

图像检索(image retrieval)- 3 - Visual Search at Pinterest(Amazon) - 1 - 论文学习
Visual Search at Pinterest
ABSTRACT
我们证明,随着分布式计算平台(如Amazon Web Services)和开源工具的可用,一个小型工程团队可以利用广泛可用的工具构建、启动和维护一个具有成本效益的大规模可视化搜索系统。我们还通过在Pinterest上的一组完整的现场实验证明,通过视觉搜索提供的内容推荐可以提高用户的参与度。通过分享我们的实现细节和从零开始推出一个商业视觉搜索引擎的经验,我们希望视觉搜索能更广泛地融入到今天的商业应用程序中。
1. INTRODUCTION
视觉搜索,或基于内容的图像检索[5],是一个活跃的研究领域,部分原因是由于在线照片的爆炸性增长和搜索引擎的流行。谷歌Goggles,谷歌Similar Images和Amazon Flow都是商业视觉搜索系统的例子。尽管在构建web-scale可视化搜索系统方面已经取得了重大进展,但很少有publication描述在商业应用程序上部署的端到端架构。这一方面是由于现实世界中可视化搜索系统的复杂性,另一方面是出于保持核心搜索技术的商业考虑。
在Pinterest上部署商业视觉搜索系统时,我们面临两个主要挑战。首先,作为一家初创公司,我们需要控制人力和计算资源上的开发成本。例如,随着大量且持续增长的图像集合的出现,特征计算会变得昂贵,而工程师们也会不断试验部署新特征,因此对我们的系统来说,既可扩展又具有成本效益是至关重要的。其次,一个商业应用程序的成功是通过它给用户带来的好处(例如,提高用户参与度)与开发和维护成本的关系来衡量的。因此,我们的开发进度需要经常通过实时用户流量的A /B实验来验证。
在本文中,我们描述了基于这两个挑战部署商业视觉搜索系统的方法。我们作出了两大贡献。
我们的第一个贡献是利用广泛可用的工具,展示我们可扩展且成本有效的可视化搜索实现,这对于一个小型工程团队来说是可行的。第2.1节描述了我们使用Pinterest中丰富的元数据(metadata)来加速和提高目标检测和定位的准确性的简单而实用的方法。通过将多类目标检测这一困难(且计算代价高昂)的任务解耦为类别分类,然后再进行每类目标检测,我们只需要在包含目标的高概率图像上运行(代价高昂的)目标检测器即可。第2.2节介绍了使用Amazon Web Services递增地添加或更新图像特征的分布式管道,这避免了对未更改的图像特征进行重新计算。章节2.3展示了我们基于广泛可用的工具构建的分布式索引和搜索基础设施。
我们的第二个贡献是分享了在两个产品应用程序中部署我们的视觉搜索基础设施的结果:即Related Pins(第3节)和Similar Looks(第4节)。对于每一个应用程序,我们使用特定应用程序的数据集来评估每个视觉搜索组件(即相似性检测的对象检测、特征表征)的有效性。在部署端到端系统之后,我们使用A/B测试来衡量在实时流量中用户的参与度。
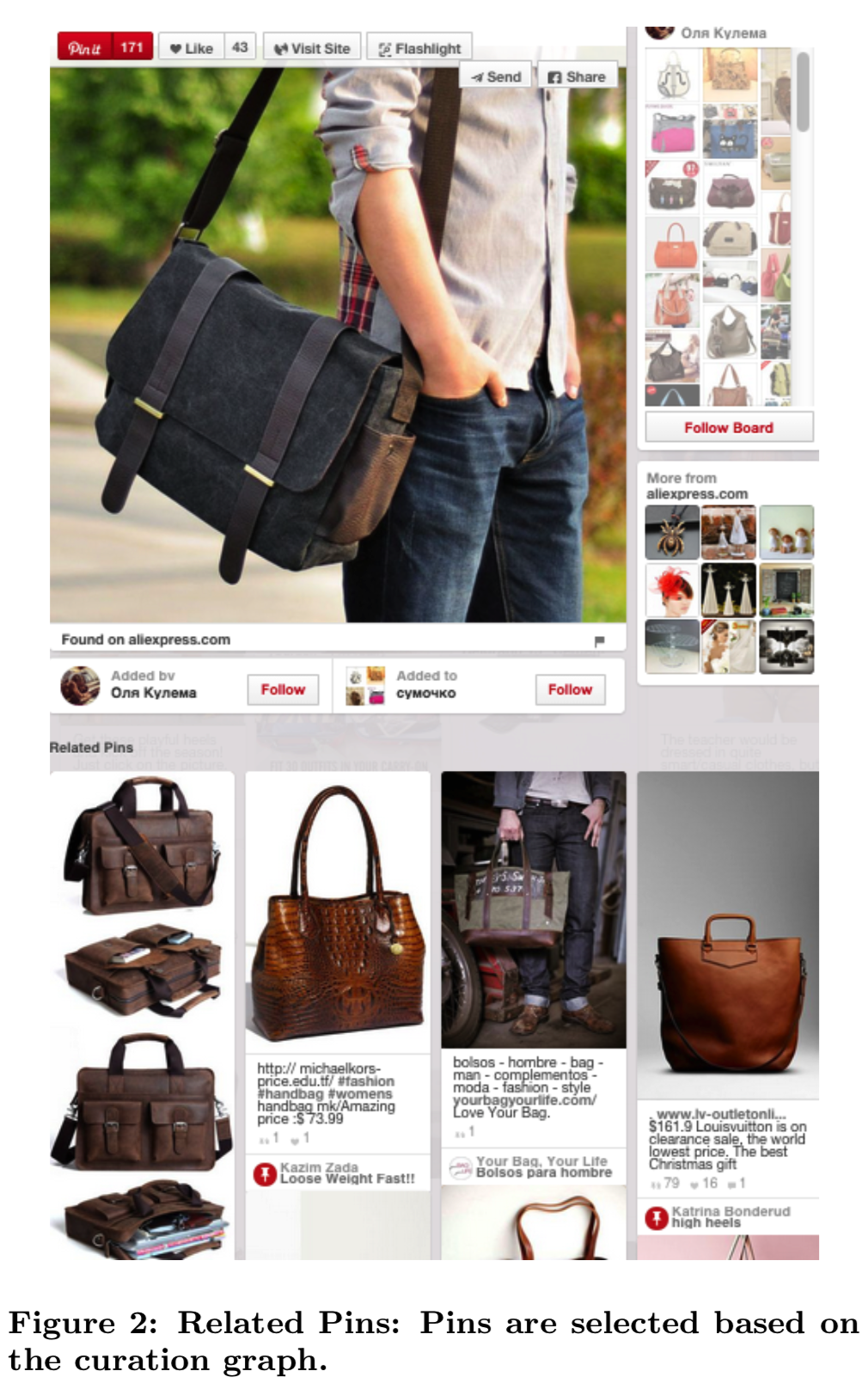
