
细粒度相关 - Learning to Zoom: a Saliency-Based Sampling Layer for Neural Networks - 1 - 论文学习
Learning to Zoom: a Saliency-Based Sampling Layer for Neural Networks
Abstract
我们为卷积神经网络引入了一个基于显著性的扭曲(distortion)层,这有助于改善给定任务的输入数据的空间采样。我们的可微层可以作为预处理块添加到现有的任务网络中,并以端到端方式完全训练。该层的作用是有效地估计如何从原始数据中采样,以提高任务性能。例如,对于一个图像分类任务的原始数据的大小可能高达几百万像素,但任务网络所需的输入图像要小得多,我们层学习如何能更好地从底层高分辨率数据上以比均匀采样更能保存任务相关信息的方式进行采样。这就产生了一种扭曲的、像漫画一样的中间图像的效果,在中间图像中,有助于提高任务性能的特殊元素被放大和夸大。与空间变换器网络等替代方法不同,我们提出的层受图像显著性的启发,从均匀下采样数据有效计算,并在不确定性下优雅地退化为均匀采样策略。我们将该层应用于改进现有的用于人眼注视估计和细粒度对象分类任务的网络。代码可见:https://github.com/recasens/Saliency-Sampler
1 Introduction
许多现代用于计算机视觉的神经网络模型都有输入尺寸限制[1,2,3,4]。这些限制的存在有各种各样的原因。通过限制输入分辨率,可以控制训练和测试期间所需的时间和计算量,并从GPU上的高效批处理训练中受益。在某些数据集上,限制输入特征维数也可以通过改进训练样本对输入空间的覆盖来提高性能。
当目标输入尺寸小于原始数据集中的图像时,标准的方法是对输入图像进行均匀下采样。也许最著名的例子是在 ImageNet Large Scale Visual Recognition Challenge [5]上训练分类器时常用的224×224像素输入,尽管原始数据集中存在一系列图像大小——可能高达数百万像素。
虽然均匀下采样在许多情况下简单有效,但对于需要不同空间分辨率和位置信息的任务来说,它可能是有损的。在这种情况下,必须在必要的(可能是不同的)尺寸和位置对突出的区域进行抽样。人类通过扫视目光来完成这些任务,以利用高度敏锐的中央凹视觉和粗糙的周边视觉来收集必要的信息。人们也曾尝试赋予机器类似形式的抽样行为。传统计算机视觉的一个流行的例子是SIFT[6],在特征提取之前,将关键点定位在空间和图像尺度内。近年来,区域proposal网络在目标检测[7]中得到了广泛的应用。为了更紧密地模仿人类的视觉系统,人们正在开发与任务相关的顺序注意机制,以允许以高分辨率处理许多场景区域(见例[8,9,10])。然而,这些方法放弃了一些使机器视觉具有吸引力的处理速度,并增加了proposal生成和评估任务完成的复杂性。
在这项工作中,我们引入了一个基于显著性的采样层:一个简单的插件模块,它可以附加到任何有输入限制的网络的开头,并用于以特定任务的方式改进下采样。如图1所示,给定目标图像输入大小,我们的显著性采样器学习将目标中的像素分配到潜在图像中对当前任务特别重要的区域。这样做,扭曲图像输入层,创建一个图像的变形版本,强调任务相关的部分,然后抑制无关紧要的部分,类似于漫画的脸试图放大的一个人的身份的那部分信息,使他们从平均水平中脱颖而出。

我们的层包括一个连接到一个的采样器显著映射估计器(saliency map),该采样器根据图像区域的相对显著值改变采样密度。由于该层被设计成完全可微的,它可以在任何传统网络之前插入,并经过端到端训练。与顺序注意模型不同[9,10,11,12],计算是在显著性采样器的单一通道中以恒定的计算成本执行的。
我们将我们的方法应用到小对象的发现或细粒度细节是重要的任务中(见图2),并一致发现在基线网络上添加我们的层得到了性能改进。

2 Related Work
我们将相关工作分为三大类:注意机制、基于显著性的方法和自适应图像采样方法。
