
特征可视化技术(CAM) - 3 - Smooth Grad-CAM++ - 论文学习
https://github.com/frgfm/torch-cam
Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models
abstract
了解深度卷积神经网络模型是如何执行图像分类的,以及如何解释它们的输出,一直是计算机视觉研究人员和决策者关心的问题。由于对深度模型内部工作的理解不深,这些深层模型通常被称为黑盒子。为了开发可解释的深度学习模型,人们提出了几种方法,如寻找相对于输入图像的类输出的梯度(灵敏度maps)、类激活映射(class activation map,CAM)和基于梯度的类激活映射(Grad-CAM)。当定位到同一类物体多次出现时,这些方法将被执行,但并不适用于所有的CNN。此外,在使用单目标图像时,Grad-CAM不能完整地捕获整个目标,这影响识别任务的性能。为了在视觉清晰度、对象定位和解释单一图像中多次出现的对象三方面创建一个更强的视觉解释,我们提出了Smooth Grad-CAM++ ,这是一种结合了来自另外两种最新技术——SMOOTHGRAD和Grad-CAM++方法的技术。我们的平滑的Smooth Grad-CAM++ 技术提供了在推理级别(模型预测过程)的每个实例上可视化 层、特征图子集或特征图中的神经元子集的能力。经过对少量图像的实验,与其他方法相比,Smooth Grad-CAM++ 生成了视觉上更清晰的maps,在给定的输入图像中具有更好的对象定位结果。
1 Introduction
如今,许多深度学习模型在诸如目标检测、语音识别、机器翻译等任务中表现良好。据[2]介绍,在图像分类[3]、目标检测[6]、语义分割[7]、图像字幕[4]、视觉问答[5]等计算机视觉任务上取得了明显的突破。尽管这些复杂模型的性能得到了改善,但传统智能模型的有效性仍存在局限性,因为它们缺乏向人类用户解释其决策的能力。在安全、健康和自主导航[1]等风险规避领域,这是一个不容忽视的问题。
更多可解释的模型可以揭示数据中重要但令人惊讶的模式,但其被复杂的模型忽略了[8]。这一点在[9]的肺炎风险预测病例研究中得到了证实。人工智能代理比人类弱,而且还不完全可靠。因此,透明性和可解释性是神经网络模型识别故障模式[10]的关键。缩小到图像分类,很少有技术被提出来理解图像分类模型的决定。一种常用的方法通常被称为显著性(saliency,灵敏度或像素属性),即通过模型找到对最终分类特别有影响的图像像素区域或像素子集[11,12,13]。这种方法,包括在定位同类多次出现时执行的常规类激活映射(CAM)方法。此外,基于梯度的CAM (Grad-CAM)不能完整地捕获整个目标,这影响识别任务的性能。尽管Grad-CAM++技术倾向于处理这些限制,但是在类对象捕获、定位和视觉吸引方面还需要改进。此外,当前可视化技术的实现没有考虑到特征图中单个或神经元子集的可视化,仅停留在特征图层次上。
在本文中,我们将梯度平滑引入到Grad-CAM++中,由此产生的技术使得卷积层、特征图子集和神经元子集在特征图中可视化,提高了视觉吸引、定位和类对象捕获能力。平滑需要对感兴趣的样本图像添加噪声,并对每幅噪声图像生成的所有梯度矩阵取平均值。Grad-CAM++根据CNN最终卷积特征图中的特定空间位置的输出的梯度按像素进行加权。这为feature map中每个像素对于CNN整体决策的重要性提供了一个度量。
2 Background
在本节中,我们将讨论之前为理解CNN输出所做的努力。理解深度CNN的最早努力之一是被称为Deconvnet的反卷积方法。在这种方法中,数据从较高层的神经元激活流向较低层,然后在处理[14]过程中突出显示对该神经元有高度影响的图像部分。这导致了guided backpropagation 的想法。[15]引入了一种新的反卷积方法,称为引导反向传播(guided backpropagation),用于将CNN学习到的特征可视化,与现有方法相比,它可以应用于更广泛的网络结构。[16]提供了一个可视化工具箱来合成输入图像,使神经网络中的特定单元具有高激活,这有助于可视化单元的功能。工具箱可以显示来自webcam或图像文件的输入图像的激活,并直观地了解每个过滤器在每一层做了什么。[17]提出了特定类saliency maps,它是通过在像素空间中进行梯度上升达到最大值而生成的。这被证明是一种更有指导意义的用来合成输入图像方法,最大限度地激活一个神经元,并有助于更好地解释给定的CNN是如何建模一个类[1]的。其他有趣的方法被提出,如Local Interpretable Model-Agnostic Explanations(LIME) [18], DeepLift [19], 和Contextual Explanation Networks (CENs) [20].。
最近的可视化技术有类激活映射(CAM)、梯度加权类激活映射(Grad-CAM)和称为Grad-CAM++的Grad-CAM的泛化。在CAM中,[11]给出了一个具有全局平均池化(GAP)层的CNN,说明了即使是经过图像级标签的训练,也具有显著的定位能力。CAM适用于不包含全连接层的改进图像分类CNN。Grad-CAM是任何基于CNN架构的CAM的一般化方法。CAM局限于狭窄的一类CNN模型,但Grad-CAM广泛适用于任何基于CNN的架构,不需要再训练。
计算类分数(Yc)关于最后一个卷积层特征map的梯度:

梯度流后跟着全局平均池化去获得权重wck:
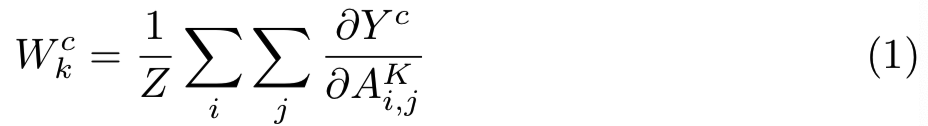
其中wck捕获了一个目标类c的特征map K的重要性
Grad-CAM的热图是特征maps的权重结合,后面跟着relu函数:
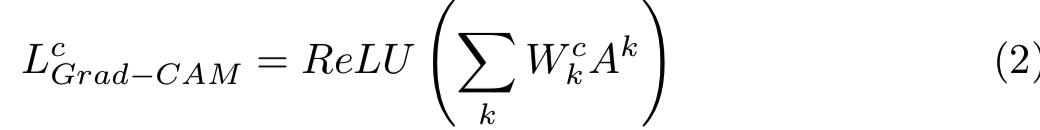
在Grad-CAM++,[1]提出了使用最后一个卷积层的特征maps关于一个特定类分数的正偏导数的权重结合结果作为权重去生成某个类标签的视觉解释。作者使用的公式为:
wck用来获取特定激活map Ak的重要性:
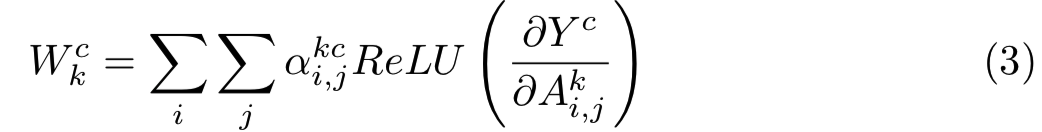
其中![]() 用来捕获关于目标类c的激活map Ak位置(i,j)上的重要性
用来捕获关于目标类c的激活map Ak位置(i,j)上的重要性
使用上面的wck替换基础CAM(这里没有显示)假设中的wck,得到:
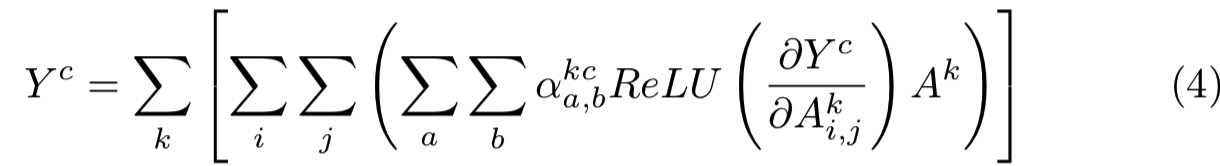
上面式子左右两边求关于Aki,j的偏导数,然后得到每个激活map的每个位置上的重要性:
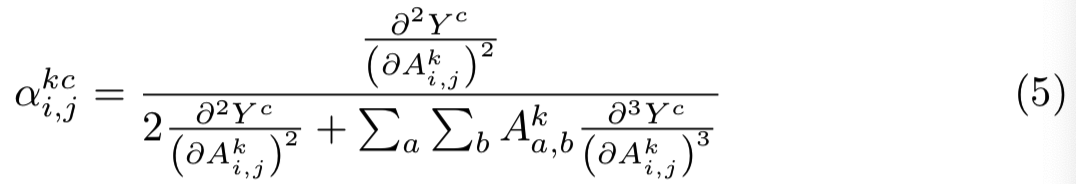
[8]引入了SMOOTHGRAD,这是一个通过使用输入x邻近的随机样本和对得到的敏感maps求均值去提高基于梯度的敏感maps的清晰度的简单方法。计算方法为:

其中n是样本的数量,![]() 表示标准差为 的高斯噪声。为了提供更强的可视化maps,我们将该光滑技术应用到Grad-CAM++如上所示的梯度计算中。最后的梯度被应用到Grad-CAM++算法中。其为深度CNNs提供了更好的maps(在视觉吸引、定位和捕捉方面)。
表示标准差为 的高斯噪声。为了提供更强的可视化maps,我们将该光滑技术应用到Grad-CAM++如上所示的梯度计算中。最后的梯度被应用到Grad-CAM++算法中。其为深度CNNs提供了更好的maps(在视觉吸引、定位和捕捉方面)。
3 Method
在这一节我们讨论平滑过程(输入噪声)和梯度平均。我们还将讨论如何使用API来生成结果,以及其他用户随后如何使用它。这包括模型、卷积层、feature map和神经元选择。
3.1 Noise Over Input
通过在原始输入中加入高斯噪声,我们将产生的噪声样本图像数目设为n。设置输入平均值的标准差,从而提供要添加的噪声程度。我们提供了与算法交互的API。所提供的API使用0作为默认情况下生成的噪声样本图像的数目。这意味着使用的原始输入的梯度没有噪声。默认的标准差值设置为0.15。这些值可以不断变化,直到产生一个满意的可视map。
3.2 Gradients Averaging
我们取所有n个噪声输入的所有一阶、二阶和三阶偏导数的平均值,并将所得的平均导数应用于计算![]() 和
和
wck。
设Dk1、Dk2、Dk3分别表示feature map k的一阶、二阶、三阶偏导数矩阵,计算出map k的坐标![]() 为:
为:
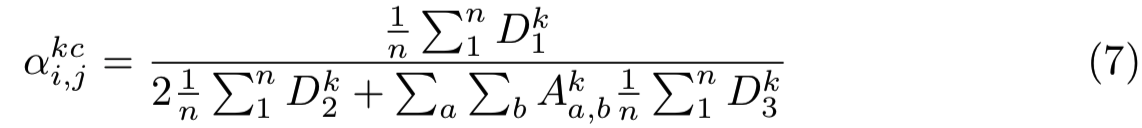
(感觉这式子不对,分子应该是二阶的????)
用于替换等式3中的平均梯度,Grad-CAM++权重wck变为:

将该wck代入等式2中,就能够得到最后的类判别显著矩阵,其可以用matplotlib或任何其他图像绘图库绘制。这将作为最后的显著map;该修改后的Grad-CAM++被称为Smooth Grad-CAM++

3.3 Choosing a Model
任何可学习的深度CNN模型都可以选择用于可视化。在该论文中,我们使用VGG-16预训练模型,然后探索其最后一个卷积层
3.4 Choosing Layer
在每个实例中,只有一个卷积层可以被可视化。要可视化的层的名称被传递给API。名称默认有一个特定的约定,然而,查看训练模型的摘要将揭示每个卷积层的名称或唯一标识符。每一层包含K个特征图,通常维数约为

其中H为输入高度,W为输入宽度,P为添加的零padding,Fh为核高度,Fw为核宽度,Sw和Sh分别为卷积的水平和垂直步长。如果没有提供padding,那么尺度大约为:

ceil()表示向上取整
3.5 Choosing Feature Maps
要指定要可视化的feature map,必须设置filter参数,filter参数是一个整数列表,指定在指定的卷积层中要可视化的feature map的索引。如果为filter参数设置n值,则对应每个feature map生成n个map。例如,如果filter值为:0,1,2,3,则表示各方程中k的取值界线为[0,3]。
回想一下,feature map的数量对应于内核的数量。
3.6 Choosing Neurons
这项工作的主要贡献之一是我们的技术能够在特征图中可视化神经元的子集。当对单个神经元的激活感兴趣时,可视化神经元是有用的。例如,[21]使用子集扫描算法来识别卷积神经网络中的异常激活。平滑的Grad-CAM++将有助于在神经元水平上提供解释。当region参数设置为true时,我们的API提供了一个选项来可视化指定坐标边界内的神经元区域。当region参数设置为false并提供一个坐标子集时,只有这些坐标中的神经元被可视化,而其他激活被裁剪为零。平滑的Grad-CAM++可能是一个非常灵活的工具,用于调试CNN模型。
3.7 API Call
必要的参数在API调用期间被传递,如下所示:

如果将region参数设为true,则将子集中的两个坐标作为神经元的边界值进行可视化处理(即这个为一块区域)。因此,集合范围内的所有神经元都被可视化。如果region为false,则会可视化子集列表中指定的每个坐标(这个为几个点)。
4 Results
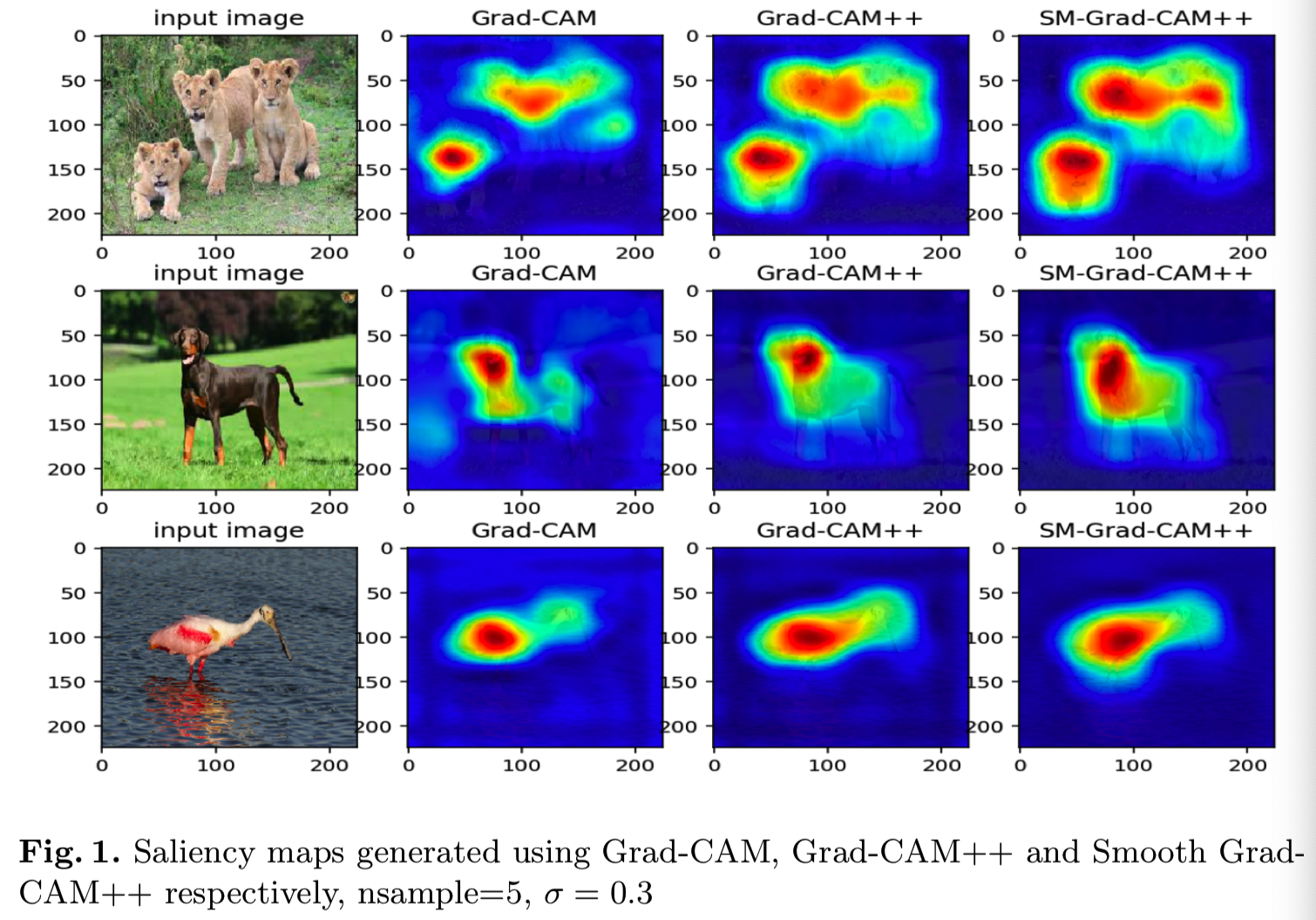
从图1中可以看出,Smooth Grad-CAM++对所学模型的特殊特性给出了更清晰的解释。例如,在图1中,Smooth Grad-CAM能够突出水鸟腿的较大部分。而且,Smooth Grad-CAM++捕获了更多的类对象(如图1中的dog图像所示),并进行了很好的定位。图2为随机选取的3张feature map的可视化图,分别是feature map 10、32和3。每个feature map学习特殊的特征,有些可能是空白的,如图2所示。图4和图5,并显示了标签中标注的特定特征图在神经元水平上的显著map。这项技术是深入了解CNN模型实际学习内容的一个步骤。


5 Conclusion
一个增强的视觉显著map可以帮助我们在推理阶段加深对深度卷积神经网络模型内部工作的理解。在本文中,我们提出了Smooth Grad-CAM++,一个增强的用于深度卷积神经网络的视觉map方法。我们的结果揭示了与现有方法相比,生成的可视化maps的改进。这些maps是通过对给定图像的许多小扰动进行梯度平均(即类分数关于输入的导数),并将产生的梯度应用到通用的Grad-CAM算法(Grad-CAM++)中生成的。Smooth Grad-CAM++在对象定位和同类对象的多次出现方面都有很好的表现。它能够创建特定层、特定特征maps和特定感兴趣神经元的maps。这将为机器学习研究者提供关于机器学习模型的解释性的更好的理解。未来的工作需要进一步的研究来扩展这个技术来处理多个类的场景,以及将其使用在除了CNNs之外的不同的网络架构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号