
attention - 1 - Residual Attention Network for Image Classification - 1 - 论文学习
https://arxiv.org/pdf/1704.06904.pdf
https://github.com/fwang91/residual-attention-network
https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch/tree/master/Residual-Attention-Network
Residual Attention Network for Image Classification
Abstract
在本论文中,我们提出了“Residual Attention Network”,这是一种使用注意力机制的卷积神经网络,它可以与先进的前向传播网络体系结构结合,以端到端的训练方式。我们的Residual Attention Network是通过叠加产生注意力感知特征的注意力模块来构建的。随着层次的加深,不同模块的注意力感知特征会自适应地发生变化。在每个注意模块内部,采用bottom-up top-dowm的前馈结构,将前馈和反馈的注意li过程展开为单个前馈过程。重要的是,我们提出注意力残差学习训练非常深的Residual Attention Network,使其可以很容易地扩展到数百层。
对CIFAR-10和CIFAR-100数据集进行了大量分析,验证了上述各模块的有效性。我们的Residual Attention Network在三个基准数据集上实现了最先进的目标识别性能,包括CIFAR-10(3.90%的误差)、CIFAR-100(20.45%的误差)和ImageNet(4.8% single model and single crop, top-5 error)。注意,与ResNet-200相比,我们的方法实现了0.6%的top-1精度提高,仅用46%的主干深度和69%的前向FLOPs。实验还证明了我们的网络对噪声标签具有良好的鲁棒性。
1. Introduction
注意力的混合性质在以前的文献中已经被广泛研究[34,16,23,40]。注意力不仅用于选择一个集中的位置,而且还增强了那个位置上物体的不同表征。以往的研究将注意力漂移作为一个连续的过程来捕捉不同的关注方面。然而,据我们所知,在图像分类任务中,还没有将注意力机制应用到前馈网络结构中,以达到最新的效果。图像分类的最新进展主要集中在使用“very deep”结构训练前馈卷积神经网络[27,33,10]。
受注意机制和深度神经网络最新进展的启发,我们提出了Residual Attention Network,一种采用混合注意力机制的深度卷积网络。Residual Attention Network由多个注意力模块组成,这些模块产生注意力感知特征。随着层次的加深,不同模块的注意力感知特征会自适应地发生变化。
除了注意力机制带来的更有鉴别性的特征表示外,我们的模型还展示了以下吸引人的特性:
(1)注意力模块的增加导致性能的持续提升,因为不同类型的注意力被广泛捕捉。图1显示了一个热气球图像的不同注意力类型的示例。天空注意力mask减少背景响应,而气球实mask突出气球的底部部分。
(2)能够在端到端的训练方式中与先进的深度网络结构相结合。具体地说,我们网络的深度可以很容易地扩展到数百个层。我们的Residual Attention Network在CIFAR-10、CIFAR-100和具有挑战性的ImageNet[5]图像分类数据集上表现优于最先进的残差网络,显著减少了计算量(69%的前向FLOPs)。

