
attention - 4 - Non-local Neural Networks - 1 - 论文学习
https://arxiv.org/abs/1711.07971
https://github.com/AlexHex7/Non-local_pytorch
Non-local Neural Networks
Abstract
卷积操作和循环操作都是一次处理一个局部邻域的building块。在本文中,我们将non-local操作作为捕获long-range依赖关系的一般building块 family提出。受计算机视觉中经典的non-local means方法[4]的启发,我们的non-local操作将某一位置的响应计算为所有位置特征的加权和。这个模块可以插入到许多计算机视觉架构中。在视频分类的任务上,即使没有任何花哨的东西,我们的non-local模型也可以在Kinetics和Charades数据集上竞争或超过当前的竞赛获胜者。在静态图像识别中,我们的non-local模型改进了目标检测/分割和姿态估计的COCO suite任务。代码可见https://github.com/facebookresearch/video-nonlocal-net.
1. Introduction
捕获long-range依赖关系是深度神经网络的核心重要性。对于序列数据(如语音、语言),循环操作[38,23]是long-range依赖建模的主要解决方案。对于图像数据,远距离依赖是由卷积操作的深度叠加形成的大接受域来建模的[14,30]。
卷积操作和循环操作都处理一个局部邻域,无论是在空间上还是在时间上;因此,只有在重复应用这些操作、通过数据逐步传播信号时,才能捕获long-range依赖关系。重复局部操作有几个限制。首先,它的计算效率很低。其次,它导致优化困难,需要仔细解决[23,21]。最后,这些挑战使得multi-hop依赖建模变得困难,例如,当消息需要在遥远的位置之间来回传递时。
在本文中,我们将non-local操作作为一种有效、简单、通用的组件,用于捕获深度神经网络的long-range依赖关系。我们提出的non-local运算是对计算机视觉中经典的non-local mean运算[4]的推广。直观地说,non-local操作将某一位置的响应计算为输入特征图中所有位置特征的加权和(图1)。位置集可以是空间、时间或时空,这意味着我们的操作适用于图像、序列和视频问题。
使用non-local操作有几个优点:(a)与循环操作和卷积操作的渐进行为不同,non-local操作通过计算任意两个位置之间的交互,直接捕获long-range依赖关系,而不考虑它们的位置距离;(b)正如我们在实验中所展示的,non-local操作是有效的,即使只有几个层(例如,5),也能获得最佳结果;(c)最后,我们的non-local操作保持了可变的输入大小,并且可以很容易地与其他操作(例如,我们将使用的卷积)结合在一起。
我们展示了non-local操作在视频分类应用中的有效性。在视频中,long-range的相互作用发生在空间和时间中遥远的像素之间。一个单一的non-local块,即我们的基本单元,可以直接以前馈方式捕获这些时空相关性。通过少量的non-local块,我们称为non-local neural networks的架构在视频分类方面比2D和3D卷积网络[48](including the inflated variant[7])更精确。此外,non-local神经网络比3D卷积神经网络在计算上更经济。Kinetics[27]和Charades[44]数据集提供了全面的消融研究。我们只使用RGB,没有任何花哨的东西(例如光流、multi-scale测试),我们的方法在两个数据集上都取得了与最近的竞赛获胜者旗鼓相当或更好的结果。
