
人脸年龄估计 - Adaptive Variance Based Label Distribution Learning For Facial Age Estimation - 1 - 论文学习
Adaptive Variance Based Label Distribution Learning For Facial Age Estimation
Abstract
从单个人脸图像中估计年龄是计算机视觉中一个经典且具有挑战性的课题。其最棘手的问题之一是标签模糊,即同一个人的相邻年龄的人脸图像往往无法区分。现有的一些方法采用分布学习,利用年龄标签之间的语义关联来解决这一问题。实际上,他们大多对所有图像的高斯标签分布的方差设置一个固定的值。然而,方差与相邻年龄之间的相关性密切相关,并且应该因年龄和身份的不同而不同。为了建立特定样本方差模型,本文提出了一种基于自适应方差分布学习(AVDL)的人脸年龄估计方法。AVDL引入了数据驱动的优化框架元学习(meta-learning)来实现这一点。具体来说,AVDL对变量(即方差)执行meta梯度下降步骤,以最小化clean无偏验证集上的损失。通过自适应学习每个样本的适当方差,我们的方法可以更有效地近似真实的年龄概率分布。在FG-NET和MORPH II数据集上的大量实验表明,我们提出的方法优于现有的最先进的方法。
1 Introduction
年龄估计是一个具有挑战性和热点的研究课题,它是根据一个人的面部图像来预测他/她的年龄。它有很多潜在的应用,包括人口统计收集、商业用户管理、视频安全监控等。然而,影响估计结果的内部或外部因素很多,包括种族、光照、图像质量等。此外,同一人的相邻年龄的面部图像,尤其是成人的面部图像,通常看起来相似,导致标签模糊。
近年来,人们提出了几种深度学习方法来提高人脸年龄估计的性能。最常用的方法是将人脸年龄预测模型作为分类或回归问题。基于分类的方法将每个年龄视为一个独立的类,忽略了类之间的相邻关系。考虑到年龄的连续性,回归方法根据提取的特征对年龄进行预测。然而,正如前人的研究[31,33]所提出的,回归方法面临过拟合问题,这是由于人类衰老过程的随机性和面部外观与实际年龄之间的模糊映射造成的。此外,提出了一些基于ranking的方法,以实现更准确的年龄估计。这些方法利用个体的序数信息,并使用多个二值分类器来确定输入图像的最终年龄。此外,Geng等[13,8]提出了标签分布学习(LDL)方法,该方法假设真实年龄可以用离散分布来表示。正如他们的实验所表明的那样,使用Kullback-Leibler (K-L)散度来衡量预测的和ground truth分布之间的相似性,可以帮助改进年龄估计。
