
Video Google(2003) - 1 - 论文学习
http://www.robots.ox.ac.uk/~vgg/publications/2003/Sivic03/sivic03.pdf
http://www.robots.ox.ac.uk/~vgg/research/vgoogle/
本篇文章主要研究的内容就是如何将文字检索的一些方法移植到视频搜索中,实际上也就是对视频中的每一帧图像进行搜索
Video Google: A Text Retrieval Approach to Object Matching in Videos
Abstract
我们描述了一种对象和场景检索的方法,它搜索和定位视频中用户描述的对象的所有出现位置。该对象由一组视点不变区域描述符表示,使识别能够在视点、光照和局部遮挡发生变化的情况下顺利进行。利用视频在一个镜头内的时间连续性来跟踪区域,以剔除不稳定区域,减少描述符中的噪声影响。
与文本检索相似的是,在实现中,描述符上的匹配是预先计算的(使用向量量化),并且使用inverted文件系统和文档排名。结果是检索是即时的,以谷歌的方式返回关键帧/镜头的排序列表。
该方法用于阐述在两个全长feature films上的匹配。
1. Introduction
这项工作的目的是使用包含特定的词的谷歌检索文本文件(网页) 对包含一个特定的对象的那些关键帧和镜头的视频进行容易,速度且准确地检索。本文研究了一种文本检索方法能否成功地用于目标识别。
在图像数据库中识别(相同的)物体现在已经达到了一定的成熟程度。但因为一个物体的视觉外观可能会因为视点和光照的不同而有很大的不同,并且其可能会被部分遮挡,所以这仍然是一个具有挑战性的问题,但是现在已经有了成功的方法。通常,一个对象由一组重叠区域表示,每个重叠区域由从该区域的外观计算出的向量表示。在控制视点和光照条件不变的前提下,建立区域分割和描述符。对数据库中的所有图像计算相似的描述符。对特定对象的识别是通过描述符向量的最*邻匹配进行的,然后使用局部空间一致性(如邻里关系、排序或空间布局)或全局关系(如极体几何关系)来消除歧义。例如[5,6,8,11,13,12,14,16,17]。
我们探讨这种类型的识别方法能否被重新定义为文本检索。本质上,这需要一个单词的视觉类比,这里我们通过量化描述符向量来提供这个类比。但是,我们可以看到,使用文本检索进行类比不仅仅是对不同矢量量化的简单优化。有许多经验教训和经验规则,已经学会和发展在文本检索文献,它是值得去确定这些方法是否也可以用于视觉
检索。
这种方法的好处是有效地预先计算匹配,因此在运行时,可以不延迟地检索包含任何特定对象的帧和镜头。这意味着视频中出现的任何对象(以及对象的conjunctions)都可以被检索到,即使在为视频构建描述符时对这些对象没有明显的兴趣。然而,我们还必须确定,如果使用了前一种最*邻匹配方法,这个向量量化检索是否会丢失任何可能已经获得的匹配。