为了证明non-local操作的普遍性,我们进一步在COCO数据集[33]上进行了目标检测/分割和姿态估计实验。在strong Mask R-CNN基线[19]的基础上,我们的non-local块可以以很小的额外计算成本提高所有三个任务的准确性。与视频上的证据一起,这些图像实验表明,non-local操作通常是有用的,可以成为设计深度神经网络的基本组成部分。
2. Related Work
Non-local image processing. [4]是一种经典的滤波算法,它计算图像中所有像素的加权平均值。它允许在一个基于patch外观相似度的位置上,远距离的像素对过滤后的响应做出贡献。这种non-local过滤思想后来发展成为BM3D(块匹配3D)[10],它对一组相似但non-local的patches执行过滤。与深度神经网络[5]相比,BM3D是坚实的图像去噪基线。块匹配与神经网络一起用于图像去噪[6,31]。non-local匹配也是[12]纹理合成、超分辨率[16]和[1]inpainting算法成功的关键。
Graphical models. long-range依赖可以通过图形模型来建模,如条件随机场(CRF)[29,28]。在深度神经网络中,CRF可用于[9]网络的语义分割预测的后处理。将CRF的迭代平均场推理转化为递归网络并进行训练[56,42,8,18,34]。相比之下,我们的方法是一个更简单的计算non-local滤波的前馈块。与这些用于分割的方法不同,我们的通用组件用于分类和检测。这些方法和我们的方法也与一个更抽象的模型有关,称为图神经网络[41]。
Feedforward modeling for sequences. 最近出现了一种使用前馈(即非循环)网络来建模语音和语言序列的趋势[36,54,15]。在这些方法中,long-term依赖关系被非常深的1-D卷积所贡献的大接受域所捕获。这些前馈模型适合并行实现,并且比广泛使用的循环模型更有效。
Self-attention. 我们的工作与最近的机器翻译的自注意力[49]方法有关。自注意力模块计算序列中某个位置(如句子)的响应,方法是关注所有位置并在嵌入空间中取其加权平均值。在接下来,我们将讨论self-attention可以被视为一种non-local mean[4]的形式,在这个意义上讲我们的工作将机器翻译的self-attention连接到non-local过滤操作的更一般的类,适用于计算机视觉图像和视频问题。
Interaction networks. Interaction Networks (IN) [2,52]最近被提出用于建模物理系统。它们对涉及成对交互的对象的图形进行操作。Hoshen[24]在multi-agent预测建模的背景下提出了更有效的 Vertex Attention IN (VAIN) 。另一种变体,名为Relation Networks[40],在其输入的所有位置对上对特征嵌入计算一个函数。我们的方法也处理所有对,后面将会解释(Eq.(1)中的 f(xi, xj)) 。当我们的non-local网络连接到这些方法时,我们的实验表明,模型的非局部性,这是正交于attention/interaction/relation的思想(例如,一个网络可以关注一个局部区域),是他们的经验成功的关键。non-local建模,一个长期以来图像处理的关键元素(如[12,4]),在最近的计算机视觉神经网络中被很大程度上忽视了。
Video classification architectures. 视频分类的一个自然解决方案是将用于图像的CNNs和用于序列的RNNs的成功结合起来[55,11]。而前馈模型是在时空中通过3D 卷积(C3D)[26,48]实现的,3D filters可以通过“inflating”[13,7]预训练的2D filters来形成。除了对原始视频输入进行端到端建模之外,已经发现光流(optical flow)[45]和轨迹(trajectories)[50,51]也有帮助。流和轨迹都是现成的模块,可以找到long-range、non-local的依赖关系。在[7]中可以找到对视频架构的系统比较。