对于标签分布学习方法,分布的均值是ground truth年龄。然而,对于人脸图像来说,分布的方差通常是未知的。以前的方法通常将方差作为一个超参数,并简单地为所有图像设置一个固定值。我们认为这些方法是次优的,因为方差与相邻年龄之间的相关性很高,并且在不同的年龄和不同的人之间应该有所不同,如图1所示。假设所有的图像共享相同的方差可能会降低模型的性能。
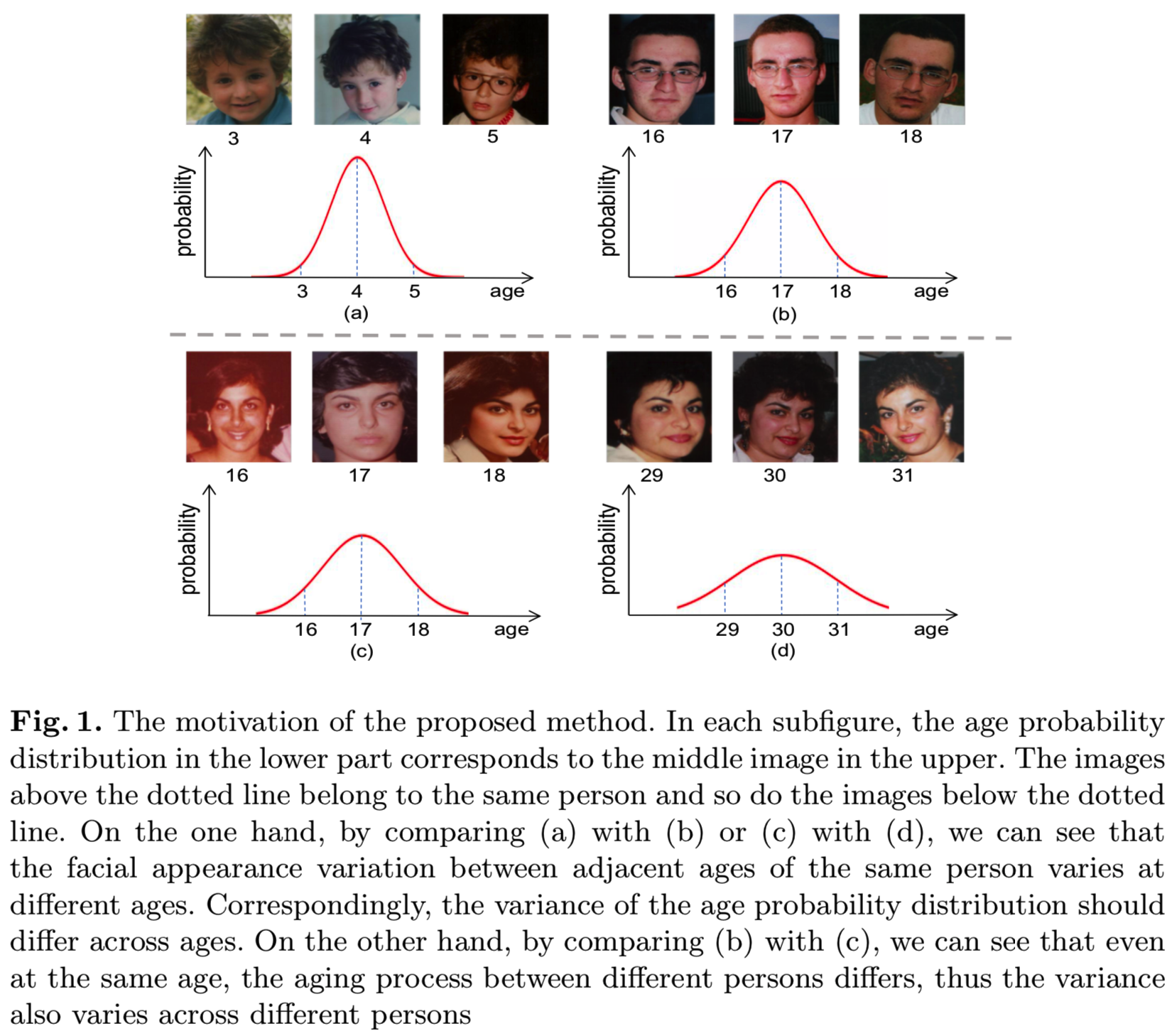
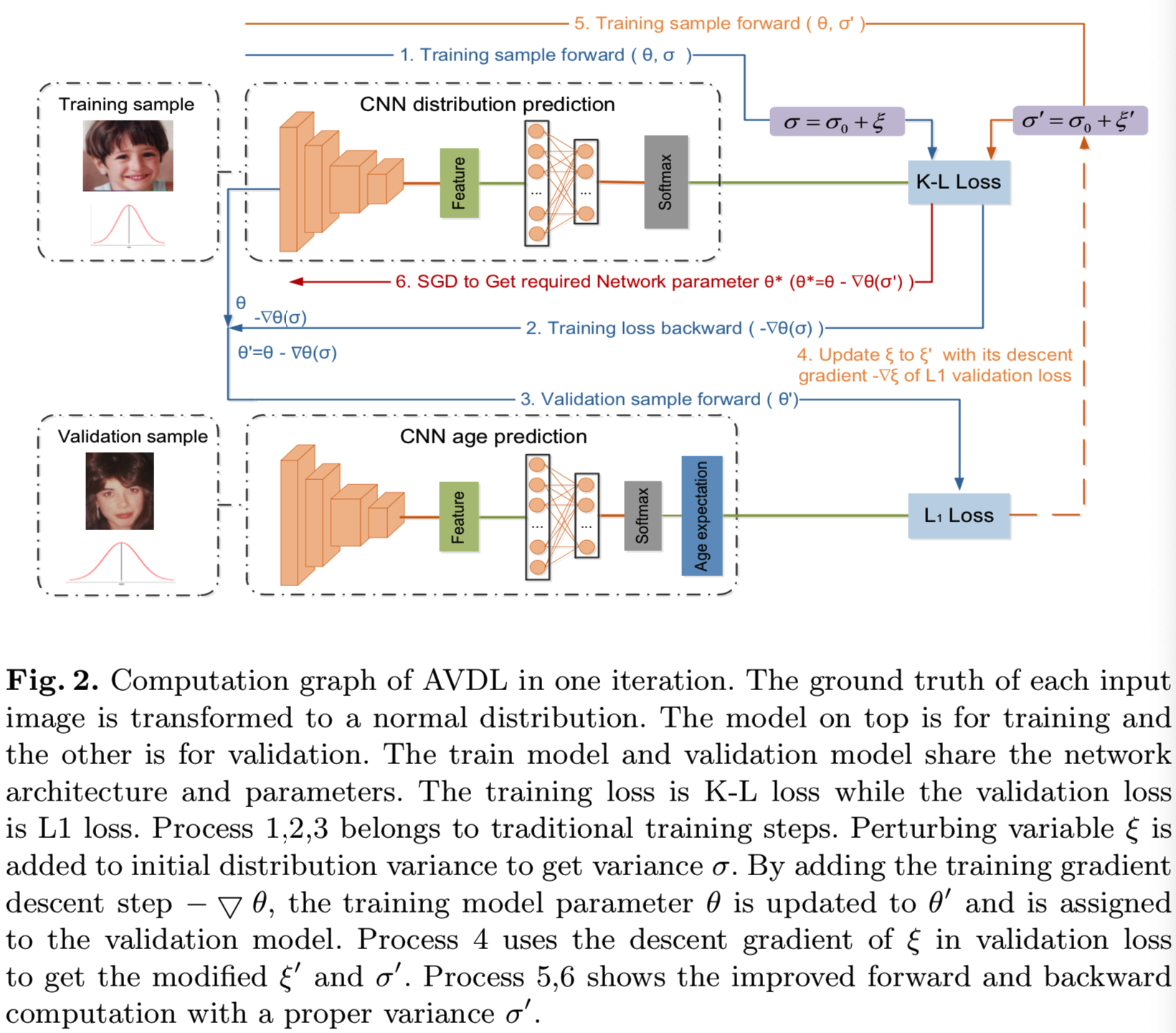
为了解决上述问题,本文提出了一种新的基于自适应方差的分布学习方法(AVDL),用于年龄估计。具体来说,我们引入元学习,利用验证集作为元目标,适用于在线超参数自适应工作[28],以构建特定方差,从而更好地近似真实年龄概率分布。如图2所示,我们首先选择一个小的验证集。对于每次迭代,在方差中加入一个干扰变量,我们使用K-L损失作为训练损失来更新训练模型参数。然后我们将更新后的参数与验证模型共享,并在验证集上使用预测的期望年龄和ground truth计算L1损失作为元目标。利用该元向导,通过梯度下降更新干扰变量,并自适应地寻找适当的方差,使模型在验证集上表现得更好。本工作的主要贡献可以总结为:
提出了一种新的基于自适应方差分布学习(AVDL)的人脸年龄估计方法。AVDL可以有效地模拟相邻年龄之间的相关性,更好地近似年龄标签分布。
现有的深度模型假设不同年龄和身份之间的方差是相同的,与之不同的是,我们引入了一种数据驱动的方法,元学习,来学习特定样本的方差。据我们所知,我们是第一个使用元学习方法来适应不同样本的不同方差的深度模型。
在FG-NET和MORPH II数据集上的大量实验表明,我们提出的方法优于现有的最先进的方法。
- 提出了一种新的基于自适应方差分布学习(AVDL)的人脸年龄估计方法。AVDL可以有效地模拟相邻年龄之间的相关性,更好地近似年龄标签分布。
- 现有的深度模型假设不同年龄和身份之间的方差是相同的,与之不同的是,我们引入了一种数据驱动的方法,元学习,来学习特定样本的方差。据我们所知,我们是第一个使用元学习方法来适应不同样本的不同方差的深度模型。
- 在FG-NET和MORPH II数据集上的大量实验表明,我们提出的方法优于现有的最先进的方法。
2 Related Work
2.1 Facial Age Estimation
