
细粒度 - Selective Sparse Sampling for Fine-grained Image Recognition - 1 - 论文学习
参考代码 https://github.com/Yao-DD/S3N
Selective Sparse Sampling for Fine-grained Image Recognition
Abstract
细粒度识别提出了一个独特的挑战,即在相当大的类间差异下捕捉细微的类内差异(如鸟类的喙)。传统的方法是crop局部区域并从这些区域中获取详细的表征,但存在parts数量固定和缺少周边上下文信息的问题。在本文中,我们提出了一个简单而有效的框架,称为选择性稀疏采样,以捕获多样化和细粒度的细节。该框架使用卷积神经网络实现,称为选择性稀疏采样网络(Selective Sparse Sampling Networks ,S3Ns)。通过图像级监督,S3Ns从类响应maps中收集峰值,即局部最大值,以估计信息接收域,并学习一组稀疏的注意力,以捕捉详细的视觉证据并保存上下文。通过对证据的选择性采样,提取出具有区别性和互补性的特征,显著丰富了学习到的表征,引导网络发现更多的微妙线索。大量的实验和ablation研究表明,在CUB-200-2011、FGVC-Aircraft和Stanford Cars等具有挑战性的基准上,所提出的方法始终优于最先进的方法
1. Introduction
细粒度识别是指在图像中识别一个基本类别下的下一级类别,如鸟类种类[24]、花卉品种[19]、汽车型号[10]、飞机类型[15]。与一般的图像分类相比,由于类内图像的细微差异,精细纹理识别更具挑战性。
认知神经科学的研究[8,16]发现,人类视觉系统在理解一个场景时会经历三个阶段。这些阶段包括视觉跳跃激活显著区域、视觉觅食选择感兴趣区域和视觉固定注视局部区域以做出最终的决定。
受此启发,许多前人的研究[31,7,13,6,30,20]通过两个主要成分来解决细粒度图像识别问题,即可区分的parts定位和ROI特征提取。然而,主要的缺点有三个方面:
1)在图像级监督下准确估计parts的bounding box仍然是一个开放的问题,经常使用复杂且耗时的pipelines,如弱监督检测模型[33,29]、循环挖掘[3]或强化学习[12]。
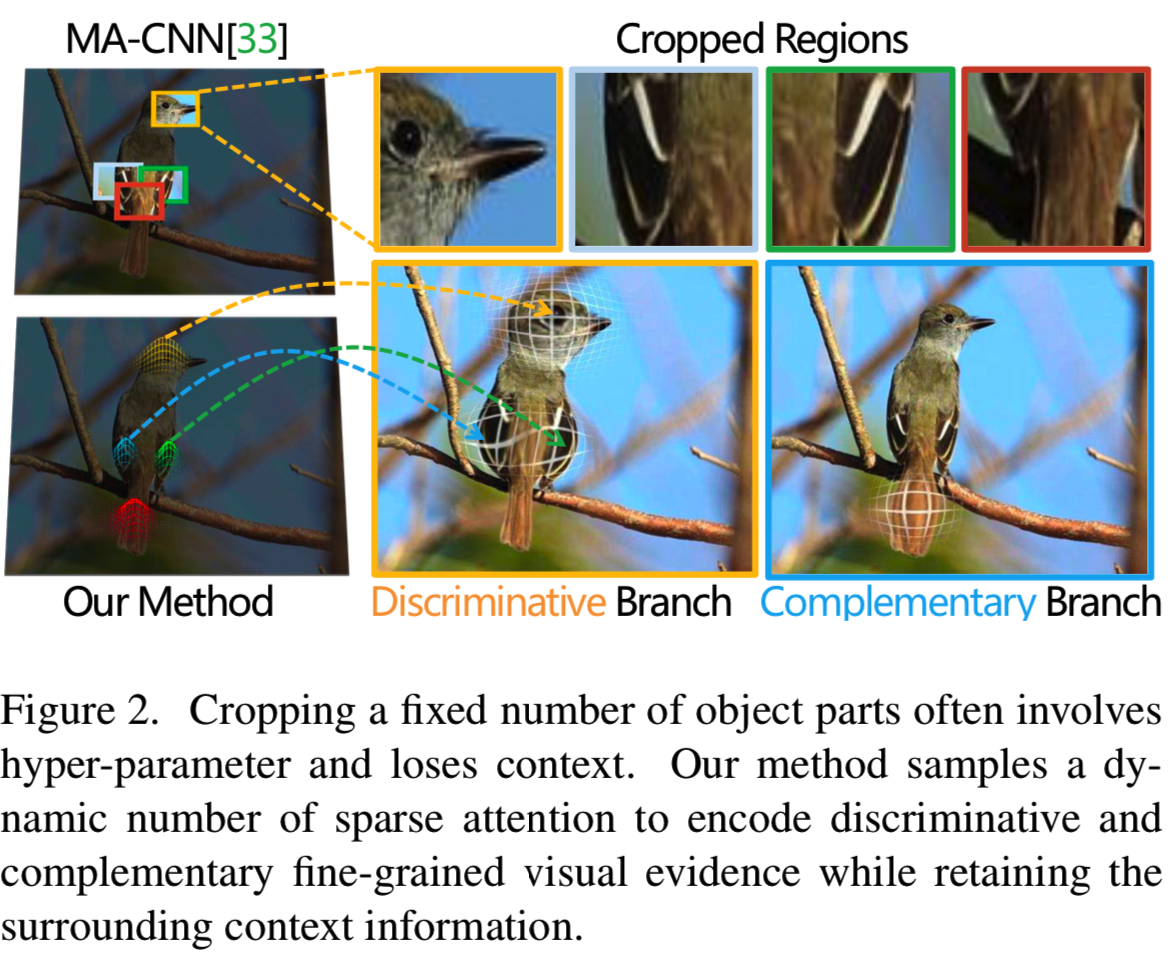
2)局部parts的数量通常是一个预定义的超参数,它是固定的(如[29]的four parts),不适应图像内容。