Related Pins(图2)是一个基于用户当前正在查看的Pin推荐Pins的功能。这些推荐主要是从用户、公告板和Pins的“管理图(curation graph)”中产生的。然而,会导致一个长尾的不太受欢迎的别针一直不被推荐。通过使用视觉搜索,我们为Pinterest上几乎所有的Pins生成推荐。我们的第二个应用程序,Similar Looks(图1)是我们专门为时尚Pins做的查找实验。它允许用户从感兴趣的区域(例如一个包或一双鞋)中选择一个视觉查询,并识别出其他视觉上相似的Pins来供用户探索或寻找。不使用整个图像,而是计算查询中的局部对象(即图中的包或鞋)与数据库图像之间的视觉相似性。据我们所知,这是在一个普遍部署的视觉搜索系统中第一个公开的用在在目标检测/定位上的研究。

我们的实验证明:
1)通过将目标检测/定位方法与元数据相结合,可以得到非常低的false positive rate(少于1%)与良好的检测率
2)使用来自VGG[21][3]的特征表征显著改善了Pinterest基准数据集的视觉搜索准确性
3)我们观察到当视觉检索被用于Related Pins和Similar Looks应用时,显著提升了用户参与度
2. VISUAL SEARCH ARCHITECTURE AT PINTEREST
Pinterest是一个视觉书签工具,帮助用户发现和保存创意。用户将图片钉在公告板上,公告板是一个包含特定主题进行的收藏。这个人工策划的user-board-graph包含关于图像及其彼此语义关系的丰富信息集。例如,当一个图像被固定到一个公告板上,它意味着会生成一个在新公告板和该图像出现的所有其他公告板之间的“curatorial链接”。元数据(比如图像注释)可以通过这些链接传播,从而形成对图像、图像公告板和用户的丰富描述。
由于图片是每个pin的焦点,视觉特征在为用户寻找有趣的、令人激动的和相关的内容方面发挥了很大的作用。在本节中,我们将描述一个视觉搜索系统的端到端实现,该系统将在Pinterest上索引数十亿张图片。我们致力于开发一个真实世界的视觉搜索系统,以平衡成本约束和快速原型的需求。我们描述了1)我们从图像中提取的特征,2)我们的分布式和增量特征提取的基础设施,3)我们的实时视觉搜索服务。
2.1 Image Representation and Features
我们从图像中提取各种特征,包括局部特征和从深度卷积网络的中间层激活中提取的“深度特征”。深层特征来源于基于AlexNet[14]和VGG[21]架构的卷积神经网络(CNNs)。我们使用了来自fc6和fc8层的特征表征。对这些特征进行二值化以提高表示效率,并利用汉明距离进行比较。我们使用开源的Caffe[11]在多gpu机器上对我们的CNNs进行训练和推断。
该系统还可以从图像中提取显著的颜色特征。首先检测图像的显著区域[24,4],然后应用k-means对显著像素的Lab像素值聚类来计算显著色彩。聚类中心和权重作为图像的颜色特征存储。
Two-step Object Detection and Localization
一个与Pinterest特别相关的特征是某些对象类的出现,比如包、鞋、手表、裙子和太阳镜。我们采用了两步检测的方法,利用Pinterest图像上丰富的弱文本标签。由于图像被多次固定在许多公告板上,聚合的pin描述和公告板标题提供了大量关于图像的文本信息。Pinterest的文本处理管道从原始文本中为图片提取相关注释,生成与每张图片相关的短语。
我们使用这些注释来确定运行哪个对象检测器。在图1中,我们首先确定图像可能包含包和鞋子,然后对这些对象类应用视觉对象检测器。首先进行类别分类,我们只需要在有着高先验似然匹配的图像上运行目标检测器,减少了计算成本和误报。(即首先进行类别分类,发现该图片对应的包和鞋子的类别概率比较高,然后再将其输入到包和鞋子对应的对象检测器中去分别检测包和鞋子的位置,得到边界框)