近年来,随着卷积神经网络(CNN)在计算机视觉任务中的快速发展,如人脸landmarks检测[23]、人脸识别[38,3]、行人属性[35]、语义分割[46,45],深度学习方法的年龄估计性能也得到了提高。本文简要回顾了人脸年龄估计领域中一些具有代表性的研究成果。Dex等人[30]将人脸年龄估计作为一个分类问题,用分类概率加权的年龄期望来预测年龄。Tan等人提出了一种年龄组分类方法,称为age group-n-encoding方法。然而,这些分类方法忽略了类或组之间的相邻关系。为了克服这一问题,Niu等人提出了一种考虑年龄顺序信息进行估计的多输出CNN学习算法。Shen等人[32]通过扩展可微分决策树来处理回归,提出了Deep Regression Forests。此外,Li等人[22]提出了由局部回归器和门控网络组成的BridgeNet,以有效地探索年龄标签之间的连续关系。Tan等人[34]提出了一种复杂的Deep Hybrid-Aligned Architecture (DHAA),它由全局、局部和全局-局部分支组成,并以互补的信息共同优化体系结构。此外,Xie等人提出了两种集成学习方法,均采用顺序回归模型进行年龄估计。
2.2 Distribution Learning
分布学习是为解决标签歧义[10]问题而提出的一种学习方法,已被应用于头部姿态估计[12,8]、年龄估计[41,20]等许多识别任务中。Geng等[13,11]提出了两种自适应标签分布学习(ALDL)算法,即IIS-ALDL和BFGS-ALDL,迭代学习估计函数参数和标签分布方差。虽然ALDL使用了自适应方差学习,但我们提出的方法在三个方面有所不同。首先,ALDL使用了传统的优化方法,如BFGS,而我们使用的是深度学习和CNN。其次,ALDL在当前的训练迭代中选择更好的样本来估计新的方差,而我们的方法使用元学习来获得自适应方差。第三点是ALDL仅通过估计训练样本来更新方差,这可能会导致过拟合。我们的自适应方差是由验证集监督的,更具通用性。利用标签分布学习的方法弥补了训练数据缺乏准确年龄的不足。Hou等人[20]提出了一种半监督自适应标签分布学习方法。它利用无标签数据来增强标签分布的适应性,以寻找适合每个年龄的方差。然而,老化趋势各不相同,相同年龄的人的差异也可能不同。Gao等[9]联合使用LDL和期望回归来缓解训练和测试之间的不一致性。此外,Pan等人[25]提出了一个用于稳健年龄估计的均值-方差损失。Li等人[21]提出了标签分布精炼方法,在不假设标签分布形式的情况下自适应估计年龄分布,几乎不考虑相邻年龄的相关性。而我们的方法采用了带有自适应元学习方差的高斯标记分布,更注重相邻的年龄和顺序信息。
2.3 Meta-learning