Attention mechanisms: 注意力已被广泛用于提高CNN的性能。Jaderberg等[13]介绍了空间转换网络(STN),是一个用来从输入图像估计参数化转换的层,以撤销有害(nuisance)图像变化(如来自rigid目标分类任务的姿势),从而提高模型的泛化。在他们的工作中,作者提出了三种类型的转换可以学习:affine, projective 和thin plate spline (TPS)。尽管我们的方法也对输入图像应用了转换,但我们的应用程序是完全不同的:我们不试图撤消变化,如局部平移或旋转;相反,我们尝试动态地改变分辨率以适应输入图像中更具任务显著性的区域。虽然我们的方法可以封装在[13]的TPS方法中,但我们隐式地防止了极端转换和折叠,这对于基于TPS的空间转换器很容易发生(这也使得非参数采样map难以直接估计)。我们相信,这有助于防止戏剧性的失败,因此有助于使模块更容易学习。
Dai等人[14]引入的可变形卷积网络(Deformable convolutional networks,DCNs)具有与STNs相似的动机。他们表明,卷积层可以学习动态调整它们的接受域,以适应输入特征,并提高对有害因素的不变性。他们的建议包括用可变形层替换CNN中的任何标准卷积层,可变形层学习根据输入估计到标准核采样位置的偏移量。我们注意到我们的工作有四个主要不同之处。首先,他们的方法从与原始CNN架构相同的低分辨率输入中采样,而我们的显著性采样器被设计为从任何可用的分辨率中采样,允许它在可用时利用更高分辨率的数据。其次,我们的方法通过显著性映射来估计样本域,显著性映射在训练全卷积神经网络[15]时已经自然出现了。我们发现,就像在DCN中一样直接估计局部空间偏移要困难得多。第三,我们的方法可以在不修改的情况下应用于现有的训练过的网络,而DCNs需要通过变换可变形的卷积来改变网络配置。最后,我们的方法以显著性映射和变形图像的形式产生人类可读的输出,这允许容易的视觉检查和调试。我们注意到,我们提出的显著性采样器和DCNs并不是互斥的:我们的显著性采样器旨在跨尺度空间进行有效采样,并可能利用可变形的卷积层来帮助建模局部几何变化。与变形网络一样,Li等人[16]提出了一种使用非平方卷积的编码器-解码器结构。与[13]中一样,它们直接预测这些转换的参数化,而不是使用显著性映射。
Saliency-based methods: CNN已经被证明可以自然地将注意力引导到输入数据的任务显著区域。Zhou等人[15]发现CNN在分类任务中使用图像的有限部分来告知他们的决策。他们提出使用Class Activation Maps(CAM)作为一种机制来定位图像中的物体,在训练过程中没有明确的位置反馈。Rosenfeld等人[19]提出了一种迭代的方法来裁剪图像的相关区域进行细粒度分类。它们生成一个CAM来突出显示网络最常用的区域,以做出最终决定。这些区域被用来裁剪图像的一部分,并生成一个新的CAM,然后突出显示网络使用的图像区域,以通知最终的预测。正如在[15]中介绍的那样,CAM需要使用一种特殊的全卷积架构。为了克服这一限制,[20]引入了一种基于梯度的方法来生成CAMs。他们的方法可以用来理解各种各样的网络。在我们的工作中,我们通过鼓励网络更多地添加这些区域,来利用CNN自然定位任务显著区域的能力。
Adaptive image sampling methods: 解决这一问题的另一种可能的方法是在多尺度策略中预先设计某些特征检测器。这种方法通常是在解决一个特定的问题时使用的特性对人类来说非常清楚的情况下使用的。例如,为了解决移动设备显示器上的视线跟踪问题,Khosla等人[21]提出了iTracker方法,一种基于RGB图像的视线估计系统。他们的系统使用该设备前置摄像头的图像,并使用单独的探测器提取出眼睛和人脸的高分辨率图像。沿这条线的另一个例子是Wang等人的[22],他们生成输入图像在不同尺度上的特征,然后选择最好的特征,产生最终的输出。
自适应图像采样也被用于计算机图形学[23]中的图像重定向。不像在我们的例子中,采样图像仅作为解决另一个问题的中间表示,重新定位的目标是变形图像以适应新的形状,并保留对人类观察者重要的内容,同时避免可见的变形。与我们的概念类似,这可以由显著性[24]驱动,并将其表述为能量最小化[25]或Finite Element Method[26]问题。
3 Saliency Sampler