所有上述的属性,对于以前的方法来说是具有挑战性的,我们通过以下贡献,使之成为可能:
(1)Stacked network structure: 我们的Residual Attention Network是通过叠加多个注意力模块来构建的。堆叠结构是混合注意力机制的基本应用。因此,不同类型的注意力可以在不同的注意力模块中被捕获。
(2)Attention Residual Learning:直接叠加注意力模块会导致明显的性能下降。因此,我们提出注意力残差学习机制,以优化极深的数百层Residual Attention Network。
(3)Bottom-up top-down feedforward attention:Bottom-up top-down的前馈结构已成功应用于人体位姿估计[24]和图像分割[22,25,1]。我们使用这种结构作为注意力模块的一部分,在特征上增加soft权重。该结构可以在单个前馈过程中模拟bottom-up的快速前馈过程和top-down的注意力反馈过程,使我们能够发展出一个有着top-down注意力的端到端可训练网络。我们工作中的bottom-up top-down结构与stacked hourglass network[24]在引导特征学习的意图上有所不同。
2. Related Work
人类感知过程[23]的证据表明注意力机制的重要性,它利用top信息指导bottom-up的前馈过程。近年来,人们开始尝试将注意力应用于深度神经网络。Deep Boltzmann Machine(DBM)[21]在训练阶段的重建过程包含了top-down的注意力。注意力机制也被广泛应用于递归神经网络(RNN)和long short term memory(LSTM)[13]来处理顺序决策任务[25,29,21,18]。Top信息被连续收集,并决定在哪里参加下一个特征学习步骤。
提出了残差学习[10]来学习恒等映射的残差。该技术极大地增加了前馈神经元网络的深度。与我们的工作相似,[25,29,21,18]使用带有注意力机制的残差学习来受益于残差学习。使用注意力机制捕获两个信息源(查询和查询上下文),以相互协助它们的工作。而在我们的工作中,一个单一的信息源(图像)被分割成两个不同的信息源并反复组合。利用残差学习来缓解重复拆分合并带来的问题。
在图像分类中,使用了不同的方法来应用top-down的注意力机制,:序列处理(sequential process)、区域proposal和控制门(control gates)。序列过程[23,12,37,7]将图像分类建模为序列决策。因此,注意力可以与上面类似地应用。这个公式允许使用RNN和LSTM进行端到端优化,并且可以以目标驱动的方式捕获不同种类的注意力。
区域proposal[26,4,8,38]在图像检测任务中被成功采用。在图像分类中,在前馈分类前增加一个区域proposal阶段。所提出的区域包含top信息,用于第二阶段的特征学习。图像检测的区域proposal需要大量的监督,如ground truth bounding box或detail segmentation mask[6],而非监督学习[35]通常用于生成图像分类的区域proposal。
控制门在LSTM中得到了广泛应用。在有注意力的图像分类中,神经元的控制门使用top信息进行更新,并在训练过程中影响前馈过程[2,30]。然而,在训练步骤中涉及到一个新的过程,强化学习[30]或优化[2]。Highway Network[29]扩展了控制门,解决了深度卷积神经网络的梯度退化问题。