我们提出的AVDL是元学习的一个实例[36,1],即learning to learn。根据利用的元数据的类型,这一概念可以分为几类[37],包括从经验相似的任务中转移知识,在任务之间转移训练过的模型参数,建立元模型去学习数据特征和单纯从模型评价中学习。Model Agnostic Meta-Learning (MAML)[7]学会了模型参数初始化,以更好地执行目标任务。在元信息的指导下,MAML对元目标进行了一次梯度下降,更新了模型参数[16]。将验证损失作为元目标的思想应用于few-shot学习[27]。参照few-shot学习,Ren等[28]提出了一种由验证集指导的重加权方法(L2RW)。该方法试图解决训练集中数据不平衡和标签噪音的问题。L2RW的关键标准是使用一个小的无偏差的干净验证集作为学习样本权重的监督员。由于验证集的性能衡量的是超参数的质量,将其作为元目标不仅可以应用于样本重新加权,也可以应用于其他在线超参数适应任务。受此启发,我们提出AVDL去结合基于验证集的元学习和标签分布学习来自适应学习标签方差。
3 Methodology
在本节中,我们首先介绍了年龄估计中的标签分布学习(LDL)方法。然后介绍了基于元学习框架的自适应方差分布学习方法。
3.1 The Label Distribution Learning Problem Revisit
X表示ground truth标签为y,![]() 的输入图像。模型被训练去预测一个尽可能和ground truth标签相近的值。对于传统的年龄估计方法,ground truth是个整数。在LDL方法中,为了解决标签的模糊性问题,Gao等[8]变换真实值y成一个正态分布p(y,σ)去表示一个新的ground truth。均值设置成ground truth标签y,σ是正态分布方差。这里我们使用的黑体小写字母如p(y,σ)去表示向量,使用pk(y,σ)(
的输入图像。模型被训练去预测一个尽可能和ground truth标签相近的值。对于传统的年龄估计方法,ground truth是个整数。在LDL方法中,为了解决标签的模糊性问题,Gao等[8]变换真实值y成一个正态分布p(y,σ)去表示一个新的ground truth。均值设置成ground truth标签y,σ是正态分布方差。这里我们使用的黑体小写字母如p(y,σ)去表示向量,使用pk(y,σ)(![]() )表示p(y,σ)的第k个元素:
)表示p(y,σ)的第k个元素:

其中pk表示真实年龄是k的概率。其表示从一个正态分布的视角,类k和y之间的关联。
在训练过程中,假设G(*,θ)是训练估计模型的分类函数,θ表示模型参数,![]() 变换输入X为分类向量
变换输入X为分类向量![]() 。一个softmax函数被用于转换
。一个softmax函数被用于转换![]() 为一个概率分布
为一个概率分布![]() ,第k个元素被表示为:
,第k个元素被表示为:
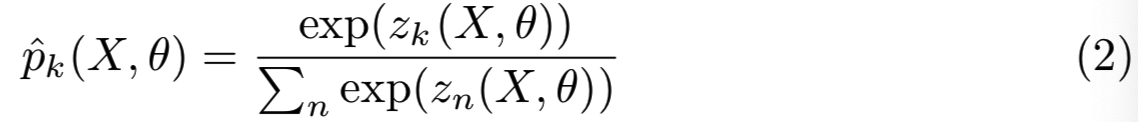
其中![]() 是
是![]() 的第k个元素
的第k个元素
LDL试图生成与ground truth分布尽可能相似的预测softmax概率分布。因此,我们使用Kullback-Leibler (K-L)散度来度量预测分布与ground truth分布[8]之间的差异:
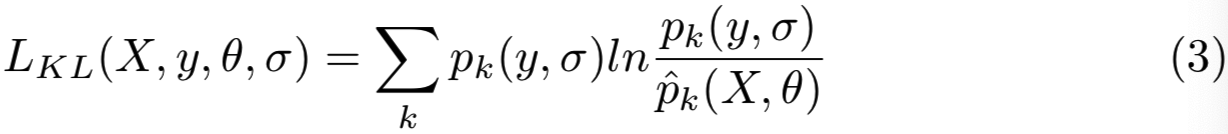
然后利用K-L损失,用SGD优化器更新模型参数。
LDL方法的目的是构建一个接近ground truth的正态分布,其关键是方差σ。对于大多数LDL方法,这个超参数被简单地设置为一个固定值,在大多数情况下是2.0。然而,事实上,不同的人,或者不同年龄的人的方差不可能是绝对相同的。因此,我们提出了一种为每个图像搜素恰当方差的方法。
3.2 Adaptive Distribution Learning Based on Meta-learning
在机器学习中,验证集的损失是调整超参数以实现泛化的指导方法之一。因此,使用干净的无偏差的验证集可以帮助训练更通用的模型。然而,传统的训练模式通常是手动调优超参数。受元学习工作[28]的启发,我们提出了由验证集指导的基于自适应方差的分布学习(AVDL)算法,为学习样本特定方差提供了一种有效的策略。
正如我们在3.1节中提到的,LDL最重要的超参数是方差σ。因为我们的目标是在训练时寻找每个图像的合适的σ,在本节中,我们使用σ来表示一个batch的训练数据的方差向量。每次迭代的最优σ取决于最优模型参数θ:
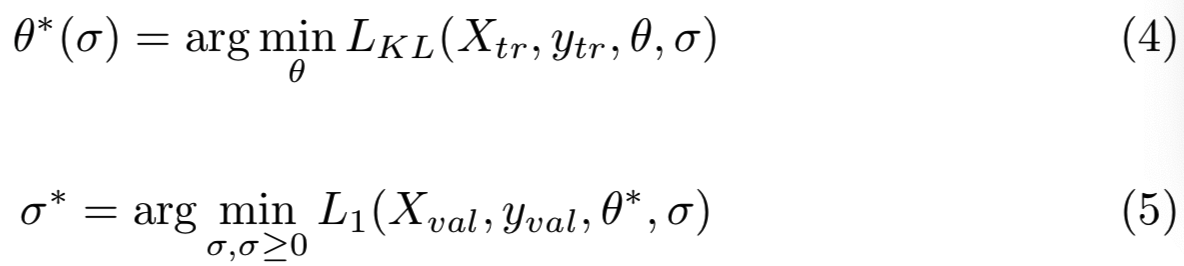
其中![]() 表示验证损失,
表示验证损失,![]() 表示训练输入图像,
表示训练输入图像,![]() 表示其对应的标签。同样地,
表示其对应的标签。同样地,![]() 表示验证输入图像,
表示验证输入图像,![]() 为其对应标签。为了解决优化问题,我们将训练过程分成几个步骤。图2显示了我们方法的计算图
为其对应标签。为了解决优化问题,我们将训练过程分成几个步骤。图2显示了我们方法的计算图
我们从训练集n的每个类中选择有着正确标签固定数量的图像去生成一个大小为m的小的无偏验证集,m << n。我们使用σi表示第i个图像的方差,同时设置所有图像方差的初始值为σi0。为了得到恰当的方差,我们为每个σi添加干扰项![]() :
:
![]()
其中![]() 表示干扰向量
表示干扰向量![]() 的第i个成分,初始化设置为0。可见,训练得到一个恰当的σ等价于训练一个恰当的