3. Non-local Neural Networks
我们首先给出了non-local操作的一般定义,然后提供了它的几个具体实例。
3.1. Formulation
根据non-local mean运算[4],我们将深度神经网络中的一般non-local运算定义为:
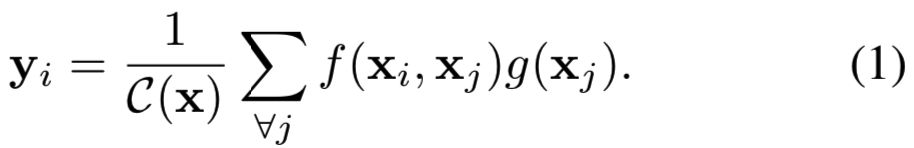
这里i是被计算的响应(response)的输出位置(在空间、时间或时空中)的索引,j是枚举所有可能位置的索引。x为输入信号(图像、序列、视频;通常是他们的特征)和y是与x大小相同的输出信号。一个pairwise函数 f 计算一个i和j之间的标量(代表两者的相关关系)。一元函数g计算位置j输入信号的表示。响应最后经因子![]() 归一化。
归一化。
等式(1)具有non-local的行为是由于所有位置(∀j) 都被考虑在了操作中。作为比较,卷积操作对一个局部邻域的加权输入求和(e.g.,i−1≤j≤ i+1 in a 1D case with kernel size 3),而第i时刻的递归操作往往仅基于当前和最新的时间steps(如j =i or i−1)。
non-local操作也不同于全连接(fc)层。等式(1)根据不同位置之间的关系计算响应,而fc使用可学习的权重。换句话说,与non-local层不同,fc中xj和xi之间的关系不是输入数据的函数。此外,我们的等式(1)支持可变尺寸的输入,并在输出中保持相应的尺寸。相反,fc层需要一个固定大小的输入/输出,并丢失位置相关性(例如,在位置i 从xi到yi的相关性)。
non-local操作是一个灵活的构建块,可以很容易地与卷积/循环层一起使用。它可以添加到深度神经网络的前期部分,而不像fc层通常在最后使用。这允许我们构建更丰富的层次结构,将non-local信息和local信息结合在一起。
3.2. Instantiations
接下来,我们将描述f和g函数的几个版本。有趣的是,我们将通过实验(表2a)表明,我们的non-local模型对这些选择不敏感,这表明一般的non-local行为是观察到的改进的主要原因。
为简单起见,我们只考虑g的线性嵌入形式:g(xj) = Wgxj,其中Wg为可学习的权值矩阵。该实现类似空间上的1×1卷积或时空上的1×1×1卷积。
接下来我们讨论pairwise函数 f 的选择。
Gaussian. 遵循non-local mean[4]和双侧滤波器(bilateral filter)[47],f的一个自然选择为高斯函数。在本文中,我们考虑:
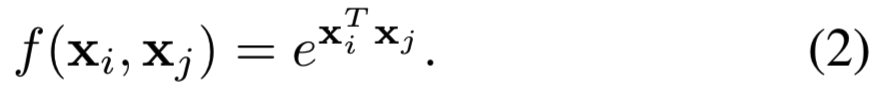
其中![]() 是点积相似度。如[4,47]中使用的欧式距离也是可以使用的,但是点积在当前的深度学习平台中实现更友好。归一化因子设置为
是点积相似度。如[4,47]中使用的欧式距离也是可以使用的,但是点积在当前的深度学习平台中实现更友好。归一化因子设置为![]()
Embedded Gaussian. 高斯函数的一个简单扩展是计算嵌入空间中的相似度。在本文中,我们考虑:
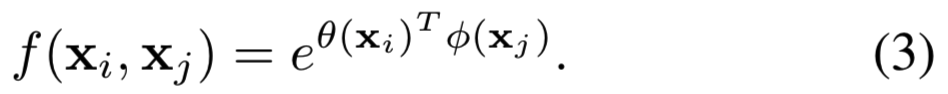
其中![]() 是两个嵌入。和上面相同,设置
是两个嵌入。和上面相同,设置![]()
我们注意到[49]最近提出的用于机器翻译的自注意力模块是嵌入式高斯版本中non-local操作的一个特例。 这可以从以下的事实看出,即当给定i时,![]() 变成了沿着维度j的softmax函数。所以我们有
