizer network. 接收到Navigator网络的top-K个信息区域后,将这K个区域调整到预先定义的大小(实验中使用224×224),并将其输入特征提取器生成这K个区域的特征向量,每个区域的长度为2048。然后,我们将这些K个特征与输入图像的特征连接起来,并将其输入到一个具有2048×(K + 1)个神经元的全连接层(图4)。我们使用函数![]() 来表示这些转换的组成。我们将Scrutinizer网络中的参数表示为
来表示这些转换的组成。我们将Scrutinizer网络中的参数表示为![]() 。
。
3.5 Loss function and Optimization
Navigation loss. 将Navigator网络中预测的M个最具信息的区域表示为![]() ,其信息量表示为
,其信息量表示为![]() =
=![]() ,Teacher网络预测的置信度表示为
,Teacher网络预测的置信度表示为![]() =
=![]() 。然后navigation损失被定义为:
。然后navigation损失被定义为:
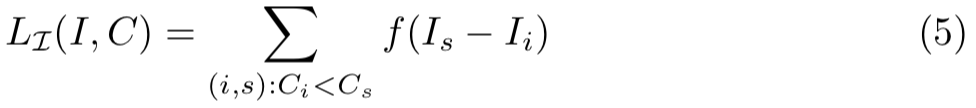
其中,函数f是non-increasing函数,用于当![]() 时,鼓励
时,鼓励![]() ,在我们的实验中,使用hinge损失函数
,在我们的实验中,使用hinge损失函数![]() 。该损失函数惩罚
。该损失函数惩罚![]() 和
和![]() 中错序的对,鼓励
中错序的对,鼓励![]() 和
和![]() 中有着相同顺序的对。navigation损失函数是可微的,在后向传播中根据链式规则估计关于
中有着相同顺序的对。navigation损失函数是可微的,在后向传播中根据链式规则估计关于![]() 的导数,我们能够得到:
的导数,我们能够得到:

该等式遵循定义![]()
Teaching loss. 我们定义Teaching损失![]() 为:
为:
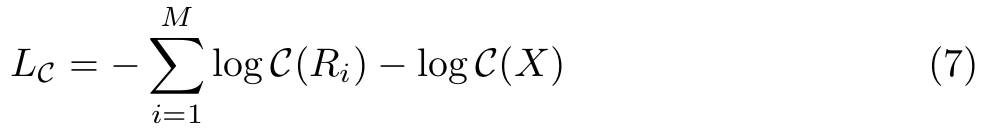
其中![]() 是置信度函数,将区域映射到其判定为ground truth类的概率。等式7的第一项是所有区域交叉熵损失的总和,第二项是整张图的交叉熵损失
是置信度函数,将区域映射到其判定为ground truth类的概率。等式7的第一项是所有区域交叉熵损失的总和,第二项是整张图的交叉熵损失
Scrutinizing loss. 当Navigator网络导航到最具信息的区域![]() ,Scrutinizer网络得到细粒度识别结果
,Scrutinizer网络得到细粒度识别结果![]() 。我们设置交叉熵损失为分类损失:
。我们设置交叉熵损失为分类损失:
![]()
Joint training algorithm. 总损失被定义为:
![]()
其中λ和μ为超参数。在我们的设置中,λ=μ= 1。总体算法可见算法1。我们使用随机梯度法来优化![]() 。
。

4 Experiments
4.1 Dataset
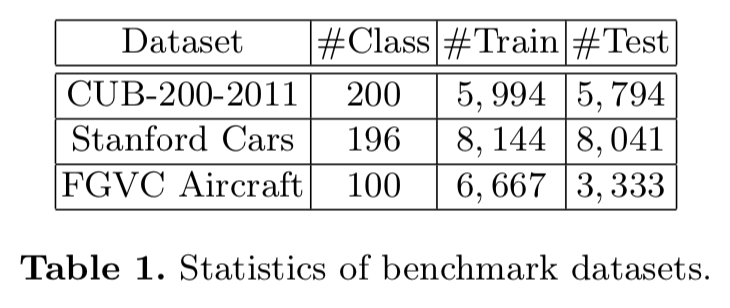
我们在Caltech-UCSD Birds (CUB-200-2011)[42]、Stanford Cars[23]和FGVC Aircraft[35]数据集上综合评价了我们的算法,这些数据集被广泛用作于细粒度图像分类的基准。我们在所有的实验中都没有使用任何bounding box/part标注。所有3个数据集的统计数据如表1所示,我们遵循与表中相同的训练/测试分割。
Caltech-UCSD Birds. CUB-200-2011是一项鸟类分类任务,有来自200种野生鸟类的11788张图像。训练数据与测试数据的比值大致为1:1。它通常被认为是最具竞争力的数据集之一,因为每个物种只有30张图像可供训练。
Stanford Cars. Stanford Cars数据集包含16,185张图像,超过196个类,每个类大约有一个50-50的分割。图片中的汽车是从多个角度拍摄的,类别通常是在生产年份和车型的级别(例如2012年特斯拉model S)。
FGVC Aircraft. FGVC Aircraft dataset包含10000张图像,超过100个类,训练/测试集分割比约为2:1。这个数据集中的大部分图像都是飞机。数据集被组织成一个从细到粗的四级层次结构:Model, Variant, Family, Manufacturer。
4.2 Implementation Details
在所有的实验中,我们进行预处理图像大小448×448,我们设置M = 6,这意味着6个区域被用于为每个图像训练Navigator网络(对超参数 K和M没有限制)。我们使用全卷积网络ResNet-50[17]作为特性提取器和使用 Batch Normalization作为规范器。我们使用初始学习率为0.001的Momentum SGD,并在60个epochs后乘以0.1,我们使用1e−4的权重衰减。NMS阈值设置为0.25,不使用预训练的检测模型。我们的模型对超参数的选择具有鲁棒性。
4.3 Quantitative Results
总的来说,我们提出的系统优于所有以前的方法。由于我们不使用任何bounding box/part标注,所以我们不与依赖于这些标注的方法进行比较。表2显示了我们的结果与CUB-200-2011之前的最佳结果的对比。ResNet-50是一个强大的基线,其本身达到了84.5%的精度,而我们提出的NTS-Net的表现明显优于它3.0%。与使用ResNet-50作为特征提取器的[26]相比,提高了1.5%。值得注意的是,当我们只使用完整图像(K = 0)作为Scrutinizer的输入时,我们的精度达到了85.3%,也高于ResNet-50。这一现象表明,在导航到信息区域时,Navigator网络也通过共享特征提取器来促进Scrutinizer,从而更好地学习特征表示。