3)最后,“hard” crop操作忽略了每个局部区域的周围上下文信息,这限制了生成特征的表达能力,特别是在发生定位错误时。
在本文中,我们通过提出选择性稀疏采样(Selective Sparse Sampling)框架来解决细粒度识别问题,如图1所示。我们的方法模仿人类的视觉系统,在图像内容的条件下预测一组动态稀疏注意力。每个注意力都集中在一个信息区域上,以估计适当的尺度,并在不丢失上下文信息的情况下捕获详细的视觉证据。
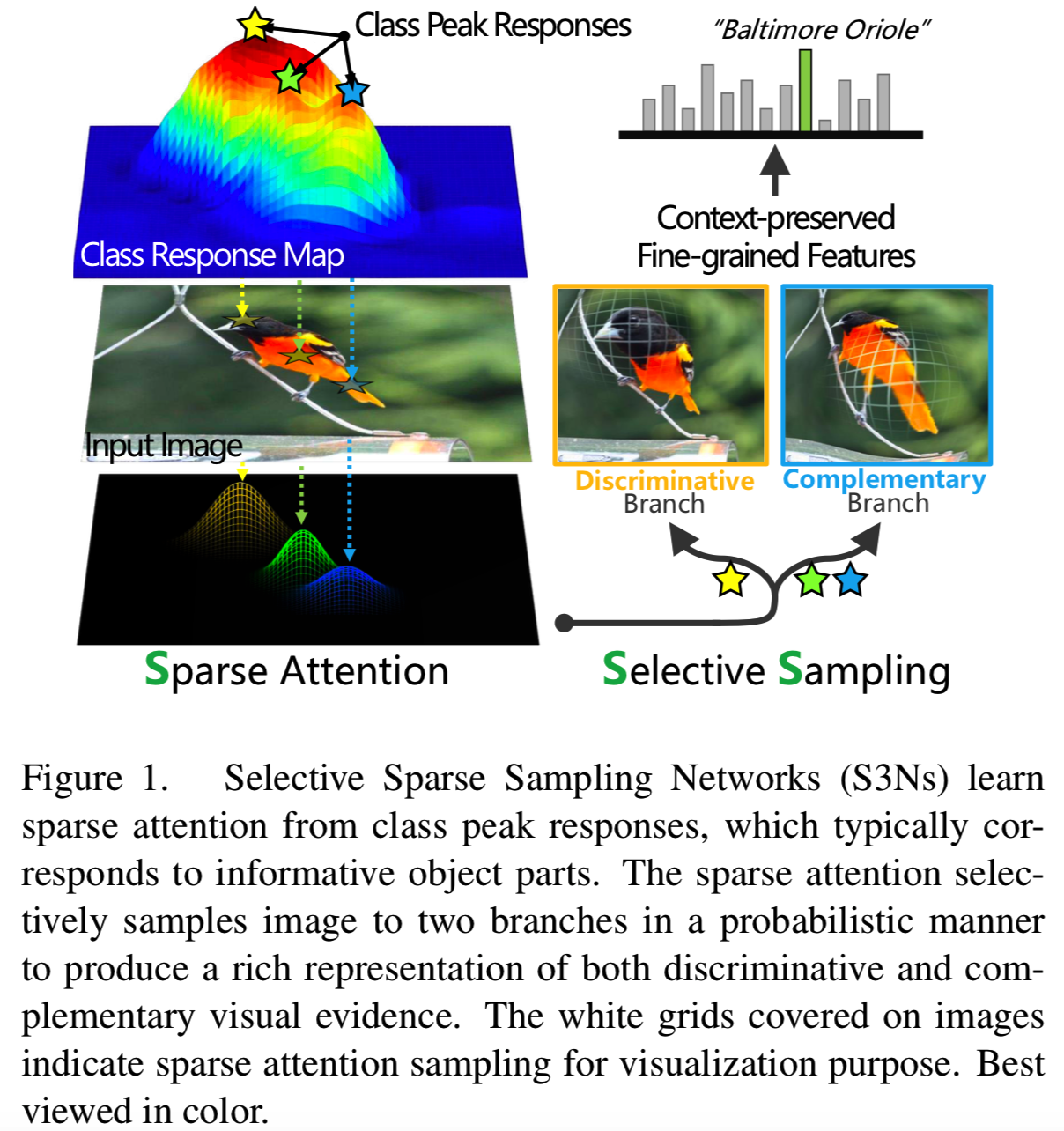
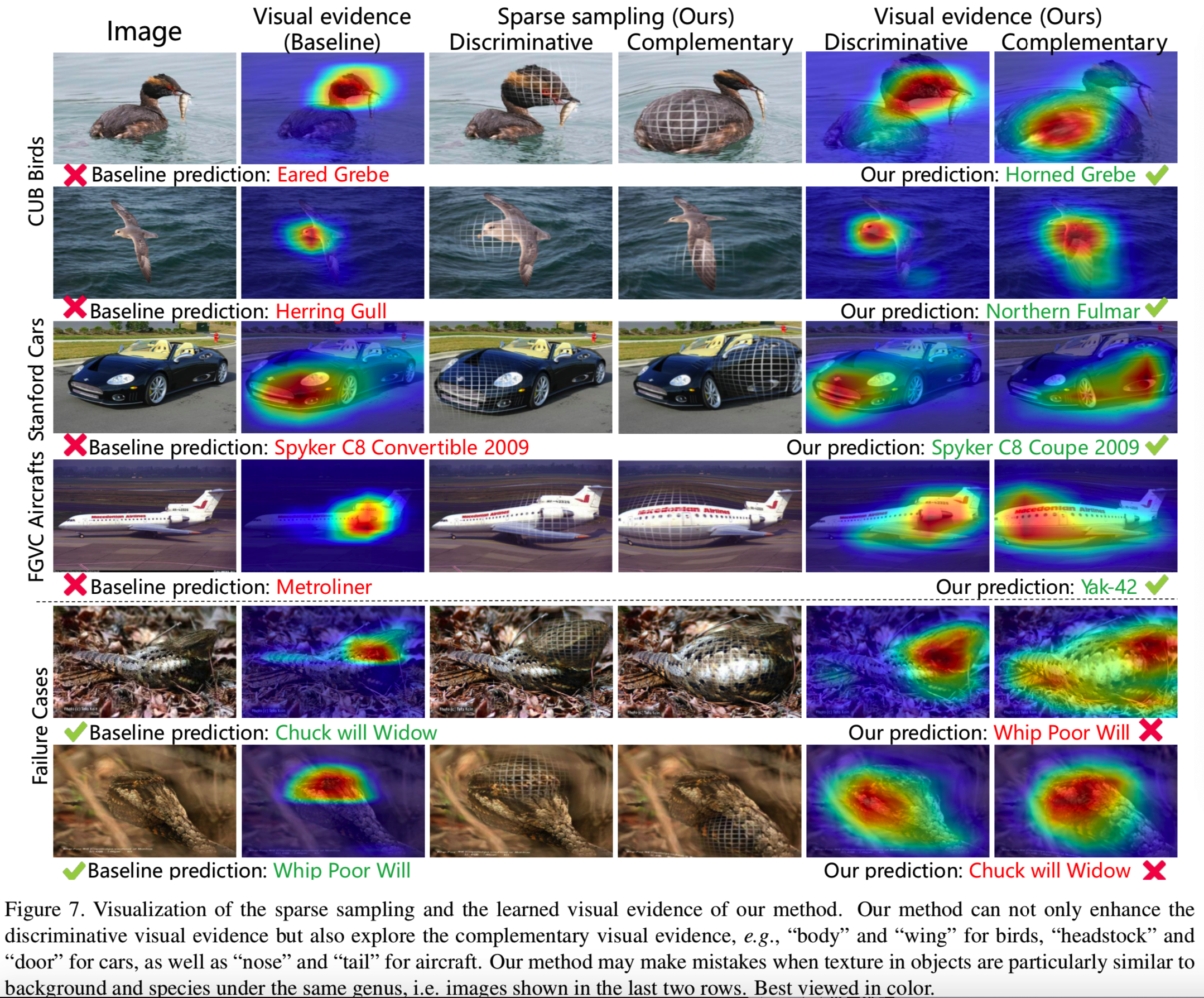
提出的使用卷积神经网络(CNNs)实现的框架称为S3Ns。s3n是通过图像级监督(即对象类别)来训练的。我们首先收集类峰值响应(class peak responses),即来自类响应maps的局部最大值[34,35],作为对包含感兴趣对象的视觉线索的信息接受域的估计。然后,我们估计每个识别的类峰值响应的规模,形成一组稀疏注意力。通过非齐次变换对图像进行选择性采样,突出相应区域,引导网络学习判别特征和互补特征。
与传统方法相比,该方法简单有效。通过利用CNN学习到的表示,即类峰值响应,我们的方法不需要额外的监督,但可以准确定位信息区域(详见第4.1节)。此外,稀疏注意力parts的数量是动态的,并取决于图像的内容。因此,提出的框架更加灵活,可以应用于不同的领域,如鸟类、飞机和汽车,无需为每个特定任务调整超参数。此外,S3N以一种“soft”方式突出显示信息区域,这有助于捕获细粒度特征并保存上下文信息,在基线之上实现显著的性能提高,如图2所示。
本文的主要贡献包括:
- 开发了一种新的选择性稀疏采样(Selective Sparse Sampling)框架,该框架通过学习一组稀疏注意力去选择性采样信息区域,并在保留上下文信息的同时提取可区分和互补特征,解决了具有挑战性的细粒度图像识别问题。
- 我们的方法在ResNet50等流行的CNN上的实现,证明了在模型精度和挖掘视觉证据的能力方面的基线上有实质性的改进。
- 全面的实验分析以及在常见的细粒度识别基准上,包括CUB-200-2011 Birds, FGVC-Aircraft, and Stanford Cars,具有最新最先进的性能。
2. Related Work
在本节中,我们从特征学习和可区分区域定位的角度简要回顾了以往的工作。