Review of text retrieval: 文本检索系统通常采用一些标准步骤[1]。文档首先被解析为单词。第二,单词由词干表示,例如“walk”,“walking”和“walks”都由词干“walk”表示。第三,停用列表用于拒绝非常常见的单词,如“the”和“an”,它们出现在大多数文档中,因此不会区分特定的文档。然后为其余的单词分配一个唯一的标识符,每个文档由一个向量表示,其中的组件由文档中包含的单词的出现频率给出。此外,组件以各种方式进行加权(第4节将详细描述),对于谷歌,web页面的加权取决于链接到特定页面[3]的web页面的数量。以上步骤都是在实际检索之前进行的,将用来表示语料库中所有文档的向量集组织为一个inverted文件[18],便于高效检索。inverted文件的结构类似于理想的图书索引。对于语料库中的每个单词,它都有一个条目,后面是单词出现的所有文档(以及文档中的位置)的列表。
通过计算其单词频率向量并返回最接*(以角度衡量)向量的文档来检索文本。此外,单词的排序和分离匹配可用于对返回的文档进行排序。
Paper outline(论文大纲): 在这里,我们探索这些步骤的视觉类比。第2节描述了所使用的视觉描述符。第3节描述了如何向量量化成视觉“单词”,第4节为向量模型加权和索引。然后在第5节中的一个ground truth框架集上评估这些想法。最后,在第6节中介绍了停用列表和排名(根据空间布局匹配),并在两个feature films: ‘Run Lola Run’ (‘Lola Rennt’) [Tykwer, 1999] 和 ‘Groundhog Day’ [Ramis, 1993]上评估对象检索。
尽管之前的工作借鉴了文本检索文献的思想,用于数据库中的图像检索(例如[15]使用了加权和inverted文件方案),但据我们所知,这是第一次系统地将这些思想应用于视频中的对象检索。
2. Viewpoint invariant description
每一帧计算两种视点协变区域。第一种方法是利用兴趣点的椭圆形状自适应构造。该方法包括迭代确定椭圆中心、尺度和形状。尺度由Laplacian的局部极值(跨尺度)决定,形状通过在椭圆区域上最大化强度梯度的各向同性而决定[2,4]。实现细节见[8,13]。这种区域类型称为适应形状(Shape Adapted,SA)。
第二类区域是通过从强度分水岭图像分割中选取区域来构造的。当强度阈值变化时,这些区域是*似*稳的。实现细节在[7]中给出。这种区域类型被称为最大稳定(Maximally Stable,MS)。