然而,最近图像分类的进展主要集中在使用“very deep”结构训练前馈卷积神经网络[27,33,10]。前馈卷积网络模拟了人类皮层 bottom-up的路径。为了进一步提高深度卷积神经网络的识别能力,人们提出了各种各样的方法。提出了VGG[27]、Inception[33]和残差学习[10]用于训练极深度神经网络。Stochastic depth[14]、Batch Normalization[15]和Dropout[28]利用正则化收敛,避免过拟合和退化。
在最近的工作[3,17]中开发的soft注意力可以训练端到端的卷积网络。我们的Residual Attention Network以一种创新的方式融合了快速发展的前馈网络结构中的soft注意力。最近提出的spatial transformer module[17]实现了最先进的门牌号码识别任务。利用获取top信息的深度网络模块生成仿射变换。对输入图像进行仿射变换,得到参与区域,再将其反馈给另一个深度网络模块。利用可微网络层进行空间变换,可以对整个过程进行端到端训练。[3]采用soft注意力作为尺度选择机制,在图像分割任务中得到了最先进的结果。
Residual Attention Network 的soft注意力结构的设计灵感来自于定位任务的最新发展,即分割[22,25,1]和人体姿态估计[24]。这些任务促使研究人员使用细粒度的特征图来探索结构。框架倾向于级联一个bottom-up和一个top-down结构。bottom-up的前馈结构产生低分辨率的特征图,语义信息强。然后,top-down的网络产生密集的特征,对每个像素进行推断。底部和顶部特征图之间采用了skip connection[22],实现了最先进的图像分割效果。最近的stacked hourglass network[24]融合了来自多个尺度的信息来预测人类姿态,并受益于编码全局和局部信息。
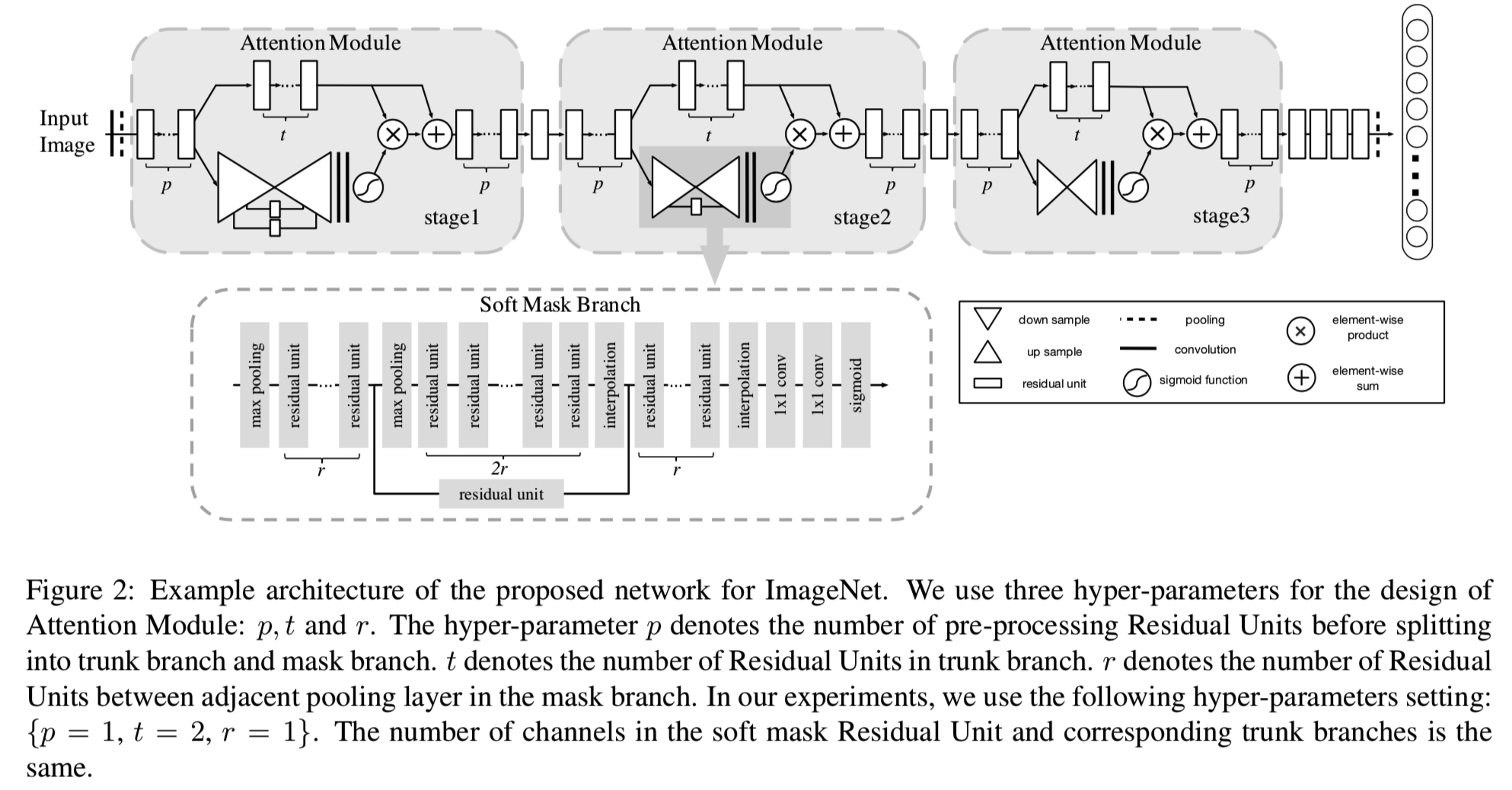
3. Residual Attention Network
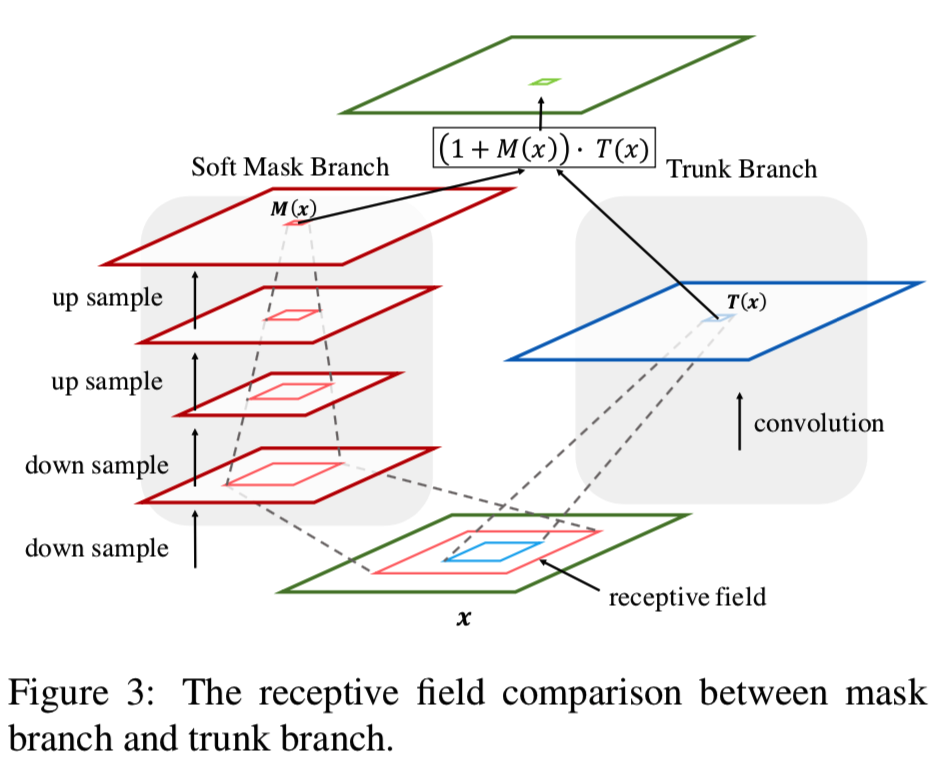
Residual Attention Network由多个注意力模块叠加而成。每个Attention模块分为两个分支:mask分支和主干分支。主干执行特征处理,可以适应任何先进的网络结构。在本研究中,我们以预激活残差单元[11]、ResNeXt[36]和Inception[32]作为残差注意力网络的基本单元来构建注意力模块。给定输入x的主干分支输出T(x),掩码分支采用bottom-up top-down的结构[22,25,1,24]来学习软权输出特征T(x)的相同大小的mask M(x)。bottom-up top-down的结构模仿了快速前馈和反馈的注意力过程。输出mask作为类似于Highway Network[29]的主干神经元的控制门。注意力模块H的输出为:
![]()
其中i取值范围为所有空间位置,c∈{1,…, C}是通道的索引。整个结构可以端到端训练。
在注意力模块中,注意力mask不仅可以作为正向推理时的特征选择器,还可以作为反向传播时的梯度更新滤波器。在soft mask分支中,输入特征的mask梯度为:

其中,Θ为mask分支参数,Φ为主干分支参数。这个特性使注意力模块对有噪声的标签具有鲁棒性。mask分支可以防止错误的梯度(来自噪声标签)来更新主干参数。第4.1节的实验表明了我们的Residual Attention Network对噪声标签的鲁棒性。
在我们的设计中,没有stacking注意力模块,一种简单的方法是使用单一网络分支生成soft权重mask,类似于spatial transformer layer[17]。然而,这些方法在像ImageNet这样具有挑战性的数据集上有一些缺点。首先,对背景杂乱、场景复杂、外观变化较大的图像进行建模时需要不同类型的注意力。在这种情况下,不同层次的特征需要用不同的注意力mask来建模。使用单个mask分支将需要幂级数量的通道来捕获不同因素的所有组合。第二,单个注意力模块只修改一次特征。如果修改在图像的某些部分失败,以下网络模块将不再有第二次机会。
Residual Attention Network缓解了上述问题。在注意力模块中,每一个主干分支都有自己的mask分支来学习它的特点。如图1所示,在热气球图像中,底层的蓝色特征采用对应的天空mask去除背景,而顶层的部分特征采用热气球实例mask进行细化。此外,叠加网络结构的递增性质可以逐渐细化对复杂图像的关注。
3.1. Attention Residual Learning
然而,单纯的叠加注意力模块导致了明显的性能下降。首先,点乘范围从0到1的mask将重复降低在深层的特征值。其次,soft mask可能破坏主干分支的良好特性,例如残差单元的恒等映射。
我们提出注意力残差学习来缓解上述问题。与残差学习的思想相似,如果能将soft mask单元构造成恒等映射,则其性能不会比对应的没有注意力的情况差。因此,我们将Attention模块的输出H修改为:
![]()
M(x)的范围为[0,1],M(x)近似于0, H(x)将近似原始特征F(x)。我们称这种方法为attention residual learning。
我们的stacked残差学习与残差学习不同。在原始的ResNet中,残差学习公式为![]() ,其中
,其中![]() 近似残差函数。在我们的式子中,
近似残差函数。在我们的式子中,![]() 表示深度卷积网络生成的特征。关键在于mask分支M(x)。它们作为特征选择器,可以增强好的特征,抑制来自主干特征的噪声。
表示深度卷积网络生成的特征。关键在于mask分支M(x)。它们作为特征选择器,可以增强好的特征,抑制来自主干特征的噪声。
此外,stacking注意力模块通过其增量特性支持attention residual learning。attention residual learning在保持原有特征良好性质的同时,也使其能够绕过soft mask分支向顶层转发,削弱mask分支的特征选择能力。stacked注意力模块可以逐步细化特征图。如图1所示,深度越深,特征越清晰。通过attention residual learning,增加Residual Attention Network的深度可以持续地提高网络性能。如实验部分所示,Residual Attention Network的深度增加到452,其性能在CIFAR数据集上大大超过ResNet-1001。
3.2. Soft Mask Branch
遵循之前DBN[21]中的注意力机制思想,我们的mask分支包含快速前馈扫描和top-down的反馈步骤。前者快速收集整幅图像的全局信息,后者将全局信息与原始特征图结合。在卷积神经网络中,这两个步骤依次为bottom-up top-down的全卷积结构。