Fine-grained Feature Learning : 学习具有代表性的特征是细粒度图像识别的关键。深度特征[11,23,5]在一般图像识别任务中取得了前所未有的性能,但在细粒度图像识别中却不太令人满意。
在[14]中,Lin等人认为特征对于细粒度分类的有效性是由于它们对对象位置和姿态的不变性。他们提出了一种双线性框架,它是一种无规则的纹理表示,并以翻译不变的方式捕捉局部特征交互。Gao等[4]将双线性模型更新为紧凑结构,可以将特征维数降低两个数量级。Kong等人[9]使用双线性分类器替代双线性特征,提高了计算效率,同时减少了需要学习的参数数量。
目前的特征学习方法主要侧重于探索物体表征的不变特征,但往往忽略了判别区域的空间分布,这限制了其在面对明显变形的物体时的性能。我们的S3N增强了采样稀疏注意的局部特征,自然实现了对空间信息的编码。
Discriminative Region Localization: 这些方法通常包括两个阶段:1)定位对象parts和裁剪固定数量的局部区域。2)从受限制的parts中提取特征,并对所有特征进行聚合,最终进行识别。
许多早期的研究集中于通过bounding box和part标注来定位重要区域进行细粒度识别[24,31,13,6,30,20]。尽管这种受监督的注释很有效,但获取它的代价很高。
因此,越来越多的研究探索弱监督方法来估计判别区域。对象检测方法为proposal区域的生成提供了参考。如Xiao等人[28]、Zhang等人[32]采用选择性搜索(Selective Searc),Yang等人[29]将特征金字塔网络引入细粒度识别。然后,设计一些策略,如part鉴别器或特定的损失,来过滤掉信息patches。Zheng等人将卷积网络中的[33]信道划分为不同group来生成不同的part模式。除此之外,还应用了注意力机制。Fu等[3]在多个尺度(如3个)上递归学习判别区域,Li等[17,22,12]使用循环视觉注意模型选择一系列注意区域。尽管基于part的区分方法很有效,但他们使用了“hard” part crop策略,忽视了被裁剪区域周围的环境,这限制了相应特征的预测能力。相反,我们使用一种soft方式来放大局部区域,同时保留上下文。
Recasens等人[21]首先提议对显著性映射进行非均匀采样。我们的方法与这项工作有以下三个不同之处。首先,我们提出对稀疏注意进行采样,这是class-aware的,并且比[21]中使用的class-agnostic显著性具有更丰富的表示。其次,我们的稀疏注意力通常对应于精细的对象部分,如喉咙、颈背和冠,提供了比[21]的显著区域更微妙的视觉证据。第三,S3N明确将视觉证据划分为两个平行的采样分支,即判别分支和互补分支,而[21]模型将其共同采样。