使用两种类型的区域,因为它们检测不同的图像区域,从而提供一个帧的互补表示。SA区域倾向于集中在角状特征上,MS区域对应于相对于其周围环境的高对比度blobs,如灰色墙壁上的黑色窗户。这两种类型的区域都用椭圆表示。这些以两倍的原始检测区域大小计算,以使图像外观更具鉴别性。对于720 x 576像素的视频帧,所计算的区域数通常为1600。图1显示了一个示例。(所以就是用这两种区域作为一帧图像的visual words,使用visual words来检测出与query帧,即query图像相似的其他帧)

每个椭圆仿射不变区域使用Lowe[5]开发的SIFT描述符,用一个128维向量表示。[9]这个描述符表现优于其他文献中使用的方法,比如一组可操纵的过滤器[8]或[13]正交过滤器的响应,我们还发现SIFT效果更优(通过将检索结果与ground-truth对比,如5.1节)。得到这种优越性能的原因是,SIFT不同于其他描述符,它被设计为对区域位置的几个像素的移动保持不变,而这种定位错误是经常发生的。将SIFT描述符与仿射协变区域相结合,得到了对图像仿射变换不变的区域描述向量。注意,区域检测和描述都是在单色版本的帧上计算的,颜色信息目前没有在这个工作中使用。
为了减少噪声和拒绝不稳定区域,信息被聚集在一个帧序列中。利用一个简单的恒速动态模型和相关算法对每帧视频中检测到的区域进行跟踪。任何不能存活超过三帧的区域都会被拒绝。追踪的每个区域都可以看作是一个共同场景区域(被检测区域的预图像)的独立测量,并通过对整个追踪过程的描述符进行*均来估计该场景区域的描述符。这在描述符的信号噪声方面提供了一个可测量的改进(这在第5.1节的ground truth测试中再次得到了证明)。
3. Building a visual vocabulary
这里的目标是矢量量化描述符成集群,其将成为文本检索的视觉“词”。然后,当观察到影片的一个新帧时,该帧的每个描述符都被分配到最*的集群中,这将立即为整个影片中的所有帧生成匹配。词汇表是由电影的一个部分构建的,它的匹配准确性和表达能力将根据电影的其余部分进行评估,如下面的部分所述。
虽然其他方法(K-medoids、直方图binning等)也有可能,但这里的矢量量化是通过K-means聚类来实现的。
3.1. Implementation
在连续帧中跟踪区域,为每个i区域计算一个*均向量描述符![]() 。为了剔除不稳定区域,去掉了有着最大对角线协方差矩阵的跟踪区域中10%的区域。每帧*均生成大约1000个区域。
。为了剔除不稳定区域,去掉了有着最大对角线协方差矩阵的跟踪区域中10%的区域。每帧*均生成大约1000个区域。
每个描述符都是一个128向量,同时对电影的所有描述符进行聚类将是一项庞大的任务。相反,48个镜头的子集被选中(这些镜头在5.1节中被更详细地讨论),覆盖了大约10k个帧,代表了电影中约10%的帧。即使如此,*均仍有200K的轨迹描述符必须被聚集。
确定聚类的距离函数Mahalanobis距离计算如下:假设对于所有tracks来说,协方差Σ是相同的,这是从所有可用数据中估计得来的,即在48个镜头中所有tracks的所有描述符。Mahalanobis距离可以使128向量中噪声较大的分量被降低权重,并且可以去掉分量的相关性。从经验上看,两者之间存在着某种程度的关联。两个描述符(由他们的*均track描述符表示)![]() 的距离给定为:
的距离给定为:![]() 。描述符空间通过Σ的*方根进行仿射变换,以便可以使用欧氏距离。
。描述符空间通过Σ的*方根进行仿射变换,以便可以使用欧氏距离。
形状适应区域(Shape Adapted)使用约6k个簇,最大稳定区域(Maximally Stable)使用约10k个簇。每种类型的聚类数量的比率被选择为*似于每种类型检测到的描述符的比率。在5.1节的ground truth集合上,经验地选择聚类的数量,使检索结果最大化。K-means算法在随机初始分配点作为聚类中心的情况下运行几次,并使用最佳结果。
图2显示了属于特定集群的区域的示例,其将被视为相同的视觉单词。聚类区域反映了SIFT描述符的属性,该属性惩罚区域间的变化,而不是互相关。这是因为SIFT强调梯度的方向,而不是区域内特定强度的位置。

SA和MS区域分开聚集的原因是它们覆盖了场景中不同且很大程度上独立的区域。因此,它们可能被认为是描述同一场景的不同词汇,因此应该有自己的词汇集,就像一个词汇可能描述建筑特征,而另一个词汇可能描述建筑物的维修状态一样。
4. Visual indexing using text retrieval methods
在文本检索中,每个文档都由单词频率向量表示。然而,它通常还会应用加权到这个矢量[1]的组成部分中哦,而不是使用频率矢量直接索引。在此,我们描述了所使用的标准加权方法,然后将文档检索视觉类比为与框架检索。
标准加权方法为‘term frequency– inverse document frequency’, tf-idf,计算如下所示。假设这里有k个单词的单词表,每个文件被表示为k-vector ![]()
![]() ,其中值为加权单词频率:
,其中值为加权单词频率:

其中nid是文件d中单词i出现的数量,nd是文件d中单词的总数量,ni是整个数据库中项i出现的数量,N则是整个数据库中文件的数量。权重包含两项:词频![]() 和反向文档频率(inverted document frequency)
和反向文档频率(inverted document frequency)![]() 。直观的感觉是,单词频率对经常出现在特定文档中的单词进行权重加强(说明它在这个文档中可能很特殊),因此可以很好地描述它,而反向文档频率对经常出现在数据库中的单词进行权重降低(说明这个单词不是很特殊,因为他在整个数据库中出现很多次)。
。直观的感觉是,单词频率对经常出现在特定文档中的单词进行权重加强(说明它在这个文档中可能很特殊),因此可以很好地描述它,而反向文档频率对经常出现在数据库中的单词进行权重降低(说明这个单词不是很特殊,因为他在整个数据库中出现很多次)。