我们最初的对象检测方法是对级联变形的基于部分的模型[7]的高度优化实现。该检测器为每个检测到的对象输出一个边界框,从中提取对象的视觉描述符。我们最近的工作重点是研究基于目标检测器[8,9,6]的深度学习的可行性和性能,其作为我们两步检测/定位流水线的一部分。
我们在第4节的实验结果显示,我们的系统获得了一个非常低的false positive rate(小于1%)结果,这对我们的应用至关重要。这种两步方法也使我们能够将其他信号纳入类别分类中。同时使用文本和视觉信号进行目标检测和定位被广泛使用[2][1][12]在Web图像检索和分类中。
Click Prediction
当用户在Pinterest上浏览时,他们可以通过点击查看全屏(“close-up”)来与pin互动,然后接着点击到内容的外部来源(a click-through)。对于每一幅图像,我们根据其视觉特征预测特写率(close-up rate,CUR)和点击率(click-through rate,CTR)。我们训练了一个CNN来学习从图像到用户打开特写视图或点击内容的概率的映射。CUR和CTR对于搜索排名、推荐系统和广告定位等应用程序都很有帮助,因为我们经常需要知道哪些图片的视觉内容更有可能得到用户的关注。
最近,CNNs已经成为许多涉及视觉输入的语义预测任务的主要方法,包括分类[15,14,22,3,20,13]、检测[8,9,6]和分割[17]。训练一个完整的CNN来学习好的表征是非常耗时的,并且需要非常大的数据语料库。我们通过保留为其他计算机视觉任务训练的模型的低水平视觉表征,将转移学习应用到我们的模型中。网络的高水平层根据我们的特定任务进行了微调。(其实就是固定CNN网络的前面一部分参数,只微调更改后面的参数,如fc层的参数)这节省了大量的训练时间,并利用了从比目标任务大得多的语料库中学习到的视觉特征。我们使用Caffe来执行这个迁移学习。
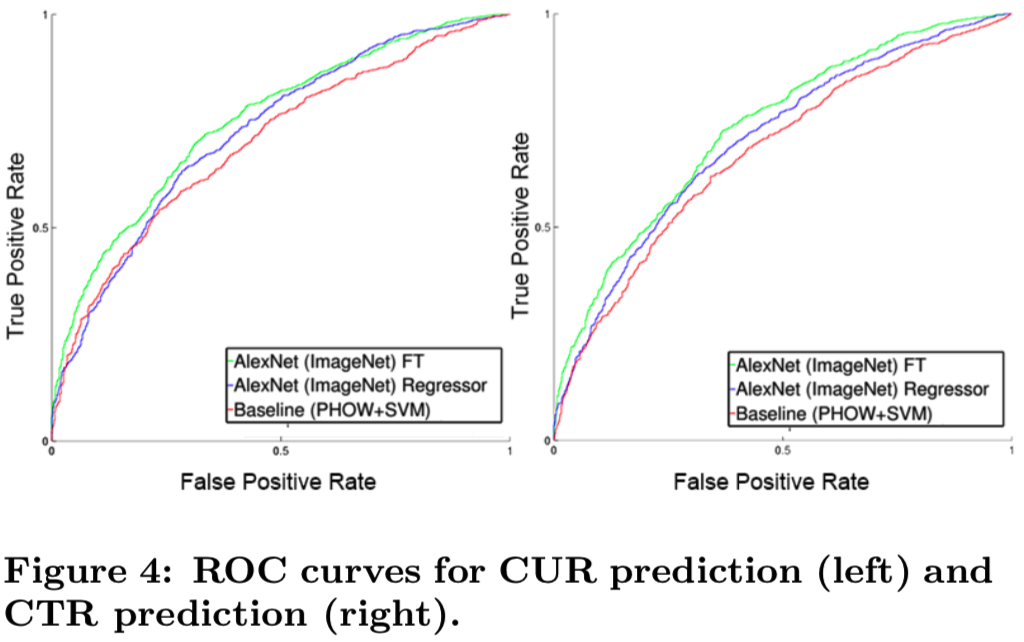
图4描述了我们基于CNN方法的receiver operating characteristic (ROC) 曲线,与基于“传统”计算机视觉管道的基线进行比较:即一个基于单词金字塔直方图(PHOW)的二值标签训练的SVM,它在像Caltech-101这样的对象识别数据集上表现良好。我们基于CNN的方法的性能优于PHOW-SVM基线,并且从端到端对CNN进行微调也能显著提高性能。在检测上传至Pinterest的淫秽图片的任务中也采用了类似的方法,效果良好。
说明使用CNN进行特征抽取的效果好
2.2 Incremental Fingerprinting Service
我们的大多数视觉应用程序依赖于拥有完整的图像特性集合,并以适于批量处理的格式存储。保持这些数据的最新是一个挑战;由于我们的集合包含超过10亿张单独的图像,因此关键是要不断地更新特征集,并尽可能避免不必要的重新计算。
我们建立了一个名为增量指纹服务(Incremental Fingerprinting Service)的系统,它使用Amazon EC2上的workers集群计算所有Pinterest图像的图像特征。它在两种主要变化场景下逐步更新特征集合:即新图片上传到Pinterest,以及特征演化(由工程师对特征进行添加/修改)。