表3分别显示了我们在FGVC Aircraft 和Stanford Cars上的结果。我们的模型实现了最新的最先进的结果,在FGVC Aircraft上得到91.4%的top-1准确率和Stanford Cars上93.9%的top-1准确率。

4.4 Ablation Study
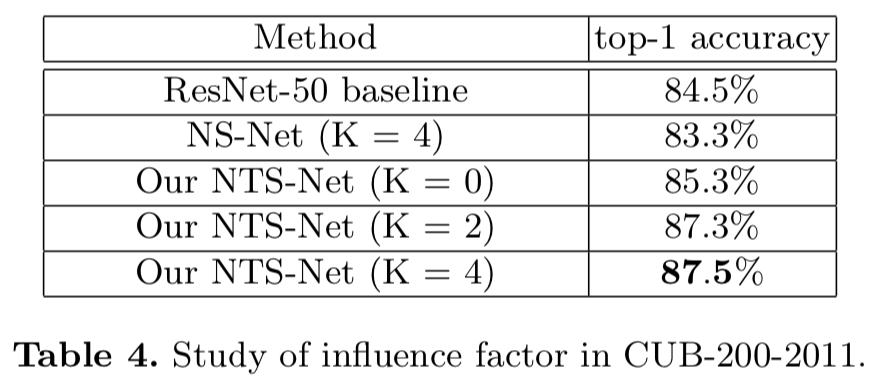
为了分析我们框架中不同组件的影响,我们在CUB-200-2011中设计了不同的运行,并将结果报告在表4中。我们使用NS-Net表示没有Teacher的指导的模型,NS-Net让Navigator网络单独提出区域,精度从87.5%下降到83.3%,我们假设这是因为Navigator没有收到teacher的监督,将随机推荐区域,这样导致我们不能从分类中获益。我们还研究了超参数K的作用,即 使用了多少个part区域进行分类。由表4可知,当K从2增加到4时,精度仅提高0.2%,精度提高很小,而特征维数几乎翻倍。另一方面,当K从0增加到2时,准确率增加了2.0%,这表明简单地增加特征维数只会得到很小的改善,但我们的多agent框架将实现相当大的改善(0.2% vs 2%)。
4.5 Qualitative Results
为了分析Navigator网络在哪里导航模型,我们在图5中绘制了Navigator网络预测的导航区域。我们使用红色、橙色、黄色、绿色矩形表示导航器网络提出的信息含量最高的四个区域,红色矩形表示信息含量最高的一个区域。可以看出,定位的区域确实为细粒度分类提供了信息。第一行显示了在cube -200-2011数据集中K = 2时:我们可以发现,使用两个区域可以覆盖鸟类的信息parts(特别是在第二幅图片中,即使鸟类的颜色和背景非常相似,也能区分出来鸟和背景)。第二行是在CUB-200-2011中设置K = 4时,我们可以看到鸟类信息最丰富的区域是头部、翅膀和身体,这与人类的认知是一致的。第三行是在 Stanford Cars中设置K = 4时:我们可以发现,headlamps和grilles被认为是车信息最丰富的区域。第四行是在FGVC Airplane中设置K = 4时:Navigator网络定位了飞机的机翼和机头,这对分类非常有帮助。

5 Conclusions
本文提出了一种不需要bounding box/part标注的细粒度分类方法。这三个网络:Navigator, Teacher和Scrutinizer相互合作,相互加强。我们设计了一个新的损失函数,它考虑了区域的信息和概率之间的排序一致性。我们的算法是端到端可训练的,并在CUB-200-2001, FGVC Aircraft 和Stanford Cars 数据集上取得了最先进的结果。