在检索阶段,根据查询向量Vq和数据库中所有文档向量Vd之间的标准化标量积(角度的余弦)对文档进行排序。
在本例中,查询向量由用户指定的帧子部分中包含的视觉词给出,其他帧根据其加权向量与该查询向量的相似性进行排序。下一节将评估各种权重模型。
5. Experimental evaluation of scene matching using visual words
这里的目标是在一个封闭的世界的镜头[12]中匹配场景位置。该方法在电影Run Lola Run中19个不同3D位置拍摄的48个镜头的164帧上进行评估。每个位置有4-9个帧。图3a显示了来自四个不同位置的三个帧的例子。在同一位置显示的三组帧上有重要的视点变化。这三组的每一帧都来自电影中不同的镜头(在时间上也很遥远)。

在检索测试中,整个帧被用作查询区域。检索性能在所有164帧上进行测量,每帧依次作为一个查询区域。正确的检索包括所有显示相同位置的其他帧,这个ground truth是手工确定的完整的164帧集合。
检索性能是用相关图像[10]的*均归一化秩来衡量的:
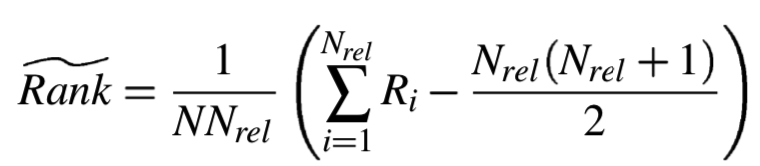
其中Nrel是关于特定查询图像的相关图像数量,N是图像集数量,Ri是第i个相关图像的秩。基本上,如果所有Nrel被先返回,则![]() 为0。
为0。![]() 测量值在0到1之间,0.5对应随机检索。
测量值在0到1之间,0.5对应随机检索。
5.1. Ground truth image set results
图3b显示了使用第4节中描述的带有tf-idf权重的数据集图像作为查询图像的*均归一化秩结果。拥有两种特征类型的好处是显而易见的。两者的结合显然比单独使用更好。每种特征类型的性能因帧或位置的不同而不同。例如,在46-49帧中,MS区域表现较好,而在126-127帧中,SA区域表现较好。(越小越好)
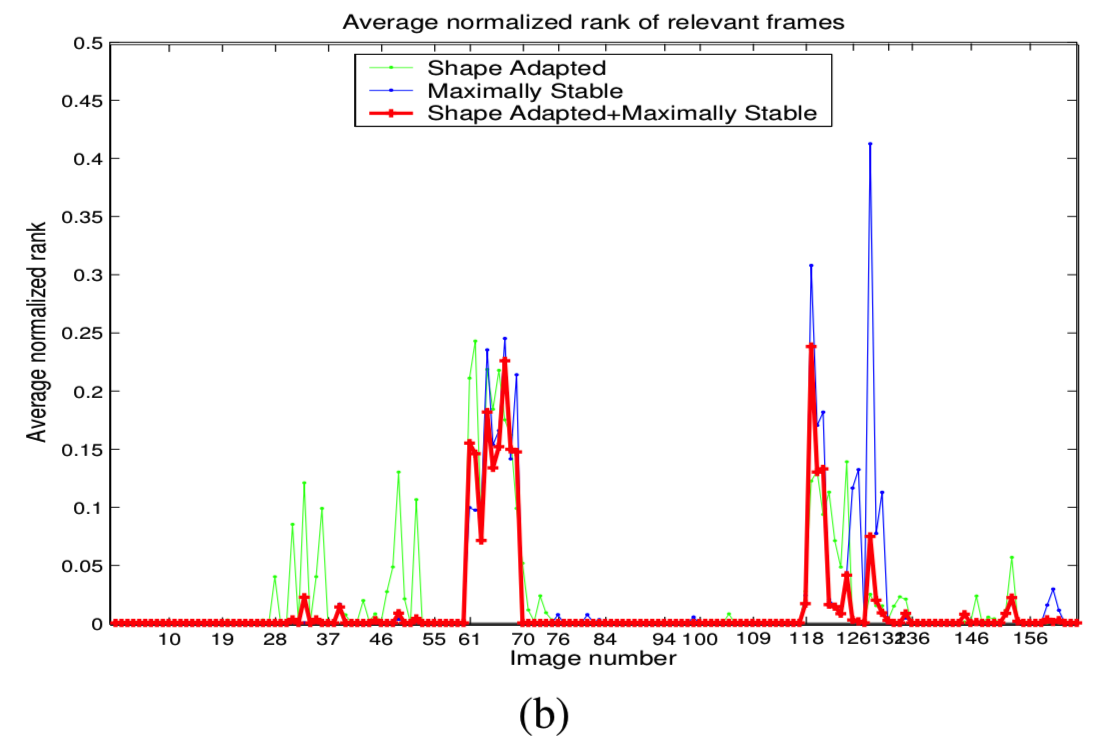
检索排名对于19个地点中的17个来说是完美的,即使是那些视点有重大变化的地方。对于图片61-70和119-121,排名结果没有那么令人印象深刻,尽管在这些情况下,其也没有错过帧匹配,只是排名较低。这是由于场景的重叠部分缺少区域,参见图4。这不是一个矢量量化的问题(相同的区域被正确匹配),是由于在这种类型的场景(路面纹理)中只有很少的特征被检测到。我们在第7节中回到这一点进行说明。

表1显示了三种标准文本检索词加权方法[1]对所有164幅图像计算出的![]() 测度的*均值。tf-idf权重优于二进制权重(即,如果图像包含描述符,则向量分量为1,否则为0)和词频权重(其分量是单词出现的频率)。对于整个ground truth集合的*均ranks来说,差异不是非常显著。然而,对于特定的帧(例如49),差异可能高达0.1。