3. Methodology
提出的选择性稀疏采样框架首先学习一组稀疏注意,其中指定对任务具有信息的候选区域的位置和尺寸。然后,该框架利用学习到的稀疏注意力,有选择地将输入图像样本分为判别和互补分支,提取上下文保留的细节特征。该框架使用卷积神经网络(CNN)骨干(如ResNet50)实现,并可以通过标准分类设置(如图像级监督和交叉熵损失)进行端到端的训练,如图3所示。
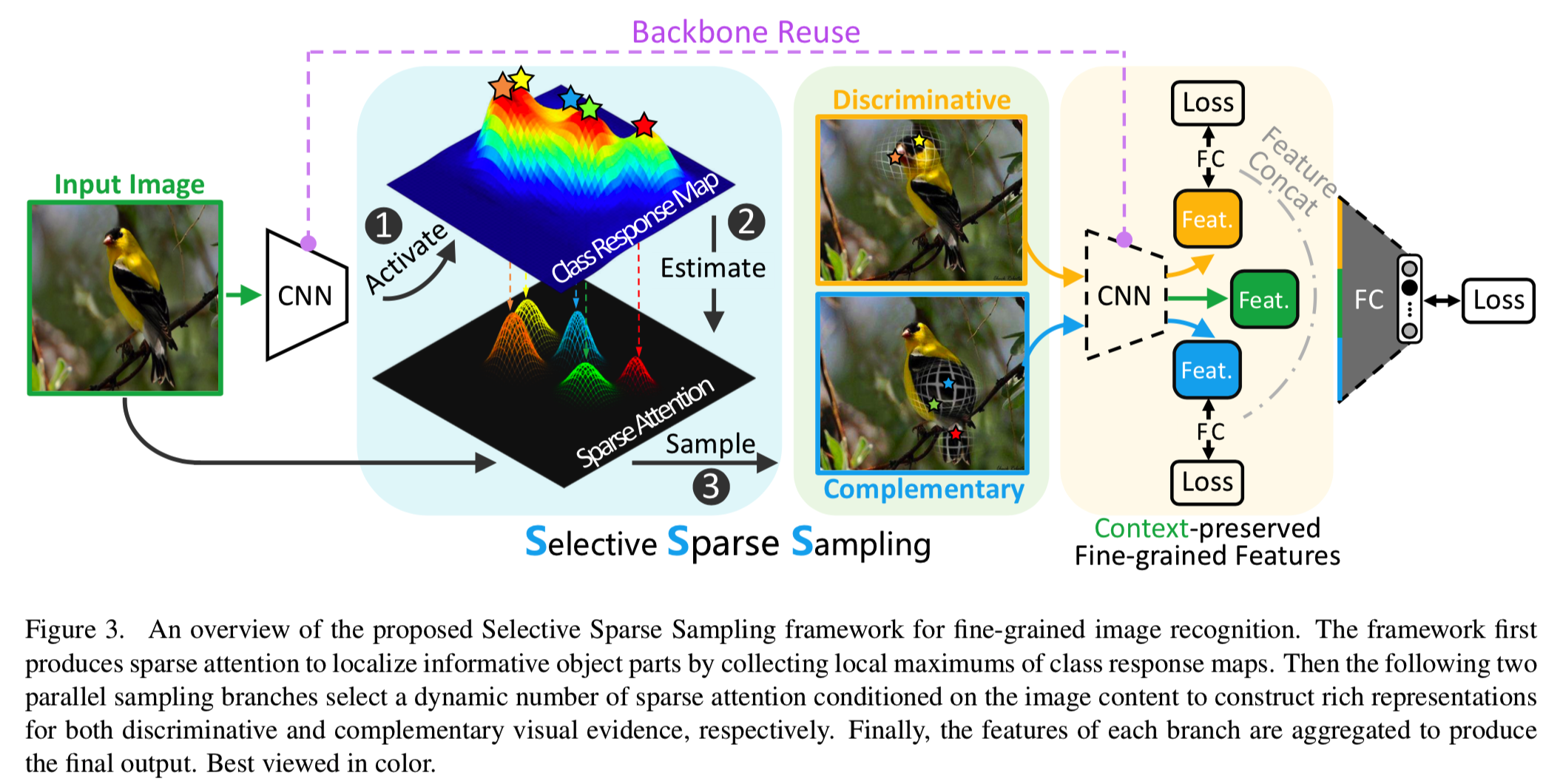
3.1. Revisiting Class Peak Response
给定一个输入图像X,我们的方法通过利用用图像级类别监督训练的分类网络的类别响应maps(class response maps)产生的类峰值响应(即局部最大值)来预测一组稀疏注意力[34,35]。
我们首先将图像X输入到CNN backbone中,从top卷积层抽取特征maps。得到的特征maps被标注为![]() ,其中D是特征通道的数量,HxW是特征map 的空间大小。然后特征maps S被输入到Global Average Pooling(GAP)层(得到Dx1x1的输出),后面跟着一个全连接层(FC)去得到类分数
,其中D是特征通道的数量,HxW是特征map 的空间大小。然后特征maps S被输入到Global Average Pooling(GAP)层(得到Dx1x1的输出),后面跟着一个全连接层(FC)去得到类分数![]() ,其中C是细粒度对象类别的数量。使用FC层
,其中C是细粒度对象类别的数量。使用FC层![]() 层的权重矩阵,我们能够计算类响应map
层的权重矩阵,我们能够计算类响应map ![]() :
:
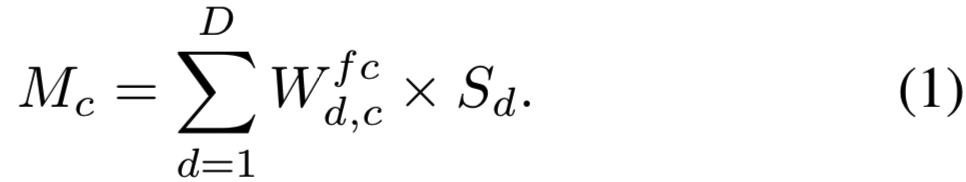
(即大小为cx1的W权重 乘以 大小为 1xHxW的特征映射,得到一个通道的Mc;D个通道的结果求和,最终得到cxHxW的类响应maps Mc)
类别c的类峰值响应(class peak response)被定义为对应类响应map ![]() 中一个r 窗口大小中的局部最大值。且峰值位置被表示为
中一个r 窗口大小中的局部最大值。且峰值位置被表示为![]() ,其中Nc是类c的有效峰值的数量。类峰值响应通常对应于感兴趣区域[35]内的强烈视觉线索。
,其中Nc是类c的有效峰值的数量。类峰值响应通常对应于感兴趣区域[35]内的强烈视觉线索。