从输入开始,在少量残留单元后,进行多次max-pooling以快速增加接收域。在达到最低的分辨率后,全局信息被一个对称的top-down的架构扩展,以引导每个位置的输入特征。在残差单元后对输出进行线性插值来上采样。双线性插值的次数与max pooling相同,以保持输出大小与输入feature map相同。然后,在连续两个1×1卷积层之后,用一个sigmoid层将输出范围归一化到[0,1]。我们还在bottom-up top-down部分之间添加了skip连接,以从不同的尺度捕获信息。整个模块如图2所示。
这种bottom-up top-down的结构已应用于图像分割和人体姿态估计。然而,我们的结构与前一个的不同之处在于它的意图。我们的mask分支旨在改进主干分支的特性,而不是直接解决一个复杂的问题。第4.1节的实验验证了上述论点。
3.3. Spatial Attention and Channel Attention
在我们的工作中,mask分支所提供的注意力可以随主干分支的特征而改变。但是,在soft mask输出之前,通过改变激活函数的归一化步骤,仍然可以将注意约束添加到mask分支中。我们使用了与混合注意(mixed attention)、通道注意(channel attention)和空间注意(spatial attention)相对应的三种激活函数。混合注意f1没有额外的限制,对每个通道和空间位置使用简单的sigmoid。通道注意f2对每个空间位置的所有通道进行L2归一化,以去除空间信息。空间注意f3对每个通道的feature map进行归一化,然后再进行sigmoid,得到只与空间信息相关的soft mask。
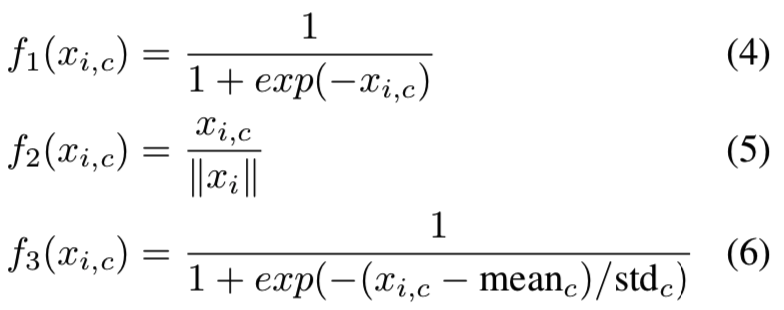
其中,i范围是所有空间位置,x范围是所有通道。meanc和stdc表示来自第c个通道的feature map的均值和标准差。xi表示第i个空间位置的特征向量。
实验结果如表1所示,混合注意具有最好的性能。以前的作品通常只关注一种类型的注意,例如尺度注意(scale attention)[3]或空间注意[17],它们通过权重共享或归一化对soft mask施加额外的约束。但是,我们的实验证明,在不附加约束的情况下,自适应地使用特征进行注意力变化可以获得最好的性能。

4. Experiments
在本节中,我们在一系列基准数据集(包括CIFAR-10、CIFAR-100[19]和ImageNet[5])上评估了所提出的剩余注意力网络的性能。我们的实验包括两部分。在第一部分中,我们分析了Residual Attention Network中各组成部分的有效性,包括注意残差学习机制和注意模块中soft mask分支的不同架构。在此基础上,研究了其抗噪声性能。由于计算资源有限,我们选择CIFAR-10和CIFAR-100数据集进行实验。最后,我们将我们的网络与CIFAR数据集的最新结果进行了比较。在第二部分中,我们用Inception模块和ResNeXt替换残差注意单元,以证明我们的Residual Attention Network在参数效率和最终性能上都超过了原始网络。我们还比较了最新的ResNet和Inception在ImageNet数据集上的图像分类性能。
4.1. CIFAR and Analysis