测度的*均值。tf-idf权重优于二进制权重(即,如果图像包含描述符,则向量分量为1,否则为0)和词频权重(其分量是单词出现的频率)。对于整个ground truth集合的*均ranks来说,差异不是非常显著。然而,对于特定的帧(例如49),差异可能高达0.1。
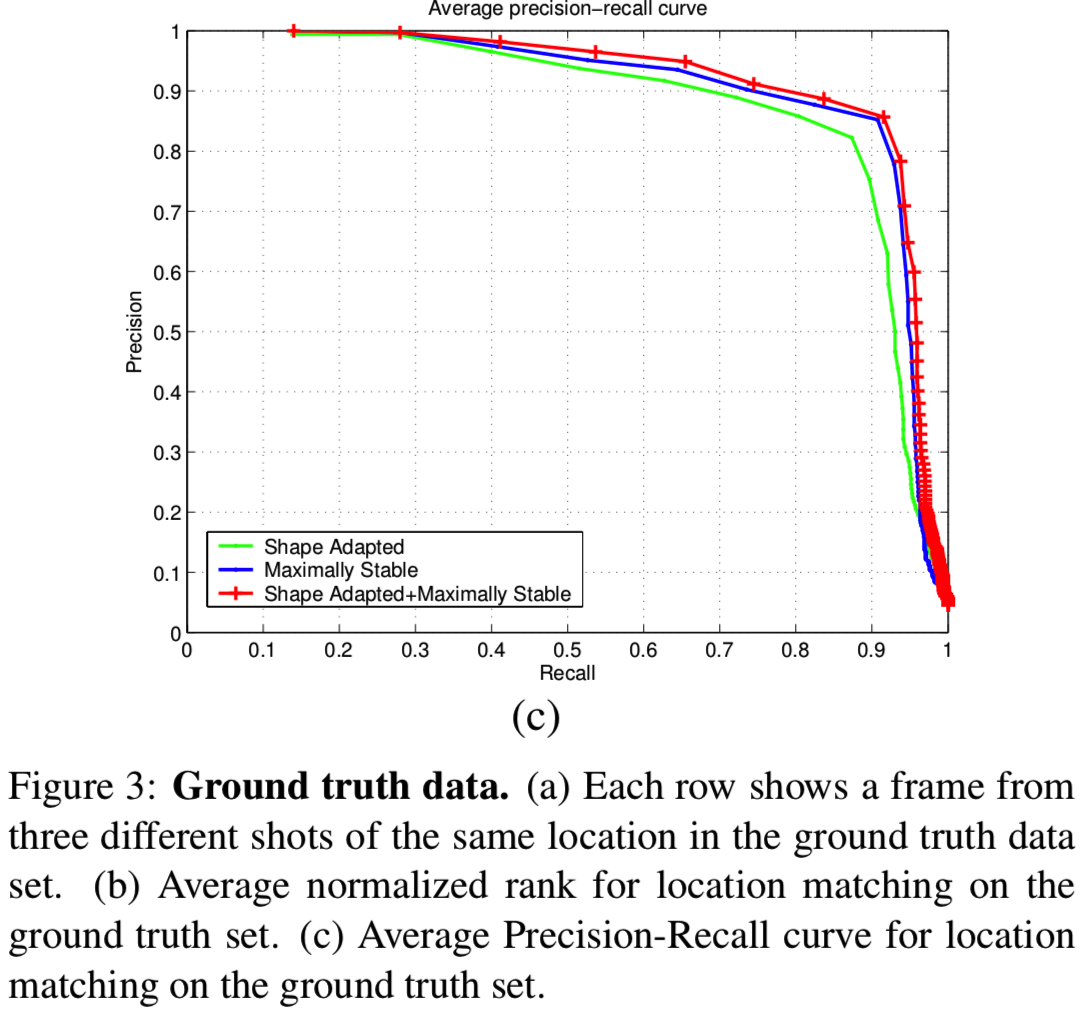
各帧的*均精度召回曲线如图3c所示。对于作为查询的每一帧,我们计算精度即相关图像(即相同位置的图像)相对于检索帧总数的比率,召回率即正确检索帧数量相对于相关帧数量的比率。结合这两种特征类型的好处是显而易见的。
这些检索结果表明,与不变量[12]的直接最*邻(或ε-nearest neighbour)匹配相比,使用向量量化(视觉词)方法没有性能损失。
这个ground truth集合也用于学习系统参数,包括:集群中心的数量;稳定特征的最小跟踪长度;根据不稳定描述符的协方差进行拒绝的比例。
6. Object retrieval
在本节中,我们将评估整个影片中的对象搜索。用户将感兴趣的对象指定为任何框架的子部分。
feature films一般有100K-150K帧。为了降低复杂性,视频每秒钟使用一个关键帧。对每个关键帧中的稳定区域计算描述符,并使用关键帧前后的两帧计算均值。描述符使用从ground-truth集聚集的中心进行向量量化。
这里我们还评估了视觉词汇的表现力,因为ground truth集合之外的框架包含了新的对象和场景,而且它们检测到的区域没有被包含在聚类中。
6.1. Stop list
使用停用列表类比在几乎所有图像中出现的最频繁的且被抑制的视觉词。图5显示了在Lola的所有关键帧中视觉词的频率。最高的5%和最低的10%已经停用。在我们的例子中,非常常见的词是由于大集群超过了3K个点。停用列表边界是根据经验确定的,以减少不匹配的数量和inverted文件的大小,同时保持足够的视觉词汇。
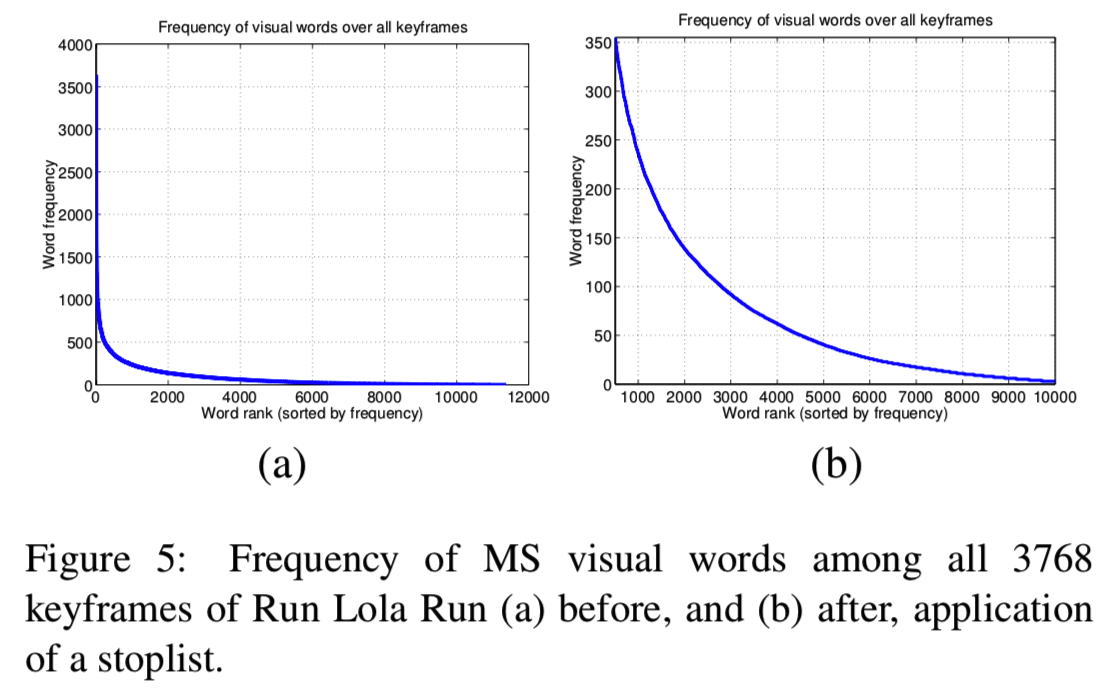
图6显示了添加停用列表的好处——非常常见的视觉单词出现在图像的许多地方,导致不匹配。一旦应用了停用列表,其中大多数将被删除。接下来将介绍如何删除其余的不匹配项。

6.2. Spatial consistency
谷歌提高了搜索到的单词在检索到的文本中出现得很*的文档的排名(以单词顺序衡量)。这种类比特别适用于通过图像的子部分查询对象,在检索帧中匹配的协变区域应该在查询图像中概述的区域中有一个类似的空间排列[12,14](例如紧凑性)。这个想法是这样实现的:首先仅使用加权频率向量检索帧,然后根据空间一致性的度量对它们重新排序。
空间一致性的度量非常简单,只需要求查询区域中位于检索帧的周边区域的相邻匹配。它还可以通过要求在查询区域和检索帧中具有相同的空间布局的相邻匹配来进行非常严格地度量。在我们的例子中,匹配区域提供了查询图像和检索图像之间的仿射变换,因此可以使用点对点映射来进行严格的度量。