3.2. Learning Sparse Attention
我们利用学习到的峰值来定位接受域(特别是有与任务相关的信息的区域),并估计一组稀疏的注意力来提取细粒度的视觉证据。
为了保持训练和测试阶段的一致性,我们使用预测的类分数 s 来为学习和推理阶段选择候选峰值。根据实验观察,top-1类响应map(即预测得到的top-1类c'对应的Mc,大小为1xHxW)中的峰值并不总是足以覆盖判别部分。然而,top-k中的峰值相当多,但可能有噪声。为了平衡视觉证据的召回和精确度,我们有选择性地从预测值排名前1或前5的类别中提取峰值。
让![]() 表示所有类的预测概率,
表示所有类的预测概率,![]() 为top-5类分数概率子集,降序排列。计算熵为:
为top-5类分数概率子集,降序排列。计算熵为:
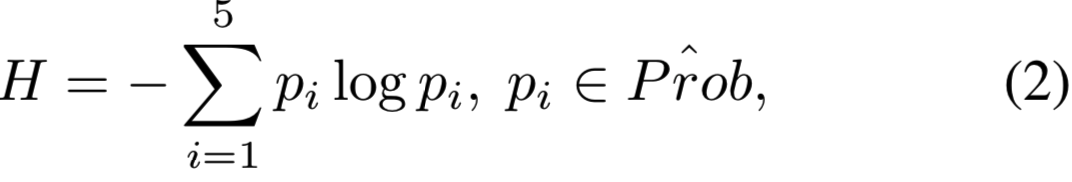
然后用下面的策略构造一个响应map R(大小为1xHxW):
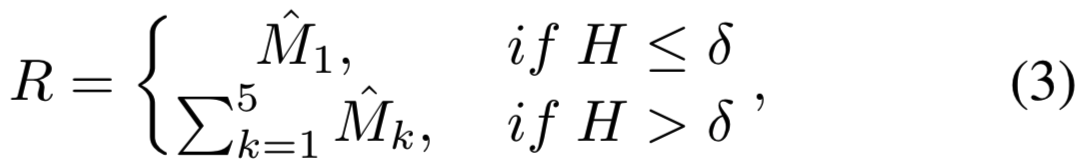
其中![]() 是与
是与![]() 相关的5个类响应maps,δ是阈值(在实验中设置为0.2,当δ值在[0.1, 0.3]范围时,模型准确度对δ是不敏感的)
相关的5个类响应maps,δ是阈值(在实验中设置为0.2,当δ值在[0.1, 0.3]范围时,模型准确度对δ是不敏感的)
然后使用Min-Max Normalize,即![]() ,将R映射为[0,1]。最后,在R中一个r 的窗口大小内寻找局部最大值,并表示它们的位置为
,将R映射为[0,1]。最后,在R中一个r 的窗口大小内寻找局部最大值,并表示它们的位置为![]() ,其中Nt是检测峰值的数量。
,其中Nt是检测峰值的数量。
注意,在上述峰值选择策略中,我们使用熵来确定网络预测的置信度。当置信度高时,我们使用top-1响应图中的峰值,当置信度低时,我们收集所有前top-5响应图中的峰值,以提高信息区域候选对象的召回。
对于通过使用上面步骤检测得到的每个峰值![]() ,我们从0到1的均匀分布中生成随机数量
,我们从0到1的均匀分布中生成随机数量![]() 。然后根据它们的响应值,将峰值分成两个集合,Td和Tc。
。然后根据它们的响应值,将峰值分成两个集合,Td和Tc。
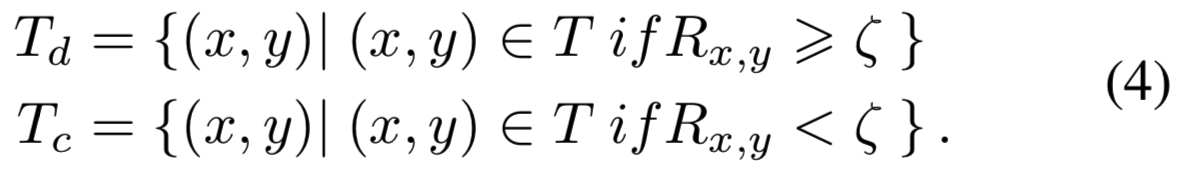
定位判别证据(例如,细粒度类别的独特模式)的高响应值峰值更有可能被划分为Td,而定位互补证据(例如,支持模式)的低响应值峰值更有可能被划分为Tc。