变成了沿着维度j的softmax函数。所以我们有![]() 这是[49]中的注意力形式。因此,我们的工作提供了新的见解,通过将最近的自我注意模型与经典的计算机视觉non-local means方法[4]相关联,并将[49]中的顺序自注意力网络扩展到计算机视觉中用于图像/视频识别的一般空间/时空non-local网络。
这是[49]中的注意力形式。因此,我们的工作提供了新的见解,通过将最近的自我注意模型与经典的计算机视觉non-local means方法[4]相关联,并将[49]中的顺序自注意力网络扩展到计算机视觉中用于图像/视频识别的一般空间/时空non-local网络。
尽管与[49]有关系,但我们表明,注意力行为(由于softmax)在我们研究的应用中并不是必不可少的。为了说明这一点,我们接下来描述non-local操作的两个替代版本。
Dot product. f可以定义为一个点积相似度:
![]()
这里我们采用嵌入式版本。在这种情况下,我们将归一化因子设为![]() = N,其中N是x中的位置数,而不是f的和,因为它简化了梯度的计算。这样的归一化是必要的,因为输入的大小是可变的。
= N,其中N是x中的位置数,而不是f的和,因为它简化了梯度的计算。这样的归一化是必要的,因为输入的大小是可变的。
这里的点积方法(没有)和上面嵌入式Gaussian版本的方法(有)的主要区别是softmax的存在,它起着激活功能的作用。
Concatenation. 在Relation Networks[40]中,pairwise函数使用concatenation进行可视化推理。我们也评估了f的concatenation形式:
![]()
其中[.,.]表示concatenation, wf是一个权重向量,用于将concatenation向量投射为标量。和上面一样,设置![]() = N。在这里,我们对f使用ReLU[35]
= N。在这里,我们对f使用ReLU[35]
上面的几个变体演示了我们通用的non-local操作的灵活性。我们相信替代版本是可用的,可能会改善结果。
3.3. Non-local Block
我们将等式(1)中的non-local操作封装到一个non-local块中,这样该块就可以合并到许多现有架构中。我们定义一个non-local块为:
![]()
式中,yi在等式(1)中给出,“+xi”表示残差连接[21]。残差连接允许我们插入一个新的non-local块到任何预训练好的模型中,而不破坏它的初始行为(例如,如果Wz被初始化为零)。图2展示了一个non-local块的示例。等式(2)、(3)、(4)的pairwise运算可以通过矩阵乘法简单地完成,如图2所示;(5)中的concatena版本很简单。
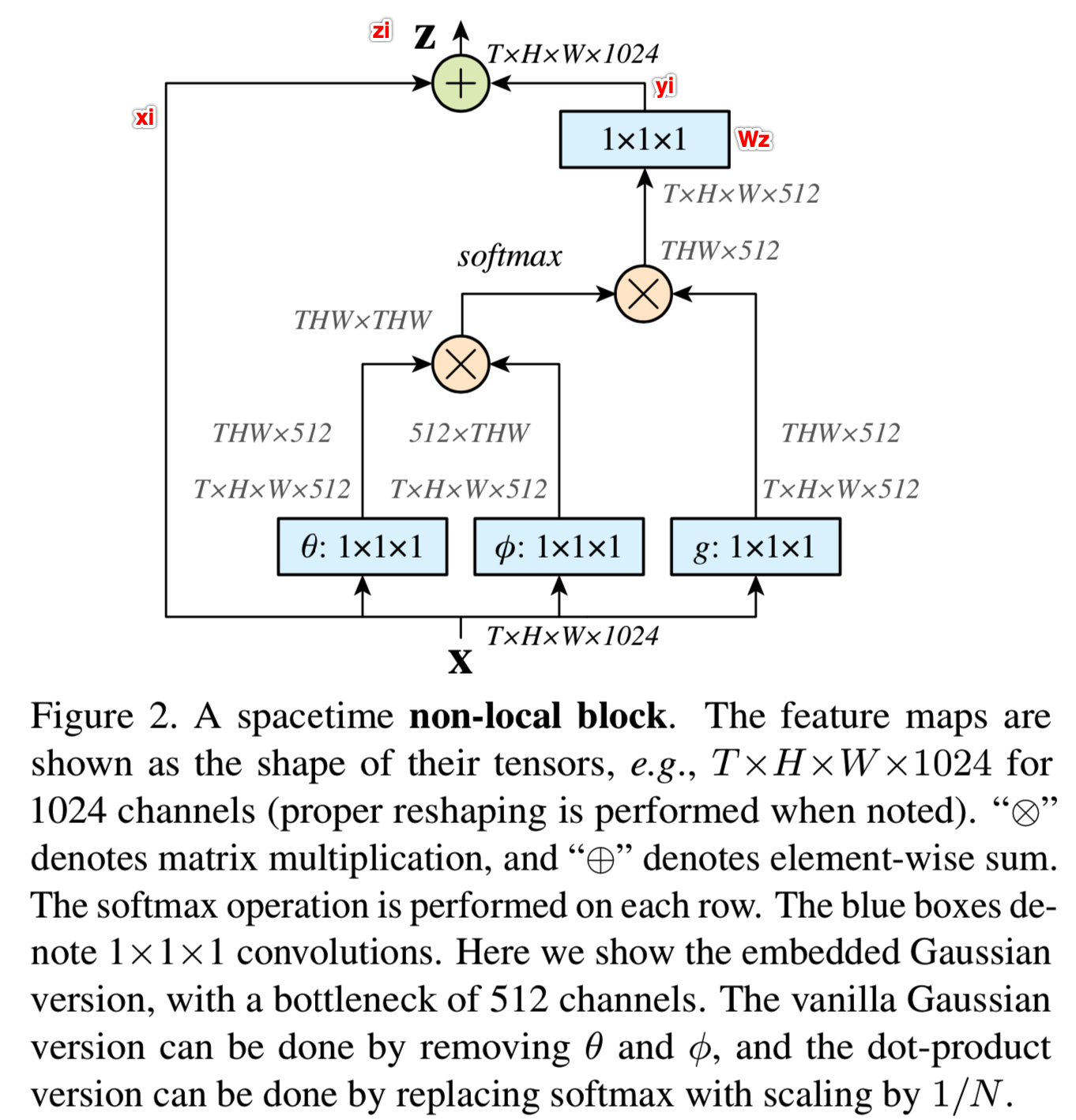
在high-level, sub-sampled特征maps中,non-local块的pairwise计算量较小。例如,图2中的典型值是T = 4, H = W = 14或7。由矩阵乘法所做的pairwise运算与标准网络中的典型卷积层相当。我们进一步采用以下实现来提高效率。
Implementation of Non-local Blocks. 我们将由Wg、WΘ和WΦ表示的通道数量设置为输入x的通道数量的一半。这遵循了[21]的bottleneck设计,将block的计算量减少了大约一半。等式(6)中的权值矩阵Wz计算yi的position-wise嵌入,将通道数与x的通道数匹配,见图2。
subsampling手段可以用于进一步减少计算量。我们修改等式(1)为![]()
![]() ,其中
,其中![]() 是x的一个再抽样版本(如使用pooling)。我们在空间域实现它,这可以减少1/4的pairwise计算量。该手段并没有更改non-local的行为,仅仅是让计算变得更稀疏了。这可以通过在图2的Φ和g函数后面增加一个max pooling层实现。