让![]() 表示任意大小的高分辨率图像,
表示任意大小的高分辨率图像,![]() 表示适合于任务网络
表示适合于任务网络![]() (图1)的大小为MxN像素的低分辨率图。通常, CNNs将输入图像
(图1)的大小为MxN像素的低分辨率图。通常, CNNs将输入图像![]() 的大小重置为
的大小重置为![]() ,而不利用
,而不利用![]() 的像素的相应重要性。但是,如果我们的任务更需要某一个图像区域的信息,那么密集地采样该区域可能会获得更好效果。saliency sampler首先分析
的像素的相应重要性。但是,如果我们的任务更需要某一个图像区域的信息,那么密集地采样该区域可能会获得更好效果。saliency sampler首先分析![]() ,然后按感知重要性的比例对
,然后按感知重要性的比例对![]() 的区域进行采样。在这样做的过程中,该模型可以获得一些提高分辨率的好处,而无需显著增加的计算负担或过度拟合的风险。
的区域进行采样。在这样做的过程中,该模型可以获得一些提高分辨率的好处,而无需显著增加的计算负担或过度拟合的风险。
采样过程可分为两个阶段。在第一阶段,使用CNN生成saliency map。这张map是特定于任务的,因为不同的任务可能需要关注不同的图像区域。第二阶段,根据saliency map对最重要的图像区域进行采样。
3.1 Saliency Network
saliency网络fs 从低分辨率图像中生成saliency map S :![]() 。在该阶段网络的选择是很灵活的,根据任务而变化。对于s的所有选择,我们在最后一层使用一个softmax操作去归一化输出map。
。在该阶段网络的选择是很灵活的,根据任务而变化。对于s的所有选择,我们在最后一层使用一个softmax操作去归一化输出map。
3.2 Sampling Approach
接下来,sampler g使用saliency map S和全分辨率图![]() 做为输入计算
做为输入计算![]() ,得到一个和
,得到一个和![]() 有着相同维度的图像,其从
有着相同维度的图像,其从![]() 采样得到,且S中高权重区域将被一个更大的图像范围表示(如图3)。在该节中,我们将讨论g采用的形式,使用更适用于CNNs的那个。在所有情况中,我们计算采样图和原始图之间的映射,然后使用在[13]中介绍的grid sampler。该映射能够能够被写成标准形式,如两个函数u(x,y)和v(x,y),即
采样得到,且S中高权重区域将被一个更大的图像范围表示(如图3)。在该节中,我们将讨论g采用的形式,使用更适用于CNNs的那个。在所有情况中,我们计算采样图和原始图之间的映射,然后使用在[13]中介绍的grid sampler。该映射能够能够被写成标准形式,如两个函数u(x,y)和v(x,y),即![]() (u(x,y)对应原图的x值,v(x,y)对应原图的y值,用来将原图(u(x,y),v(x,y))位置的像素映射到重采样图J的(x,y)位置)。
(u(x,y)对应原图的x值,v(x,y)对应原图的y值,用来将原图(u(x,y),v(x,y))位置的像素映射到重采样图J的(x,y)位置)。
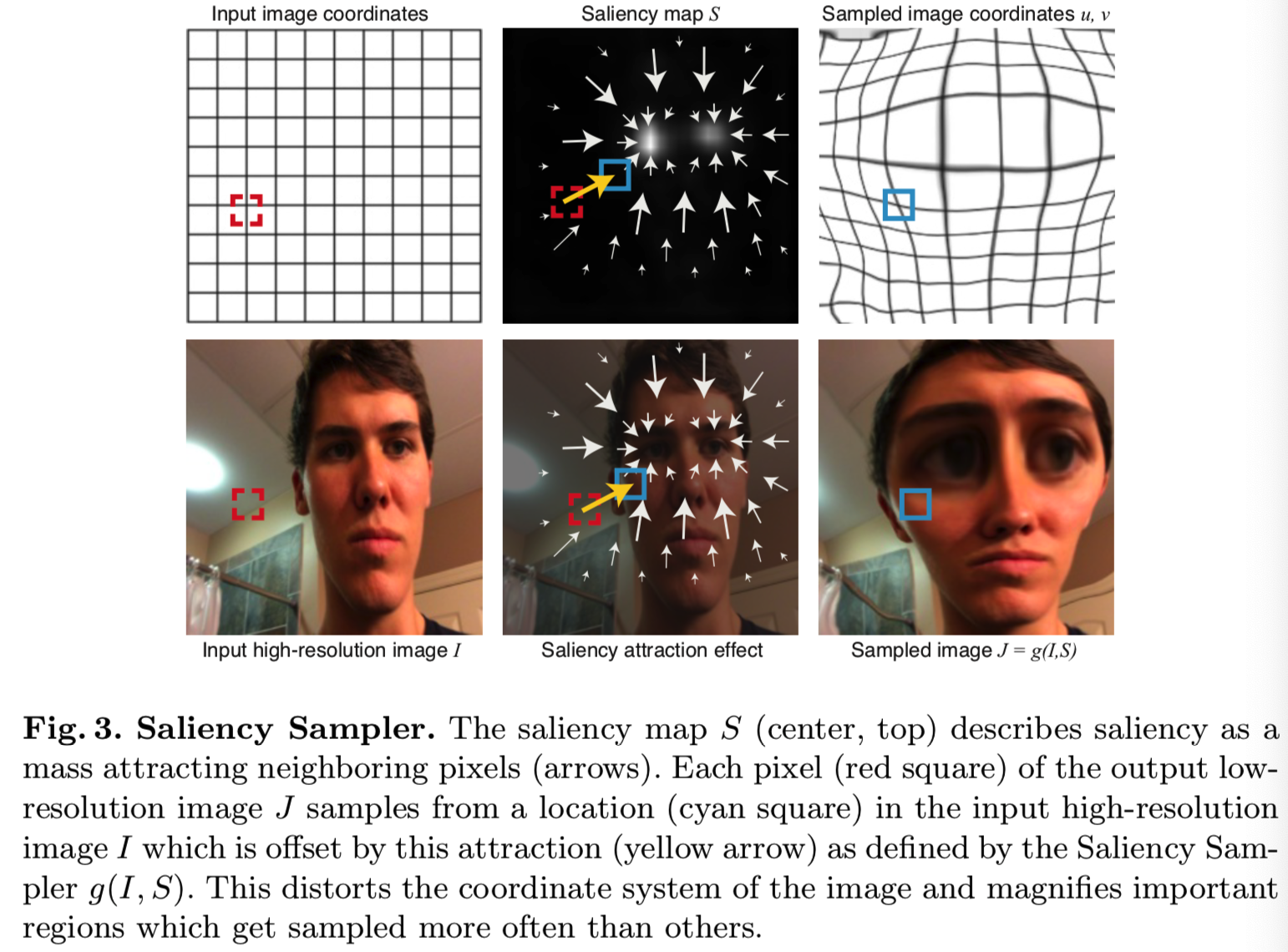
u和v设计的主要目的是按比例映射像素到saliency map复制给它们的归一化权重。假设u(x,y)和v(x,y)的x和y范围从0到1。一个该问题的确切近似将如下式去寻找u和v:
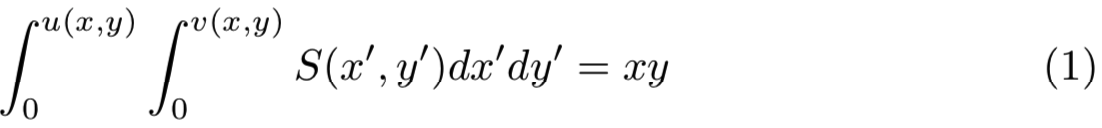
然而,求出u和v等价于求出将S(x, y)的分布集转换成均匀分布的变量的变化。这个问题已经被广泛地探索过,通常的解决方案在计算上是非常昂贵的[27]。因此,我们需要采取一种适合CNNs使用的替代方法。
我们的方法受到每个像素![]() 使用力
使用力![]() 拉扯其他像素的想法的启发(如图3)。如果我们添加距离核
拉扯其他像素的想法的启发(如图3)。如果我们添加距离核![]() ,则两个函数可以表示为:
,则两个函数可以表示为:
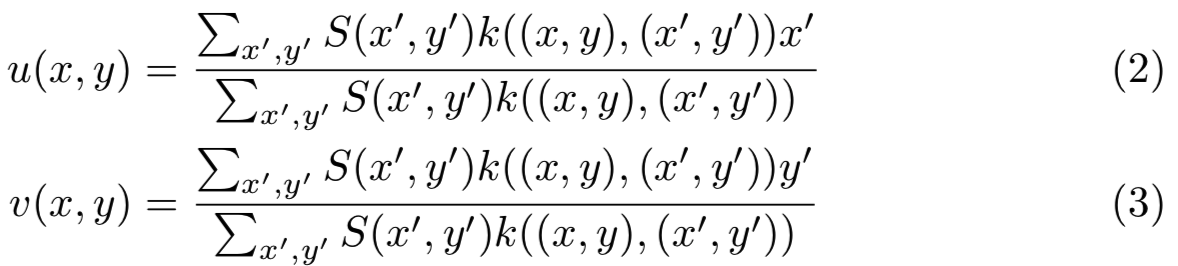
对于函数u和v,这个公式具有某些可取的性质,特别是:
Sampled areas: 高显著性区域的采样更密集,因为具有高显著性质量的像素会吸引其他像素。注意,内核k可以作为一个正则化器,以避免所有像素收敛到相同值的极端情况。在我们所有的实验中,我们使用一个参数σ设置为saliency map度的三分之一的高斯核,我们发现这在各种设置中工作得很好。
Convolutional form: 这种形式允许我们用简单的卷积来计算u和v,这是整个系统效率的关键。这一层可以很容易地添加到标准CNN中,并通过反向传播保持训练所需的可微性。
注意,等式2和等式3中的公式有一个不可取的偏向于图像中心的采样偏好。我们通过填充saliency map的边框值来避免这种影响。
代码
saliency_sampler.py:


import argparse import os import shutil import time import torch import torch.nn as nn import torch.nn.parallel import torch.backends.cudnn as cudnn import torch.distributed as dist import torch.optim import torchvision.transforms as transforms import torchvision.models as models import torch.nn.functional as F import torchvision.utils as vutils import torchvision.models as models import numpy as np import random def makeGaussian(size, fwhm = 3, center=None): """ Make a square gaussian kernel. size is the length of a side of the square fwhm is full-width-half-maximum, which can be thought of as an effective radius. """ x = np.arange(0, size, 1, float) y = x[:,np.newaxis] if center is None: x0 = y0 = size // 2 else: x0 = center[0] y0 = center[1] return np.exp(-4*np.log(2) * ((x-x0)**2 + (y-y0)**2) / fwhm**2) class Saliency_Sampler(nn.Module): def __init__(self,task_network,saliency_network,task_input_size,saliency_input_size): super(Saliency_Sampler, self).__init__() self.hi_res = task_network self.grid_size = 31 self.padding_size = 30 self.global_size = self.grid_size+2*self.padding_size self.input_size = saliency_input_size self.input_size_net = task_input_size self.conv_last = nn.Conv2d(256,1,kernel_size=1,padding=0,stride=1) gaussian_weights = torch.FloatTensor(makeGaussian(2*self.padding_size+1, fwhm = 13)) # Spatial transformer localization-network self.localization = saliency_network self.filter = nn.Conv2d(1, 