Implementation. CIFAR-10和CIFAR-100数据集分别包含10个类和100个类的6万幅的32×32的彩图,其中有5万幅训练图像和1万幅测试图像。采用目前广泛应用的最先进的网络结构ResNet作为基线方法。为了进行公平的比较,我们保持大部分的设置与ResNet[10]相同。将图像每边填充4个像素,填充0值,得到40×40的图像。从一幅图像或它的水平翻转中随机采样32×32的剪裁,减去每个像素的RGB平均值。我们采用与之前研究[9]相同的权值初始化方法,并使用nesterov SGD对Residual Attention Network进行训练,最小batch size为64。我们使用权值衰减为0.0001,momentum为0.9,并将初始学习率设置为0.1。在64k和96k次迭代时,学习率除以10。我们在16万次迭代时终止训练。
整体网络架构和超参数设置如图2所示。该网络由3个阶段组成,类似于ResNet[10],在每个阶段堆叠相同数量的注意力模块。此外,我们在每个阶段增加两个残差单元。主干权重层数为36m+20,其中m为某一阶段的注意力模块数。我们使用原始的32×32图像进行测试。
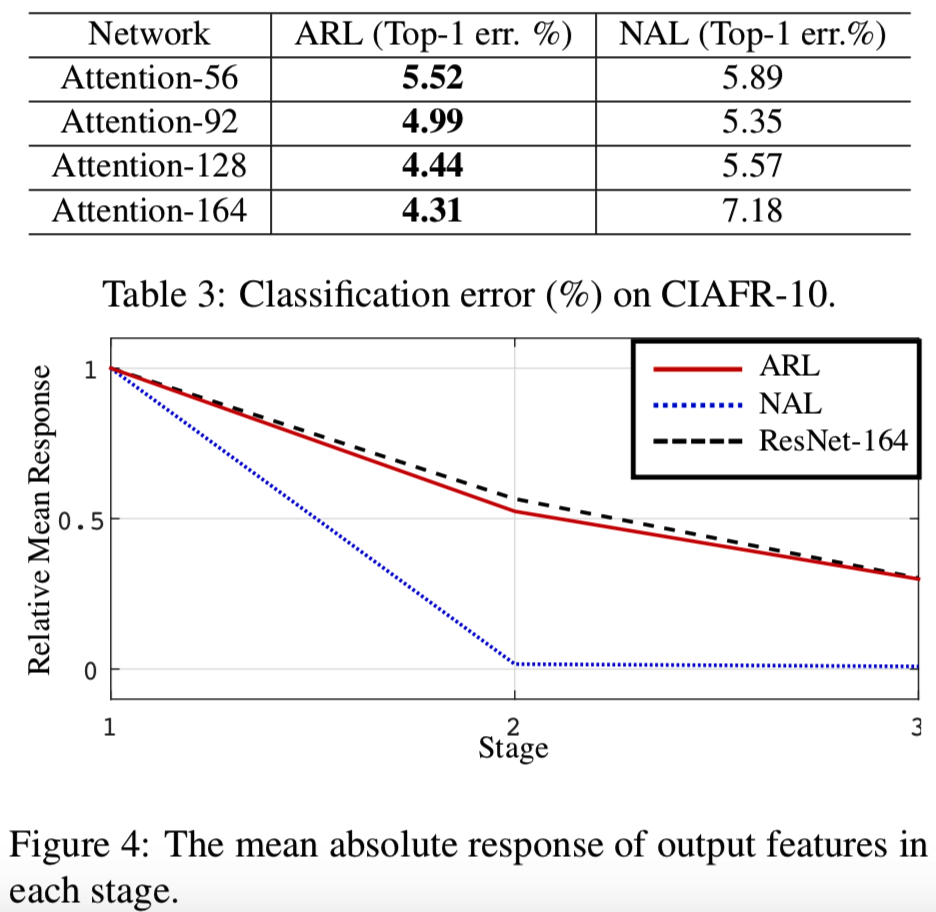
Attention Residual Learning. 在本实验中,我们对注意残差学习机制的有效性进行了评价。由于attention residual learning(ARL)的概念是新的,以前没有合适的方法是可比较的,因此我们使用“朴素注意力学习”(NAL)作为基准。具体来说,“naive attention learning”使用的是注意模块,其特征是通过soft mask直接点积,而不需要attention residual learning。我们设置每个阶段的注意模块数量m ={1,2,3,4}。对于Attention模块,这将分别产生Attention-56(根据主干层深度命名)、Attention-92、Attention-128和Attention-164网络。
我们使用不同的机制训练这些网络,并在表3中总结了结果。如表3所示,使用注意力残差学习技术训练的网络性能始终优于基线方法训练的网络,证明了我们方法的有效性。注意力残差学习的性能随注意力模块数目的增加而提高。而采用朴素注意学习方法训练的网络,随着注意模块数量的增加,其性能明显下降。
为了理解注意力残差学习的好处,我们计算每个阶段输出层的平均绝对响应值。我们使用Attention-164来进行这个实验。如图4所示,在经过4个注意力模块后,与使用注意力残差学习训练的网络相比,使用朴素注意力学习训练的网络所产生的响应在第二阶段迅速消失。注意力模块通过在特征和soft mask之间应用点积来抑制噪声,同时保留有用的信息。但是,在这个过程中,重复的点积会导致有用信息和无用信息的严重退化。注意力残差学习可以使用恒等映射缓解信号衰减,增强特征对比度。因此,在不损失显著信息的情况下,降低了噪声,使得优化更加容易,同时提高了表征特征的识别率。在接下来的实验中,我们使用这种技术来训练我们的网络。
Comparison of different mask structures. 通过与没有任何下采样和上采样的局部卷积进行比较,验证了encoder-decoder结构的有效性。局部卷积soft mask由三个残差单元组成,使用相同数量的FLOPs。用Attention-56分别构造Attention-Encoder-Decoder-56和Attention-Local-Conv-56网络。结果如表4所示。Attention-Encoder-Decoder-56网络最低测试error为5.52%,Attention-Local-Conv-56网络的测试error为6.48%,两者有0.94%的显著差距。结果表明,soft注意力优化过程将受益于多尺度信息。