是x的一个再抽样版本(如使用pooling)。我们在空间域实现它,这可以减少1/4的pairwise计算量。该手段并没有更改non-local的行为,仅仅是让计算变得更稀疏了。这可以通过在图2的Φ和g函数后面增加一个max pooling层实现。
4. Video Classification Models
为了了解非局域网络的行为,我们对视频分类任务进行了全面的消融实验。首先,我们描述了这项任务的基本网络架构,然后将其扩展到3D ConvNets[48,7]和我们提出的non-local网络。
2D ConvNet baseline (C2D). 为了隔离我们的non-local网络 vs. 3D ConvNets的时间(temporal)效应,我们构建了一个简单的2D基线架构,其中时间维度是微不足道的(i.e., only by pooling)。
表1显示了在ResNet-50主干下的C2D基线模型。输入视频片段有32帧,每帧224×224像素。表1中的所有卷积本质上都是逐帧处理输入的2D核(实现为1×k×k核)。这个模型可以直接从ImageNet上预训练的ResNet权重初始化。一个ResNet-101对应的版本也是以同样的方式构建的。

涉及时态(temporal)域的唯一操作是池化层(pooling)。换句话说,这个基线只是简单地聚集了时间信息。
Inflated 3D ConvNet (I3D). 正如在[13,7]中所做的那样,通过“inflating”内核,可以将表1中的C2D模型转换为3D卷积模型。例如,一个2D k×k核可以膨胀为跨越t帧的3D t×k×k核。这个核可以从二维模型(ImageNet上预训练过的)进行初始化:t×k×k核中的每个t平面都用预训练过的k×k权值进行初始化,并乘以1/t重新调整。如果一个视频由一个重复的静态帧组成,这个初始化产生的结果与在静态帧上运行的2D预训练模型相同。
我们研究了两种inflat情况:将残差块中的3×3核inflat为3×3×3(类似于[7]),或将残差块中的first 1×1核inflat为3×1×1(类似于[13])。我们将他们表示为I3D3×3×3和I3D3×1×1。由于三维卷积是计算密集型的,我们只对每2个残差块inflat一个核;inflating更多的层次表明收益递减。我们将conv1 inflat为5×7×7。
[7]的作者已经证明I3D模型比CNN+LSTM模型效果更精确。
Non-localnetwork. 我们将non-loca块插入到C2D或I3D中,将其转化为non-local网络。我们研究增加1、5或10个non-block块;实现细节将在下一节中描述。
4.1. Implementation Details
Training. 我们的模型是在ImageNet[39]上预训练的。除非指定,我们使用32帧的输入clip来调整我们的模型。这些clip是由从原始的全长视频中随机裁剪出64个连续的帧,然后每隔一帧删除而成。遵循[46],空间大小为224×224像素,从较短边在[256,320]像素范围的缩放后的视频中随机裁剪得到。我们在一台8-GPU机器上训练,每个GPU的一个mini-batch中有8个clip(所以一个mini-batch总共有64个clip)。我们模型总共训练了400k次迭代,学习率从0.01开始,每150k次迭代将学习率降低10倍(参见图4)。我们使用0.9的momentum和0.0001的权重衰减。我们在全局池化层之后采用dropout [22], dropout ratio为0.5。我们在应用BatchNorm (BN)[25]时使用它来微调我们的模型。这与微调ResNets的常规做法[21]相反,这里的BN层是被冻结的(frozen)。我们发现在应用程序中启用BN可以减少过拟合。