1, kernel_size=(2*self.padding_size+1,2*self.padding_size+1),bias=False) self.filter.weight[0].data[:,:,:] = gaussian_weights self.P_basis = torch.zeros(2,self.grid_size+2*self.padding_size, self.grid_size+2*self.padding_size) for k in range(2): for i in range(self.global_size): for j in range(self.global_size): #k = 0时,为(j-self.padding_size)/(self.grid_size-1.0) #k=1时,为(i-self.padding_size)/(self.grid_size-1.0) #k=0时,每一行都相同,前[0:30]是[-1,0], [30:60]是[0,1],[60:]是[1,2] ##k=1时,每一列都相同,前[0:30]是[-1,0], [30:60]是[0,1],[60:]是[1,2] self.P_basis[k,i,j] = k*(i-self.padding_size)/(self.grid_size-1.0)+(1.0-k)*(j-self.padding_size)/(self.grid_size-1.0) def create_grid(self, x): #x : 相当于论文中等式2和等式3的S(x',y')* k((x,y),(x',y')),是权重 #P : 相当于论文中等式2和等式3的[x',y'] # P = torch.autograd.Variable(torch.zeros(1,2,self.grid_size+2*self.padding_size, self.grid_size+2*self.padding_size).cuda(),requires_grad=False) P = torch.autograd.Variable(torch.zeros(1,2,self.grid_size+2*self.padding_size, self.grid_size+2*self.padding_size).cpu(),requires_grad=False) # print("P size is : ", P.size()) #torch.Size([1, 2, 91, 91]) P[0,:,:,:] = self.P_basis #从[1, 2, 91, 91]扩展为[batch_size, 2, 91, 91] P = P.expand(x.size(0),2,self.grid_size+2*self.padding_size, self.grid_size+2*self.padding_size) # print("P size is : ", P.size()) #torch.Size([5, 2, 91, 91]) x_cat = torch.cat((x,x),1) #[batch_size, 2, 91, 91] # print("x_cat size is : ", x_cat.size()) #torch.Size([5, 2, 91, 91]) #得到的是论文中等式2的分母 p_filter = self.filter(x) #输入[batch_size, 1, 91, 91],输出[batch_size, 1, 31, 31] # print("p_filter is : ", p_filter) # print("p_filter size is : ", p_filter.size()) #torch.Size([5, 1, 31, 31]) #得到的是论文中等式2和等式3的分子 x_mul = torch.mul(P,x_cat).view(-1,1,self.global_size,self.global_size) #[batch_size*2, 1, 91, 91] # print("x_mul size is : ", x_mul.size()) #torch.Size([10, 1, 91, 