最后,我们使用高斯核去计算稀疏注意力![]() (Nt是检测峰值的数量),计算如下:
(Nt是检测峰值的数量),计算如下:
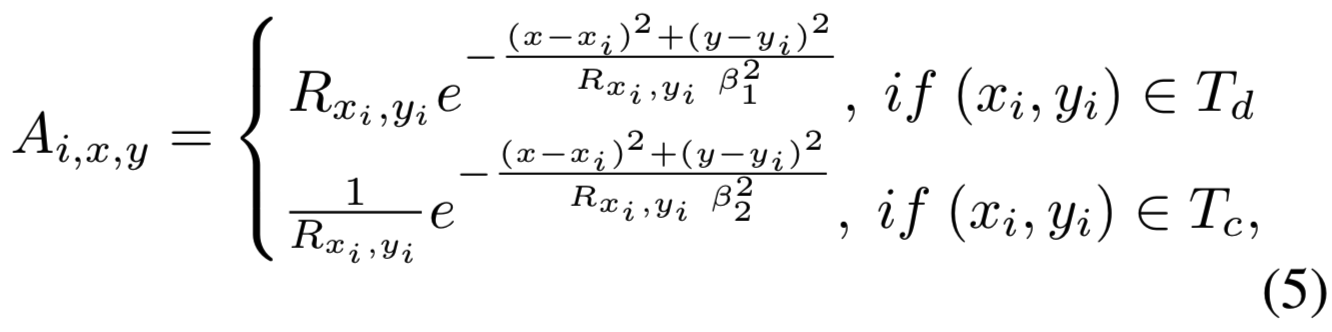
(Ai,x,y计算的是稀疏注意力map中,位置(x,y)相对于峰值(xi,yi)的结果)
其中β1和β2是可学习的参数,![]() 是T中第i个peak的峰值。注意,相应视觉证据(第3.3节)的每个稀疏注意控制采样尺度的振幅和半径,受对应的峰值响应值动态影响;这样输入的图像内容就有条件了。
是T中第i个peak的峰值。注意,相应视觉证据(第3.3节)的每个稀疏注意控制采样尺度的振幅和半径,受对应的峰值响应值动态影响;这样输入的图像内容就有条件了。
3.3. Selective Sampling
利用等式5定义的稀疏注意力,我们进行图像重采样,在保留周围上下文信息的同时,从信息丰富的局部区域突出细粒度的细节。针对特征提取的判别分支和互补分支,构造了两个样本映射Qd和Qc:
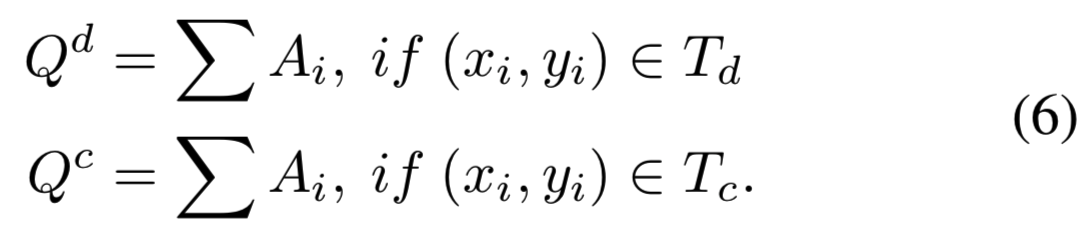
(就是将两个组的峰值对应的注意力加在一起,Qd大小为1xHxW,Qc大小为1xHxW)
表示一个输入X为一个有着顶点V的mesh grid,其中![]() 。顶点可以连接成水平和垂直的网格线。
。顶点可以连接成水平和垂直的网格线。
采样步骤旨在探索一个新mesh几何![]() ,其中对重要性较高的区域进行均匀scaling,对重要性较低的区域进行较大程度的抑制。这个问题可以转化为找到重新采样图像和输入图像之间的映射关系。这样的映射可以被写成两个函数,f(v)和g(v),所以
,其中对重要性较高的区域进行均匀scaling,对重要性较低的区域进行较大程度的抑制。这个问题可以转化为找到重新采样图像和输入图像之间的映射关系。这样的映射可以被写成两个函数,f(v)和g(v),所以![]() ,其中Xnew表示重采样图像。
,其中Xnew表示重采样图像。
f和g的设计目标是使用采样map,成比例地映射像素到赋值给它们的归一化权重。该问题的准确近似是f和g可以满足条件:![]() 。遵循[21]中的方法,解决办法如下所示:
。遵循[21]中的方法,解决办法如下所示:
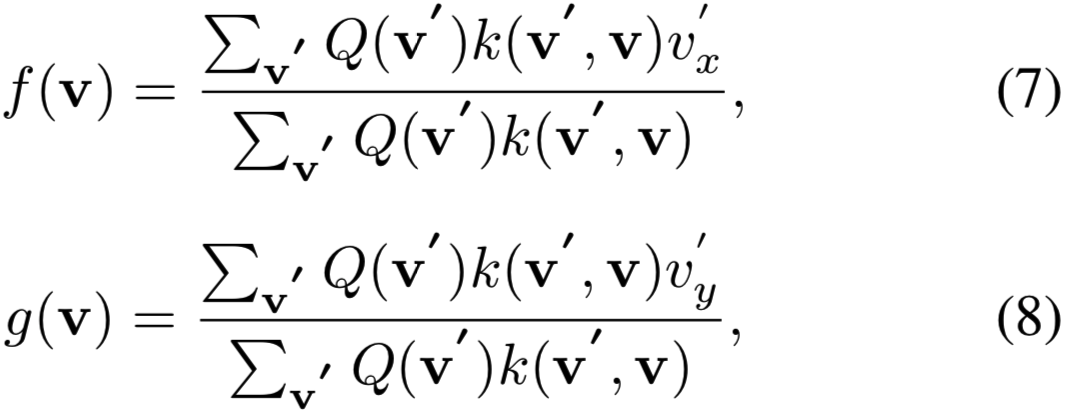