我们采用[20]中的方法对non-local块引入的权重层进行初始化。我们在最后一个代表Wz的1×1×1层之后添加了一个BN层;我们不向non-local块中的其他层添加BN。遵循[17], 这个BN层的scale参数被初始化为0。这就保证了整个non-local块的初始状态是一个恒等映射,所以它可以插入到任何预训练过的网络中,同时保持它的初始行为。
Inference. 遵循[46],我们对短边被调整为256的视频进行空间全卷积推理。对于时域,在我们的实践中,我们均匀地从一个全长视频中抽取10个片段,并分别计算它们的softmax分数。最后的预测是所有片段的平均softmax分数。
5. Experiments on Video Classification
我们对具有挑战性的Kinetics数据集[27]进行了全面的研究。我们还报告了Charades数据集[44]上的结果,以显示我们模型的一般性。
5.1. Experiments on Kinetics
Kinetics[27]包含约246k的训练视频和20k的验证视频。它是一个分类任务,涉及400个人类行为类别。我们在训练集上训练所有的模型,在验证集上进行测试。
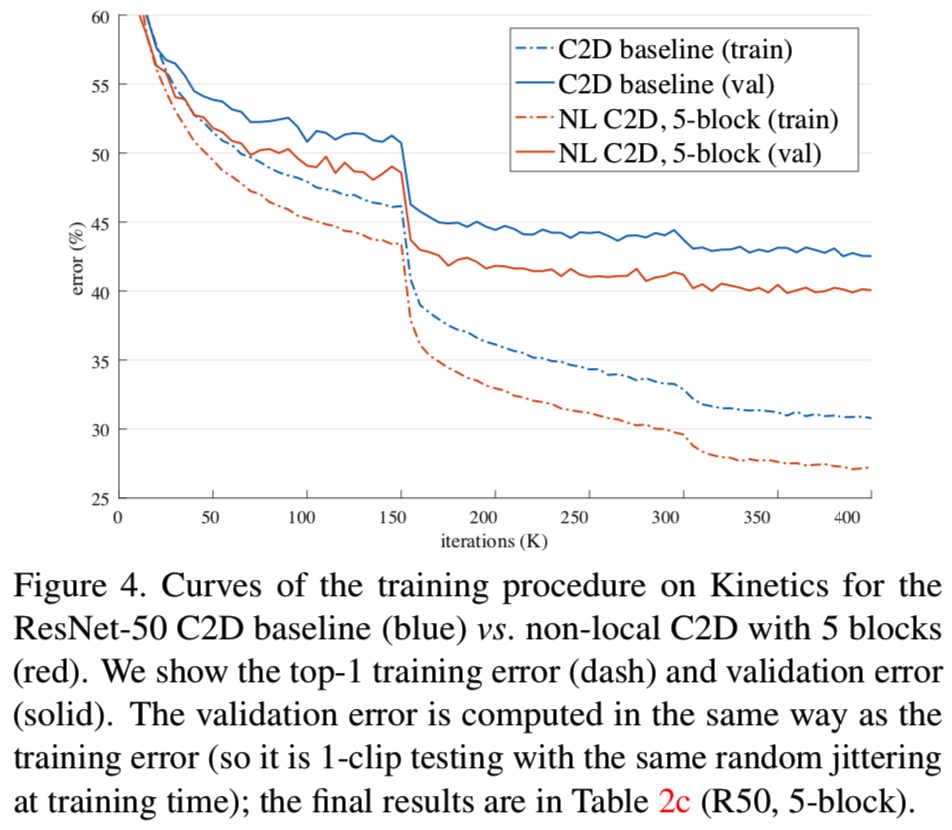
图4显示了ResNet-50 C2D基线与具有5个块的non-local C2D的训练过程曲线(更多细节见下文)。在整个训练过程中,我们的non-local C2D模型在训练和验证误差方面始终优于C2D基线。
图1和图3可视化了由我们的模型计算的non-local块的行为的几个例子。我们的网络可以学会寻找有意义的关系线索,而不管空间和时间的距离。


Instantiations. 表2a比较了添加到C2D基线中的单个non-local块的不同类型(就在res4的最后一个残差块之前)。即使是添加一个non-local块,也会导致相对于基线的约1%的改进。
有趣的是,嵌入的Gaussian, dot-product和concatenation版本的执行情况类似,只是有一些随机变化(72.7到72.9)。如3.2节所述,高斯核的non-local操作与自注意模块[49]类似。然而,我们的实验表明,这个模块的注意力(softmax)行为不是改进我们的应用程序的关键;相反,更可能的情况是,non-local行为很重要,而且它对实例化不敏感。
在本文的其余部分,我们使用默认的嵌入Gaussian版本。这个版本更容易可视化,因为它的softmax分数在[0,1]的范围内。
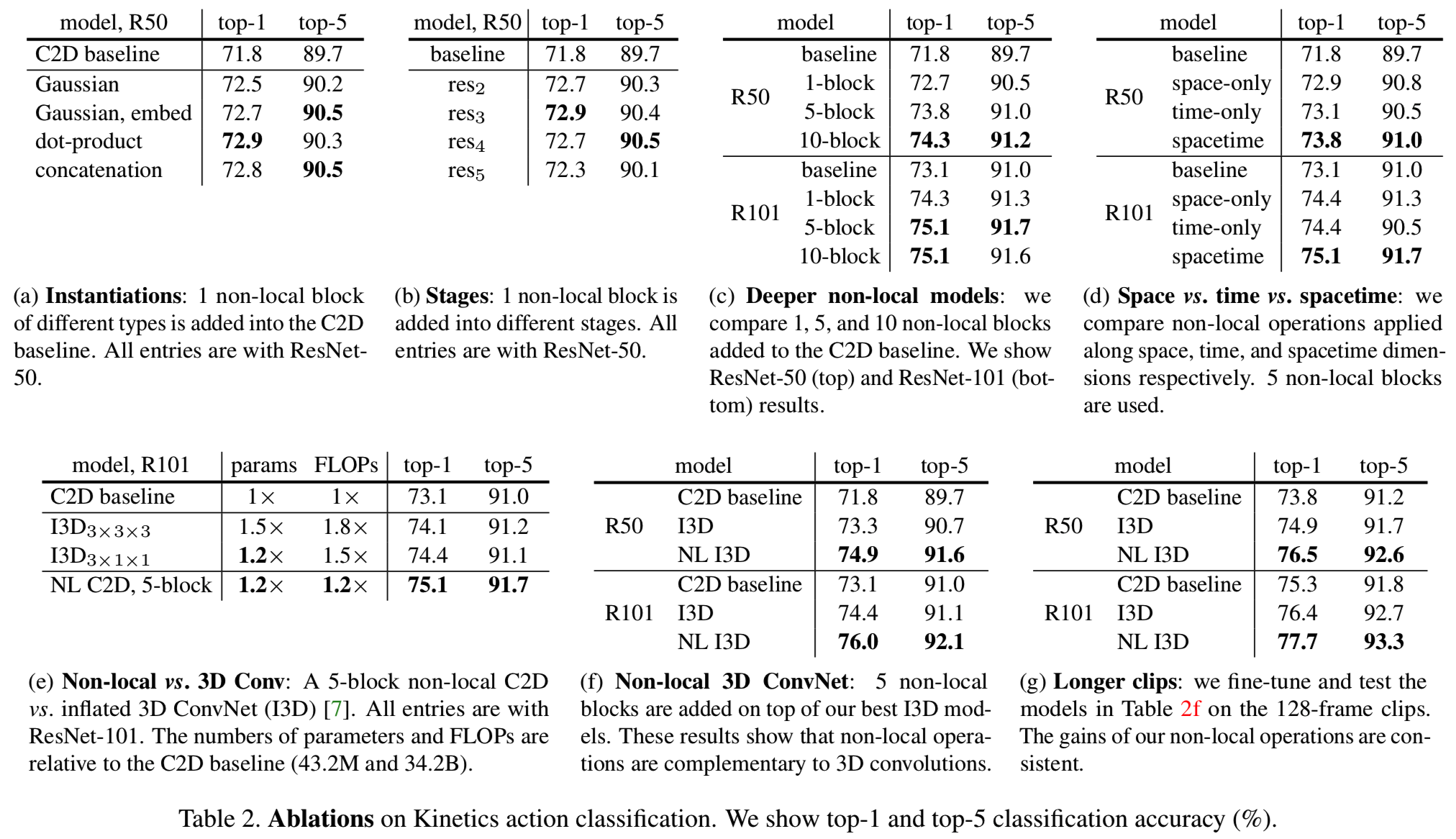
Which stage to add non-local blocks? 表2b比较了添加到ResNet不同阶段的单个non-local块。该块被添加到一个stage最后一个残差块的之前。在res2、res3或res4上对non-local块的改进是类似的,而在res5上则稍微小一些。一种可能的解释是res5空间尺寸较小(7×7),不足以提供精确的空间信息。更多non-local块利用空间信息的证据将在表2d中进行研究。
Going deeper with non-local blocks. 表2c显示了更多non-local块的结果。在ResNet-50中添加1个块(在res4中)、5个块(在res4中添加3个块,在res3中添加2个块,在其他所有残差块中添加)和添加10个块(在res3和res4中的所有残差块中添加);在ResNet-101中,我们将它们添加到相应的残差块中。表2c显示,一般来说,non-local块越多,结果越好。我们认为,多个non-local块可以实现远程多跳(long-range multi-hop)通信。信息可以在时空中遥远的位置之间来回传递,而这很难通过局部模型来实现。