我们发现,在这个可能的测量范围的中间可以获得最好的性能。搜索区域由每个匹配项的15个最*邻定义,并且在该区域内匹配的每个区域都对该框架进行投票。不支持的匹配将被拒绝。投票的总数决定了帧的排名。如图6的最后一行所示,它显示了拒绝了空间一致性的不正确匹配。图7到图9的对象检索示例使用了这种排序度量,并充分证明了它的有用性。
在某些情况下其他度量可能需要考虑图像之间的仿射映射,但这涉及到更大的计算开销。



6.3. Object retrieval
Implementation – use of inverted files: 在经典的文件结构中,所有单词都存储在它们出现的文档中。inverted文件结构为每个单词提供一个条目(命中列表),其中存储该单词在所有文档中出现的所有情况。在我们的例子中,inverted文件为每个视觉单词都设置一个条目,该条目存储所有匹配项,即在所有帧中出现的相同单词。文档向量非常稀疏,使用inverted文件使检索非常快。在2GHz pentium上使用Matlab实现查询一个4k帧的数据库大约需要0.1秒。
Example queries: 图7和8显示了对电影‘Run Lola Run’的两个对象查询的结果,图9显示了对电影‘Groundhog day’的一个对象查询的结果。这两部电影都包含大约4K的关键帧。返回的实际帧和它们的排名都是很好的——可以说,没有包含对象的帧的丢失(即没有false negatives),而且高排名的帧都包含对象(精度高)。
对象查询结果确实展示了视觉词汇表的表达能力。在Groundhog Day电影的检索中,对萝拉学习到的视觉单词的使用没有变化。
7. Summary and Conclusions
与文本检索的类比确实证明了它的价值:我们可以在整个电影数据库中立即进行实时的对象检索,尽管在许多帧中发生了重大的视点变化。将目标指定为图像的子部分,证明了其对于quasi-planar rigid目标来说是充分的。
当然,改进主要是为了克服视觉处理中的问题。目前低rankings是由于缺乏一些场景类型的视觉描述符。但是,框架允许添加其他现有的仿射协变区域(它们将定义一个扩展的视觉词汇表),例如[17]。另一个改进是将感兴趣的对象定义在一个以上的框架上,以允许搜索在所有视觉aspects上。
文本检索的类比也为未来的工作提出了有趣的问题。在文本检索系统中,文本词汇表不是静态的,会随着新文档添加到集合中而增长。类似地,我们并不是说矢量量化对所有图像都是通用的。到目前为止,我们已经为两部电影学习了足够的矢量量化,但是需要找到提高视觉词汇的方法。你可以考虑学习不同场景类型的视觉词汇(例如城市景观vs森林)。
最后,我们现在有了一种有趣的可能性,可以采用文本检索社区的其他成功方法,比如使用潜在语义索引来查找内容,以及自动聚类来查找影片中出现的主要对象。

