
图像检索(image retrieval)- 1 - Deep Learning of Binary Hash Codes for Fast Image Retrieval(2015) - 1 - 论文学习
https://github.com/kevinlin311tw/caffe-cvprw15
这是一篇比较简单的论文,就简单说下思路即可
Deep Learning of Binary Hash Codes for Fast Image Retrieval
就是直接使用CNN模型的7层结果作为特征,但是直接计算两个4096维的向量是十分不高效的,提出使用PCA和判别维度缩减方法来压缩特征
传统的线性搜索方法已经不适用于大尺度的数据集了,所以提出使用Approximate Nearest Neighbor (ANN) or hashing based method [6, 29, 18, 20, 15, 30] 来加速,即将高维的特征投射到一个低维的空间然后生成紧凑的二进制编码,然后可以通过二进制模式匹配或hamming distance来快速搜索,减少了计算开销和提高了搜索效率
受这个的鼓舞,我们想是否能够直接利用CNN去获得hashing,即直接得到二进制紧凑编码
因此提出了一个能够同步生成图像表征和二进制编码的CNN模型,假设数据都是被标记好的,该模型是监督学习的
方法就是部署一个潜在层去表示潜在concepts(使用一个二进制激活函数,如sigmoid),所以不用想其他方法一样需要成对数据
我们的方法包括三个主要部分:
第一个是对大规模ImageNet数据集[14]进行监督预训练,得到预训练模型。
第二个是使用潜在层对网络进行微调,以同时学习特定领域的特征表示和一组类散列函数。
第三个通过提出的分层深度搜索,检索类似图像的查询。

输入图像的F6-8层的特征激活能够用做视觉签名(visual signatures),但是因为这些都是高维向量,用来做大规模的图像检索效率低,所以方法就是将特征向量转成二进制编码。这种二进制紧凑编码能够很快地使用哦hashing和hamming distance进行比较
所以我们的方法是在F7和F8层中间嵌入一个潜在层H,这个潜在层是一个全连接层,它的神经元激活由随后的F8层调控,F8层对语义进行编码并实现分类。在设计中,H层的神经元使用sigmoid函数激活,使其值约分在{0,1}之间
微调的时候H层和F8层随机初始化
使用coarse-to-fine策略来快速且准确地进行图像检索
首先coarse层,将H层的输出中的每个节点根据下面的策略输出:
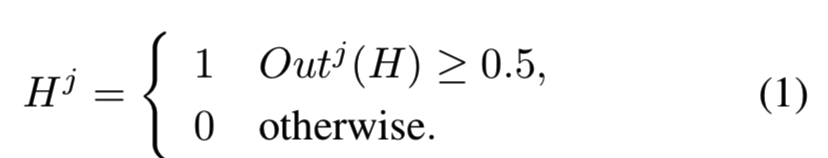
即节点值大于0.5的输出1,小于0.5的输出0,这样就能够将H层的输出变为二进制编码了,然后就能够使用这个编码去比较两个样本间的相似度,即hamming distance,低于制定的某个阈值时则表示相似
然后时Fine层,即使用F7层的特征来计算Euclidean distance,距离越近,表示两张图越相似;然后进行距离由小到大的排序,得到top k的相似图像
就是先用一个低维的二进制编码进行数据的筛选,因为hamming distance计算更快,能够进行一次粗筛,将数据量先减少,然后再在比较少的数据量中使用高维的特征向量进行细筛(这个就是一个将特征二值化的方法,这样的特征占用内存少,且计算速度快,后面的论文中很多都有用到这个方法去进行粗糙排序)
准确度的算法:
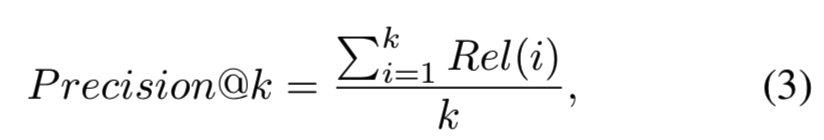
即top k中的结果图像如果和query的图像相关,则Rel(i) = 1,否则为0;计算k个检索出来的图中的相关性的和,然后除以数量k来计算准确度
H层的节点数实验中分别有设置为48和128的,结果是48的效果好,使用的是MNIST数字数据集,数据集简单,所以48个节点就够了,过多反而过拟合了
对于数据集CIFAR-10,对于一个马头,如果使用的是48bit的H层,得到的结果比较偏向于整个马;如果使用的是128bit的,那么得到的结果更接近于马头,更具体一些。所以对于复杂图像,H层更大更能表示准确。准确率大概是89%
结果:
对于Yahoo-1M数据,包含产品数据,H层为128,准确率为83.75%,即使输入图像的背景很复杂
计算4096维的Euclidean distance需要109.767ms,在cpu中;而计算128维的hamming distance只用0.113ms