值得注意的是,non-local块的改善不仅仅是因为它们增加了基线模型的深度。为了说明这一点,我们注意到表2c中non-local的5块ResNet-50模型有73.8的精度,高于更深层次的ResNet-101基线的73.1。但是,对比ResNet-101基线,5块的ResNet-50只有约70%的参数和约80%的FLOPs,而且也更浅。这一对比表明,non-local块的改进与规范的增加深度的方法是互补的。
我们还尝试在基线模型中添加标准残差块,而不是non-local块。准确性没有提高。这再次表明non-local块的改善不仅仅是因为它们增加了深度。
Non-local in spacetime. 我们的方法可以自然地处理时空信号。这是一个很好的特性:视频中的相关对象可以出现在遥远的空间和长期的时间间隔,它们的依赖性可以被我们的模型捕获。
在表2d中,我们研究了沿空间、时间或时空应用的non-local块的影响。例如,在只使用空间的版本中,non-local依赖只发生在同一个帧内:即在等式(1)中,它只对索引i的同一个帧内的索引j求和。表2d显示,只使用空间和只使用时间的版本都优于C2D基线,但逊于时空版本。
Non-localnetvs.3DConvNet. 表2e比较了我们的non-local C2D版本和inflated 3D ConvNets。non-local操作和三维卷积可以看作是将C2D扩展到时间维度的两种方法。
表2e还比较了与基线相比的参数和FLOPs数量。我们的non-local C2D模型比I3D模型更准确(例如,75.1 vs. 74.4),同时FLOPs数量也更少(1.2倍vs. 1.5倍)。这一比较表明,我们的方法比单独使用的三维卷积更有效。
Non-local 3D ConvNet. 尽管有上述比较,但non-local操作和3D卷积可以对问题的不同方面建模:3D卷积可以捕获局部依赖关系。表2f为I3D3×1×1模型中插入5个non-local块的结果。这些non-local I3D (NL I3D)模型改善了其对应的I3D模型(+1.6点精度),这表明non-local操作和3D卷积是互补的。
Longer sequences. 最后,我们研究了我们的模型在较长的输入视频上的通用性。我们使用由128个连续帧组成的输入clip,没有使用子采样(subsampling)。因此,网络中所有层的序列比32帧的序列长4倍。为了适合这个模型到内存中,我们将每个GPU的mini-batch大小减少到2。由于使用了小批量,我们在这种情况下冻结了所有BN层。我们使用以32帧输入训练的相应的模型来初始化这个模型。我们使用与32帧相同的迭代次数对128帧输入进行微调(尽管mini-batch的大小现在更小了),初始学习率为0.0025。其他实现细节与前面相同。
表2g显示了128帧clip的结果。与表2f中的32帧模型相比,所有模型在更长的输入上都有更好的结果。我们还发现,我们的NL I3D可以保持其相对I3D的增益,这表明我们的模型在较长的序列上工作得很好。
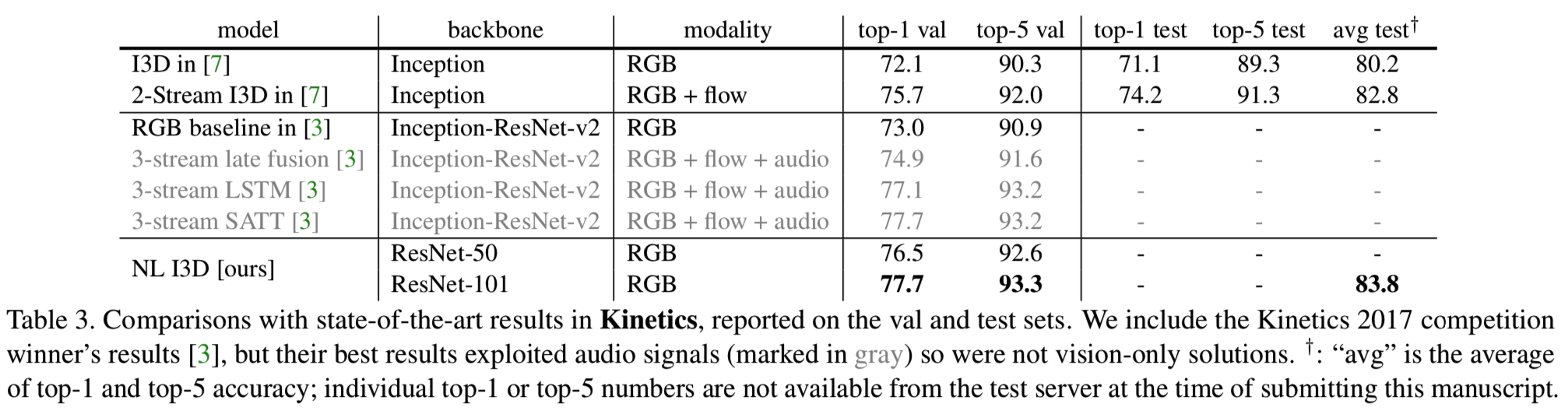
Comparisons with state-of-the-art results. 表3显示了I3D作者[7]和2017Kinetics竞赛冠军[3]的结果。我们注意到,这些是对系统的比较,系统可以在许多方面不同。然而,我们的方法在很大程度上超过了所有现有的RGB或RGB +流方法。我们的方法没有使用光流,也没有任何花哨的东西,与2017年大赛冠军的经过精心设计的结果是一样的。
5.2. Experiments on Charades
Charades[44]是一个视频数据集,具有约8k训练、约1.8k验证和约2k测试视频。它是一个具有157个动作类别的多标签分类任务。我们使用每个类别的sigmoid输出来处理多标签属性。