91]) #filter()输入[batch_size*2, 1, 91, 91], 输出[batch_size*2, 1, 31, 31] #然后重置为[batch_size, 2, 31, 31] all_filter = self.filter(x_mul).view(-1,2,self.grid_size,self.grid_size) # print("all_filter size is : ", all_filter.size()) #torch.Size([5, 2, 31, 31]) # x_filter是u(x,y)的分子,y_filter是v(x,y)的分子 x_filter = all_filter[:,0,:,:].contiguous().view(-1,1,self.grid_size,self.grid_size) #[batch_size, 1, 31, 31] y_filter = all_filter[:,1,:,:].contiguous().view(-1,1,self.grid_size,self.grid_size) #[batch_size, 1, 31, 31] # print("y_filter size is : ", y_filter.size()) #torch.Size([5, 1, 31, 31]) #值的范围是[0,1] x_filter = x_filter/p_filter #u(x,y) y_filter = y_filter/p_filter #v(x,y) # print("y_filter is : ", y_filter) # print("y_filter max is : ", y_filter.max()) #tensor(1.0341, grad_fn=<MaxBackward1>) # print("y_filter min is : ", y_filter.min()) #tensor(-0.0268, grad_fn=<MinBackward1>) #将值的范围从[0,1]改为[-1,1] xgrids = x_filter*2-1 ygrids = y_filter*2-1 # print("ygrids max is : ", ygrids.max()) #tensor(1.0200, grad_fn=<MaxBackward1>) # print("ygrids min is : ", ygrids.min()) #tensor(-1.0502, grad_fn=<MinBackward1>) xgrids = torch.clamp(xgrids,min=-1,max=1) #将里面的值的范围控制在[-1,1] ygrids = torch.clamp(ygrids,min=-1,max=1) xgrids = xgrids.view(-1,1,self.grid_size,self.grid_size) ygrids = ygrids.view(-1,1,self.grid_size,self.grid_size) grid = torch.cat((xgrids,ygrids),1) #[batch_size, 2, 31, 31] grid = nn.Upsample(size=(self.input_size_net,self.input_size_net), mode='bilinear')(grid) #上采样为[batch_size, 2, 224, 224] grid = torch.transpose(grid,1,2) #[batch_size, 224, 2, 224] print("grid size is : ", grid.size()) #torch.Size([5, 224, 2, 224]) grid = torch.transpose(grid,2,3) #[batch_size, 224, 224, 2] print("grid size is : ", grid.size()) #torch.Size([5, 224, 224, 2]) return grid def forward(self, x,p): x_low = nn.AdaptiveAvgPool2d((self.input_size,self.input_size))(x) #先均匀下采样得到低分辨率图,[batch_size,3,224,224] # print('x_low size is : ', x_low.size()) #torch.Size([5, 3, 224, 224]) xs = self.localization(x_low) #得到saliency map,当输入是[batch_size,3,224,224]时,输出是[batch_size, 256, 14, 14] # print('xs size is : ', xs.size()) #torch.Size([5, 256, 14, 14]) xs = nn.ReLU()(xs) xs = self.conv_last(xs) #得到saliency map,channels=1,即[batch_size, 1, 14, 14] # print('xs size is : ', xs.size()) #torch.Size([5, 1, 14, 14]) xs = nn.Upsample(size=(self.grid_size,self.grid_size), mode='bilinear')(xs) #上采样为[batch_size, 1, 31, 31] # print('xs size is : ', xs.size()) #torch.Size([5, 1, 31, 31]) xs = xs.view(-1,self.grid_size*self.grid_size) #重置大小为[batch_size, 31*31] # print('xs size is : ', xs.size()) #torch.Size([5, 961]) xs = nn.Softmax()(xs) #得到每个像素的权重 # print('xs size is : ', xs.size()) #torch.Size([5, 961]) xs = xs.view(-1,1,self.grid_size,self.grid_size) #再重置为[batch_size, 1, 31, 31] # print('xs size is : ', xs.size()) #torch.Size([5, 1, 31, 31]) #对图像或者张量的边缘进行镜像对称的填充,大小为[batch_size, 1, self.grid_size+2*self.padding_size, self.grid_size+2*self.padding_size] #即[batch_size, 1, 91, 91] xs_hm = nn.ReplicationPad2d(self.padding_size)(xs) #避免等式2和3偏向于图像中心的采样偏好 # print('xs_hm size is : ', xs_hm.size()) #torch.Size([5, 1, 91, 91]) grid = self.create_grid(xs_hm) #输入为x = [batch_size, 3, x_size, x_size], grid=[batch_size, 224, 224, 2],grid是归一化后的结果,值范围为[-1,1] #输出x_sampled为[batch_size, 3, 224, 224] #grid的[n,h,w]指定的2维表示(x,y),意思是输入x的(x,y)位置的像素插到输出x_sampled的x_sampled[n,:,h,w]上 x_sampled = F.grid_sample(x, grid) #得到重采样的图像 if random.random()>p: #均匀采样 s = random.randint(64, 224) x_sampled = nn.AdaptiveAvgPool2d((s,s))(x_sampled) x_sampled = nn.Upsample(size=(self.input_size_net,self.input_size_net),mode='bilinear')(x_sampled) x = self.hi_res(x_sampled) return x,x_sampled,xs if __name__ == '__main__': from saliency_network import saliency_network_resnet18 from resnet import resnet101 model_v = Saliency_Sampler(resnet101(),saliency_network_resnet18(),224,224) import torch from torch.autograd import Variable input_ = Variable(torch.randn((5,3,800,800))) x,x_sampled,xs = model_v(input_, 1)
3.3 Training with the Saliency Sampler
当网络需要更高分辨率输入的更有信息的子采样时,saliency sampler可以插入到任何卷积神经网络ft中。由于该模块是端到端可微的,我们可以用标准的优化技术训练整个pipeline。我们的完整pipeline包括四个步骤(见图1):
1.获得图![]() 的一个低分辨率版本
的一个低分辨率版本![]()
2.图像![]() 被用于saliency 网络 fs去计算saliency map
被用于saliency 网络 fs去计算saliency map ![]() ,图像中与任务相关的区域被赋予更高的权重
,图像中与任务相关的区域被赋予更高的权重
3.根据saliency map ,使用deterministic grid sampler g去采样高分辨率图像![]() ,获得重采样图像
,获得重采样图像![]() ,其与
,其与![]() 有着相同的分辨率
有着相同的分辨率
4.原始任务网络ft被用于计算最后的输出 ![]() (使用的输入是重采样图像J)
(使用的输入是重采样图像J)
fs和ft都有可学习的参数,因此可以针对特定任务联合训练。我们发现,在训练过程的开始阶段,对重新采样的任务网络输入图像进行模糊处理是有帮助的。它迫使显著性采样器更深入地放大图像,以便进一步放大小的细节,否则会被随后的模糊破坏。这甚至对移除模糊后的模型的最终性能都是有益的。
4 Experiments
省略
5 Discussion
添加我们的saliency sampler对于那些特征小且稀疏,或出现在多个图像尺度的图像任务来说是十分有利的。如果另一个感兴趣的点受到影响,在放大区域附近引入的变形可能会潜在地阻止网络产生强烈的变形。这对文本识别等任务可能是有害的。在实践中,我们观察到学习过程能够很好地处理这种情况,因为它能够在不影响注视预测性能的情况下放大两眼。这是特别有趣的,因为这项任务需要保存图像中的几何信息。该方法被证明比其他修改空间采样的方法更容易训练,如Spatial Transformer Networks [13] 或Deformable Convolutional Networks [14]。由于这些方法无法为其抽样策略找到合适的参数,因此这些方法的性能往往接近基线。saliency map引入的非均匀放大方法也允许在空间域上可变性缩放。正如我们在细粒度分类任务中观察到的那样,与一致放大的感兴趣区域crops相比,这一点加上端到端优化会带来性能上的好处。与iTracker[21]的情况不同,我们在任务中不需要关于相关图像特征的先验知识。
6 Conclusion
我们提出了saliency sampler —— 一种新的CNNs层,它可以适应图像采样策略来提高任务性能,同时为给定的图像处理任务保留内存分配和计算效率。我们已经证明了我们的技术在定位和聚焦图像特征方面的有效性,这些特征对于注视跟踪和细粒度目标识别的任务很重要。该方法很容易集成到现有的模型中,并且可以以端到端的方式有效地训练。与其他一些图像变换技术不同,我们的方法不限于预先定义的重要区域的数量或大小,它可以在整个图像域重新分配采样密度。同时,我们的技术通过单个标量注意力映射实现参数化,使其对由于折叠或奇点导致的图像不可恢复的退化具有鲁棒性。这导致在需要恢复小图像特征,如眼睛或相关动物物种之间的细微差别的问题上的卓越表现。