Noisy Label Robustness. 在这个实验中,我们证明了我们的Residual Attention Network在CIFAR-10数据集上具有良好的抗噪声性能。我们实验的混淆矩阵设置如下:
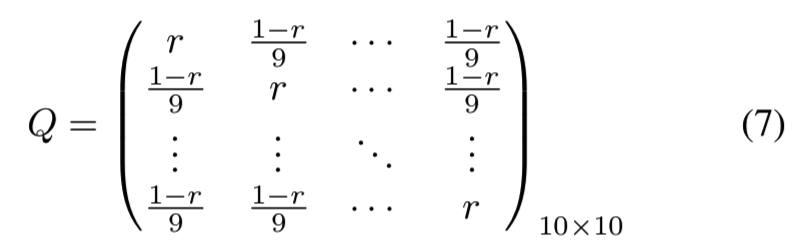
式中,r为整个数据集的clean label ratio。
我们比较了不同噪音水平下的ResNet-164网络和Attention-92网络。表5显示了结果。在相同噪声水平下,Attention-92网络的测试误差明显低于ResNet-164网络。另外,当增加噪声比时,Attention-92的测试误差比ResNet-164的测试误差下降较慢。这些结果表明,即使在高水平噪声数据下,我们的Residual Attention Network也能表现良好。当标签有噪声时,相应的mask可以防止标签错误引起的梯度在网络中更新主干分支参数。这样一来,只有主干分支是学习了错误的监督信息和soft mask分支masks错误的标签。

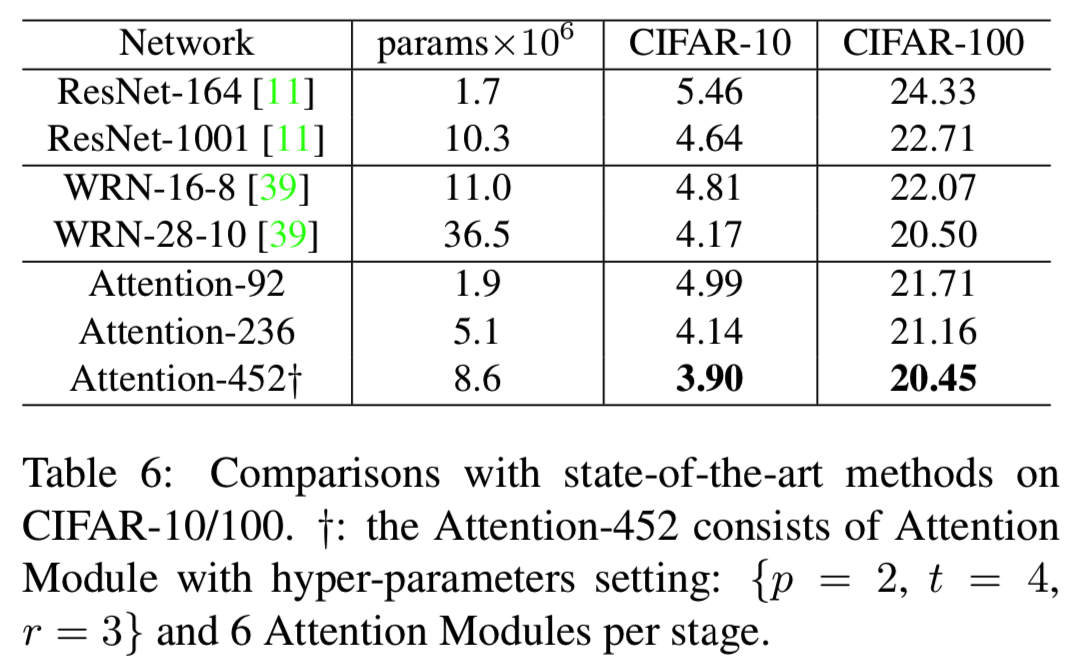
Comparisons with state-of-the-art methods. 在CIFAR-10和CIFAR-100数据集上,我们将Residual Attention Network与最先进的方法进行比较,包括ResNet[11]和Wide ResNet[39]。结果如表6所示。我们的Attention-452在CIFAR-10和CIFAR-100数据集上优于所有的基线方法。值得注意的是,在相似参数大小下,Attention-92网络对CIFAR-10的测试误差为4.99%,对CIFAR-100的测试误差为21.71%,而ResNet-164网络对CIFAR-10和CIFAR-100的测试误差为5.46%,24.33%。此外,仅使用一半的参数,Attention-236的表现就优于ResNet-1001。这表明,我们的注意力模块和注意力残差学习方案能够在提高分类性能的同时有效地减少网络中的参数数量。
4.2. ImageNet Classification
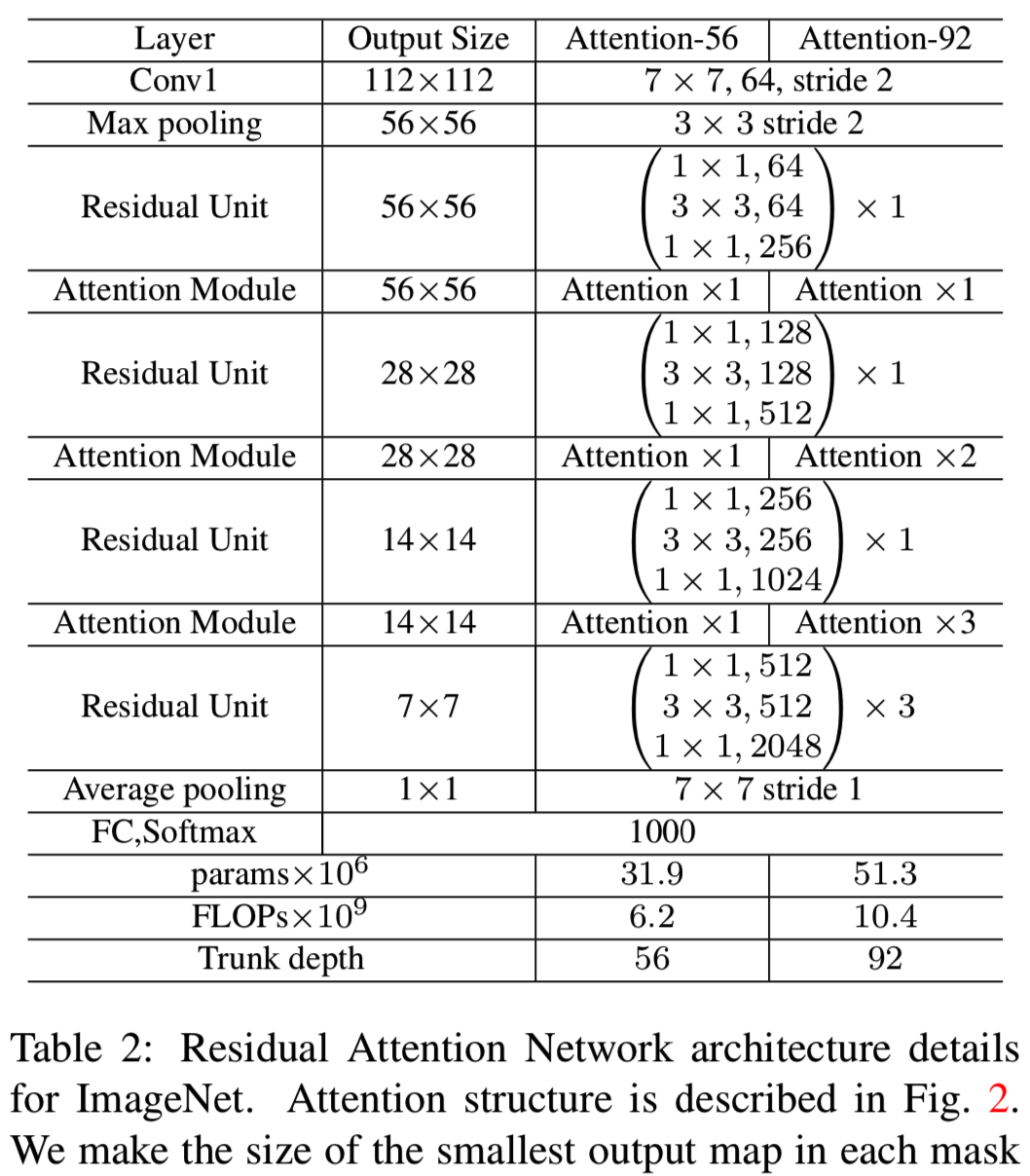
在本节中,我们使用ImageNet LSVRC 2012数据集[5]进行实验,该数据集包含1000个类和120万张训练图像、5万张验证图像和10万张测试图像。评价在ImageNet LSVRC 2012验证集的非黑名单图像上进行测量,我们使用Attention-56和Attention-92进行实验。网络结构和超参数见表2。
Implementation. 我们的实现通常遵循前面研究[20]中的实践。我们对原始图像应用尺度和宽高比增强[33]。从一幅增大图像或其水平翻转中随机采样一幅224×224的裁剪图,每像素的RGB范围为[0,1],减去平均值,除以标准方差。我们采用标准的彩色增强[20]。该网络使用momentum为0.9的SGD进行训练。我们将初始学习率设置为0.1。迭代次数为200k、400k、500k时,学习率除以10。我们在53万次迭代时终止训练。