我们的方法是将图像集合按上传日期分组,并为每种特征类型(全局deep、局部local、深度deep特征)的每个版本(全局、局部、深度特性)维护一个单独的特征存储。特征批量存储在Amazon S3上,按特征类型、版本和日期组织。当数据完全更新时,每个特征存储包含所有的epochs。在每次运行时,系统会检测每个特征缺少的epoch,并将作业放入一个分布式队列中填充这些epoch。
该存储方案支持以下增量更新。每一天,当一个新的带有当天单独上传内容的epoch被添加到我们的收藏,我们将产生这个日期缺失的特征。由于旧图像不改变,它们的特征不重新计算。如果用于生成特征的算法或参数被修改,或者如果添加了一个新特征,则启动一个新特征存储,并为该特征计算所有epoch。未更改的特性不受影响。
我们将这些特征复制成各种形式,以便其他作业更方便地访问:特征被合并成包含图像所有可用特征的指纹fingerprint,指纹被复制到分片、排序的文件中,以便通过图像签名(MD5哈希)进行随机访问。这些连接的指纹文件定期re-materialized,但只需对每幅图像进行一次昂贵的特征计算。
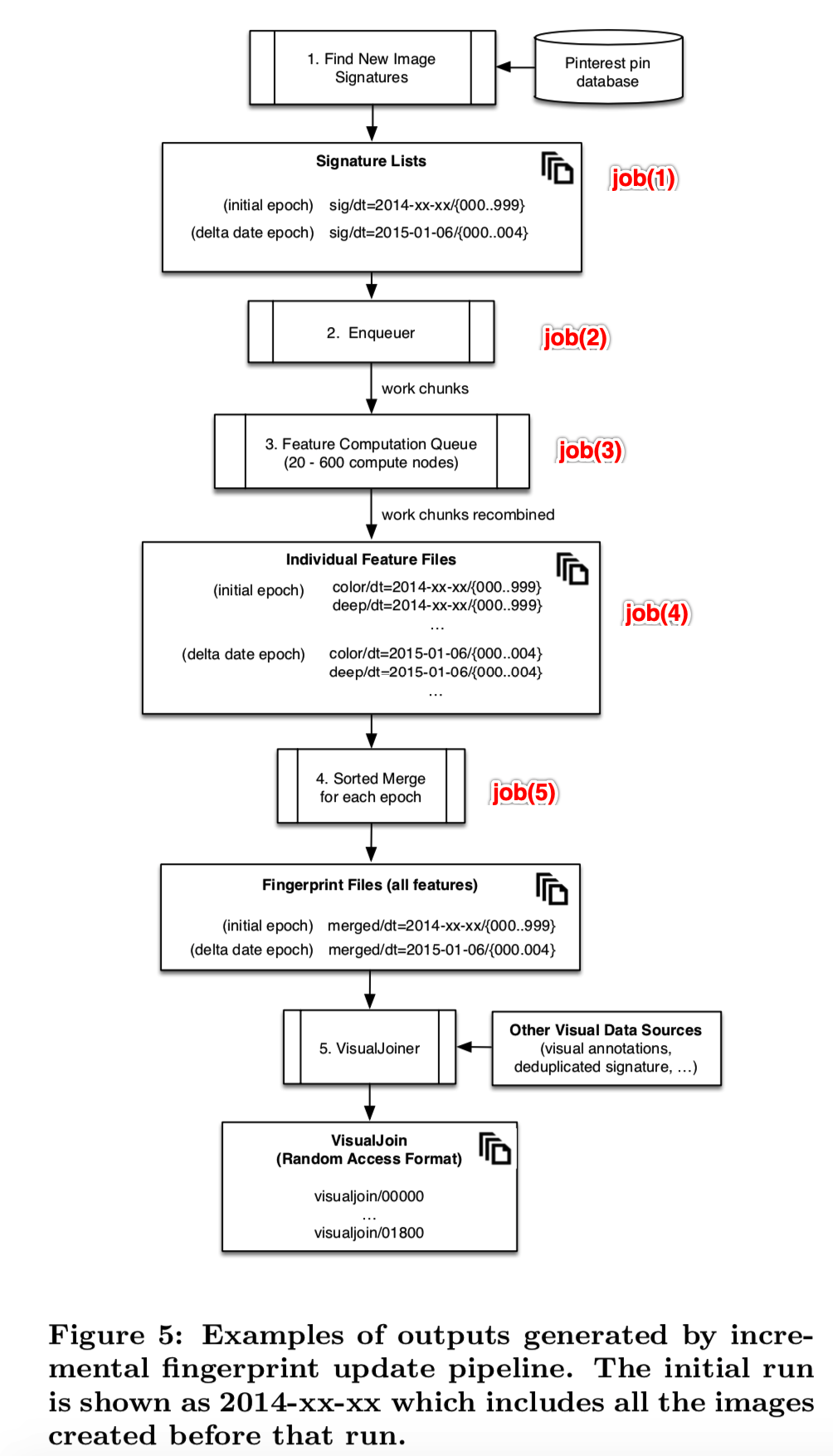
增量指纹更新过程的流程图如图5所示。它由五个主要jods组成:
- job(1)编译新上传的图像的签名列表,并按日期将其分组成epochs(一个epoch中包含的是某个日期中多张图的签名)。我们随机将每个epoch分成大约20万张图像的有序分片shards,以限制最终指纹文件的大小(即再将一个epoch分成更小的shards单元)。
- Job(2)标识每个特征存储中缺失的epochs(即通过图像指纹去查那个图像的特征不在特征存储中,不在则缺失,要计算),并将jobs(即需要计算特征的图像)排队到PinLater(类似于Amazon SQS的分布式队列服务)中。这些jobs将分片shards细分为“工作块(work chunks)”(分得更细),调整为每个块大约需要30分钟来计算。
- Job(3)运行在自动启动的EC2实例集群上(计算特征),根据更新的大小进行缩放。可以使用Spot实例;如果一个实例被终止,它的job将在另一个worker上重新调度。每个工作块的输出被保存到S3中,并最终重新组合成与原始分片shards对应的特征文件。
- Job(4)将单个特征shards(因为一张图可能会计算得到很多类型的特征,如deep、local、global和color等特征)合并成一个统一的指纹,包含每幅图像的所有可用特征
- Job(5)将所有epochs合并为有序、分片的HFile格式,允许随机访问。(即计算完缺失的图像特征后,将其存放到特征存储中来访问)
使用一个由几百台32核机器组成的集群,对所有图像上所有可用特征的初始计算花费了一天多一点的时间,并生成大约5 TB的特征数据。在稳定状态下,增量处理新图像的要求只有大约5台机器。
讲的是怎么存储更新特征的
2.3 Search Infrastructure
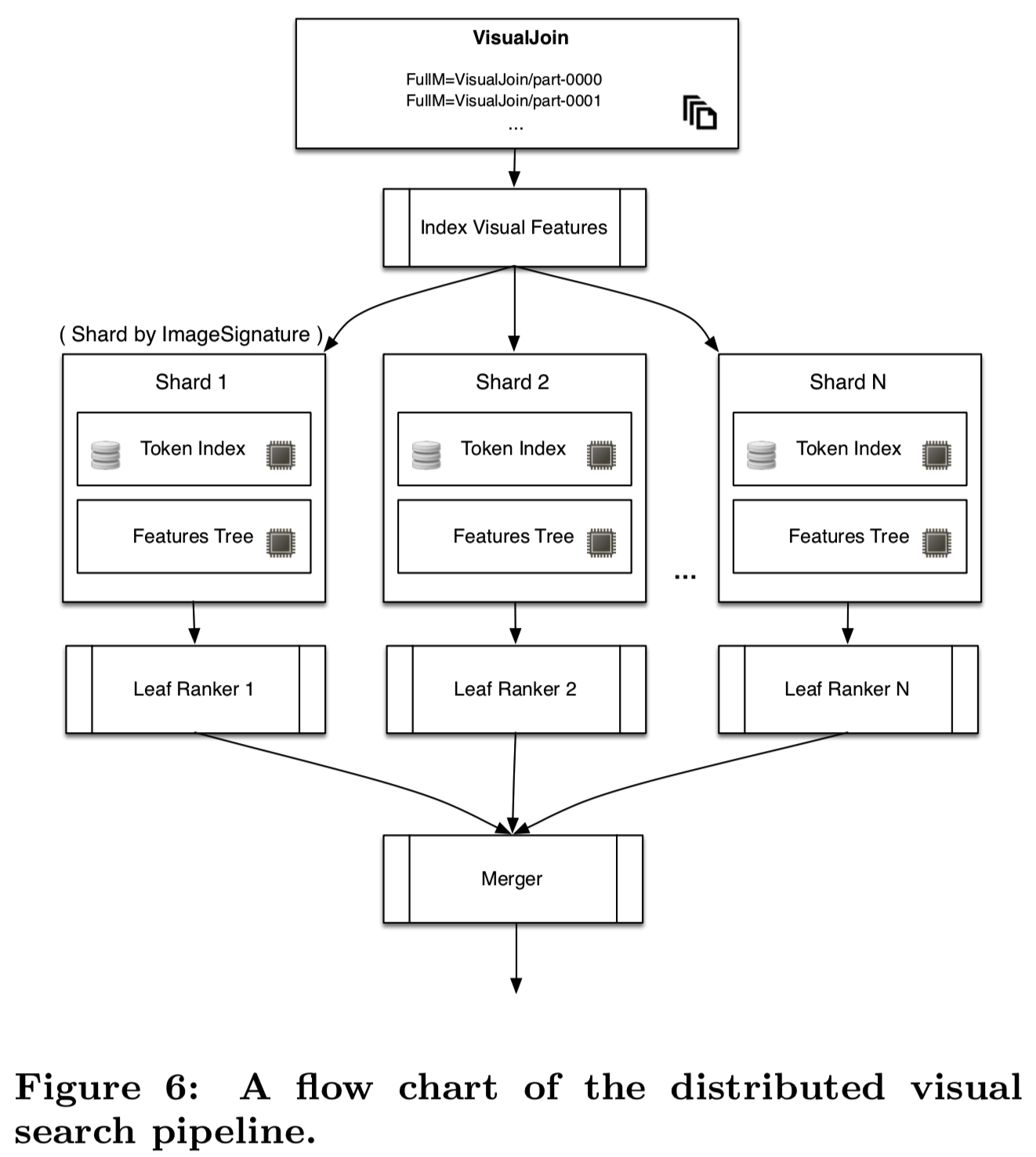