我们使用对Kinetics预训练的模型进行初始化(128帧)。mini-batch大小设置为每个GPU 1个clip。训练200k个迭代,从0.00125的学习率开始,并每75k迭代减少10倍。我们使用一种类似于Kinetics中的抖动策略来确定224×224裁剪窗口的位置,但是我们重新缩放视频,使这个裁剪窗口输出为288×288像素,并在此基础上微调我们的网络。我们在320像素的单一尺度上进行测试。
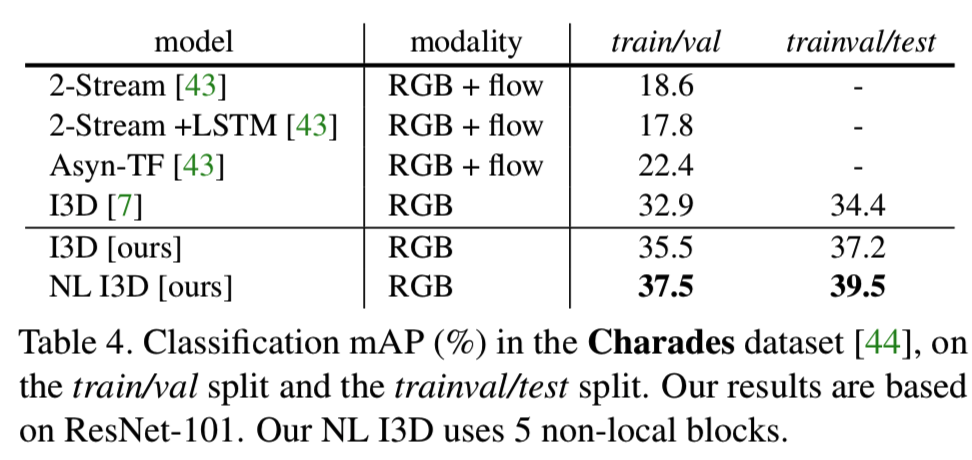
表4显示了与之前Charades结果的比较。[7]的结果是2017年Charades比赛的冠军,这也是根据Kinetics预先训练的模型进行微调的。我们的I3D基线高于之前的结果。作为对照比较,我们的non-local网络在测试集上比I3D基线提高了2.3%。
6. Extension: Experiments on COCO
我们也在静态图像识别中研究了我们的模型。我们在Mask R-CNN基线[19]上进行了COCO[33]目标检测/分割和人体姿态估计(关键点检测)的实验。模型在COCO train2017(即2014年的trainval35k)上进行训练,并在val2017(即2014年的minival)上进行测试。
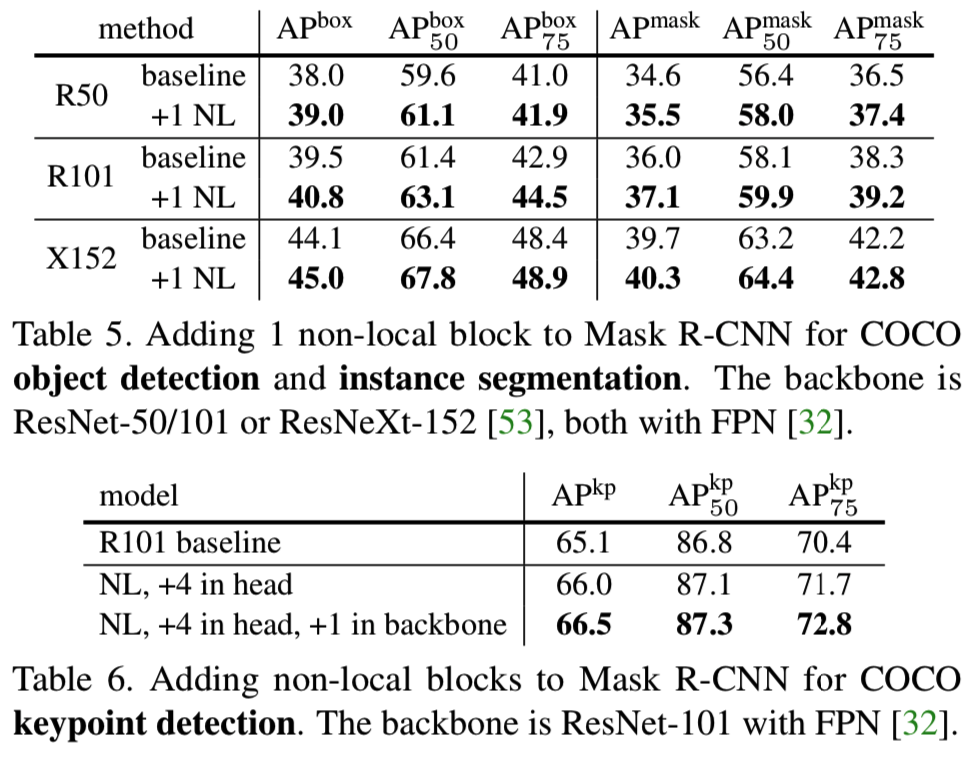
Object detection and instance segmentation. 我们通过添加一个non-local块(就在res4的最后一个残差块之前)来修改Mask R-CNN主干。所有的模型都从预训练ImageNet网络进行微调。我们评估了ResNet-50/101的标准基线和ResNeXt-152 (X152)[53]的high基线。与原始论文[19]采用的关于RPN的阶段式训练不同,我们使用了一种改进的实现,类似于[37]的端到端联合培训,这导致了比[19]更高的基线。
表5显示了COCO上的box和mask AP。我们看到,一个单一的non-local块改善了所有R50/101和X152基线,包括所有涉及检测和分割的指标。APbox在所有情况下都会增加约1个点(比如在R101中增加约1.3个点)。我们的non-local块是对增加模型容量操作的补充,即使模型从R50/101升级到X152。这一比较表明,尽管现有模型的深度/容量有所增加,但它们并没有充分地捕捉到non-local依赖性。
此外,上述增益的代价非常小。单个non-local块只给基线模型增加<5%的计算量。我们也曾尝试使用更多的non-local块作为骨干,但发现回报递减。
Keypoint detection. 接下来我们在Mask R-CNN中评估用于关键点检测的non-local块。在[19]中,Mask R-CNN像1-hot masks一样,使用8个卷积层的stack来预测关键点。这些层是局部操作,可能忽略了跨长距离关键点之间的依赖关系。基于此,我们在关键点头中插入4个non-local块(在每2个卷积层之后)。
表6显示了对COCO的结果。在R101这个strong基线上,将4个non-local块添加到关键点头导致约1个点的keypoint AP的增加。如果我们像目标检测一样,添加一个额外的non-local块到backbone,我们观察相对于基线到1.4个点的keypoint AP的增加。特别地是,我们看到AP75这个严格标准提高了2.4个点,这意味着更强的定位性能。
7. Conclusion
我们提出了一类新的神经网络,它通过non-local操作来捕获long-range依赖关系。我们的non-local块可以与任何现有的架构相结合。我们展示了non-local建模对于视频分类、目标检测和分割以及姿态估计等任务的重要性。在所有任务中,简单地添加non-local块就可以提供比基线更可靠的改进。我们希望non-local层将成为未来网络架构的重要组成部分。