Mask Influence. 在这个实验中,我们探讨了所提出的Residual Attention Network的有效性。我们比较了Attention-56和ResNet-152[10]。ResNet-152有50个主干残差单元和60.2×106个参数,而Attention-56有18个主干残差单元和31.9×106个参数。我们在ImageNet验证集上使用单一crop模式评估我们的模型,并在表7中显示结果。Attention-56网络的性能大大优于ResNet-152,在top-1 error上减少了0.4%,在top-5error上减少了0.26%。更重要的是,与ResNet-152相比,attention-56网络仅用52%的参数和56%的FLOPs就获得了更好的性能,说明本文提出的attention机制可以在降低模型复杂度的同时显著提高网络性能。
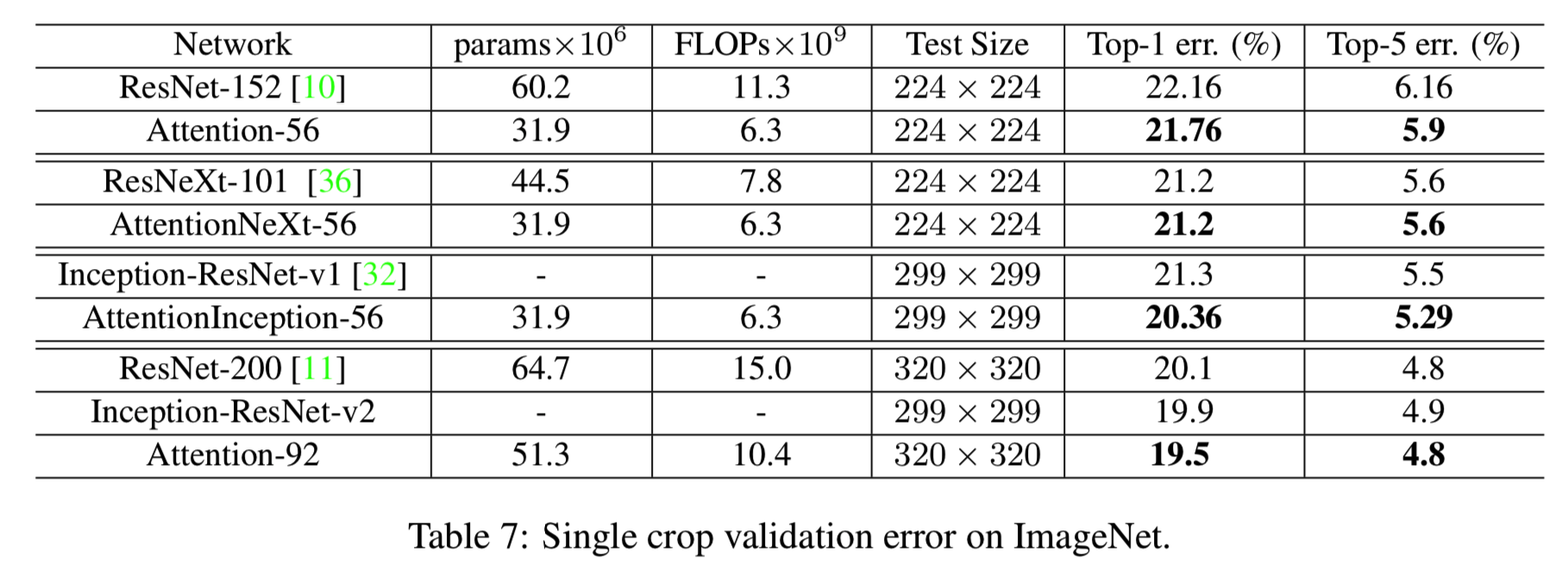
Different Basic Units. 实验表明,使用不同的基本单元可以很好地推广Residual Attention Network。我们使用三个流行的基本单元:Residual Unit、ResNeXt[36]和Inception[32]来构建我们的Residual Attention Network。为了将参数和FLOPs的数量保持在相同的范围内,我们简化了Inception。结果如表7所示。
当以ResNeXt为基本单元时,AttentionNeXt-56网络性能与ResNeXt-101相同,但参数和FLOPs明显少于ResNeXt-101。首先,AttentionIncepiton-56比Incepase-Resnet-v1[32]的表现好,top-1 error减少了0.94%,top-5 error减少了0.21%。结果表明,我们的方法可以适用于不同的网络结构。
Comparisons with State-of-the-art Methods. 我们将我们在ILSVRC 2012验证集上使用了单一crop的Attention-92的评估与最先进的算法相比较。表7显示了结果。我们的Attention-92远远超过ResNet-200。top-1 error 降低了0.6%。注意,ResNet-200网络比Attention-92多包含32%的参数。表7中所示的attention-92的计算复杂度表明,通过增加注意力机制和降低主干深度,我们的网络比ResNet-200减少了近一半的训练时间。结果表明,该模型具有较高的效率和良好的性能。
5. Discussion
我们提出了一个叠加多个注意力模块的Residual Attention Network。我们的网络的好处有两个方面:它可以捕获mixed注意力,是一个可扩展的卷积神经网络。第一个好处在于,不同的注意模块捕获不同类型的注意力来指导特征学习。我们对激活函数形式的实验也验证了这一点:自由形式的混合注意力比有约束的注意力(包括单一注意力)有更好的表现。第二个好处是将每个注意力模块中的top-down的注意机制编码为bottom-up top-down的前馈卷积结构。这样,基本的注意力模块就可以组合成更大的网络结构。此外,残差注意力学习允许训练非常深的残差注意力网络。我们的模型的性能超过了最先进的图像分类方法,例如CIFAR-10的ResNet(3.90%的error),CIFAR-100的ResNet(20.67%的error),以及具有挑战性的ImageNet数据集的ResNet(0.6%的top-1精度提高),只用了46%的trunk depth和69%的forward FLOPs(与ResNet-200比较)。在未来,我们会将深度Residual Attention Network应用于检测和分割等不同领域,更好地探索针对特定任务的混合注意机制。