在Pinterest,有几个分布式视觉搜索系统的用例。一个用例是探索外观相似的产品(Pinterest Similar Looks),其他的包括near-duplicate检测和内容推荐。在所有这些应用程序中,可以通过构建在上一节生成的visualjoin之上的分布式索引来计算视觉相似结果。由于每个用例都有不同的性能和成本需求集,因此我们的基础设施被设计为灵活且可重新配置的。搜索基础结构的流程图如图6所示。
(这部分是说明当输入一个查询图像时,怎么使用存储的特征对查询图像查找相似图像,其实就是使用两种索引进行两层查找得到top k的候选集,然后再用原数据metadata进行重排序,然后将多个机器的结果合并起来就得到最中的推荐结果)
第一步,我们使用Hadoop从visualjoin创建分布式图像索引。通过使用doc-ID分片,每台机器都包含与整个图像集合的一个子集相关联的索引(和特性)。使用两种类型的索引:第一种是磁盘存储(和部分内存缓存)token索引,以矢量量化特性(例如视觉词汇表)作为键(这是使用特征计算得到的),和图像doc-id哈希作为发布列表。这类似于基于文本的图像检索系统,只是文本被视觉token所替代。第二种是内存缓存特性,包括视觉和元数据,比如图像注释和从user-board-image图中计算出的“topic vector主题向量”。第一部分用于快速(但不精确)查找,第二部分用于更精确(但较慢)的排序细化。
每台机器都运行一个叶排序器(Leaf ranker),它首先根据索引计算k近邻,然后根据附加的元数据(如注释)计算查询图像和每个最优候选图像之间的分数,从而对最优候选图像重新排序。在某些情况下,叶排序器跳过token索引,直接使用近似KNN的variations(如[18])从特征树索引中检索k-近邻图像。驻留在另一台机器上的根排序器(root ranker)将从每个叶排序器中检索K个top结果,它们将结果合并并返回给用户。为了处理我们的实时特征提取器生成的新指纹,我们有一个在线版本的视觉搜索管道,在那里会发生非常类似的过程。然而,对于在线版本,给定的指纹是在预先生成的索引上查询的。
3. APPLICATION 1: RELATED PINS
Pinterest视觉搜索产品线的首批应用之一是一个名为Related Pins的推荐产品,该产品可以在用户浏览Pin时推荐用户可能感兴趣的其他图片。传统上,我们使用用户管理的image-to-board关系和基于内容的信号来生成这些推荐。然而,这种方法的一个问题是,计算这些推荐是一个离线的过程,假设了image-to-board的关系肯定已经被策划,但是对于我们不太受欢迎的Pins或新创建的Pins来说,其image-to-board的关系可能并没有被创建。因此,Pinterest上6%的图片很少或根本没有推荐。对于这些图像,我们使用前面描述的视觉搜索管道,根据视觉信号生成Visual Related Pins,如图7所示。
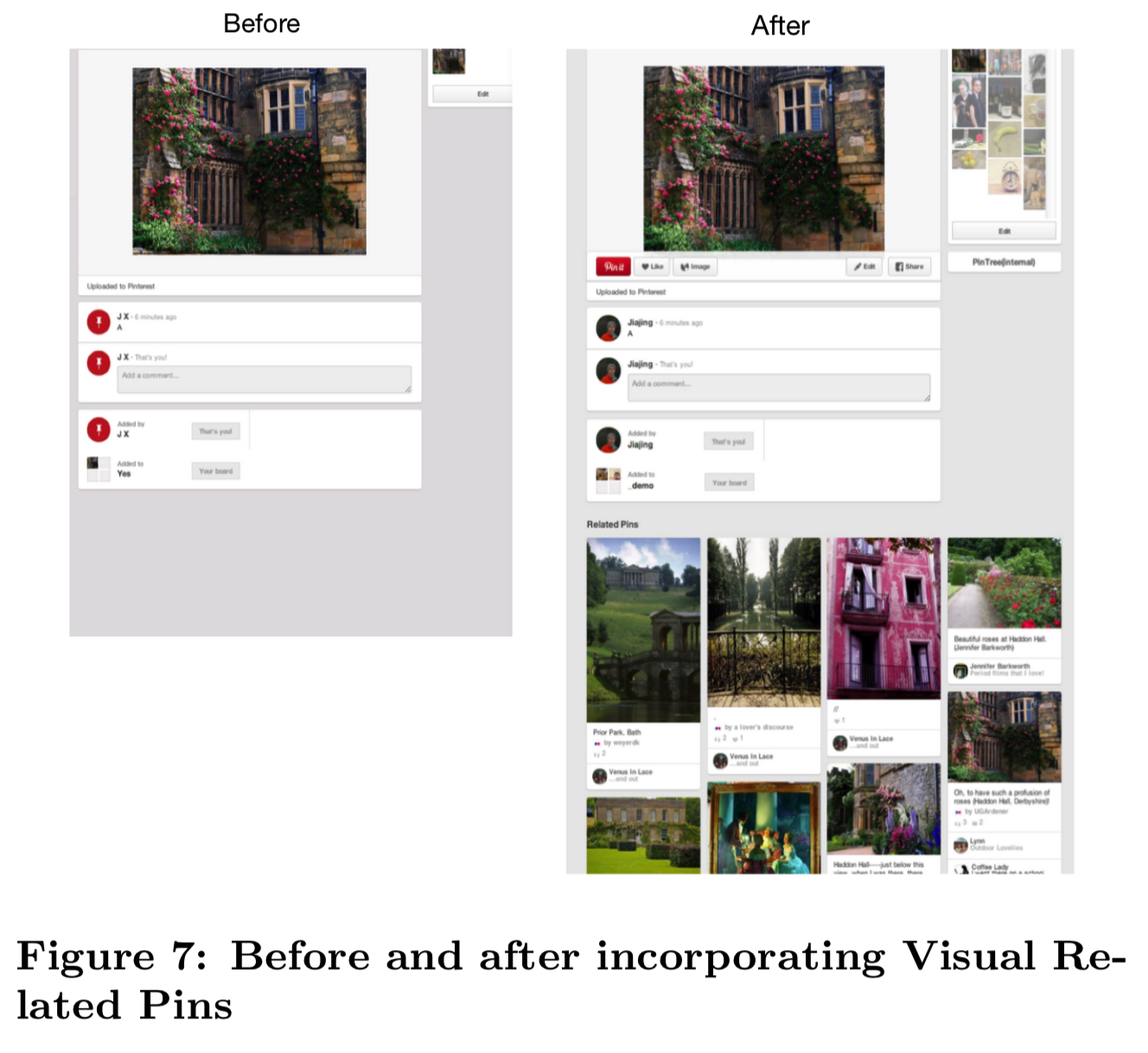
Visual Related Pins产品的第一步是使用从所有已有的Pinterest图像构建的本地token索引来检测我们是否有与查询图像近似重复的图像(去重)。具体来说,给定一个查询图像,系统将返回一组图像,这些图像是同一图像的变体,但经过调整(如调整大小、裁剪、旋转、翻译、添加、删除和修改可视内容的较小部分)而改变。由于结果图像看起来与查询图像相同,因此它们的推荐很可能与查询图像相关。然而,在大多数情况下,我们发现要么没有检测到近似重复的图像,要么近似重复的图像没有足够的推荐。因此,我们将大部分注意力集中在检索基于深度特征的索引生成的可视化搜索结果上。(说明本地token索引没有什么用)