(其实就相当于将原图中注意力相关的part图像放大,其他不相关的地方缩小,使用的是论文-Learning to zoom: A saliency- based sampling layer for neural networks中的方法,可见细粒度相关 - Learning to Zoom: a Saliency-Based Sampling Layer for Neural Networks - 1 - 论文学习)
其中![]() 是做为regularizer的一个高斯距离核,且用于避免所有像素收敛于相同值的特殊情况。将等式7和等式8中的Q替换为等式6中计算的Qd和Qc,我们可以得到两个重新采样的图像。与Qd相对应的判别分支图像(discriminative branch image)突出了用于提取详细证据的重要区域。另一个是Qc对应的互补分支图像(complementary branch image),将对挖掘更多视觉线索不太重要的区域进行放大。如图4所示,所提出的选择采样可以防止强大的特征控制梯度学习,并鼓励网络学习更多样化的图像表示。重新采样过程通过卷积实现,并嵌入到端到端训练中,其中β1和β2可以通过重新采样图像的分类损失进行更新。
是做为regularizer的一个高斯距离核,且用于避免所有像素收敛于相同值的特殊情况。将等式7和等式8中的Q替换为等式6中计算的Qd和Qc,我们可以得到两个重新采样的图像。与Qd相对应的判别分支图像(discriminative branch image)突出了用于提取详细证据的重要区域。另一个是Qc对应的互补分支图像(complementary branch image),将对挖掘更多视觉线索不太重要的区域进行放大。如图4所示,所提出的选择采样可以防止强大的特征控制梯度学习,并鼓励网络学习更多样化的图像表示。重新采样过程通过卷积实现,并嵌入到端到端训练中,其中β1和β2可以通过重新采样图像的分类损失进行更新。

3.4. Fine-grained Feature Learning
在上述定义的稀疏注意和选择性采样过程下,特征学习过程以端到端的方式实现。在此过程中,首先将图像X输入到S3N,并生成两个重新采样的图像,大小与输入图像相同。它们放大了对应于判别和互补特征的动态数量的信息区域,。然后,S3N将重新采样的两幅图像作为输入,用于提取细粒度特征。对所有输入的特征提取重用相同的主干;因此,我们所提出的方法没有引入重要的模型参数。
得益于集合图像的全局和局部信息特征,我们定义了每幅图像的特征表示为:![]() 分别表示从原始图像、判别分支图像和互补分支图像抽取的特征。这些特征串联后输入一个带有softmax函数的全连接融合层,做最后的分类。在学习中,整个模型使用如下的分类损失优化:
分别表示从原始图像、判别分支图像和互补分支图像抽取的特征。这些特征串联后输入一个带有softmax函数的全连接融合层,做最后的分类。在学习中,整个模型使用如下的分类损失优化:
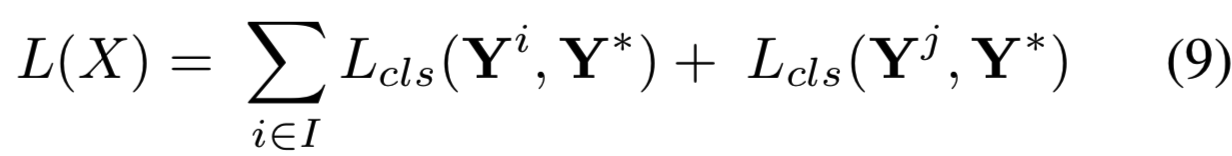
其中Lcls表示交叉熵损失。![]() 。Yi是基于特征
。Yi是基于特征![]() 的,来自原图和重采样图像的预测标签向量。Yj是使用关联特征
的,来自原图和重采样图像的预测标签向量。Yj是使用关联特征![]() 的预测标签向量,Y*是ground-truth标签向量。
的预测标签向量,Y*是ground-truth标签向量。
3.5. Discussion
所提出的S3N利用图像分类网络学习的类峰值响应来估计任务的信息区域,即细粒度图像识别,指导选择性采样程序来突出详细的视觉证据而不丢失周围的上下文信息。然后,将重新采样的图像输入共享网络骨干网更新学习到的类峰值响应。通过多次峰值预测和图像重采样,S3N实现了一种特殊的迭代学习。
S3N将稀疏注意机制与图像内容重采样结合在一个集成框架中,提供了一种融合局部和全局特征的新方法。第一步,使用全局图像特征来激活类峰值响应。第二步,激活峰值用来强化图像内容和全局特征。因此,局部特征和全局特征是相辅相成的。
4. Experiments
输入图像大小为448x448,使用resnet-50。使用SGD优化器,batch size为16,训练60 epochs。设置权重衰减为1e-4,momentum为0.9。对于已经使用预训练模型初始化的参数,学习率设置为0.001,其他学习率设置为0.01
其他省略...
5. Conclusions
在本文中,我们提出了选择性稀疏采样方法(Selective Sparse Sampling),这是一个简单而有效的框架,旨在解决细粒度图像识别的挑战。该框架是通过卷积神经网络实现的,称为选择性稀疏采样网络(Selective Sparse Sampling Networks,S3Ns)。通过图像级监督,S3Ns估计稀疏注意力并实现空间和语义采样。通过这种方式,它有选择性地从一个动态数量的信息区域中聚集精细细节的视觉证据,这些区域取决于图像内容和周围的环境。S3Ns不断地改进基线,并在多个流行的细粒度识别基准上产生优于最先进水平的性能。潜在的现实是,选择性稀疏采样与人类视觉系统的机制是一致的,这为图像识别领域提供了新的见解。