的第i个成分,初始化设置为0。可见,训练得到一个恰当的σ等价于训练一个恰当的![]() 。
。
首先,由图2的步骤1、2、3可见,第t个迭代,输入训练的batch使用干扰σ去计算如Section 3.1描述的K-L损失。使用SGD更新模型参数θt为![]() :
:
![]()
α表示下降步长
训练损失与分布有关。为了弥补最终预测年龄值缺乏约束的不足,我们在验证时采用L1损失来度量预测的期望年龄与验证ground truth值[9]之间的距离:
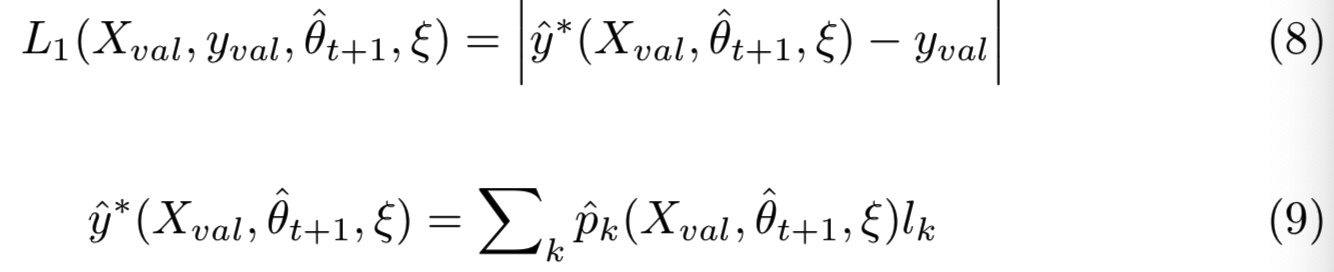
其中![]() 表示验证输入
表示验证输入![]() 预测向量的第k个元素,
预测向量的第k个元素,![]() 表示第k个类的年龄值,即
表示第k个类的年龄值,即![]() 。在section 4中期望年龄计算方法也用于估计测试图像
。在section 4中期望年龄计算方法也用于估计测试图像

超参数越好,验证性能就越好。在此,我们用梯度下降步骤更新了扰动ξ:
![]()
其中β表示下降步数。该操作和图2中的步骤4相关。由于σ的非负限制,我们要归一化ξ到[-1,1],使用映射![]() 。然后根据等式6更新参数σ。在训练的第3步,使用修改后的方差,计算训练图像的K-L损失,然后使用SGD优化器更新模型参数,如图2的步骤5、6所示
。然后根据等式6更新参数σ。在训练的第3步,使用修改后的方差,计算训练图像的K-L损失,然后使用SGD优化器更新模型参数,如图2的步骤5、6所示
我们在算法1中一步步罗列了我们的伪代码,这里对变量ξ进行了两次导数计算,PyTorch的autograd机制能够自动实现该操作
4 Experiments
图像大小为224x224,并进行了数据增强。在测试中,输入原图和反转版本两张图,其结果的平均值作为预测的最终结果。使用Resnet-18做为基础网络,使用SGD优化器,batch size设置为32。权重衰减和momentum设置为0.0005和0.9。初始学习率设置为0.01,每20个epochs衰减0.1倍。每张图的方差的初始值设置为1,使用Pytorch在GTX TITAN X GPUs训练网络
详情省略
5 Conclusions
本文提出了一种新的年龄估计方法——基于自适应方差的分布学习(AVDL)。AVDL引入元学习,在单次迭代中自适应地调整每幅图像的方差。在多个年龄估计数据集上,该算法的性能优于其他算法。我们的实验也表明,AVDL可以引导方差接近真实的面部衰老规律。使用元学习来指导关键超参数的想法是鼓舞人心的,我们将探索更多的可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号