Static Evaluation of Search Relevance
我们最初的Visual Related Pins实验在搜索基础设施中利使用了来自原始版本和微调版本的AlexNet模型。然而,最近成功的更深的用于分类的CNN架构使我们能从各种CNN模型中研究特征集的性能。
在进行可视化搜索的评估时,我们使用与图像关联的图像注释作为相关性的代理。除了人工评估之外,这种方法通常用于视觉搜索系统[19]的离线评估。在这项工作中,我们使用与每个图像相关联的顶部文本查询作为测试注释。我们使用Pinterest Search对每1000个查询检索3000张图像,生成一个大约160万张独特图像的数据集。我们用生成图像的查询来标记每个图像(说明某个图像是因为某个query得到的)。如果两个图像label相同,则假设视觉搜索结果与查询图像相关。(得到的是测试集)
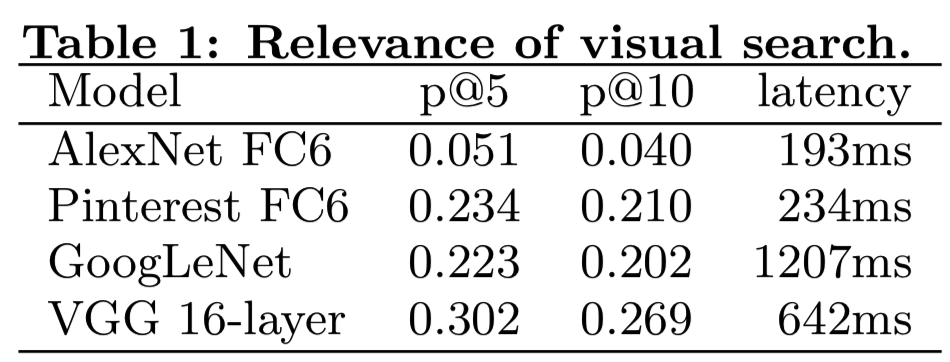
利用该评价数据集,我们计算出了几个特征集的precision@k度量:原始的AlexNet第6层全连接特征(fc6),经过Pinterest产品数据训练的微调AlexNet模型的fc6特征,GoogLeNet(“loss3”层输出),以及16层VGG网络[3]的fc6特征。我们还研究了将上述low-level特征的得分与分类器层的输出向量(语义特征)的得分相结合。表1显示了使用low-level特征进行最近邻搜索的这些模型的p@5和p@10性能,以及可视化搜索服务的平均延迟(包括查询图像的特征提取和检索)。当使用 16层VGG模型的FC6特性时,我们观察到评估数据集的精度有了实质性的提高,并且应用程序有了可接受的延迟。
Live Experiments
在我们的实验中,我们建立了一个检测带有少量推荐的新Pins的系统,并对我们的视觉搜索系统进行查询,并将结果存储在HBase中,以供Pin 特写(close-up)时使用。
在视觉搜索系统的基础上,我们为本实验做了一个改进,增加了一个结果元数据一致性阈值,以降低召回率为代价提高了搜索精度。这一点很重要,因为我们担心,向用户提供糟糕的推荐会对该用户在Pinterest上的参与度产生持久影响。这一点尤其值得关注,因为我们在查看新创建的pin时提供了视觉推荐,而这种行为在新加入的用户中经常发生。因此,我们选择降低召回率,如果这意味着能提高相关性。
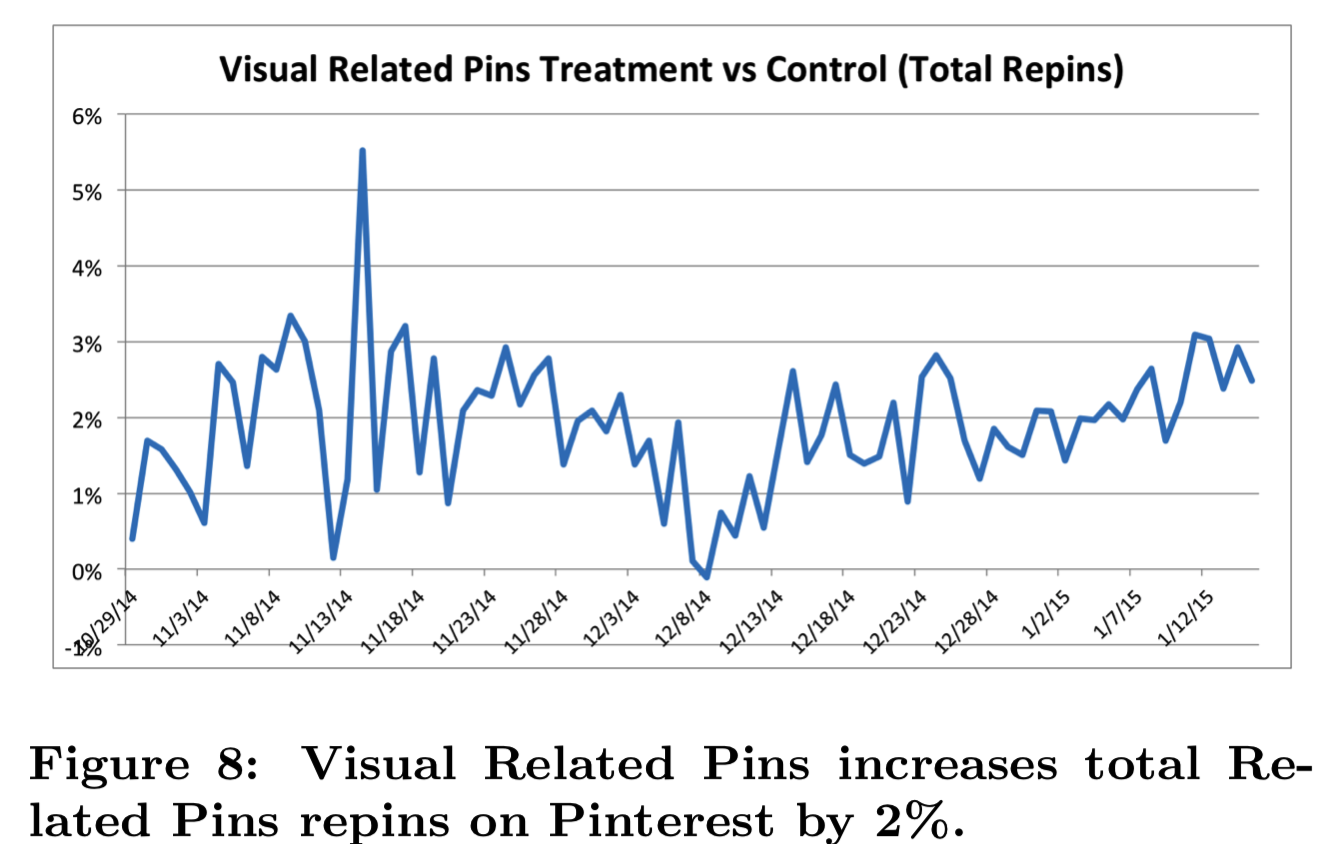
我们最初将实验应用到Pinterest中符合条件的10%的live流量中。我们认为当用户查看一个没有足够推荐的Pin的close-up时,我们认为用户是有资格的,并触发了用户进入一个treatment,该组能够使用得到的视觉搜索结果替换Related Pins部分(其实就是将推荐结果放在了相应位置);或者触发进入一个control组,该组不对实验进行更改。在这个实验中,我们测量的是Related Pins部分中总repins的变化,repinning是用户添加一张图到他们的收藏的这个动作。我们选择衡量repins是因为它是我们用来测量参与度的首要指标之一。
经过3个月的实验,可见在Related Pins产品中Related Pins的总repins增加了2%,如图8所示。
4. APPLICATION 2: SIMILAR LOOKS
Pinterest上最受欢迎的类别之一是女性时尚。然而,在这类产品中,很大一部分pin无法引导用户体验购物体验,因此不具有可操作性。要让这些Pins具有可操作性,有两个挑战:1)许多pins都标注了比如“街头时尚”服装的编辑shots,这些照片通常链接到一个网站,但对图片中所展示的物品没有什么额外信息;2)Pin图像通常包含多个对象(例如,一个女人走在街上,带着一个豹纹包,黑色的靴子,太阳镜,破旧的牛仔裤,等等)一个用户看着Pin可能有兴趣了解更多的手袋,而另一个用户可能想买太阳镜。
用户研究显示,这是一种常见的用户挫折感,我们的数据表明,相对于其他类别,用户更不可能点击进入女性时尚Pin的外部网站。
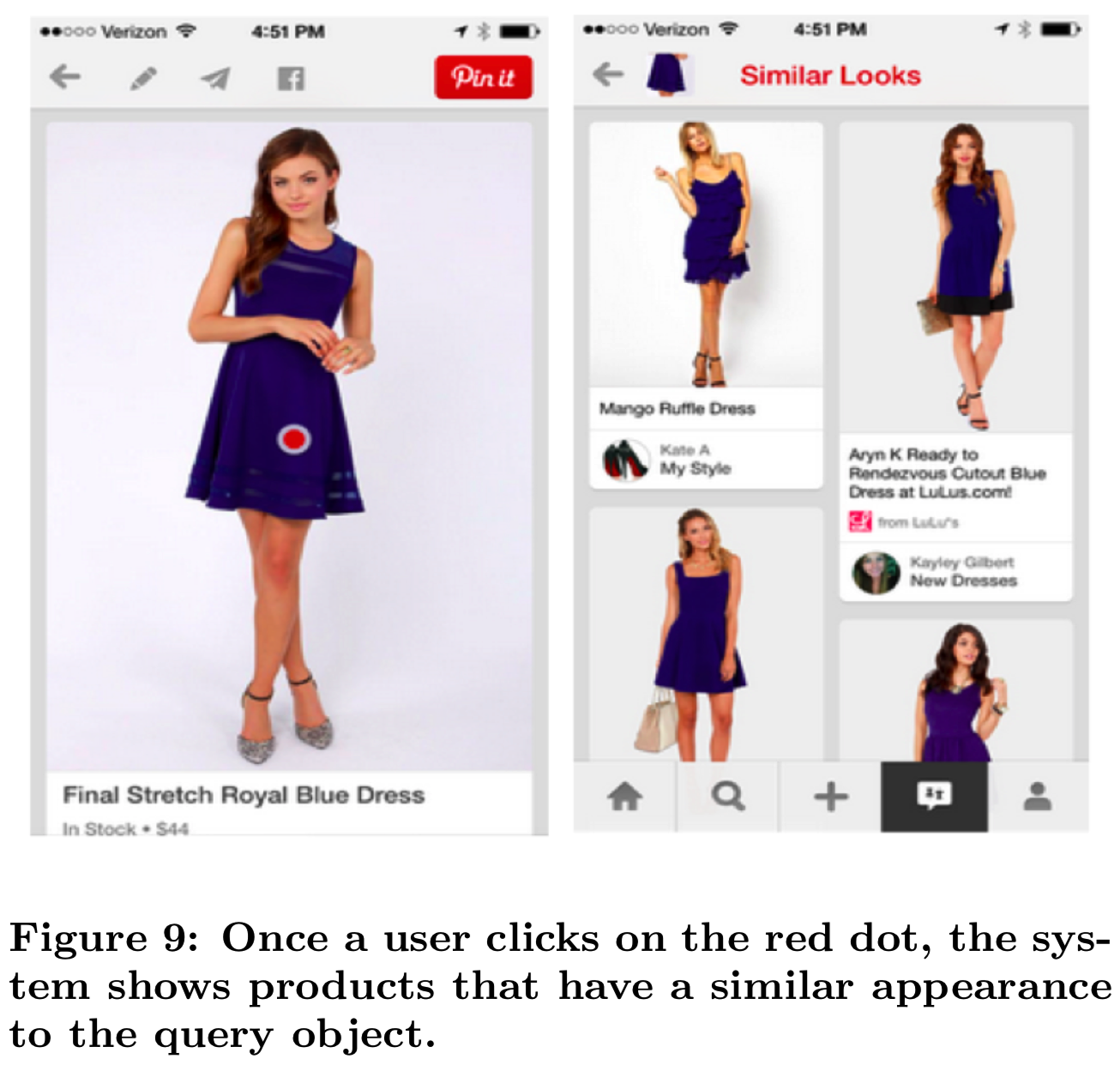
为了解决这个问题,我们构建了一个名为“Similar Looks”的产品,该产品对时尚对象进行了定位和分类(图9)。我们使用目标识别来检测Pin图像中的产品,如包、鞋、裤子和手表。从这些对象中,我们提取视觉和语义特征来生成产品推荐(“Similar Looks”)。如果Pin中的对象上有一个红点,用户就会通过它发现相应的推荐(参见图1)。单击红点将加载视觉上类似对象的Pins(例如,其他视觉上类似的蓝色连衣裙)。
Related Work
将视觉搜索应用到“soft goods”已经在学术界和工业界进行了探索。像.com,谷歌Shopping和Zappos(亚马逊旗下)就是一些著名的计算机视觉时尚推荐应用。百度和阿里巴巴最近也推出了视觉搜索系统,解决了类似的问题。也有越来越多的基于视觉的时尚推荐研究[23,16,10]。我们的方法展示了基于对象的视觉搜索系统在数千万Pinterest用户上的可行性,并展示了围绕这些检测到的对象的交互式搜索体验。
Static Evaluation of Object Localization
评估Similar Looks产品的第一步是研究对象定位和检测能力。我们选择关注时尚对象,是因为上述业务需求,因为“soft goods”往往有独特的视觉形状(例如短裤、包、眼镜)。
我们从Pinterest的女性时尚类别中随机抽取一组图片,通过在图片上画一个矩形剪裁,手工标注9个类别(鞋子、衣服、眼镜、包、手表、裤子、短裤、比基尼、earnings)中的2399个时尚物品,从而收集我们的评估数据集。我们观察到,鞋子、包、裙子和裤子是我们评估数据集中的四个最大类别。表2显示了时装对象的分布以及基于文本的过滤器、基于图像的检测和两者的组合方法(在对象检测之前应用文本过滤器)的检测精度。
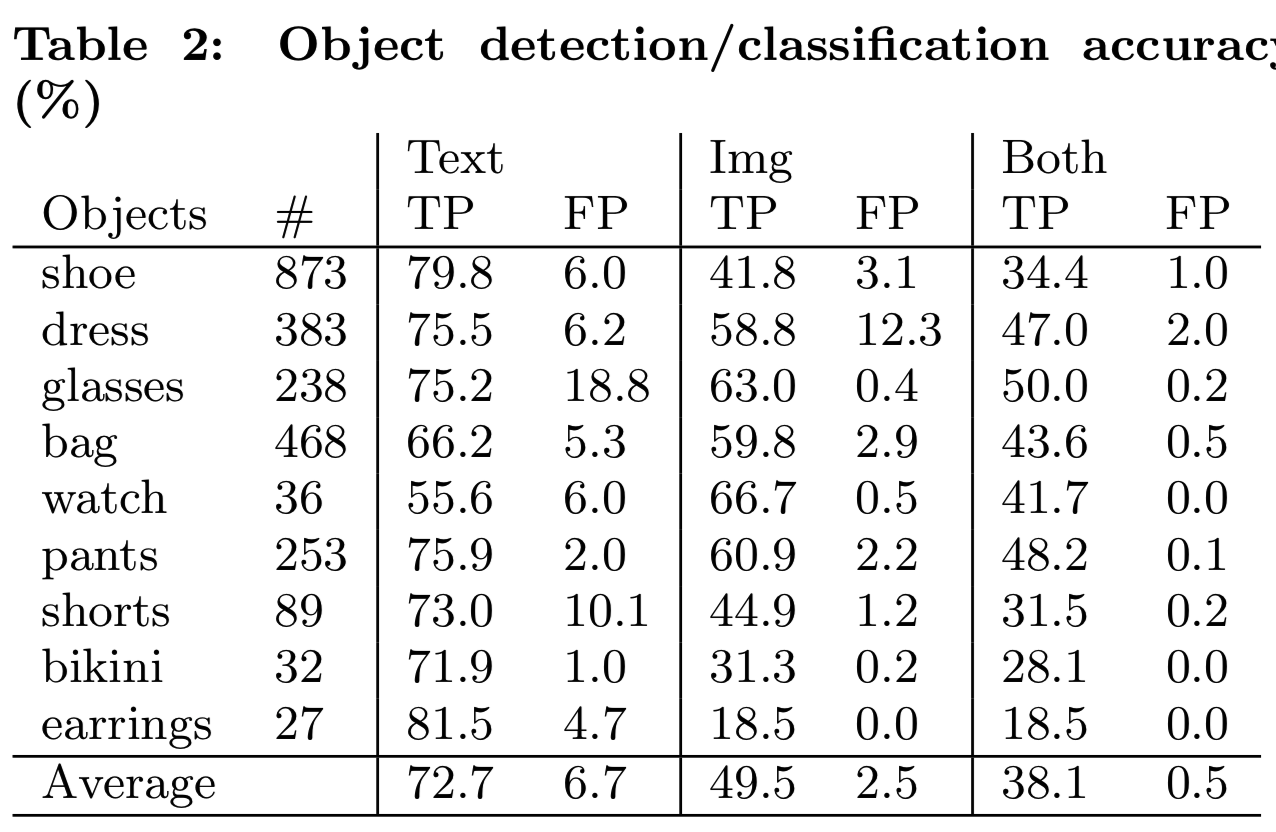
如前所述,基于文本的方法将手工制作的规则(例如正则表达式)应用到与图像相关的Pinterest元数据(我们将其视为弱标签)。例如,注释为“spring fashion, tote with flowers”的图像将被归类为“bag”,如果图像包含一个“bag”对象框标签,则被认为是一个积极的样本。在基于图像的评估中,我们计算预测对象边界框与同类型标记对象边界框的交集,当交集和并集比大于0.3时,视为正匹配。
表2表明,单独使用文本注释过滤器和对象定位都不足以完成我们的检测任务,因为它们的false positive rate相对较高,分别为6.7%和2.5%。毫不奇怪,两种方法的结合显著地降低了我们的false positive rate到1%以下。
具体来说,我们发现对于像“glasses”这样的类,文本注释是不够的,而基于图像的分类则更出色(因为眼镜具有独特的视觉形状)。对于其他类,比如“dress”,这种情况被逆转了(我们的服装检测器的false positive rate很高,为12.3%,这是由于该类的遮挡和样式的高差异,并且发现添加文本过滤器后,显著提高了结果)。除了减少我们需要用目标分类器去fingerprint的图像数量外,对于几个对象类(鞋、包、裤子),我们观察到文本预过滤对于实现可接受的false positive rate(1%或更少)是至关重要的。
Live Experiments
我们的系统从一个Pinterest图片子集中识别出超过8000万“可点击”的对象(即可以放红点的对象)。一个可点击的红点被放置在被检测的物体上。一旦用户点击了这个点,我们的视觉搜索系统就会检索到一个在视觉上与对象最相似的Pins集合。我们向Pinterest的一小部分live流量使用了该系统,并收集了一个月的用户参与度指标,比如CTR。具体来说,我们研究了红点的点击率,视觉搜索结果的点击率,并且比较了带有已有的Related Pin推荐的Similar Looks结果的参与度。
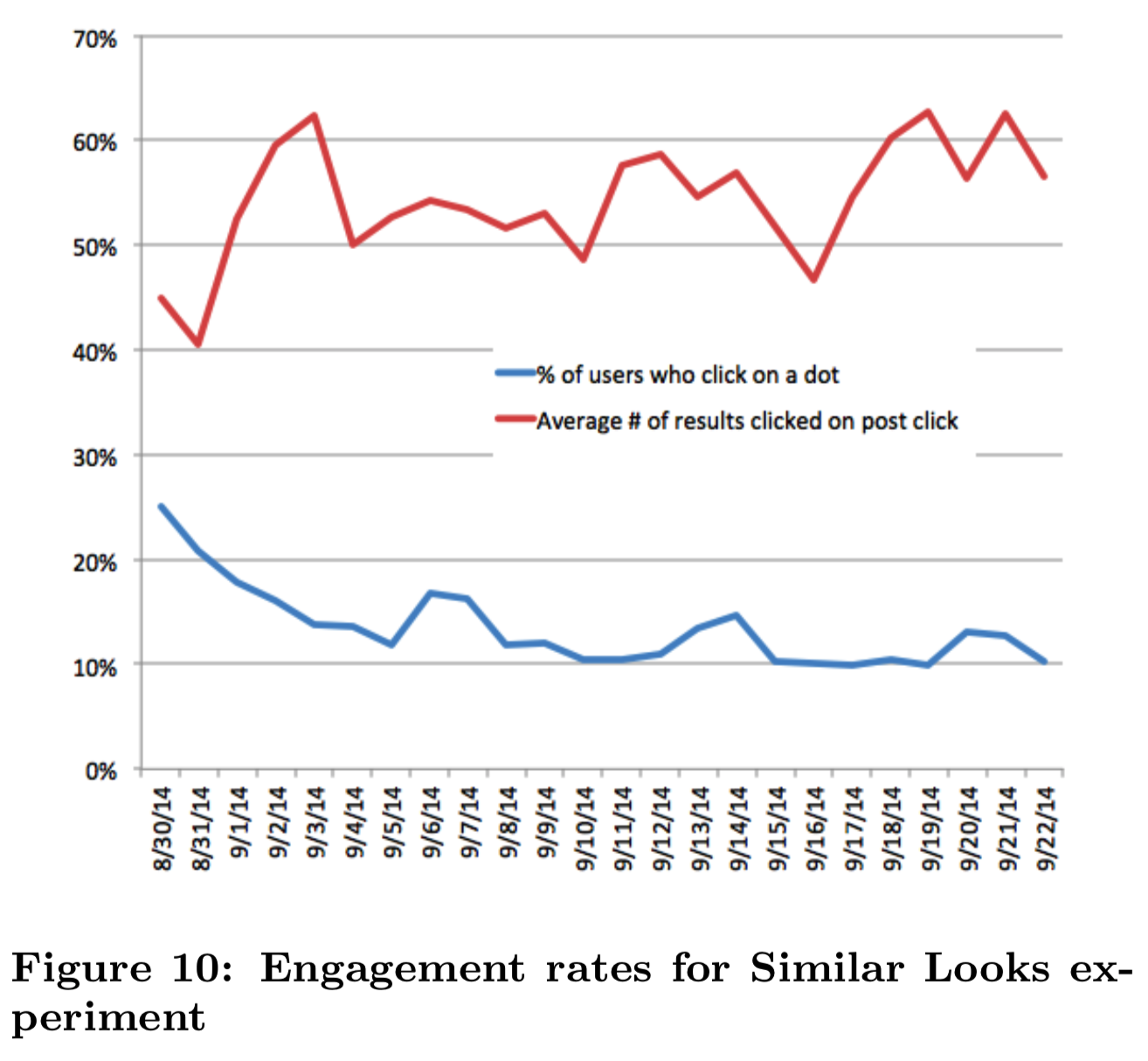
如图10所示,平均有12%的用户在某一天点击了一个点。这些用户继续点击平均0.55个Similar Looks结果。虽然这些数据令人鼓舞,当我们比较在pin close-up中的所有相关内容的参与度时(即对在treatment组的Related Pin和Similar Looks结果的参与度求和;而仅关联control组的pin参与度),Similar Looks实际上减少了pin close-up上4%的总参与度。当这些新的努力消退后,我们看到红点上的CTR逐渐下降,稳定在10%左右。
为了独立于引入新用户行为(学习去点击“object dots”)而产生的偏差来测试Similar Looks结果的相关性,我们设计了一个实验,将Similar Looks结果直接混合到现有的Related Pins产品中(用于包含检测的对象的Pins)。这给了我们一种方法来直接衡量用户是否认为我们的视觉上相似的推荐与我们的非视觉上的推荐相关。在我们检测到物体的Pins上,这个实验将Related Pins的整体参与度(repins和close-up)提高了5%。尽管我们为这个实验设置了一个初始静态混合比例(即一个用于三个产品结果的视觉相似结果),但该比例会根据用户单击数据进行调整。
5. CONCLUSION AND FUTURE WORK
我们证明,随着分布式计算平台(如Amazon Web Services)和开源工具的可用,少数工程师或学术实验室可以使用非专有工具的组合来构建大规模的可视化搜索系统。本文提出了我们的端到端可视化搜索管道,包括增量特征更新和两步目标检测和定位方法,提高了搜索精度,降低了开发和部署成本。我们的live产品实验表明,视觉搜索功能可以提高用户的参与度。
我们计划在以下方面进一步完善我们的制度。首先,我们感兴趣的是研究基于CNN的目标检测方法在实时视觉搜索系统中的性能和效率。其次,我们希望利用Pinterest的“管理图”来增强视觉搜索的相关性。最后,我们想要实验视觉搜索的替代交互界面。
